研究现状
现有研究大多通过分别考虑空间相关性和时间相关性或在滑动时间窗口内对这种时空相关性进行建模,而未能对直接的时空相关性进行建模。受最近图领域Transformer成功的启发,该模型提出利用局部多头自关注,在自适应时空图上直接建立跨时空相关性模型。
挑战点
以前的研究者通过将图结构引入时空数据预测模型已经取得了显著进展,但由于时空相关性的复杂性,当前模型仍然面临诸多挑战。
-
首先,在空间图中,一个节点对另一个节点的影响可能会跨越多个时间步。这种时空相关性不仅概括了空间相关性和时间相关性,同时更接近于隐藏在时空图结构数据中的真实因果效应。然而,大多数现有研究是分别处理空间维度和时间维度,并采用不同的模块和机制进行建模,之后再融合结果,或者在有限的时间窗口内建模时空注意力。这种分解方式和时间窗口方法在建模长期时间序列中的直接跨时空效应时可能效果欠佳。
-
其次,已有研究通常使用基于距离测度或其他地理连接方式构建的预定义图结构,这基于这样一个假设:所使用的图结构可以捕捉节点之间的真实依赖关系。然而,这种基于地理位置的连接方式可能并不等同于真实的交通相关性。例如,即使两个十字路口在地理上是相连的,但如果连接道路上没有车辆流动,那么它们之间的交通流量可能并无直接关系。一些研究已经关注到这个问题,并提出了自适应图以探索隐藏的相关性。
-
第三,即使图结构能够捕捉节点之间的真实依赖关系,空间相关性仍然可能在不同时间步中动态变化。例如,在两个相连的十字路口,早高峰和晚高峰的车流方向可能完全相反,这是由于通勤者在家与公司之间往返。因此,我们不能在所有时间步都采用相同的节点更新机制,因为节点相关性也可能受到时间动态的影响。近年来,Transformer 架构在语言建模和计算机视觉领域取得了卓越的性能,所以本文提出使用自注意力机制来建模图中的动态时空相关性。
创新点
该论文提出了一种新颖的自适应图时空变换网络(ASTTN),它堆叠了多个时空注意层,在输入图上应用自注意机制,然后由线性层进行预测。
-
为了解决上述挑战,在本研究提出ASTTN,以对交通网络中每个位置的交通流量进行联合预测。该论文在时空图上执行多头自注意力机制,并设计了 ST-attention 块 来处理图结构化数据。
-
与先前使用空间和时间分开建模的方法不同,ASTTN 采用堆叠的 ST-attention 模块,在不将时空相关性分解为空间和时间两个独立域的情况下,联合建模时空相关性。为了降低时间复杂度,该论文将时空图的构建限定在空间域内的一跳邻居。此外,我们进一步引入自适应空间图建模以探索真实的相关性,从而提高注意力机制的效率。
-
我们在真实高速公路交通数据集上进行了广泛的实验,结果表明,与基线模型相比,该模型在预测性能上具有竞争力。
方法论
问题的提出
我们将道路网络表示为一个加权图 𝐺 = (V, E, 𝐴),其中:
-
V 是节点集合,且 |V| = 𝑁,表示图中包含 𝑁 个节点;
-
E 是边集合,且 |E| = 𝐸,表示图中包含 𝐸 条边;
-
𝐴 ∈ R^(𝑁 ×𝑁) 是邻接矩阵,描述节点之间的空间距离。
在每个时间步 𝑡,图 𝐺 具有一个特征矩阵 𝑋𝑡 ∈ R^(𝑁 ×𝐷),该矩阵会随时间 𝑡 动态变化。
