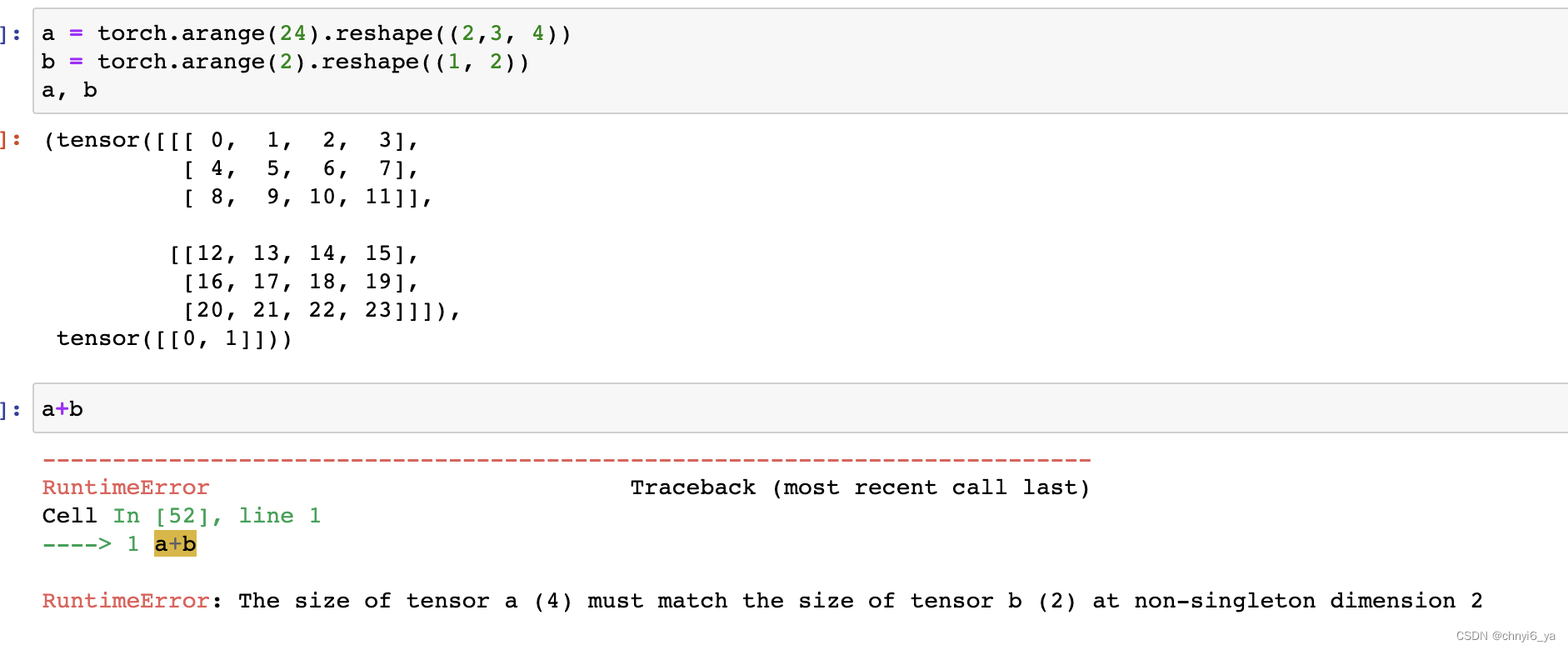
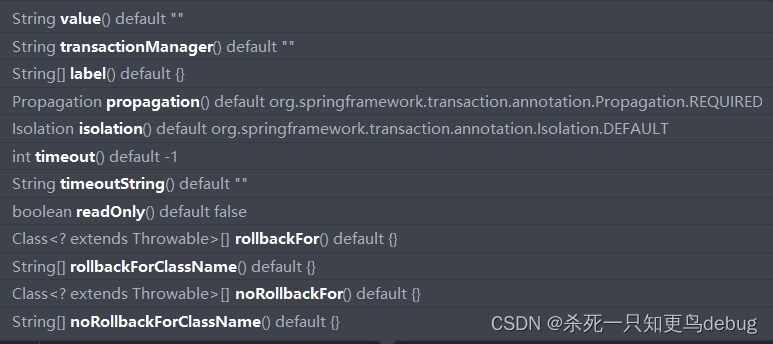
数据集
fooball球员在场上的位置
数据来自国际足联的视频游戏FIFA 。游戏的特点是在游戏的各个方面评价每个球员的能力。等级是量化变量(介于0和100之间),但我们将它们转换为分类变量。所有能力都被编码在4个等级:1.低/ 2.平均/ 3.高/ 4.非常高。最近我们被客户要求撰写关于多重对应分析(MCA)的研究报告,包括一些图形和统计输出。
加载和准备数据
首先将数据集加载到data.frame中。
第二行也将整数列转换为因子。
数据分析
我们的数据集包含分类变量。适当的数据分析方法是多重对应分析。
产生了三个图:类别和球员在坐标轴上的投影,以及变量的图形。
这里显然有两个球员集群。
解释
显然,我们必须先将分析减少到一定数量的维度。选择变量数量的方法是肘法。我们绘制特征值的图形:
> barplot(mca_no_gk $ eig $ eigenvalue)特征值图
围绕第三或第四个特征值,我们观察到一个值的下降(这是MCA解释的方差的百分比)。因此,我们选择将我们的分析减少到前三个因子。
> plot.MCA(mca_no_gk )在前两个因子坐标轴上投影
我们可以通过在图表上读取最有代表性的变量名称来开始分析。
第一因子的最有代表性的能力是:在轴的右侧攻击能力 的能力较弱,左边的能力非常强。因此,我们的解释是,因子1根据他们的进攻能力(左侧更好的攻击能力,右侧更弱)来区分球员。我们对第2因子进行同样的分析,并得出结论:根据他们的防守能力来区分球员:在顶部会发现更好的防守者,而在底部会发现弱防守者。
补充变量也可以帮助确认我们的解释,特别是位置变量:
> plot.MCA(mca_no_gk,invisible = c(“ind”,“var”))在前两个维度上投影补充变量
