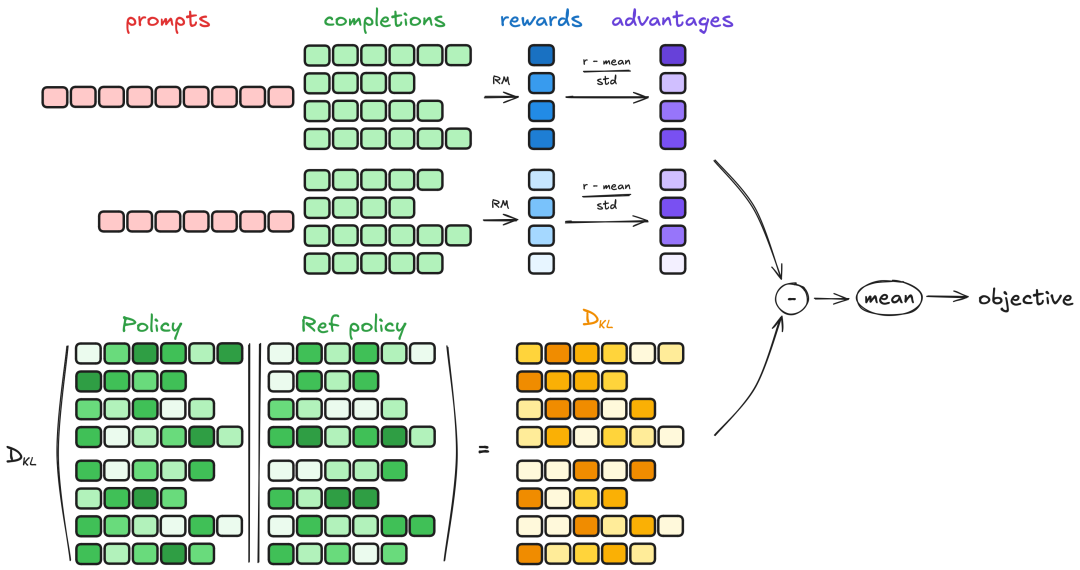
TRL(Transformer Reinforcement Learning) 是由 Hugging Face 开发的一套基于强化学习(Reinforcement Learning, RL)的训练工具,专门用于优化和微调大规模语言模型(如 GPT、LLaMA 等)。它结合了 PPO(Proximal Policy Optimization) 等强化学习算法,使开发者能够高效地对预训练语言模型进行 RL 微调,以优化特定目标(如人类偏好对齐、任务性能提升等)。
TRL 的核心功能
TRL 提供了一套完整的 RL 训练流程,主要包括以下几个关键模块:
1. 监督微调(Supervised Fine-Tuning, SFT)
- 在 RL 训练之前,通常需要先用监督学习对预训练模型进行初步微调,使其适应目标任务(如对话、摘要等)。
- TRL 支持直接加载 Hugging Face 的
transformers模型,并使用SFTTrainer进行高效微调。
2. 奖励建模(Reward Modeling)
- 在 RL 训练过程中,需要一个奖励模型(Reward Model)来评估生成文本的质量(如是否符合人类偏好)。
- TRL 支持训练或加载自定义奖励模型(如基于
BERT或RoBERTa的模型),用于 PPO 训练阶段的反馈。
3. PPO 强化学习训练(Proximal Policy Optimization)
- PPO 是一种高效的强化学习算法,TRL 的
PPOTrainer封装了 PPO 的训练逻辑,使其适用于语言模型优化。 - 训练过程:
- 生成阶段:语言模型生成文本(如对话回复)。
- 评估阶段:奖励模型对生成的文本打分。
- 优化阶段:PPO 根据奖励信号调整模型参数,使其生成更高分的文本。
4. 偏好学习(Direct Preference Optimization, DPO)
- TRL 还支持 DPO(一种更高效的 RL 替代方案),它直接优化人类偏好数据,无需显式训练奖励模型。
- DPO 训练更稳定,计算成本更低,适用于小规模数据场景。
TRL 的主要应用场景
-
人类偏好对齐(Human Preference Alignment)
- 让模型生成更符合人类价值观的文本(如减少有害内容、提高有用性)。
- 例如:ChatGPT、Claude 等聊天机器人的 RLHF(RL from Human Feedback)训练。
-
任务优化(Task-Specific Optimization)
- 优化模型在特定任务上的表现(如摘要、问答、代码生成等)。
- 例如:让模型生成更简洁的摘要或更准确的代码补全。
-
可控文本生成(Controlled Generation)
- 通过 RL 训练使模型遵循特定风格或约束(如正式/非正式语气、特定主题等)。
TRL 的使用示例
1. 安装
pip install trl transformers datasets
2. PPO 训练示例
from trl import PPOTrainer, PPOConfig
from transformers import AutoModelForCausalLM, AutoTokenizer
# 加载预训练模型和 tokenizer
model = AutoModelForCausalLM.from_pretrained("gpt2")
tokenizer = AutoTokenizer.from_pretrained("gpt2")
# 初始化 PPO 训练器
ppo_config = PPOConfig(batch_size=32)
ppo_trainer = PPOTrainer(ppo_config, model, tokenizer)
# 模拟训练循环
for epoch in range(10):
# 生成文本
queries = ["Explain RLHF in simple terms."] * 32
responses = ppo_trainer.generate(queries)
# 计算奖励(假设 reward_model 已定义)
rewards = [reward_model(response) for response in responses]
# PPO 优化
ppo_trainer.step(queries, responses, rewards)
3. DPO 训练示例
from trl import DPOTrainer
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("gpt2")
trainer = DPOTrainer(
model,
train_dataset=dataset, # 包含偏好数据(chosen/rejected pairs)
beta=0.1, # 控制 KL 散度权重
)
trainer.train()
TRL 的优势
✅ 与 Hugging Face 生态无缝集成(兼容 transformers、datasets 等库)
✅ 支持多种 RL 训练方式(PPO、DPO)
✅ 适用于不同规模模型(从 GPT-2 到 LLaMA、Mistral 等)
✅ 简化 RLHF 训练流程(减少手动实现 PPO 的复杂度)
总结
TRL 是一个强大的工具,特别适合希望用强化学习优化语言模型的开发者。它降低了 RLHF 的训练门槛,使研究人员和工程师能够更高效地实现:
- 人类偏好对齐(如 ChatGPT 风格优化)
- 任务性能提升(如摘要、问答等)
- 可控文本生成(如风格控制)
如果正在尝试 RLHF 或 DPO,TRL 是一个值得尝试的库!🚀
实际案例
《0元!使用魔搭免费算力,基于Qwen基座模型,复现DeepSeek-R1》