给定一个图 𝐺 以及历史 𝑇 个时间步的特征矩阵,交通预测的目标是学习一个函数 𝑓,能够预测未来 𝑇′ 个时间步的特征矩阵。
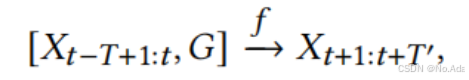
局部时空注意力机制
处理时空数据需要在空间和时间域上建模其相关性。将相同时间步(或位置)内节点之间的注意力称为空间注意力(spatial-attention)或时间注意力(temporal-attention),而对于同时具有不同时间步和不同位置的节点对之间的注意力,我们称之为时空注意力(st-attention)。
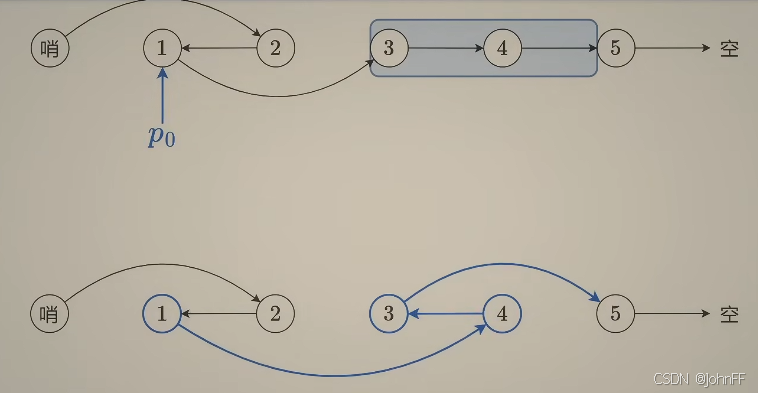
方法1:全局时空注意力
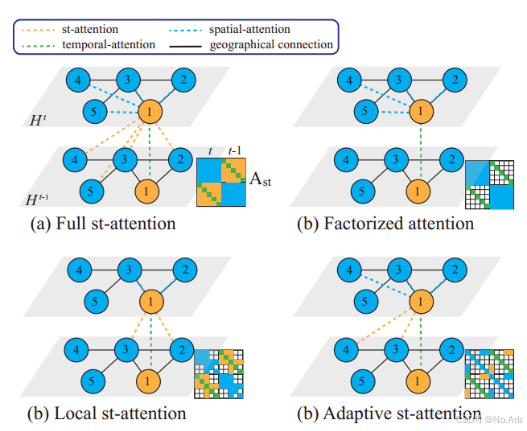
如图 1(a) 所示,将空间和时间注意力融合的最直接方式是对时空图中的每对节点计算注意力(即完全时空注意力)。这种方法能够捕获在空间和时间域上距离较远的两个节点之间的注意力关系,但其时间复杂度为O(𝑇²𝑁²),随着𝑁 的增长,无法扩展到大规模图数据。
方法2:组合时空注意力
另一种降低时间复杂度的方法是将时空注意力分解为空间维度和时间维度,然后依次计算注意力 [24],如图 1(b) 所示。这种方法的时间复杂度降低至 O(𝑇² + 𝑁²),但无法直接建模动态时空注意力,因为其是通过分别计算空间注意力和时间注意力后再组合得到的。
方法3:局部时空多头注意力
为了高效捕获空间和时间维度上的节点相关性,我们采用局部时空多头注意力(local spatial-temporal multi-head attention)进行节点更新。如图 1(c) 所示,我们利用空间邻接关系来降低计算复杂度,将时空注意力的计算范围限定在空间 1-hop 邻居内。具体来说,我们将输入特征矩阵展平成 𝑋 ∈ R^(𝑇𝑁 ×𝐷),并用 𝐴𝑠𝑡 ∈ R^(𝑇𝑁 ×𝑇𝑁) 表示时空注意力掩码。
首先,我们将输入矩阵投影为:
![]()
其中,𝑊𝑄, 𝑊𝐾 ∈ R^(𝐷×𝐷𝑄𝐾),𝑊𝑉 ∈ R^(𝐷×𝐷𝑉),查询矩阵 𝑄 和键矩阵 𝐾 维度相同(𝐷𝑄𝐾),而值矩阵 𝑉 维度为 𝐷𝑉,通常我们设定 𝐷𝑄𝐾 = 𝐷𝑉。
然后,局部多头自注意力(L-MSA)计算如下:

需要注意的是,该方法在时间维度上保留了完整的注意力计算(𝑇 个时间步),可以建模长距离的时间交互,相比于时间滑动窗口方法(temporal sliding window approach)仅考虑相邻时间步的情况,该方法具有更强的时序建模能力。该方法的时间复杂度为 O(𝐸𝑇²),对于稀疏图是可扩展的,其中 𝐸 代表空间图中的总边数。
方法四:自适应局部时空多头注意力
此外,我们通过引入自适应可学习邻接矩阵(adaptive learnable adjacency matrix)𝐴𝑎𝑝𝑡 来进一步优化局部时空注意力,该矩阵不依赖于任何先验知识,可以通过端到端的方式进行学习。具体而言,我们使用两个随机初始化的可学习节点嵌入矩阵 𝑈₁, 𝑈₂ ∈ R^(𝑁 ×𝑐) 来计算 𝐴𝑎𝑝𝑡:
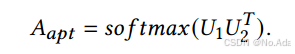
