项目效果:
python车流量检测双向车流计数
1、环境配置
1.1 安装显卡加速工具
(1) 安装CUDA和cudnn
NVIDIA CUDA® 深度神经网络库 (cuDNN) 是经 GPU 加速的深度神经网络基元库。cuDNN 可大幅优化标准例程(例如用于前向传播和反向传播的卷积层、池化层、归一化层和激活层)的实施。
世界各地的深度学习研究人员和框架开发者都依赖 cuDNN 实现高性能 GPU 加速。借助 cuDNN,研究人员和开发者可以专注于训练神经网络及开发软件应用,而不必花时间进行低层级的 GPU 性能调整。cuDNN 可加速广泛应用的深度学习框架,包括 Caffe2、Chainer、Keras、MATLAB、MxNet、PyTorch 和 TensorFlow。如需获取经 NVIDIA 优化且已在框架中集成 cuDNN 的深度学习框架容器,请访问 NVIDIA GPU CLOUD 了解详情并开始使用。
①查看显卡信息
若计算机带有英伟达系列的显卡的话才需要安装,没有的话跳过1.1。
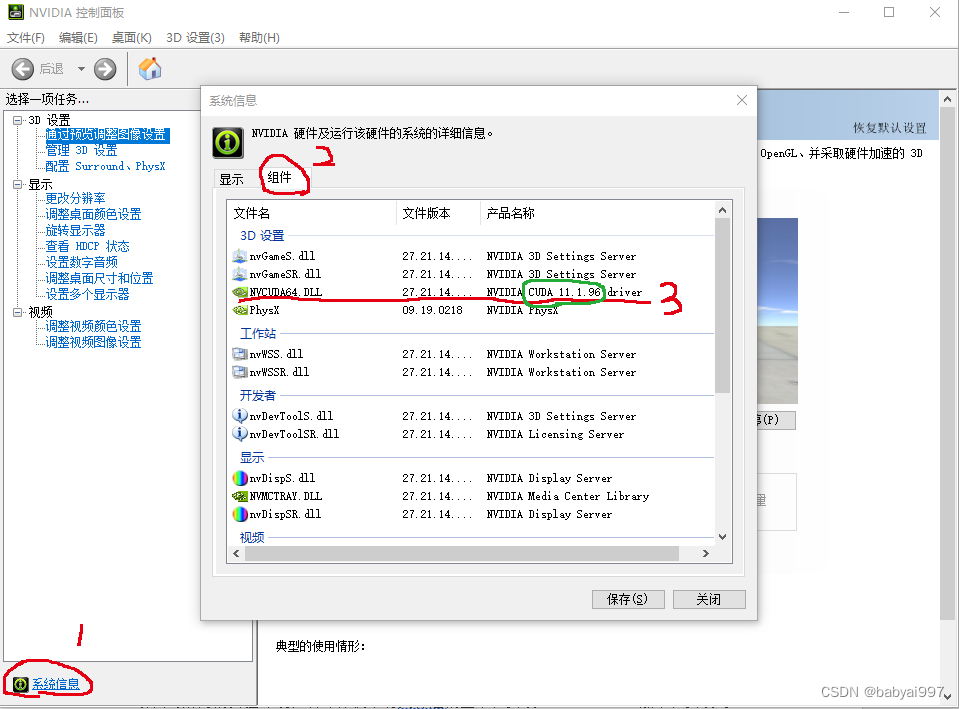
查看自己的显卡的版本以及显卡支持的CUDA版本,在显卡驱动中,右键控制面板,点击左下角的系统信息,点击组件,查看NVCUDA64.DLL,可以看出我的计算机的最高支持的CUDA版本为11.1.96,安装小于这个版本的即可。本人使用的CUDA版本为10.1,其他版本其实也可以,但是防止报错和不兼容等问题还是推荐使用10.1。30系的显卡仅支持11版本的CUDA。
如果没有安装显卡驱动也不要紧,在安装CUDA时会对显卡驱动进行安装。
②下载CUDA
CUDA10.1: ![]()
以及对应cudnn: ![]()
链接:https://pan.baidu.com/s/1PJb2RXJ37XOWlqDWzs3eZw
