文章目录
- 一、auto
- 二、内联函数(inline)
- 三、函数重载
一、auto
auto在c++中是会根据等号右边表达式自动推导等号左边的类型
#include<iostream>
using namespace std;
int main()
{
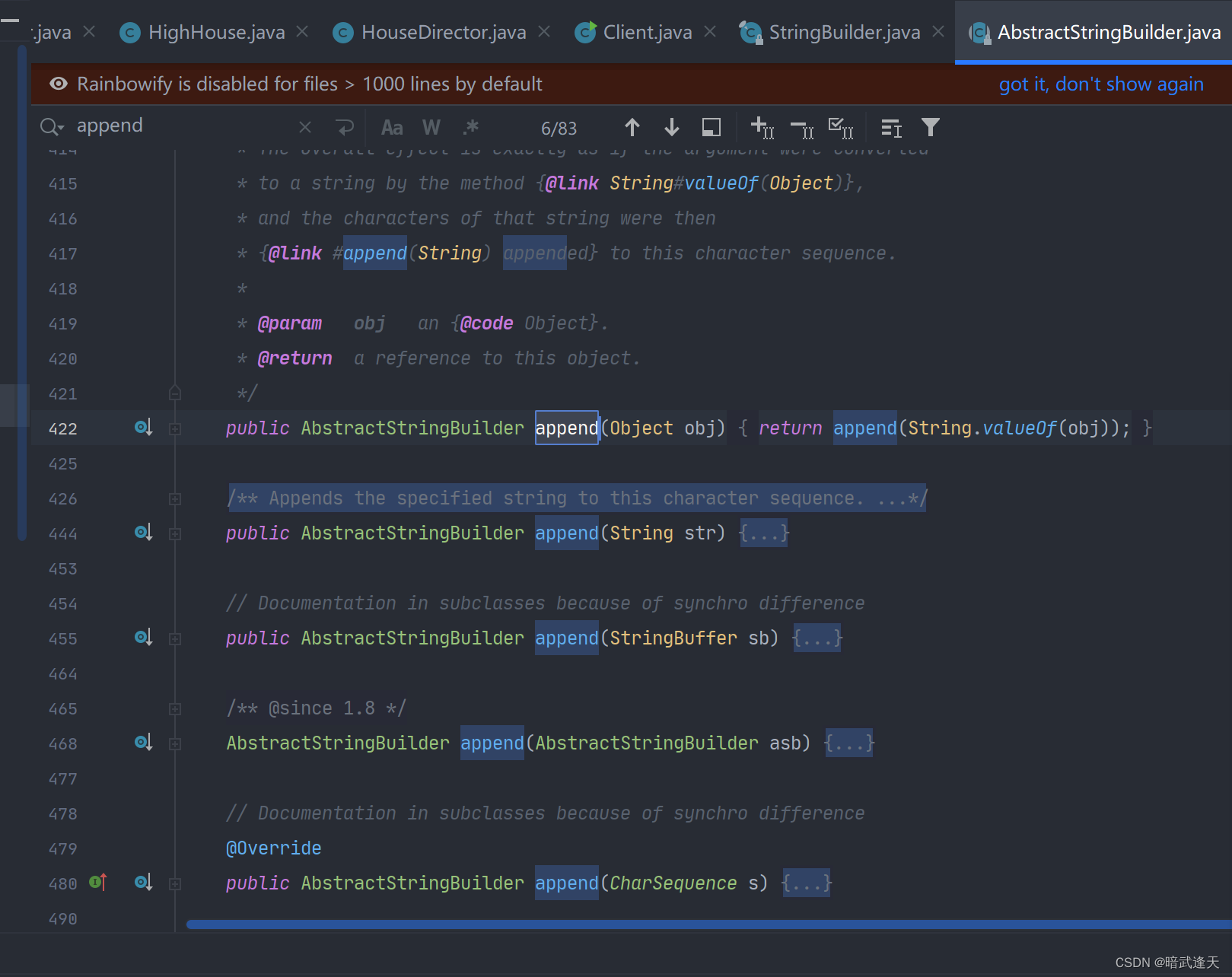
int a = 0;
auto b = a;
double c = 1.1;
auto d = c;
//打印类型typeid().name()
cout << typeid(b).name() << endl;
cout << typeid(d).name() << endl;
return 0;
}
什么情况下auto会被使用?