然而,由于计算得到的自适应邻接矩阵会形成一个完全图(即所有节点对均有连接),为了避免完全时空注意力的计算,我们使用Gumbel-Sigmoid 技巧来计算二值掩码 𝑏,并基于 𝐴𝑎𝑝𝑡 中的每个元素设置最大入度(每行最多允许的非零值数量),然后通过逐元素乘法应用到 𝐴𝑎𝑝𝑡:
![]()
Q:为什么需要引入自适应可学习邻接矩阵?
-
自适应可学习邻接矩阵的作用是增强模型的灵活性,使其能够自动学习节点之间的潜在关联,而无需依赖预定义的邻接关系。这种方法在建模复杂的时空关系时尤为重要,尤其是在原始邻接信息可能不完整或不足以完全表达节点间依赖性的情况下。
-
直接计算全局时空注意力(full ST-attention)会导致计算复杂度过高,难以扩展到大规模数据。而自适应邻接矩阵的引入可以通过学习更合理的邻接结构,使得时空注意力仅计算必要的节点关系,从而降低计算量,提高计算效率。这种优化方式使得时空注意力机制能够在更大规模的图结构上高效运行。
模型框架
下图为 ASTTN 的框架。该框架由输入层、时空嵌入层、带有残差连接的堆叠时空注意力(ST-attention)模块和输出层组成。

时空嵌入(Spatial-Temporal Embedding)
-
对于位置编码,我们采用 图(c)中用于图结构的拉普拉斯编码(Laplacian Encoding)。然后,将位置嵌入输入到全连接(FC)层,以保持与输入矩阵X相同的维度。
-
对于时间序列上的时间编码,利用时间步长(time step)来生成时间嵌入。考虑到交通流量的周期性,该论文遵循的方法是使用每个时间步的“星期几”和“一天中的时间”信息来组成二维时间编码,并随后通过全连接层处理。然后,我们将位置嵌入和时间嵌入相加,得到 时空嵌入(STE),用于描述图结构中不同时间步上节点的唯一位置。
时空注意力块(ST-Attention Block)
ST-attention 块对输入的交通矩阵 ![]() 执行局部时空注意力机制。如图 (b) 所示,该模块由两个并行的局部多头注意力(local MSA)模块组成,它们基于两种不同的图结构和时空嵌入进行计算。
执行局部时空注意力机制。如图 (b) 所示,该模块由两个并行的局部多头注意力(local MSA)模块组成,它们基于两种不同的图结构和时空嵌入进行计算。
在此模块中,我们考虑两种图结构:
-
原始道路图
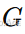 ,其邻接矩阵
,其邻接矩阵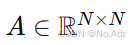 由道路的地理连接关系决定。
由道路的地理连接关系决定。 -
自适应图
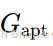 ,其邻接矩阵
,其邻接矩阵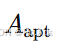 由模型参数化,并通过上述提到的自适应公式学习得到。
由模型参数化,并通过上述提到的自适应公式学习得到。
分别基于原始道路图和自适应图计算两种时空嵌入:
-
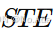 :基于原始图 计算的时空嵌入。
:基于原始图 计算的时空嵌入。 -