提取码:715s
如果安装CUDA10.1就可以不进行以下操作了。
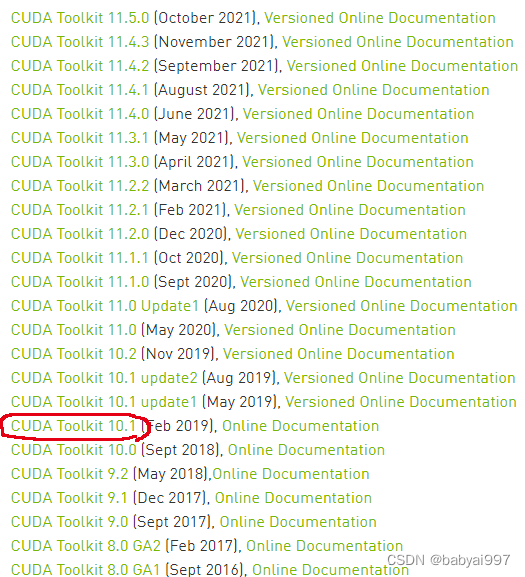
下载网址为CUDA Toolkit Archive | NVIDIA Developer
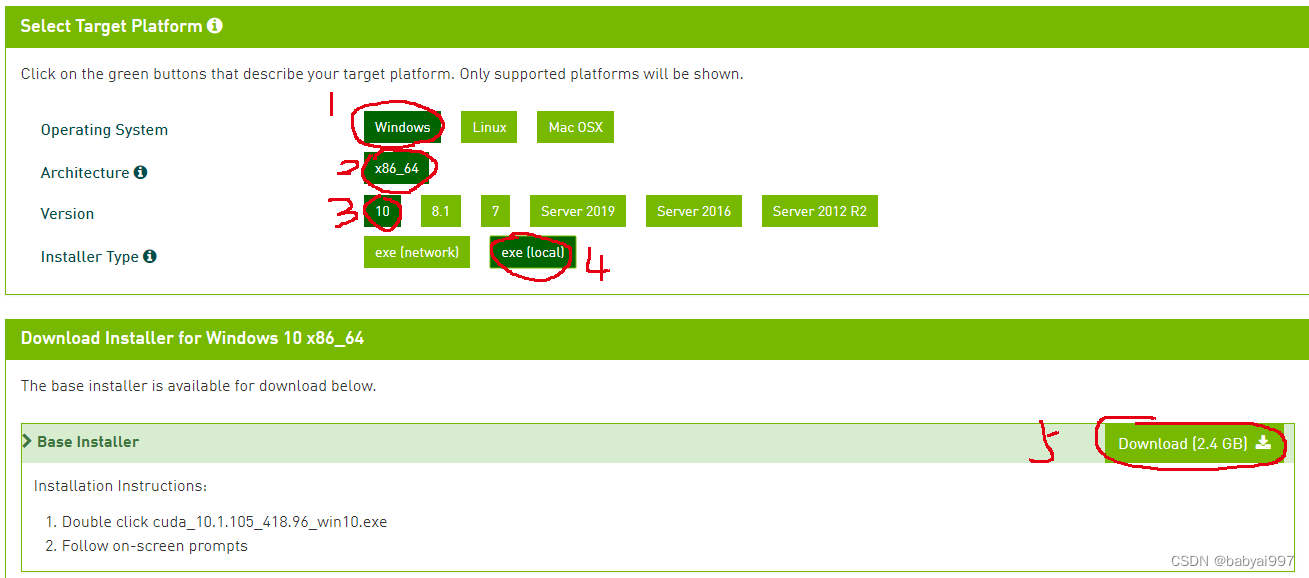
选择对应的版本,依次点击‘windows’,‘x86_64’,‘10’,‘exe(local)’,‘Download’。
③CUDA的安装
运行下载好的exe文件
步骤如下(部分过程图):
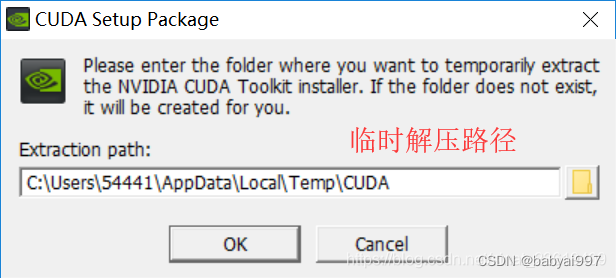
路径不需要修改。选择自动定义安装。
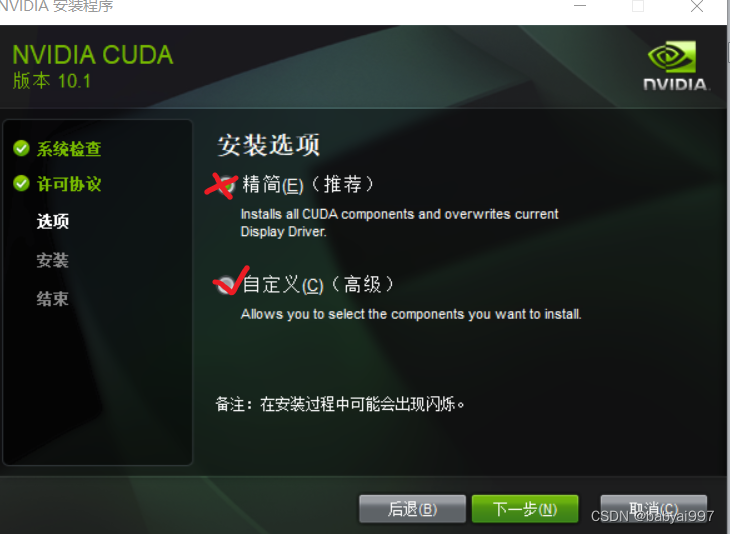
取消CUDA下面Visual Studio integration的勾选。
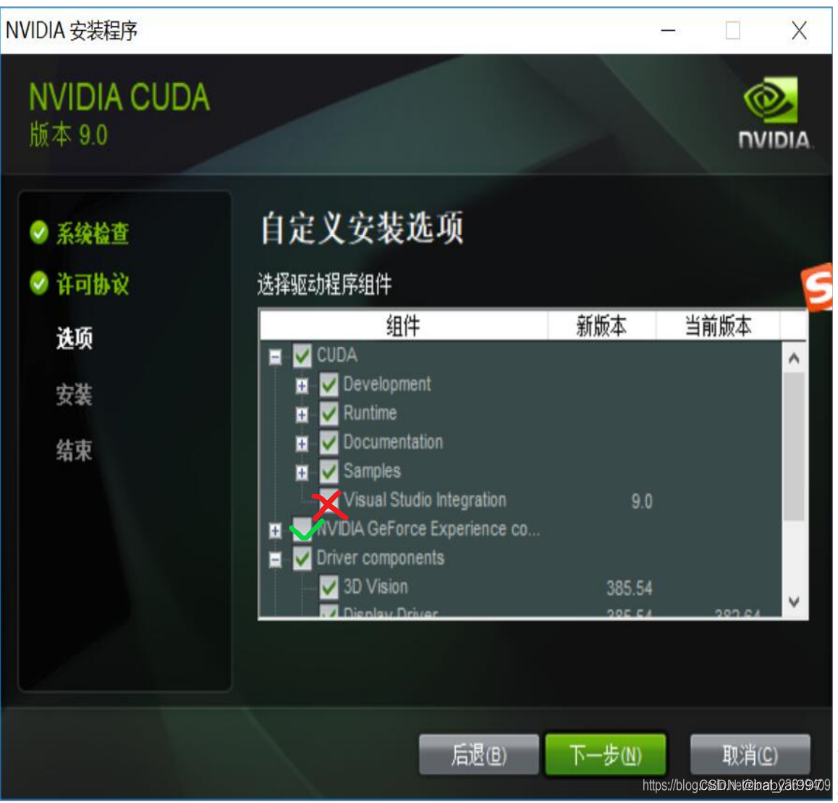
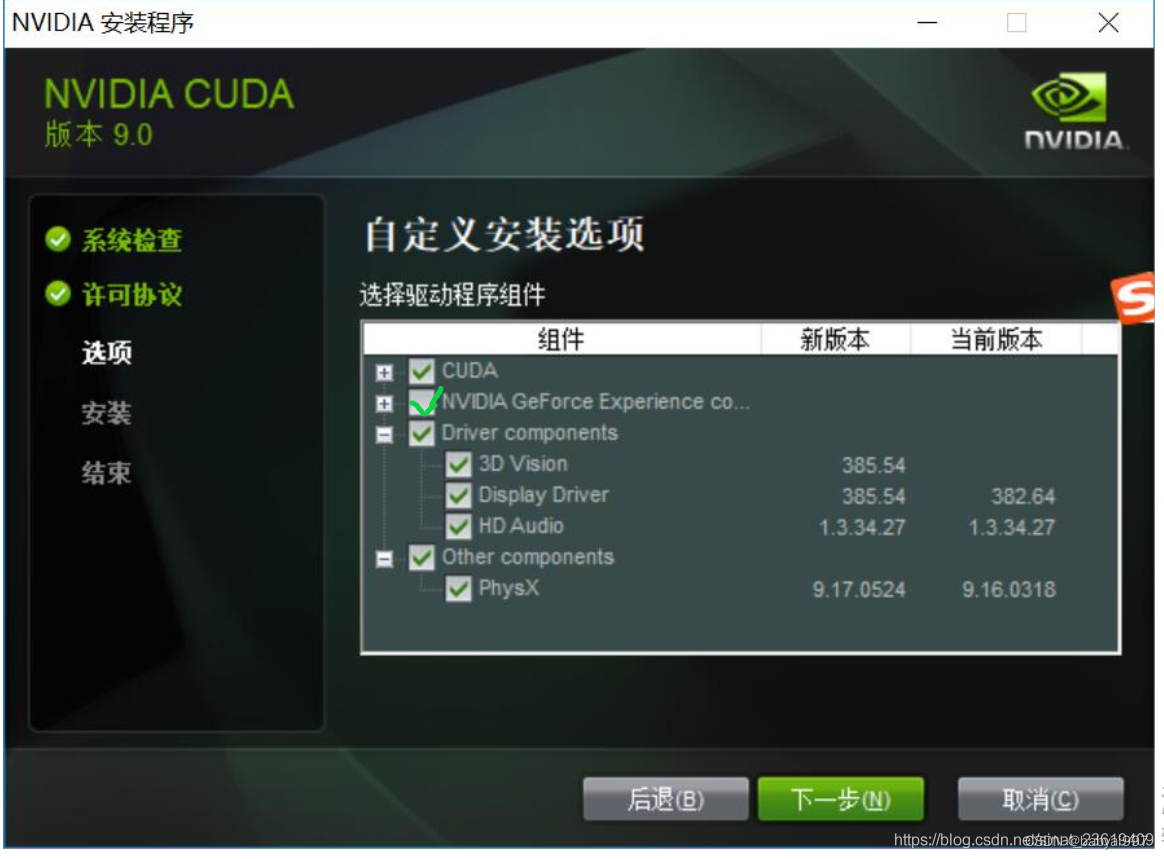
其余选项全部勾选。点击下一步。
④安装cudnn
可以从③中的百度网盘连接中下载,就不需要到网站中进行下载了。
下载网址:cuDNN Archive | NVIDIA Developer
在其中找到对应CUDA的cudnn版本,点击之后找到对应你的操作系统的cudnn后,不要直接点进去,可能需要你进行登录操作,比较麻烦,选中后右键‘复制链接地址’,然后使用迅雷等下载工具进行下载。
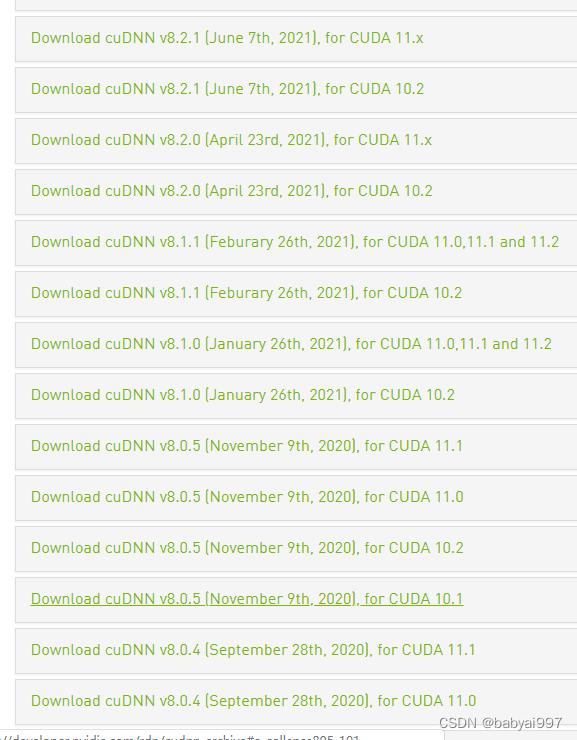

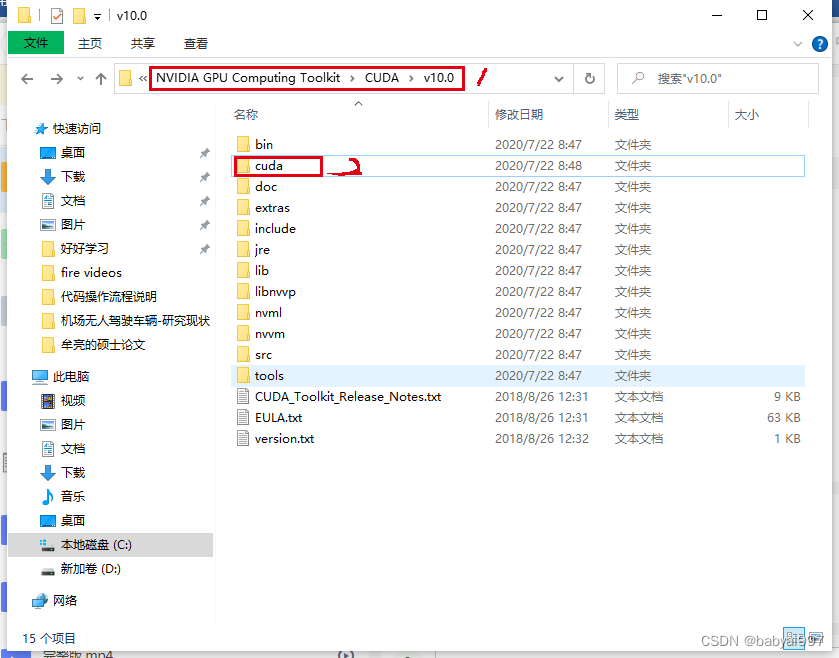
下载完成后,将其解压到CUDA的安装位置:
