可视化单词统计词频统计中文分词
- 项目架构
- 新建文件
- 单词计数
- 全文单词索引
- 中文分词统计词频
- 源代码
项目架构
新建一个文件,输入文件的内容,查询此文件中关键字的出现的次数,关键字出现的位置,将所有的文本按照中文分词的词库进行切割划分,返回JSON字符串,返回中文切分的单词和出现的频次,最后关闭程序
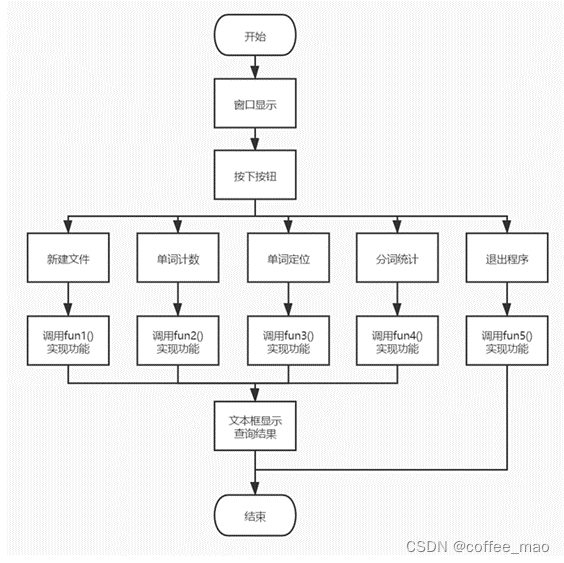
新建文件
新建指定文本文件,输入一个文件名,以及里面的文件内容建立一个文本文件。通过GUI的Entry控件实现一个文本框text1,作用是用来接收用户输入的文件名。
content1用来存储文件名,如果输入的文件名为空就弹出窗体显示“文件名不为空!”的提示,content2用来存储文件内容文件名有效则通过open()函数以读文件的方式打开文件。
然后使用write()将输入的文件内容写入新建好的文件中,点击新建文件按钮,弹出提示框“文件建立成功”,完成后close关闭文件。

输入文件名,输入一段内容,点击新建文件,成功建立文件

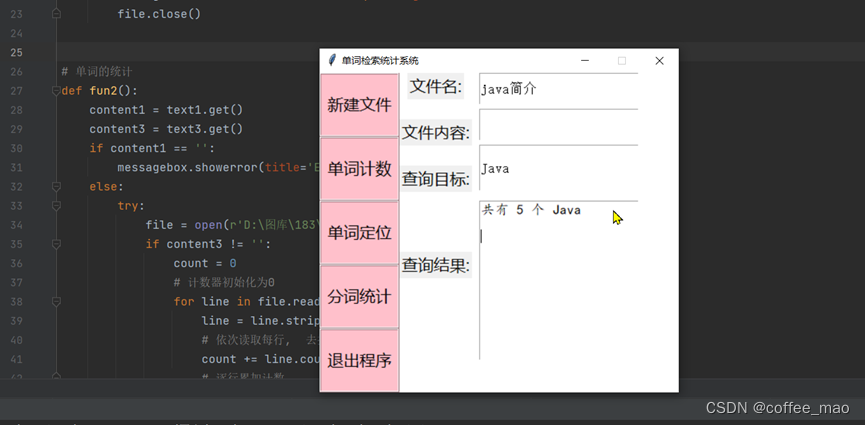
单词计数
给定单词计数,输入一个不含空格的单词,统计输出该单词在文本中的出现次数。通过GUI的Entry控件实现一个文本框text1,作用是用来接收用户输入的文件名。content1用来存储文件名,如果输入的文件名为空就弹出窗体显示“文件名不为空!”的提示。
文件名有效则通过open()函数以读文件的方式打开文件。Entry控件实现一个文本框text3,作用是用来接收用户输入要查询的目标单词,count = 0 将计数器初始化为0。
利用了模式匹配算法:循环读入文件,每次读入一行,逐行扫描文本文件,利用strip()去掉每行头尾空白字符,一行调用count(keyword)函数匹配到目标单词返回目标单词出现的次数count函数封装了字符串匹配,目标串P的长度为m,主串T的长度是n,枚举主串T中每一个位置i, 然后检查T[i,i+m-1]是否与目标串P完全相同,相同的就将count加一,i加一,继续往后匹配子串。
如果不同,就只将i加一,继续往后匹配子串。直到整行结束。存储下当前行目标单词出现的次数,再遍历下一行。直到整个文件扫描结束;然后输出文件中单词出现的总次数。并且关闭文件。
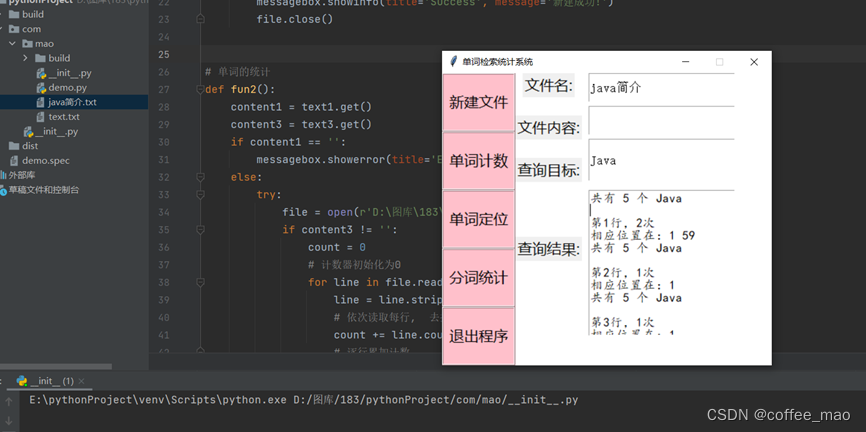
全文单词索引
查找给定单词在文件中的位置。定义content1接收text1的值,content3接收text3的值,content1用来接收用户输入的文件名,如果输入文件名为空就弹出窗体显示“文件名不能为空!”的提示。
文件名有效则通过open()函数以读文件的方式打开文件,content3用来接收用户所输入需查询的单词;使用for循环逐行进行检索,先判断输入文件名是否为空,为空则弹出错误对话框,并提示“文件名不能为空!”。
不为空则使用open()打开文件,row初始化为1,再判断文件内容是否为空,为空则row+1且跳出此层循环,不为空则使用for循环检索出用户指定单词的位置与出现次数并输出第x行n次。
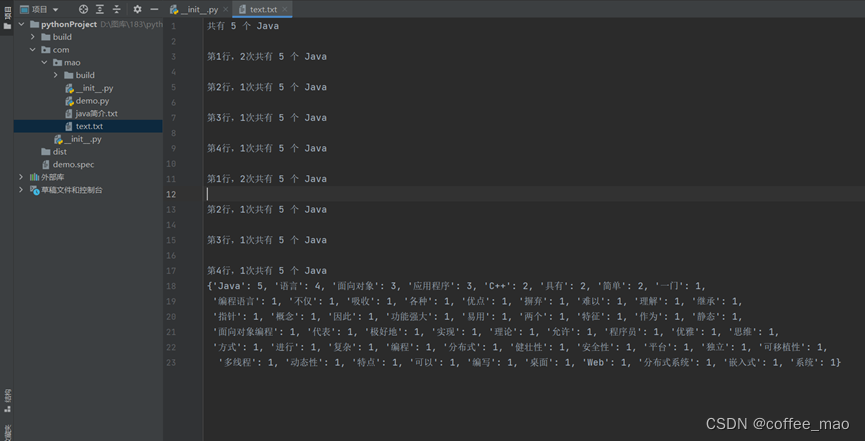
中文分词统计词频