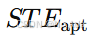 :基于自适应图 计算的时空嵌入。
:基于自适应图 计算的时空嵌入。
然后,将两种时空嵌入加到输入![]() 上。接下来,局部多头注意力按照公式执行局部时空注意力计算,其中:
上。接下来,局部多头注意力按照公式执行局部时空注意力计算,其中:
-
输入的时空特征矩阵为展平后的
 。
。 -
输入的时空注意力掩码由
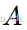 或
或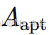 生成。
生成。
两个并行的局部 MSA 模块的输出随后会使用门控融合机制(gated fusion mechanism)进行融合。
输入层和输出层(Input and Output Layers)
输入层和输出层均为带 ReLU 激活函数的全连接网络(FC)。
-
输入层:将输入的节点特征映射到更高维度
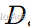 。
。 -
输出层:将时间维度从历史时间步长
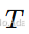 映射到未来的预测时间步长
映射到未来的预测时间步长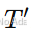 。
。
最终的预测结果为:
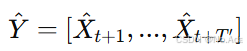
然后,我们使用平均绝对误差(MAE)作为损失函数,与真实值进行比较:
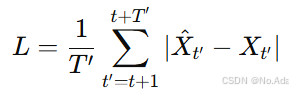
该损失用于训练 ASTTN 模型,并通过反向传播(back-propagation)进行端到端优化。
Q:为什么输入层和输出层都要使用带ReLU激活函数的全连接层
1. 输入层使用 FC + ReLU 的原因
在输入层,主要目的是将输入特征映射到更高维度 D,以便后续模型能够更好地学习复杂的时空模式:
-
非线性映射能力:ReLU(Rectified Linear Unit)可以引入非线性,使得模型能够学习更复杂的特征,而不仅仅是线性变换。
-
特征变换和增强:通过全连接层,可以对输入数据进行投影,将其转换到适合后续时空注意力机制处理的特征空间。
-
保持正信息,减少梯度消失问题:ReLU 具有梯度传播良好的特点,可以有效缓解梯度消失问题,使得深层网络更易训练。
在时空模型中,原始数据可能具有不同的尺度(如交通流量、时间特征等),使用 ReLU 可以过滤掉无效或负值信息,让后续注意力模块关注有效特征。
2. 输出层使用 FC + ReLU 的原因
在输出层,主要目的是将隐藏层的高维表示转换回原始的时间序列格式,以进行预测:
-
回归任务的输出:通常交通预测任务是回归问题(如预测未来的流量数值),全连接层可以将高维表示映射回原始时间序列格式。
-
ReLU 保持非负性:如果预测值代表的是某种物理量(如交通流量、速度等),那么它通常是非负的。ReLU 可以避免负值的预测输出,使其更符合现实情况。
-
数值稳定性:ReLU 可以有效防止小数值带来的梯度消失问题,确保模型在训练过程中能够稳定更新权重。