⑤配置环境变量
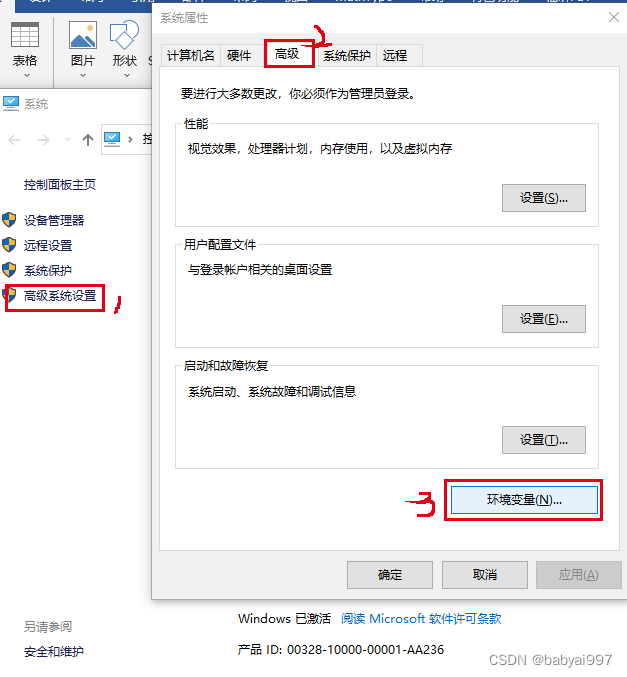
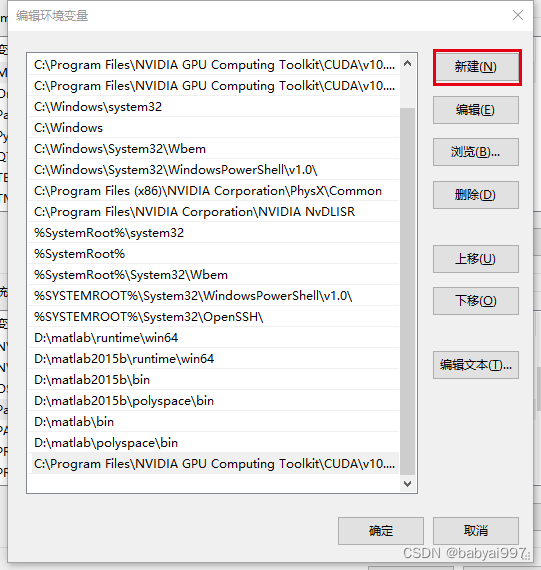
安装完成,需要将CUDA和cudnn添加到操作系统的环境变量中。首先打开‘此电脑’后,在空白处右键选择‘属性’,点击‘高级系统设置’,点击‘高级’,‘环境变量’,选择‘系统变量’一栏下的Path后点击‘编辑’,点击新建将CUDA下的bin文件夹和解压的cudnn文件夹的路径位置添加到环境变量中,我需要添加的两个位置为:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\cuda
供大家参考。
配置完成之后连续点击确定即可。


1.2安装anaconda3
Anaconda指的是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。 因为包含了大量的科学包,Anaconda 的下载文件比较大(约 531 MB),如果只需要某些包,或者需要节省带宽或存储空间,也可以使用Miniconda这个较小的发行版(仅包含conda和 Python)。
下载地址:Free Download | Anaconda

Anaconda 是跨平台的,有 Windows、macOS、Linux 版本,我们这里以 Windows 版本为例,点击那个 Windows 图标。双击下载好的anaconda文件,出现如下界面,点击 Next 即可。
点击 I Agree (我同意),不同意,当然就没办法继续安装啦。
Install for: Just me还是All Users,假如你的电脑有好几个 Users ,才需要考虑这个问题.其实我们电脑一般就一个 User,就我们一个人使用,如果你的电脑有多个用户,选择All Users,我这里直接 All User,继续点击 Next 。(这里选哪个都可以,按照推荐的选择即可)
