网络爬虫—照片管道
- Scrapy基础
- Scrapy运行流程原理
- Scrapy的工作流程
- scrapy照片管道
- 实战演示
- 设置图片路径
- 配置爬虫
- 解析数据
- 运行爬虫
- 查看文件
- 后记
前言:
🏘️🏘️个人简介:以山河作礼。
🎖️🎖️:Python领域新星创作者,CSDN实力新星认证
📝📝第一篇文章《1.认识网络爬虫》获得全站热榜第一,python领域热榜第一。
🧾 🧾第四篇文章《4.网络爬虫—Post请求(实战演示)》全站热榜第八。
🧾 🧾第八篇文章《8.网络爬虫—正则表达式RE实战》全站热榜第十二。
🧾 🧾第十篇文章《10.网络爬虫—MongoDB详讲与实战》全站热榜第八,领域热榜第二
🧾 🧾第十三篇文章《13.网络爬虫—多进程详讲(实战演示)》全站热榜第十二。
🧾 🧾第十四篇文章《14.网络爬虫—selenium详讲》测试领域热榜第二十。
🧾 🧾第十六篇文章《网络爬虫—字体反爬(实战演示)》全站热榜第二十五。
🎁🎁《Python网络爬虫》专栏累计发表十八篇文章,上榜七篇。欢迎免费订阅!欢迎大家一起学习,一起成长!!
💕💕悲索之人烈焰加身,堕落者不可饶恕。永恒燃烧的羽翼,带我脱离凡间的沉沦。
Scrapy基础
🧾 🧾Scrapy是一个用于爬取网站数据和提取结构化数据的Python应用程序框架。Scrapy的设计是用于Web爬虫,也可以用于提取数据和自动化测试。
