📫作者简介:小明java问道之路,专注于研究 Java/ Liunx内核/ C++及汇编/计算机底层原理/源码,就职于大型金融公司后端高级工程师,擅长交易领域的高安全/可用/并发/性能的架构设计与演进、系统优化与稳定性建设。
📫 热衷分享,喜欢原创~ 关注我会给你带来一些不一样的认知和成长。
🏆 InfoQ签约作者、CSDN专家博主/后端领域优质创作者/内容合伙人、阿里云专家/签约博主、51CTO专家 🏆
🔥如果此文还不错的话,还请👍关注、点赞、收藏三连支持👍一下博主~
本文目录
本文导读
一、容灾级别
二、同城多活——一地三中心
1、同城多活原理
2、一地三机房架构
三、两地三中心
四、三地五中心
五、数据兜底核对(数据轧差)
1、业务数据轧差
2、DBA数据核对
总结
本文导读
我们在实际生产环境中,要求不允许丢失任何数据。也就是说,当MySQL数据库由于各种原因而无法使用时(发生宕机、网络异常等),不仅需要快速恢复业务,还需要确保数据一致性。
本文主要讲解数据库机房架构与跨城容灾,包括主从复制的强一致性、同城多活、两地三中心、三地五中心、数据兜底逻辑等进行逐步讲解。
一、容灾级别
高可用性用于处理各种停机问题,停机时间可分为服务器停机、机房停机,甚至城市停机。
机房级宕机:例如机房光纤被阻断、切断,机房整体停电、主备或双备用电源也不可用;
城市级宕机:一般指整个城市的进出口网络和骨干交换机发生故障(这种故障的概率很小)。
如果我们综合考虑,高可用性将成为一种灾难恢复机制,相应的高可用性体系结构的评估标准将提高。主要有三种方案:机房容灾、同城容灾、多地容灾
机房容灾:机房内的数据库服务器不可用,因此切换到同一机房的数据库服务器,以确保业务连续性;
同城容灾:机房不可用,切换本地机房数据库服务器,确保业务连续性;