实际上,我们在图的左边部分发现了攻击位置(LW,ST,RW),并在图顶部看到了防守位置(CB,LB,RB)。
如果我们的解释是正确的,那么图表中第二个维度上的投影就可以代表球员的整体水平。最强的球员将会在左上角找到,而较弱的将会在右下角找到。“overall_4”位于左上角,“overall_1”位于右下角。此外,在补充变量的图表中,我们观察到“法甲联赛第一”(Ligue 1)位于左上方,而“Ligue 2”位于右下方。
> plot.MCA(mca_no_gk,invisible = c(“ind”,“var”),axes = c(2,3))
在第二和第三维度上投影变量
最具代表性的第三维度是技术上的弱点:技术能力较低的球员(运球,控球等)位于坐标轴的末端,而这些能力中成绩最高的球员往往被发现在坐标轴的中心:
在第二和第三因子坐标轴上投影补充变量
在补充变量的帮助下,中场平均拥有最高的技术能力,而前锋(ST)和后卫(CB,LB,RB)似乎一般都不以球控技术着称。
参考Mathieu Valbuena在坐标轴1和坐标轴2上生成的图形:
1和2因子坐标轴补充变量
第2和3因子坐标轴
所以,马蒂厄·瓦尔布纳似乎有很好的进攻技巧,但他也有很好的整体水平(他在第二因子上的投射比较高)。他也位于第三坐标轴的中心,这表示他具有良好的技术能力。因此,最适合他的位置(统计上)是中场位置(CAM,LM,RM)。再加上几行代码,我们可以找到法国联赛中最相似的球员:
我们得到:Ladislas Douniama,FrédéricSammaritano,Florian Thauvin,N'GoloKanté和Wissam Ben Yedder。





![[附源码]Python计算机毕业设计Django大学生心理健康测评系统](https://img-blog.csdnimg.cn/af1d473e76f342d1bbc88f0cf1b235f9.png)