Scrapy提供了一个内置的HTTP请求处理器,可以通过编写自定义的中间件来扩展其功能。Scrapy使用Twisted事件驱动框架,可以同时处理数千个并发请求。
🧾 Scrapy的主要组件包括:
ScrapyEngine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。Scheduler(调度器):它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到Responses交还给ScrapyEngine(引擎),由引擎交给Spider来处理。Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。Downloader Middlewares(下载中间件):一个可以自定义扩展下载功能的组件。Spider Middlewares(Spider中间件):一个可以自定扩展和操作引擎和Spider中间通信的功能组件。
Scrapy运行流程原理
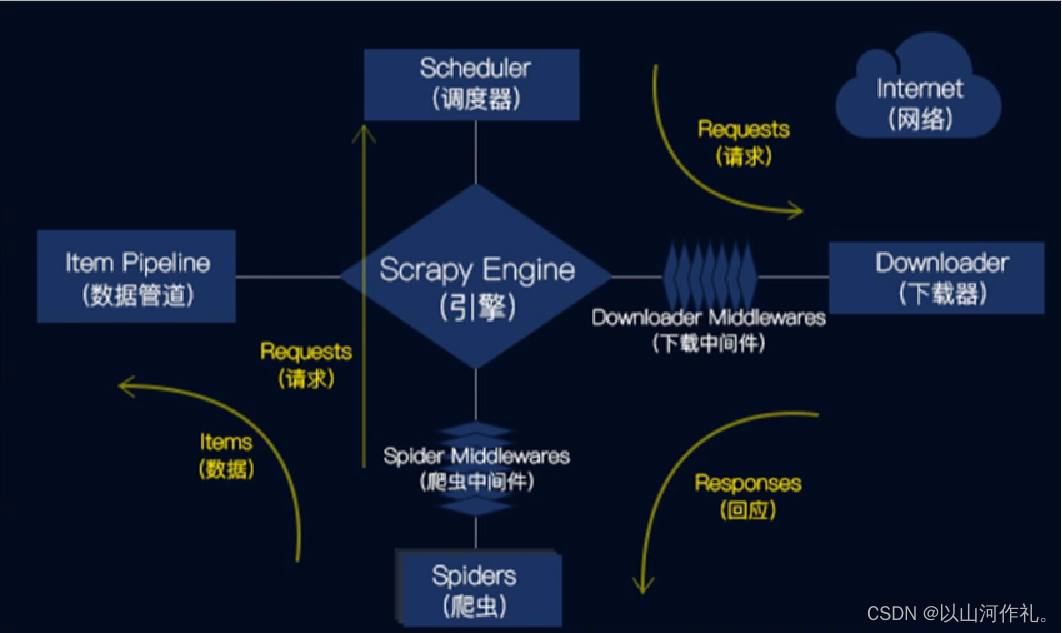
Scrapy的工作流程
1.引擎从爬虫的起始URL开始,发送请求至调度器。
2.调度器将请求放入队列中,并等待下载器处理。