多地容灾:单个城市的机房整体不可用。切换到跨城市机房的数据库实例以确保业务连续性。
二、同城多活——一地三中心
1、同城多活原理
前面我们谈到的高可用设计,都只是机房内的容灾。详情请参考《MySQL参数调优与实战详解》、《MySQL复制原理与主备一致性同步工作原理解析》、《MySQL复制与高可用水平扩展架构实战》、《MySQL日志系统以及InnoDB背后的技术》
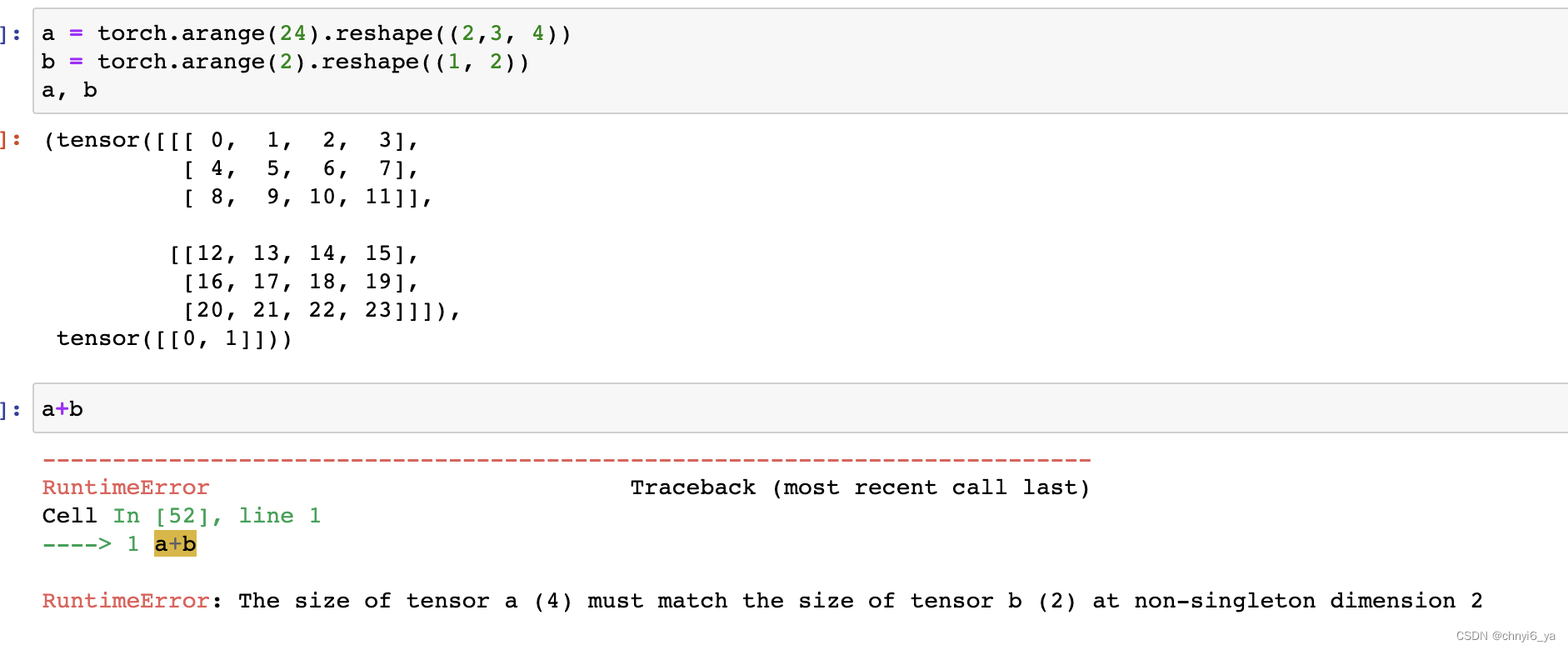
本文主要是同城和跨城的容灾设计,事实上,同城双服务器(同城双活)热备系统与上述文章中双服务器热备用系统没有本质区别,但物理距离要远得多,同城专用网速仍然很快。
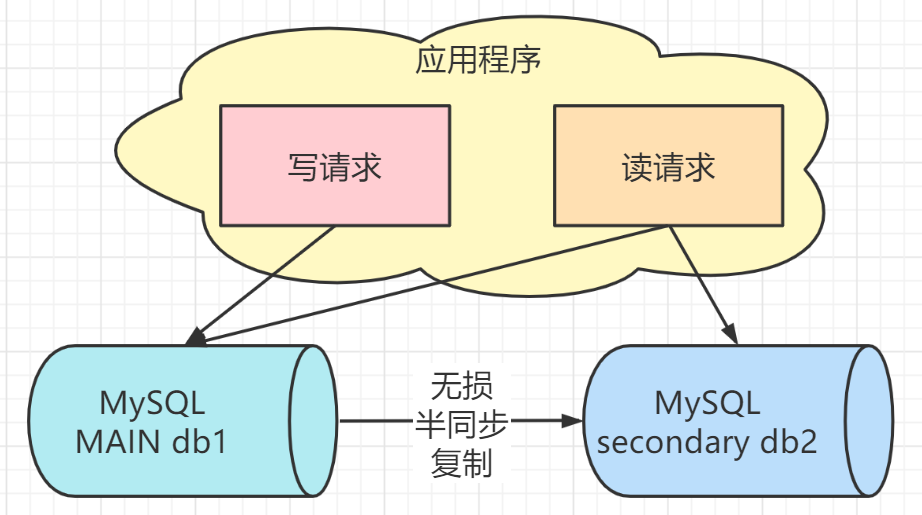
双机热备份提供灾难恢复能力,双机互备份避免了过度的资源浪费。
这种设计没有考虑到机房网络的抖动,如果机房1和机房2之间的网络抖动,则事务提交需要从机房2中的服务器接收日志,因此事务提交将被挂起。同时机房网络抖动非常普遍,因此同城灾备核心业务应采用多活架构。如下图所示:

这种架构如果三个机房位于一个城市,则称为“一地三中心”。如果它们位于两个相邻的城市,则称为“两地三中心”。然而,这种同城/同大区灾难恢复要求机房网络之间的延迟不应超过5ms。
数据的副本存储在三个机房中,这里,MySQL的 rpl_semi_sync_master_wait_for_slave_count 半同步复制参数,如果count设置为1,则只要一台半同步备用计算机接收到日志,就可以提交主服务器上的事务。
这种设计确保了除主机房外,其他机房中的数据至少是一个完整的数据。
这样即使机房1和机房2之间存在网络抖动,因为机房1与机房3之间的网络非常好,因此不会影响主服务器上事务的提交。