auto适用于右边表达式类型很长的情况,相当于类型的替换
还有一种情况,范围for 数组访问时,每次都要判断,且自增或者调整 用auto
for(auto e:arr)这样就可以将数组数据依次赋值给e,然后可以将其得到的值插入cout显示到控制台
:会自动迭代,自动判断结束,但是:只针对数组,其它就不行
#include<iostream>
using namespace std;
int main()
{
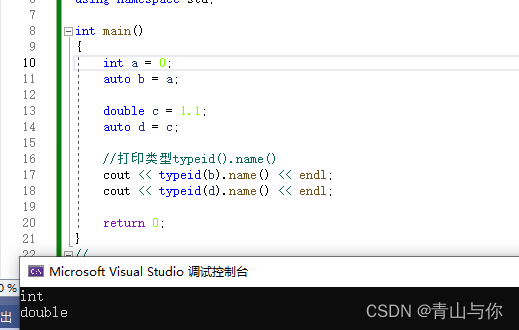
int arr[] = { 1,2,3,4,5 };
//这样就可以访问了,但是这样要修改数组内容应该如何办到
for (auto e : arr)//根据左边类型自动为e匹配类型,且:将数组值依次赋值给e
cout << e << ' ' ;
cout << endl;
/*for (auto e : arr)
e *= 2;
for (auto e : arr)
cout << e << ' ';*/
//在auto后面加引用操作符&,auto为变量e自动匹配类型,&就是对数组每个元素的引用,改变e就是改变数组
/*for (auto& e : arr)//引用修改数组值
e *= 2;
for (auto e : arr)
cout << e << ' ';*/
return 0;
}
二、内联函数(inline)
在调用函数时需要建立栈帧,在栈上开辟一块空间,要压栈,也要使用很多寄存器做临时变量拷贝去拷贝来有一定的消耗
对于那种重复调用的函数,这种消耗尤为明显,函数调用一次,就会建立一个栈帧,当某个函数被调用n次时,会建立n个栈帧
建立这些栈帧消耗太大了,那么如何能够降低或者减少哦这种因建立栈帧带来的消耗
c语言中可以用宏函数来实现对于重复调用的函数
#include<iostream>
using namespace std;
//宏函数实现,宏中的函数参数没有给其声明类型,且没有返回(return)这个关键字,
//除了函数名之外的所有变量每个变量都要用括号括起来
#define Add(x,y) ((x)+(y))
int main()
{
for (int i = 0; i < 10000; i++)
Add(1, 2);
return 0;
}
但是并不是所有都适用宏,宏也有其优缺点
优:在调用函数时不需要建立栈帧,提高调用效率,当需要该函数中某个值时可以直接在宏出修改,不必到函数中去一 一修改
缺:复杂、容易出错、可读性差(函数时,参数你在读的时候不知道参数是什么类型)、不能调试
那么c++如何解决?
对于这种大量重复调用某个函数时,c++用内联函数

内联函数:就是在调用函数的地方将函数展开,并不像普通函数在调用函数时需要建立栈帧
内联函数在调用函数时不用建立栈帧,将函数展开,减少了因建立栈帧带来的消耗
但是将这个函数展开就要使用额外的空间,这种方法是以空间换时间的方法
且展开时,如果函数中代码量过大,那么就会导致可执行程序变大代码膨胀
所以内联函数是适用于那种重复调用且代码量很少的函数(一般不超过十行的代码量)
那么内联不适用于哪些函数?