选择Anaconda的安装位置,因为Anaconda需要管理很多的三方库以及代码运行环境,所以需要很大的安装空间,建议不要安装到系统盘内。
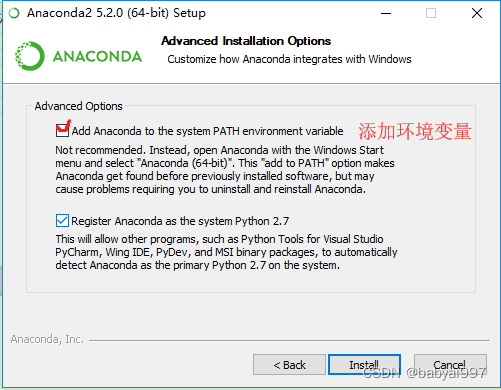
选择添加环境变量,两个勾都需要选上。
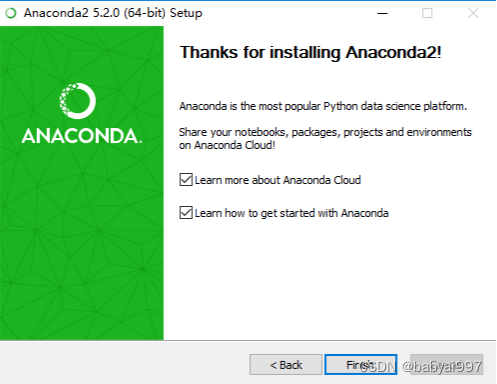
安装完成后可以取消这两个勾,点击完成即可。
1.3集成开发环境(Integrated Development Environment,IDE)
(1)安装
我一直是用的pycharm,感觉功能很全还是比较好用的,当然使用其他的编译器如VSCode、spider等都可以,这里仅介绍pycharm的安装以及使用方法。
Pycharm的下载网址:PyCharm: the Python IDE for Professional Developers by JetBrains

下载社区版本的pycharm
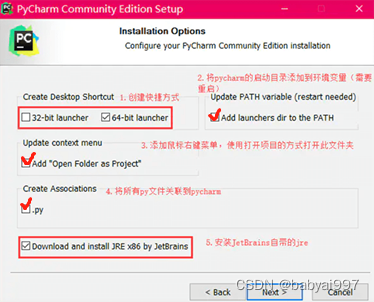
安装过程中勾选以上选项后,点击Next。
默认即可,点击 install。如果你勾选了上图中的最后一个选项“安装JetBrains自带的JRE”,会出现如下的下载界面,等待其自动下载完毕即可,然后等待安装完毕。
(2)使用
首次启动 pycharm,会弹出配置窗口:
如果你之前使用过 pycharm 并有相关的配置文件,则在此处选择;如果没有,默认即可。同意用户使用协议:
确定是否需要进行数据共享,可以直接选择Don't send:
选择主题,左边为黑色主题,右边为白色主题,根据需要选择:
下载插件,你可以根据需要下载,也可以不装。建议只装 MarkDown插件即可:
1.4 代码环境配置
(1)打开代码
现在安装代码所需要的代码库,简称环境配置,从百度网盘中下载好代码,右键Yolov5_DeepSort_Pytorch-master1文件(就是你下载的项目文件,这个文件是YOLO v5目标检测算法,如果配置的环境可以运行这个代码,那么其他代码都可以运行)选择open folder as pycharm,点击右下角的terminal,如图:

点开后会出现这样的终端:
(2)建立虚拟环境
这里可以使用anaconda的基础环境,就不需要再建立虚拟环境了,直接跳过该步骤。
也可以自建一个独立的虚拟环境,建议读者使用这种方法。
操作如下:每次输入命令后需要按回车,并且出现需要你输入Y/N的时候都输入Y然后回车。
建立虚拟环境:conda create –n yolov5-deepsort python =3.7
红色字的部分为建立虚拟环境的名称,可以按照自己的需要进行修改。
![]()
激活建立的虚拟环境:conda activate yolov5-deepsort

激活后,左边括号里的就是在使用的环境。
在新版本的pycharm中存在一种bug,无法在终端中直接激活虚拟环境,如果这样的话使用步骤(4)进行虚拟环境的激活。
(3)安装环境
在终端中输入pip install -r requirements.txt
![]()
等待安装完成。如果安装缓慢的话,可是使用清华镜像源,在输入安装命令后加上-i Simple Index
安装完成后继续安装torch,安装与你安装的 Cuda版本对应的torch,torch安装包比较大,网络不好的话可能下载失败,可以在torch的官网中复制命令进行下载:
https://pytorch.org/get-started/previous-versions/
在官网中找打对应操作系统以及对应CUDA的torch版本,安装操作如:在终端中输入:conda install pytorch==1.7.0 torchvision==0.8.0 torchaudio==0.7.0 cudatoolkit=10.1 -c pytorch或者是pip install torch==1.7.0+cu101 torchvision==0.8.0+cu101 torchaudio==0.7.0 -f https://download.pytorch.org/whl/torch_stable.html
如果是cuda10.2,输入conda install pytorch==1.7.0 torchvision==0.8.0 torchaudio==0.7.0 cudatoolkit=10.2 -c pytorch 或者pip install torch==1.7.0 torchvision==0.8.0 torchaudio==0.7.0
等待安装完成
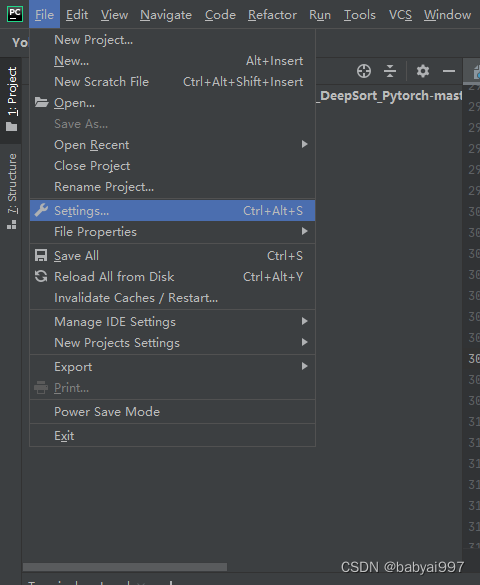
(4)将配置好的环境在pycharm中调用,点击pycharm的左上角file中的settings
点击project下的python interpreter,然后点击右边的小齿轮,中的add
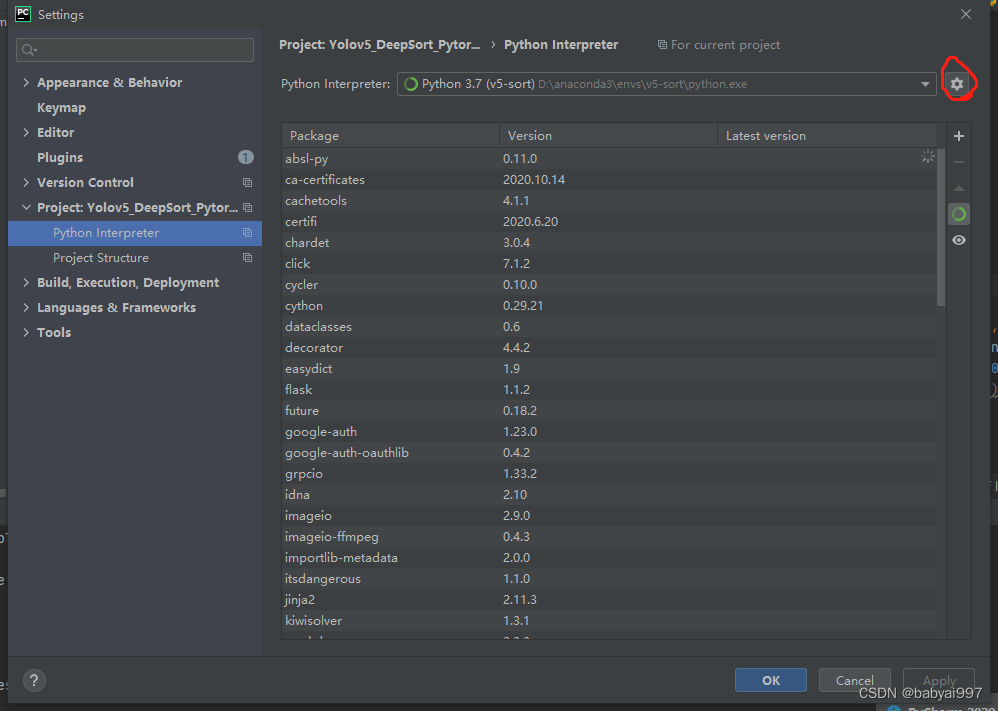
选中conda environment,再选中existing environment,右边的…
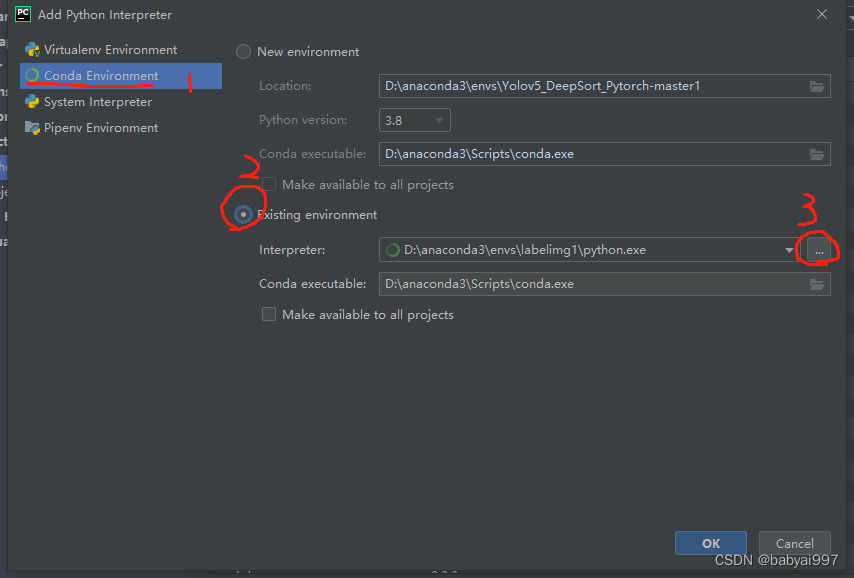
选中之前建立的yolov5-deepsort环境下的python.exe