3.下载器将请求发送给网站服务器,并下载网页内容。
4.下载器将下载的网页内容返回给引擎。
5.引擎将下载的网页内容发送给爬虫进行解析。
6.爬虫解析网页内容,并提取需要的数据。
7.管道将爬虫提取的数据进行处理,并保存到本地文件或数据库中。
scrapy照片管道
Scrapy是一个Python编写的高效的Web抓取框架,主要用于抓取网站信息并将其存储到数据库或其他存储介质中。Scrapy框架中有一个强大的下载器管道系统,可以通过编写自定义管道来处理下载的网页内容。
下面是一个简单的Scrapy照片管道的实现代码示例:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
class PhotoPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for image_url in item['image_urls']:
yield scrapy.Request(image_url)
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
item['image_paths'] = image_paths
return item
这个照片管道是通过重写Scrapy自带的ImagesPipeline类实现的。首先,我们重写了get_media_requests()方法,用于将每个待下载照片的URL构造成一个请求对象,交由Scrapy下载器下载照片。接着,我们重写了item_completed()方法,用于处理下载完成的照片并将其存储到本地磁盘,最后返回照片的本地文件路径。
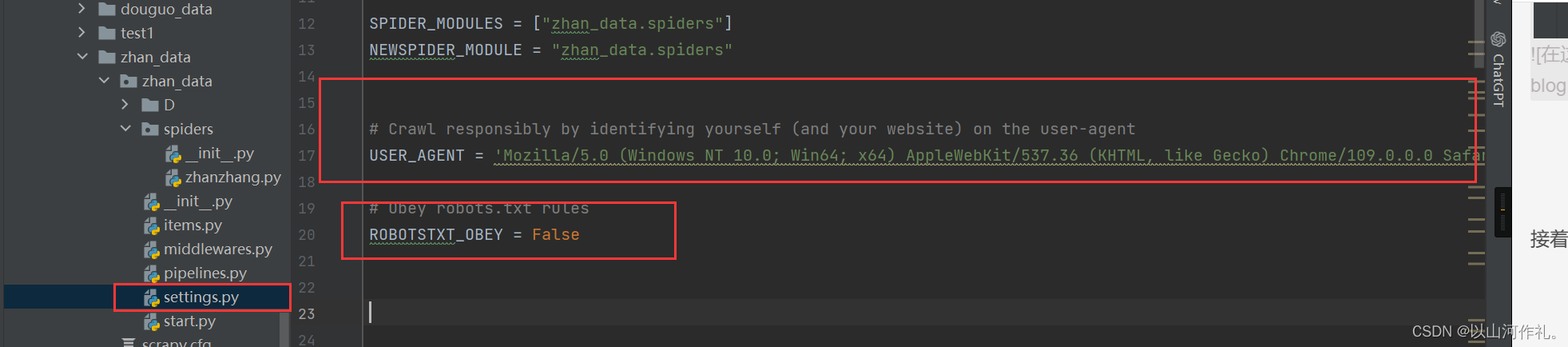
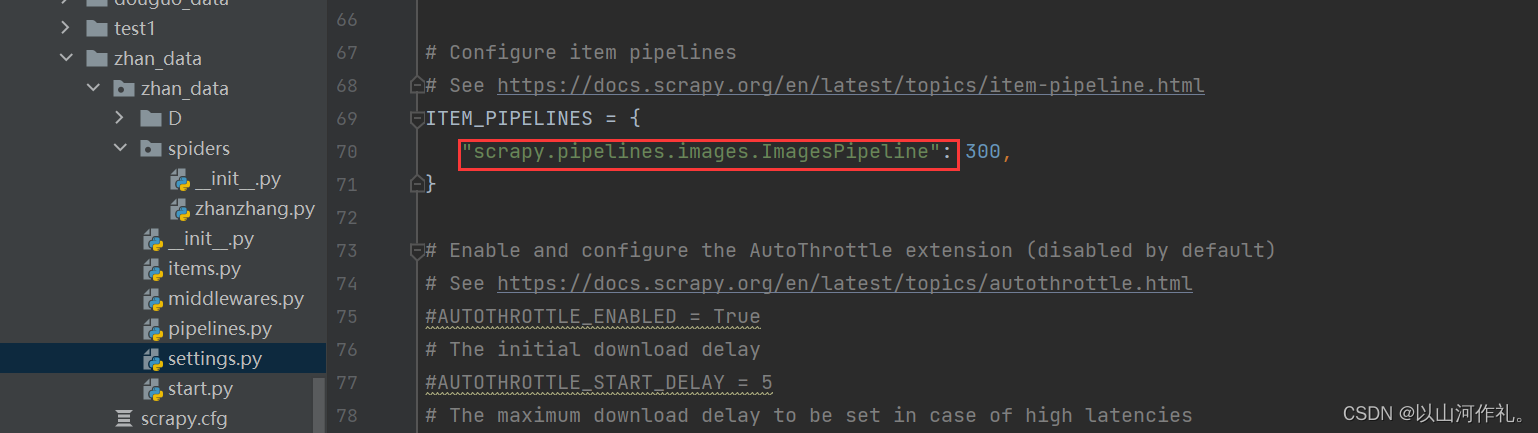
在运行Scrapy时,我们需要在settings.py文件中添加以下配置:
ITEM_PIPELINES = {'my_project_name.pipelines.PhotoPipeline': 1}
IMAGES_STORE = 'path_to_save_images'
其中,my_project_name.pipelines是指我们自定义的管道所在的模块和文件名,path_to_save_images是指下载的照片保存的本地路径。在运行时,Scrapy框架会自动调用我们编写的照片管道,并将下载的照片保存到指定的本地路径中。
实战演示
🎯我们本次实战目的是爬取站长素材的风景照片
🎯按照之前我们学过的流程,先创建项目,接着创建爬虫。如果有不会的可以看我之前的文章帮助理解学习。《网络爬虫—Scrapy入门与实战》