如果机房1的出口开关或光纤发生故障,那么可以将故障转移到机房2或机房3,因为至少有一条数据是完整的。
2、一地三机房架构
机房2和机房3中的数据用于确保数据一致性,但是,如果要实现读/写分离或备份,则需要为异步复制引入备用节点。因此,生产环境中整体结构如下:

从图中可以看出,我们添加了两个异步复制节点来分离业务的读写。此外,我们还引入了一个延迟备用机,用于从机房3中的备用机进行异步复制,以从数据删除错误中恢复。由于机房1中的主服务器向四个从属服务器发送日志,因此网卡可能会成为瓶颈,一般需要万兆网卡。
三、两地三中心
只需在两城三中心,通过不同城市设置三个机房,当主服务器停机时,数据库将切换到跨城市,跨城市之间的网络延迟超过25ms。
四、三地五中心
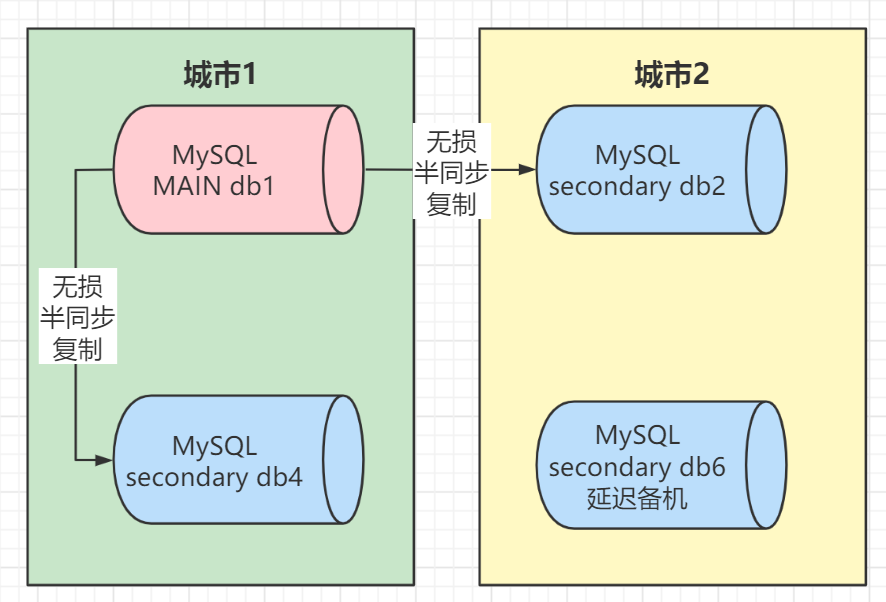
跨城灾难恢复一般设计为“三地五中心”架构,如下图所示:
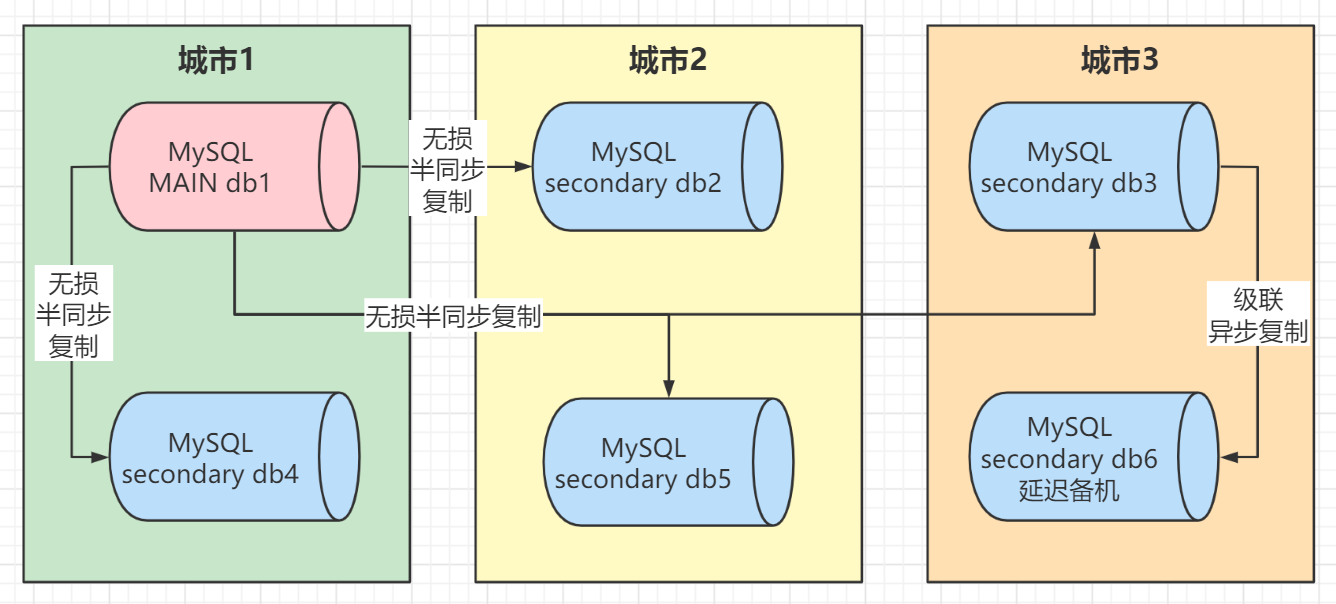
如上图所示,机房1和机房4位于城市1;机房2和机房5位于城市2;机房3位于3号城市,三个城市之间的距离超过200公里,一般允许延迟超过25毫秒。由于有五个机房,ACK设置为2,以确保至少一条数据在两个机房中具有数据。这样,当城市级故障发生时,城市2或城市3中至少有一个完整的数据。
同时,跨城市灾难恢复通常基于同城灾难恢复架构,每个中心都是多活中心。
五、数据兜底核对(数据轧差)
1、业务数据轧差
除了高可用性的灾难恢复架构设计之外,我们还需要做一层底层服务来判断数据的一致性。这里引入数据检查来解决,数据在业务逻辑上是一致的,该担保业务是正确的。
一般使用的方式就是 业务团队 进行异步对账。