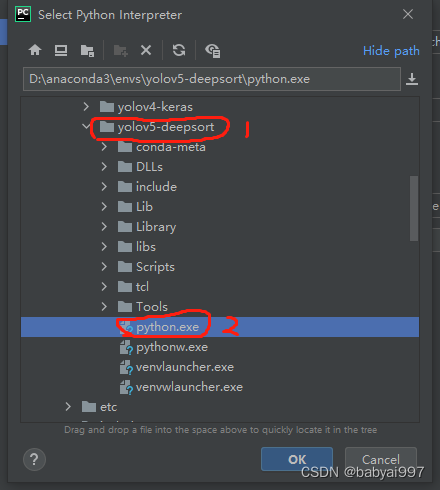
全部点击ok即可。
环境配置完成。
2、目标检测算法训练
YOLOv5目标检测算法,是该系统获取视频中车辆信息的第一步,使用深度学习框架Pytorch搭建。这里可以通过训练自己的数据集来检测所需要检测的目标,训练的代码与该系统的项目代码是分开的,主要由coco128、yolov5-master1两个文件夹组成:

coco128文件夹中train文件夹中存放训练集,vaild文件夹中存放验证集:

train和valid文件夹下有:

Images文件夹中存放训练的图片,labels文件夹下存在训练图片对应的标签文件,两者数量和名称上必需要同一。一般的数据集的标签格式不是按照YOLO格式进行标注的,所以需要进行格式的转换,YOLO标签的格式如下。
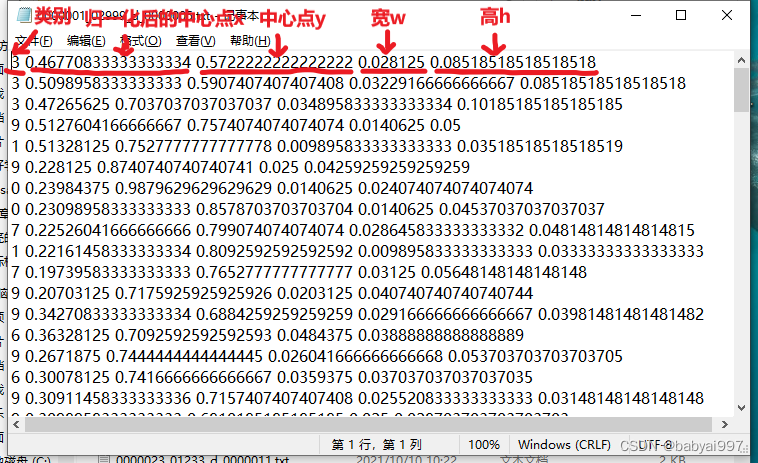
coco128.yaml是关于配置训练参数的文件,其中nc代表本次训练样本类别的数量,names代表每个类别的名称。
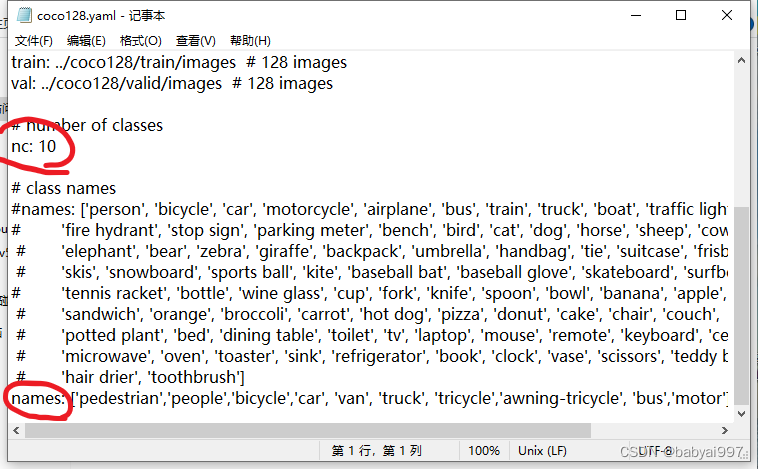
使用IDE打开yolov5-master1,其中的train.py为训练文件,配置其中关于训练参数的信息即可运行代码(提前配置好所需环境)。weights是预训练的权重文件,即接下来的训练是在该模型的基础上进行的;epoch为训练的迭代次数;batch_size为每次训练时放入图片的张数,显存越低该数值需要调的越低。
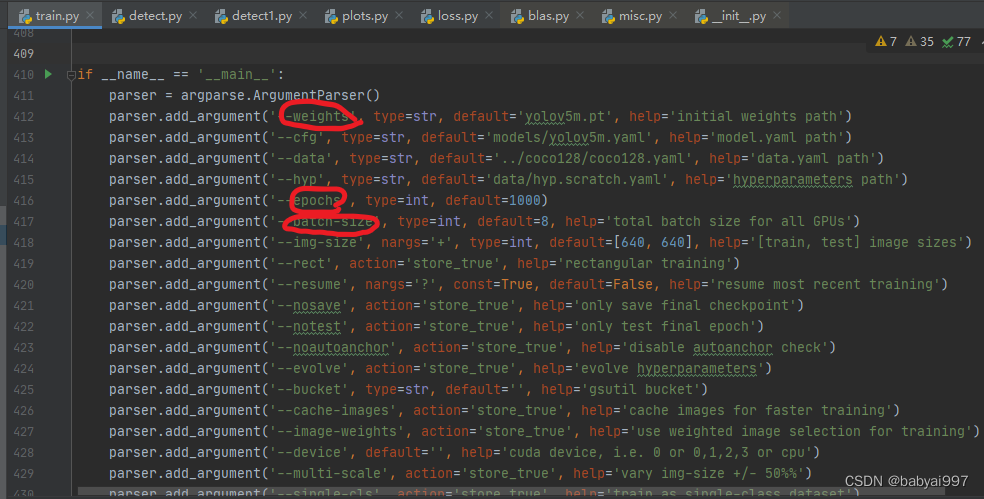
成功训练的效果为:

训练后的权重文件以及训练过程参数存放在:yolov5-master1\runs\train中

3、关于其他代码的运行