设置图片路径
setting.py 中添加存储路径的变量
IMAGES_STORE = 'D:\\img\\'
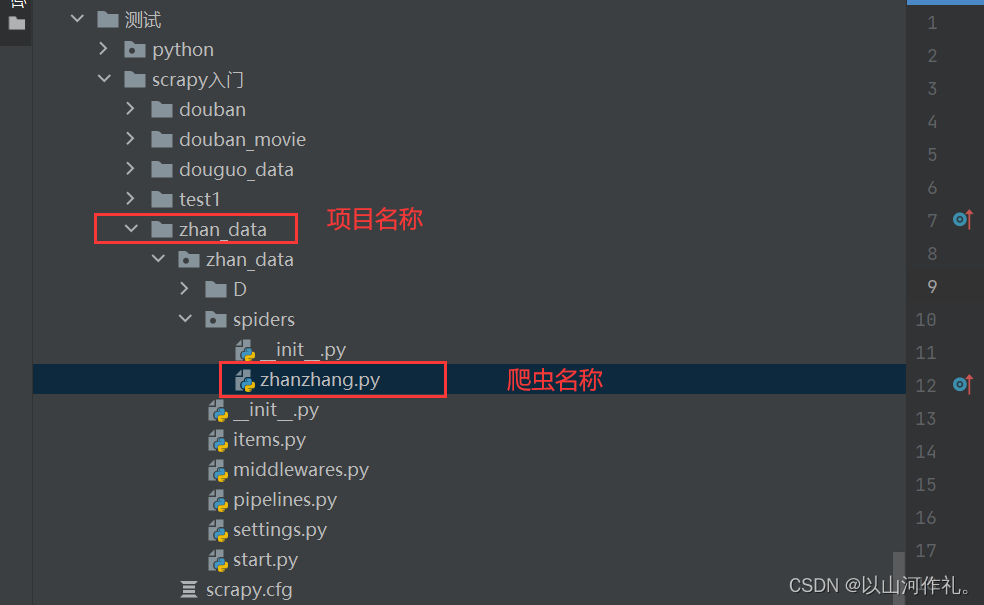
配置爬虫
🎯接着我们来配置爬虫

解析数据
🎯接着我们对爬取的数据进行解析,拿到我们需要的照片的url:
def parse(self, response, *_):
item = ZhanDataItem()
img_url = response.xpath('//img[@class="lazy"]/@data-original')
item['image_urls'] = ['https:' + url.replace("_s.jpg", ".jpg") for url in img_url.extract()]
首先我们创建了一个
ZhanDataItem对象,用于存储从网页中解析出来的数据。接着,我们使用XPath表达式从网页响应response中提取了所有class属性为"lazy"的图片节点的data-original属性,即该图片的原始URL。这个img_url变量的类型是一个XPath对象,我们需要使用extract()方法将其转换为一个数组。