例如:1、订单数据与清结算数据进行数据对平(一般为支付金额、优惠金额,结算金额等等);2、扣减库存的数据与下单数据进行数据对平(库存消耗是否等于订单明细);3、发券数据是否超过使用的优惠金额;4、当日正向交易金额与反向(退款)交易金额对比;5、待发货、已发货、已收货是否等于交易总数,等等……
2、DBA数据核对
主服务器和从服务器之间的数据是一致的,确保了从属服务器的数据是安全和可访问的。
一般由 数据库团队(DBA) 负责。
通过主从验证服务以确保主从数据的一致性,此检查不依赖于副本,但也是逻辑检查。检查最近一段时间内主服务器和从服务器上更改的记录,以从逻辑上验证它们是否一致。
通过表 last_modify_date 记录每个记录的最后修改时间。通过根据此条件进行筛选,找到最近更新的记录,然后比较每个记录。同时扫描最新的二进制日志,过滤出最近更新的表和主键,然后检查数据。
总结
我们在实际生产环境中,要求不允许丢失任何数据。也就是说,当MySQL数据库由于各种原因而无法使用时(发生宕机、网络异常等),不仅需要快速恢复业务,还需要确保数据一致性。
前面我们谈到的高可用设计,都只是机房内的容灾。详情请参考《MySQL参数调优与实战详解》、《MySQL复制原理与主备一致性同步工作原理解析》、《MySQL复制与高可用水平扩展架构实战》、《MySQL日志系统以及InnoDB背后的技术》。
本文主要讲解数据库机房架构与跨城容灾,包括主从复制的强一致性、同城多活、两地三中心、三地五中心、数据兜底逻辑等进行逐步讲解。



![[附源码]Python计算机毕业设计Django大学生心理健康测评系统](https://img-blog.csdnimg.cn/af1d473e76f342d1bbc88f0cf1b235f9.png)