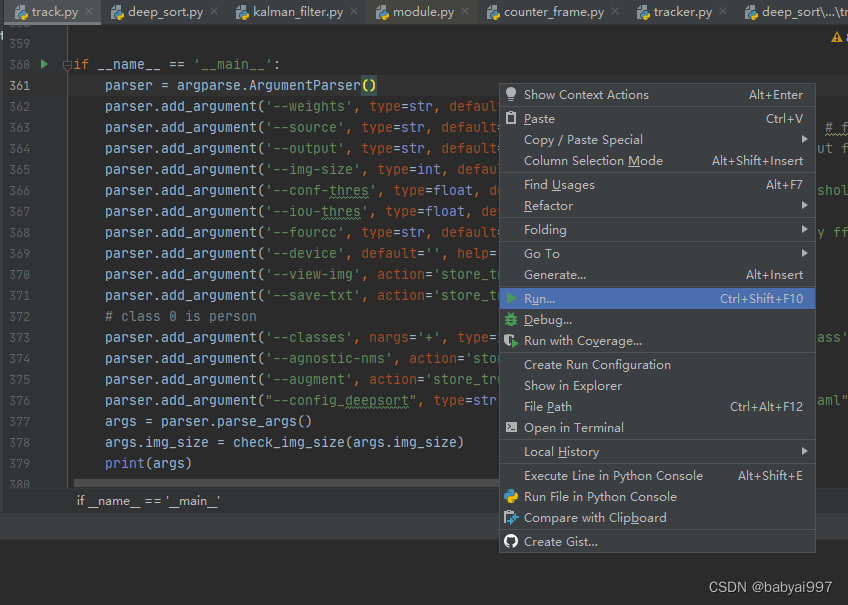
(1)打开工程文件下的track.py文件,找到下图的位置

--weights代表了权重,在后面的default后为代码所使用权重的位置’../best.pt’其中..代表了和工程文件相同的位置的,若工程文件放到了桌面,该位置就代表了桌面上的best.pt,best.pt为权重的名称;--source为需要检测的视频,default后的路径就代表了桌面上的convert文件夹中的out_1.avi文件,名称和位置必须要求正确,否则会报错。并且在代码中输入关于路径的地方全部需要使用/而不是\;--output代表输出的视频文件,一般不需要修改。
(2)将文件位置和路径配置好后就可以运行代码,点击代码中的任意位置,右键点击run(还有其他运行代码的按键,不一一列举)
代码运行成功的效果如下图所示:
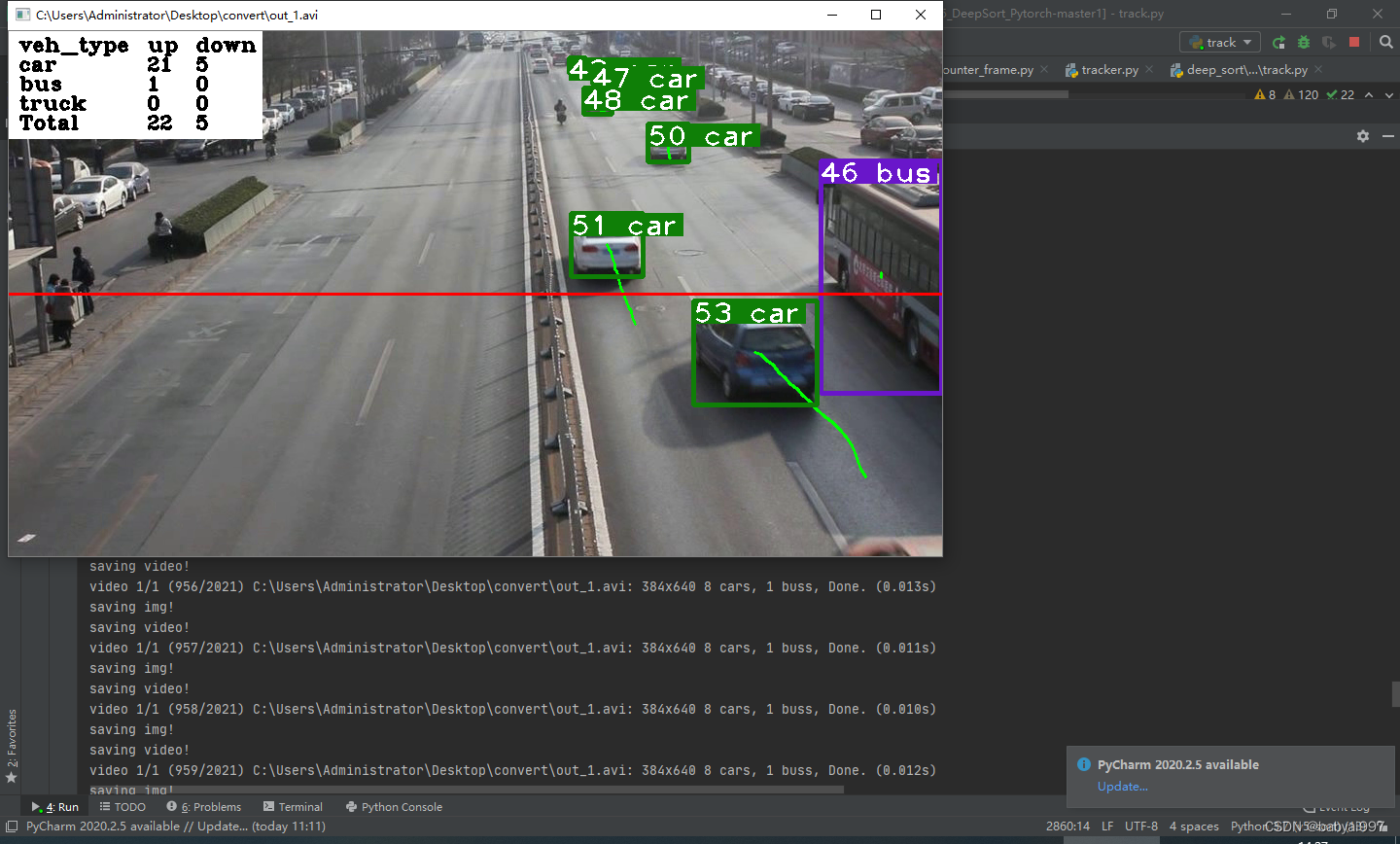
代码运行结束后,视频会保存到如下位置
项目下载:
https://download.csdn.net/download/babyai996/85020479![]() https://download.csdn.net/download/babyai996/85020479
https://download.csdn.net/download/babyai996/85020479
部署视频教程:
https://download.csdn.net/download/babyai996/85100267![]() https://download.csdn.net/download/babyai996/85100267
https://download.csdn.net/download/babyai996/85100267