接着,我们使用一个列表推导式将每个原始URL进行替换和处理,得到最终可以下载的照片URL。具体来说,我们将每个原始URL中的"_s.jpg"替换为".jpg",然后添加"https:"作为协议前缀作为最终的下载链接。最后,我们将生成的照片链接列表赋值给item对象中的
'image_urls'属性,该属性会在后续的Scrapy下载器中被自动处理并下载照片。
🎯我们本次实战使用的是scrapy自带的管道来爬取照片
爬虫中传递的参数名称(必须要是此名称传入,传入一个由多个链接组成的列表对象)
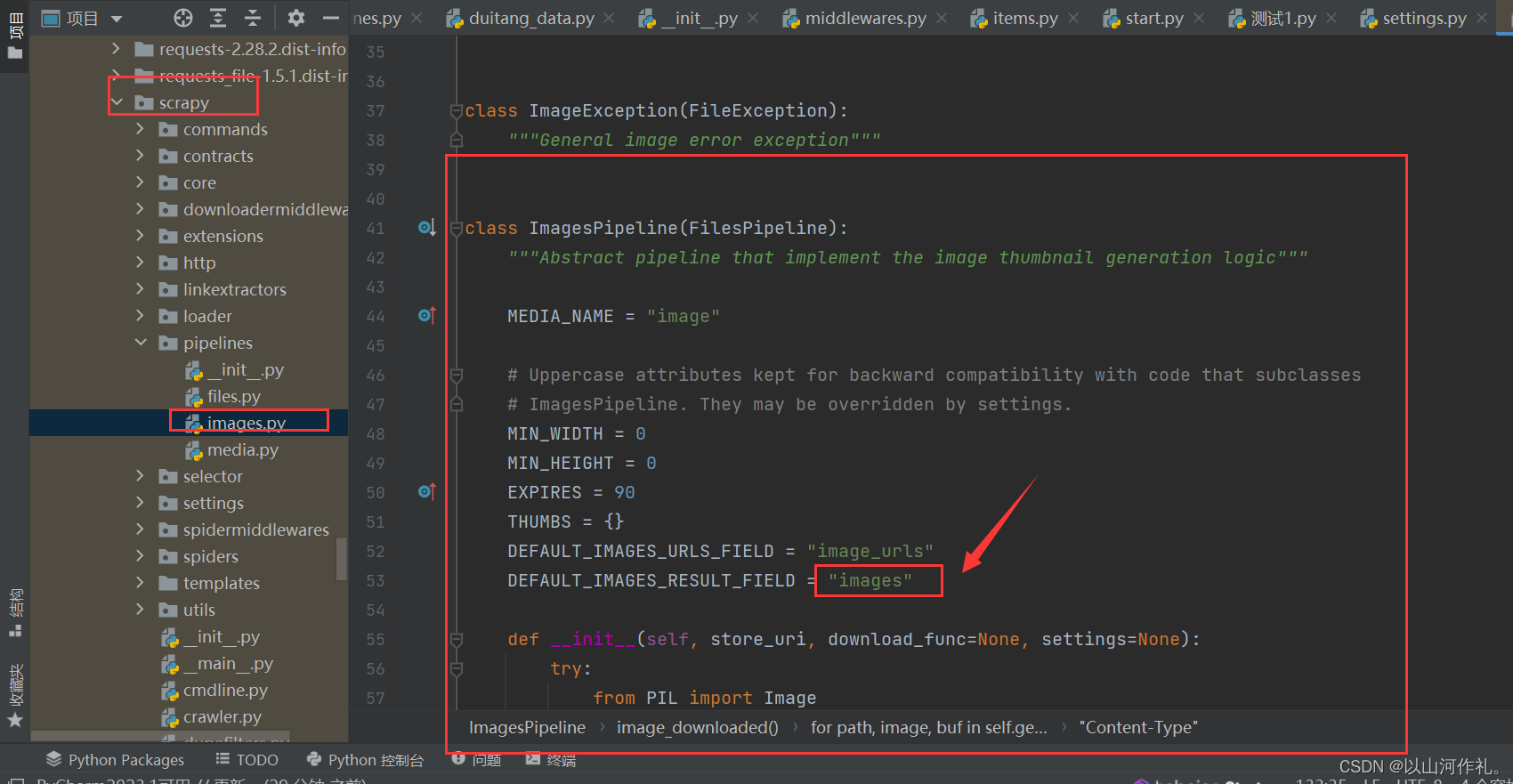
scrapy.pipelines.images.ImagesPipeline 设置中管道需要修改为scrapy管道类
运行爬虫
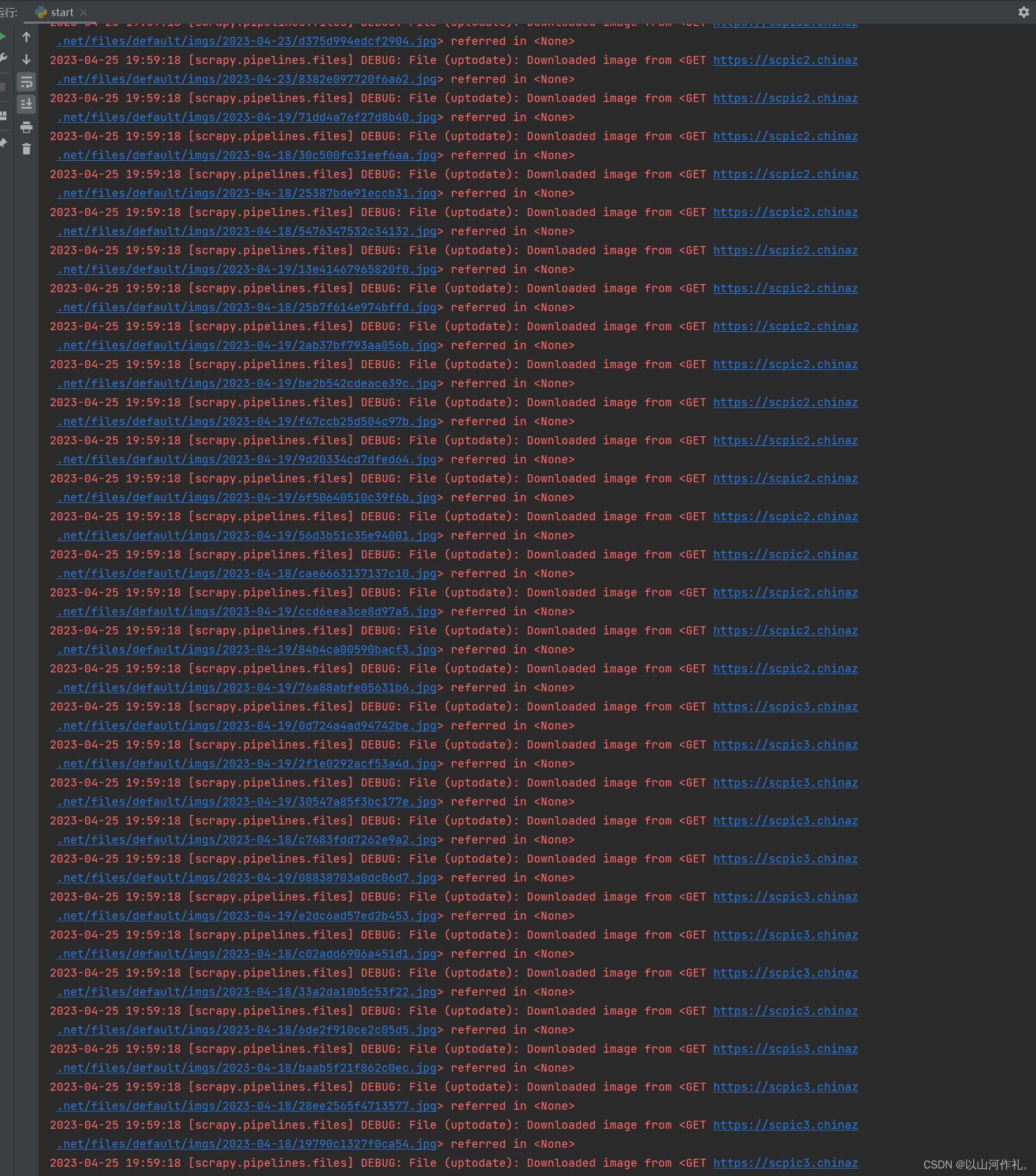
🎯到这里,我们整体算完成了,接下来就可以运行爬虫了。
查看文件
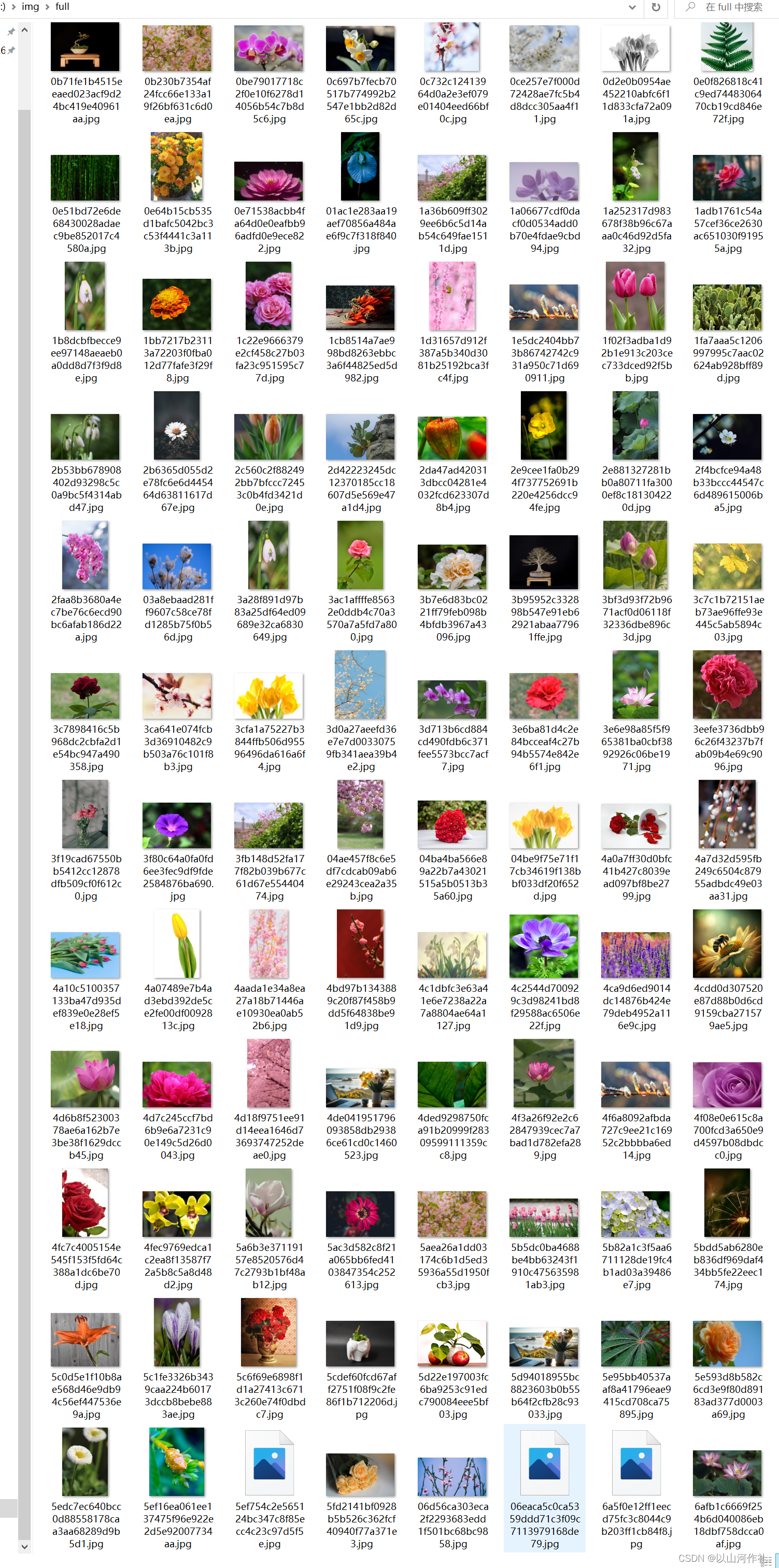
🎯我们来打开文件夹查看一下:
后记
👉👉本专栏所有文章是博主学习笔记,仅供学习使用,爬虫只是一种技术,希望学习过的人能正确使用它。
博主也会定时一周三更爬虫相关技术更大家系统学习,如有问题,可以私信我,没有回,那我可能在上课或者睡觉,写作不易,感谢大家的支持!!🌹🌹🌹