实验
实验参数
该论文使用 Adam 优化器训练模型,初始学习率为 0.001。在构建自适应图(adaptive graph)时,我们采用均匀分布随机初始化节点嵌入 𝑈₁、𝑈₂,并将其维度设为 10。
模型的超参数包括:
-
st-attention 块的数量(𝐿)
-
注意力头的数量(𝐾)
-
每个注意力头的维度(𝑑),其中 中间节点维度 𝐷 = 𝑑 × 𝐾
-
用于屏蔽自适应图的入度阈值
为了评估交通预测的性能,采用了三种常用的评价指标:
-
平均绝对误差(MAE)
-
均方根误差(RMSE)
-
平均绝对百分比误差(MAPE)
实现细节
使用 PyTorch实现模型,并利用 DGL(Deep Graph Library)进行图神经网络的高效训练,以充分利用输入图的稀疏性并加速消息传递。
为了高效计算 st-attention,该论文仅使用 DGL 构建空间图(spatial graph),避免构建完整的时空图(spatial-temporal graph)带来的高内存消耗。
在计算 局部 st-attention 时,我们采用如下方法:
-
固定查询矩阵(𝑄),同时沿着第一个时间维度对键(𝐾)和值(𝑉)矩阵进行滚动(即沿时间维度移动一步)。
-
将得到的 𝑄、𝐾、𝑉 组合分配给每个节点,并使用 DGL 进行消息传递,以计算注意力得分。
-
这样,我们实际上计算的是相邻两个时间步之间的时空注意力(对应于图 1 中的橙色虚线)。
-
该滚动过程重复 𝑇 次,最终将所有结果求和,相当于计算公式中的完整 st-attention 计算。
实验设计
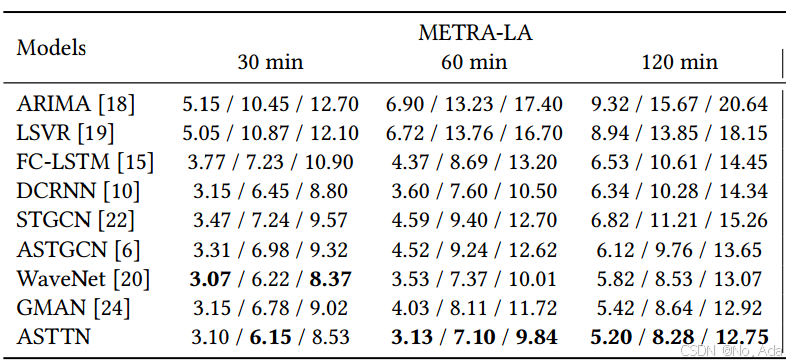
实验1(基线实验)
在 METR-LA 和 PEMS-BAY 数据集上进行实验,并在 30 分钟(6 个时间步)、60 分钟(12 个时间步)、120 分钟(24 个时间步) 这三种时间跨度下,对 ASTTN 和基线模型的性能进行了比较。
实验2(消融实验)
为了探究模型中各个组件的影响,该论文进一步构造了以下变体并进行消融实验:
-
ASTTN-NE(去除时空节点嵌入)
-
ASTTN-NF(去除门控融合模块)
-
ASTTN-NA(去除自适应局部-MSA 模块)
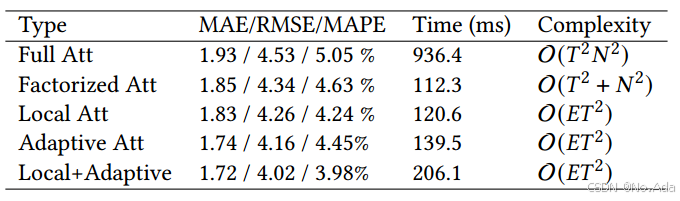
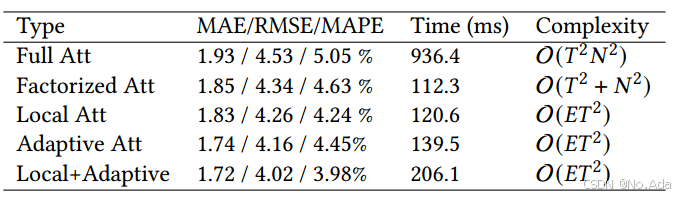
实验3(消融实验)
该论文分析了不同类型的时空注意力,并在相同超参数设定下,仅更改 局部 MSA 模块(local MSA modules) 的注意力机制,以确保公平比较。
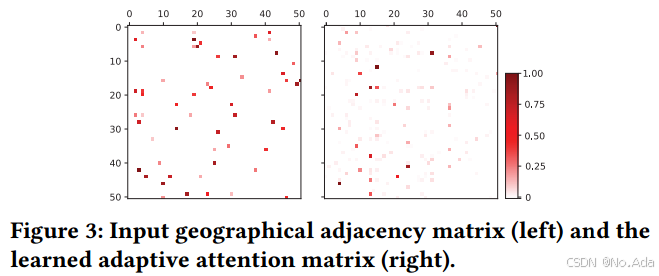
实验4(验证自适应矩阵)
该论文还进一步研究了 PEMS-BAY 数据集中前 50 个节点 的自适应邻接矩阵(adaptive adjacency matrix)。如下图所示,该矩阵显示了更加多样化的节点间关联,这表明:
-
传统的邻接矩阵可能无法完全描述真实的节点依赖关系。
-
地理邻接关系并不能完全反映节点之间的实际相关性,而自适应邻接矩阵可以挖掘更丰富的时空依赖性。