导入jieba第三方中文分词函数库,lcut(text),精确模式,返回text分词后的列表变量使用函数lcut()进行文本处理时,英文文本的分词只需要通过空格就可以分割。而中文的文本是需要一个“词典”来实现分词jieba第三方库实现了“词典” 采取了精确模式,试图将句子最精确地切开。
words = jieba.lcut(text)将文本的分词实现切分后,返回一个分词的列表words定义counts 的空字典循环遍历分词列表,分词的长度为1 就继续遍历,否则就进行统计分词出现的次数。每一个分词作为字典中的键,出现的次数作为字典中的值counts[word] = counts.get(word, 0) + 1键值的添加,获得文件中相同字符出现的次数有word这个分词时,时返回其值,默认是0,+1能够累计次数;没有word时则返回0。
counts.items()字典键值对,list()转化为列表赋值给items,列表items进行按照键从小到大的顺序进行排序,在dict转化为字典输出,输出后关闭文件。

最后将查询的所有结果都追加到输出文件中
源代码
import tkinter as tk
from tkinter import messagebox, END, RIDGE
import jieba
root = tk.Tk()
root.title("单词检索统计系统")
root.resizable(False, False)
root.geometry('450x400')
root.configure(bg='white')
# 新建文件
def fun1():
content1 = text1.get()
content2 = text2.get('1.0', END)
if content1 == '':
messagebox.showerror(title='Error', message='文件名不为空!')
else:
file = open(r'D:\图库\183\pythonProject\com\mao\\' + content1 + '.txt', 'w', encoding='GBK')
file.writelines(content2)
file.write('\n')
messagebox.showinfo(title='Success', message='新建成功!')
file.close()
# 单词的统计
def fun2():
content1 = text1.get()
content3 = text3.get()
if content1 == '':
messagebox.showerror(title='Error', message='文件名不为空!')
else:
try:
file = open(r'D:\图库\183\pythonProject\com\mao\\' + content1 + '.txt', 'r')
if content3 != '':
count = 0
# 计数器初始化为0
for line in file.readlines():
line = line.strip()
# 依次读取每行, 去掉每行头尾空白
count += line.count(content3)
# 逐行累加计数
if count == 0:
messagebox.showerror(title='Error', message='没有此单词!')
