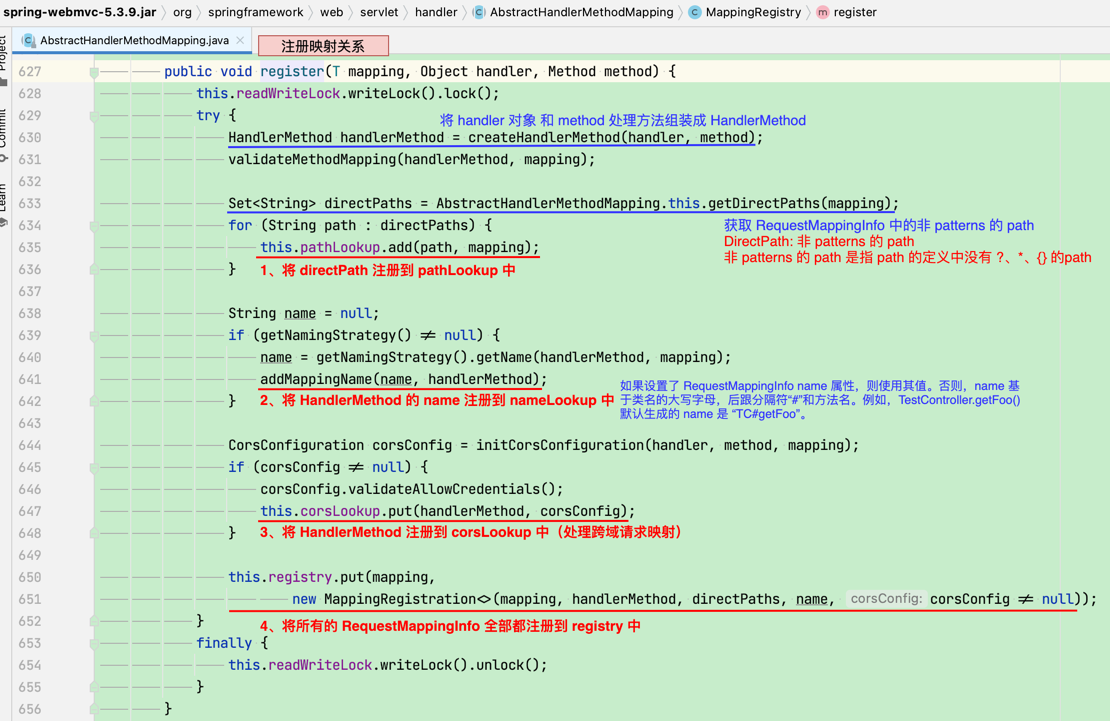
1. re.findall()
re.findall():函数返回包含所有匹配项的列表。返回string中所有与pattern相匹配的全部字串,返回形式为list / 数组。
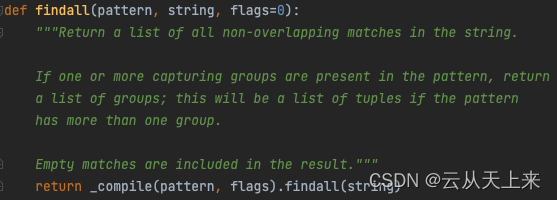
由函数原型代码可知,findall() 函数存在三个参数:
1. pattern:正则表达式中的 ‘模式字符串’ ;
2. string:当前需要处理(查找替换)的原始字符串;
3. flags:可选参数,表示编译时用的匹配模式(如忽略大小写、多行模式等),数字形式,默认为0
# 示例代码
import re
text1 = '北京市海淀区不存在的38街区不想工作大厦99号'
res = re.findall(r'\d+', text1)
print(type(res))
print(res)
# output
# <class 'list'>
# ['38', '99']2. re.sub()
re.sub():函数将所有匹配项,替换为选择的文本,并返回结果。
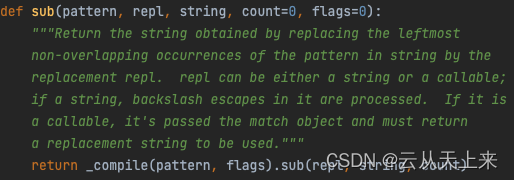
由函数原型代码可知,re.sub() 函数存在五个参数:
1. pattern:正则表达式中的 ‘模式字符串’ ;
2. repl:需要被替换成的字符串,即将匹配到的pattern替换为repl;可以是函数;
3. string:当前需要处理(查找替换)的原始字符串;
4. count:可选参数,表示需要替换的最大次数,必须是非负整数;默认值为0,即匹配到的所有子串都进行替换操作;5. flags:可选参数,表示编译时用的匹配模式(如忽略大小写、多行模式等),数字形式,默认为0
# 将所有匹配到的‘数字串’ 替换为 ’520‘
text1 = '北京市海淀区不存在的38街区不想工作大厦99号'
res = re.re(r'\d+', 520)
print(type(res))
print(res)
# output,返回值res结果是str
# <class 'str'>
# 北京市海淀区不存在的520街区不想工作大厦520号3. set()
set():python内置函数的其中一个,创建一个无序不重复元素集。支持计算交集、差集、并并集。
# 为list数组l1 去重
l1 = [1, 1, 2, 2, 2, 3, 4]
s1 = set(l1)
print(type(s1))
print(s1)
# output,返回类型是 set
# <class 'set'>
# {1, 2, 3, 4}# 计算l1 和 l2 的交集
l1 = [1, 1, 2, 2, 2, 3, 4]
l2 = [2, 3, 3, 4, 5, 6, 6]
s1 = set(l1)
s2 = set(l2)
u = s1 & s2
print(type(u))
print(u)
# output,返回结果类型set
# <class 'set'>
# {2, 3, 4}# 计算l1 和 l2 的并集, 并集符号 ‘|’,intersection
l1 = [1, 1, 2, 2, 2, 3, 4]
l2 = [2, 3, 3, 4, 5, 6, 6]
s1 = set(l1) # {1, 2, 3, 4}
s2 = set(l2) # {2, 3, 4, 5, 6}
u = s1 | s2
print(type(u))
print(u)
# output,返回结果类型set, 计算 {1, 2, 3, 4} 和 {2, 3, 4, 5, 6} 的并集
# <class 'set'>
# {1, 2, 3, 4, 5, 6}# 计算差集,diff
l1 = [1, 1, 2, 2, 2, 3, 4]
l2 = [2, 3, 3, 4, 5, 6, 6]
s1 = set(l1) # {1, 2, 3, 4}
s2 = set(l2) # {2, 3, 4, 5, 6}
print(s2)
u = s1 - s2
print(type(u))
print(u)
# output,返回结果是set
# <class 'set'>
# {1}# set内也可以传入字符串,会自动转换成list类型
text1 = '北京市海淀区海淀区不想上班不想上班'
res = set(text1)
print(res) # 内部元素是一个个的字,去重 且 无序
# output
# <class 'set'>
# {'上', '北', '班', '海', '淀', '京', '不', '想', '区', '市'}