函数中代码量多
递归函数
虽然我们使用inline使函数成为内联函数了,对于我们来说可以给任意函数变成内联函数,但是这只是我们给编译器的建议,至于是否采纳还看编译器对于这个函数能否成为内联的判断,如果函数中代码量过多或者是递归函数编译器是不会采纳的
而且还要注意内联函数在声明和定义不能分离,由于声明时就将函数展开了,如果在另外定义,此时链接时去调用找其地址,根本找不到
三、函数重载
函数重载:也就是相当于汉语中的一词多义的意思,有时候一个汉字它有多个意思
而函数重载也是一词多义,一个函数名它虽然它实现的功能雷士,但是它具体的参数不相同
参数不相同(参数类型、参数个数、参数类型顺序)多个函数功能实现上是类似的,只是在具体细节上有些许差异
同一个函数名代表函数实现功能类似,只是形参数据类型存在差异 c++允许函数名相同
c语言不允许相同的函数名出现 函数同名时,在调用函数时不知道调用谁,
参数类型
#include<iostream>
using namespace std;
//参数类型不同
void fun(int a)
{
cout << "fun(int a)" << endl;
}
void fun(double a)
{
cout << "fun(double a)" << endl;
}
int main()
{
fun(1);
fun(1.2);
return 0;
}
参数个数
#include<iostream>
using namespace std;
参数个数不同
void fun(int a, int b)
{
cout << "fun(int a,int b)" << endl;
}
void fun(int a)
{
cout << "fun(int a)" << endl;
}
int main()
{
fun(1,2);
fun(1);
return 0;
}
参数类型顺序
#include<iostream>
using namespace std;
//参数类型顺序不同
void fun(int a, double b)
{
cout << "fun(int a, double b)" << endl;
}
void fun(double a, int b)
{
cout << "fun(double a, int b)" << endl;
}
int main()
{
fun(1, 1.1);
fun(1.1, 1);
return 0;
}

函数缺省参数能否构成重载,构成,但是如果在调用该函数传参时,两个函数什么都不传时,不构成函数重载,调用存在歧义
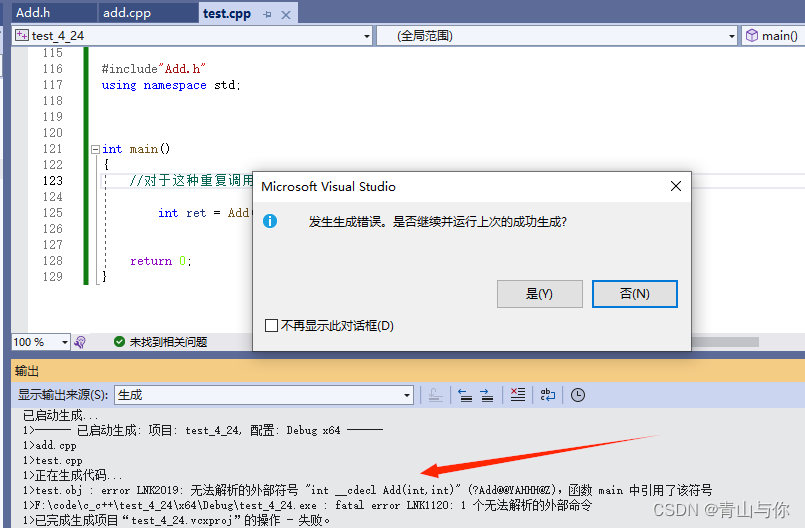
c语言函数在调用时,call指令只给其转成了一个函数地址名
c语言不支持函数重载。因为在链接时,调用该函数的地址,调用同一个函数名,此时调用有多个地址
编译器不知道去找哪个地址,所以c语言不支持函数重载。 c语言并没有函数名修饰规则,在编译调用函数时并没有将函数名改变
所以在链接找地址时(找的是函数名),由于存在多个地址,当一个调用时并不知道找的是哪个地址,调用存在歧义

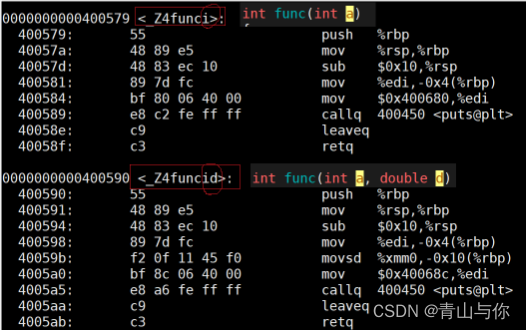
c++中,在调用时压栈,每个函数压栈的地址不一样,用同一个函数压栈过后它们函数名会发生变化,这种变化
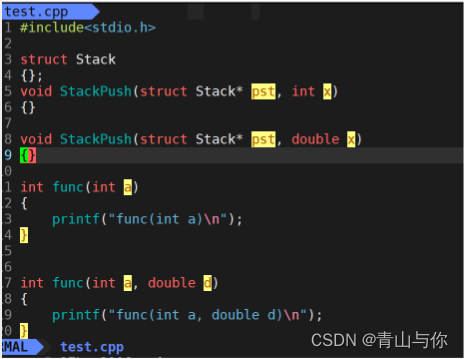
遵循函数名修饰规则,在调用函数时,在linux下c++将参数名带入了函数名,一般以_Z为函数名前缀然后_Z+数字(原函数名字符个数)+调用函数它的参数类型缩写,
其后有多少个字符就表示形参类型有多少个,类型缩写为其类型首字符
在链接时找它的地址时找函数名,此时它们的函数名都不一样,当然可以调用,各个函数名不同也就不会存在调用歧义
函数名修饰规则:将函数参数带入函数名中
在linux下,c++将参数类型带入了函数名,所有这也是为什么在调用时不会存在调用歧义的原因