else:
text4.insert(tk.END, '共有 ' + str(count) + ' 个 ' + content3 + '\n')
with open(r"D:\图库\183\pythonProject\com\mao\text.txt", "a") as output:
output.write('共有 ' + str(count) + ' 个 ' + content3 + '\n')
file.close()
else:
messagebox.showerror(title='Error', message='查询目标单词不为空!')
except Exception as e:
messagebox.showerror(title='Error', message=e)
# 单词的定位
def fun3():
content1 = text1.get()
content3 = text3.get()
if content1 == '':
messagebox.showerror(title='Error', message='文件名不为空!')
else:
try:
file = open(r'D:\图库\183\pythonProject\com\mao\\' + content1 + '.txt', 'r')
row = 1
# 行初始化为1
for line in file.readlines():
# 检索每一行
if content3 == '':
messagebox.showerror(title='Error', message='查询目标单词不为空!')
break
else:
if line.count(content3):
# 每一行目标单词出现的次数
text4.insert(tk.END, '\n第' + str(row) + '行,' + str(line.count(content3)) + '次')
with open(r"D:\图库\183\pythonProject\com\mao\text.txt", "a") as output:
output.write('\n第' + str(row) + '行,' + str(line.count(content3)) + '次')
index_list = []
# 建立索引列表
index = line.find(content3)
# 找到单词所在的位置:索引号
while index != -1:
# 判断索引是否结束,并将查找到的索引号添加到索引列表中
index_list.append(index)
index = line.find(content3, index + 1)
# 下标下一位开始,找到word之后添加到列表中
text4.insert(tk.END, '\n相应位置在:')
for index in index_list:
# 遍历索引列表并输出
text4.insert(tk.END, str(index + 1) + ' ')
text4.insert(tk.END, '\n')
row += 1
else:
# 无法查询到单词,没有目标单词的行输出此行没有找到,进入下一行继续查找
row += 1
continue
fun2()
except Exception as e:
messagebox.showerror(title='Error', message=e)
# 分词统计
def sign4():
content1 = text1.get()
def read(path):
if path == '':
messagebox.showerror(title='Error', message='文件名不为空!')
else:
try:
text = open(r'D:\图库\183\pythonProject\com\mao\\' + path + '.txt', 'r')
content = text.read()
words = jieba.lcut(content)
counts = {}
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word, 0) + 1
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True)
counts = dict(items)
text4.insert(tk.END, counts)
with open(r"D:\图库\183\pythonProject\com\mao\text.txt", "a") as output:
output.write(str(counts))
text.close()
except Exception as e:
messagebox.showerror(title='Error', message=e)
read(content1)
# 页面布局
button1 = tk.Button(root, text='新建文件', bg='pink', font=('微软雅黑', 15), relief=RIDGE, command=fun1)
button1.place(x=0, y=0, width=100, height=80)
label1 = tk.Label(root, text='文件名:', font=('微软雅黑', 15), )
label1.grid(padx=100)
text1 = tk.Entry(root, font=('MingLiU', 13))
text1.place(x=200, width=200, height=40)
label2 = tk.Label(root, text='文件内容:', font=('微软雅黑', 15))
label2.grid(pady=25)
text2 = tk.Text(root)
text2.place(x=200, y=45, width=200, height=40)
button2 = tk.Button(root, text='单词计数', bg='pink', font=('微软雅黑', 15), relief=RIDGE, command=fun2)
button2.place(x=0, y=80, width=100, height=80)
button3 = tk.Button(root, text='单词定位', bg='pink', font=('微软雅黑', 15), relief=RIDGE, command=fun3)
button3.place(x=0, y=160, width=100, height=80)
button4 = tk.Button(root, text='分词统计', bg='pink', font=('微软雅黑', 15), relief=RIDGE, command=sign4)
button4.place(x=0, y=240, width=100, height=80)
label3 = tk.Label(root, text='查询目标:', font=('微软雅黑', 15))
label3.grid(padx=100)
text3 = tk.Entry(root, font=('MingLiU', 13))
text3.place(x=200, y=90, width=200, height=58)
label4 = tk.Label(root, text='查询结果:', font=('微软雅黑', 15))
label4.grid(pady=75)
text4 = tk.Text(root, font=('楷体', 13))
text4.place(x=200, y=160, width=200, height=200)
button5 = tk.Button(root, text='退出程序', bg='pink', font=('微软雅黑', 15), relief=RIDGE, command=root.destroy)
button5.place(x=0, y=320, width=100, height=80)
root.mainloop()







![[附源码]Python计算机毕业设计Django大学生心理健康测评系统](https://img-blog.csdnimg.cn/af1d473e76f342d1bbc88f0cf1b235f9.png)