2022年12月15日,中山大学史俊鹏副教授、中国科学院遗传与发育生物学研究所田志喜研究员、中国农业大学赖锦盛教授和上海师范大学黄学辉教授共同撰文,在Molecular Plant杂志发表了题为“Plant pan-genomics and its applications”的长篇综述。该论文对植物中泛基因组产生的源动力、表征、分析方法以及在植物遗传学和育种中的应用进行了系统总结和展望。

全文总结如下:
摘要
植物基因组的多样性很高,以至于很大一部分基因组序列是个体所特有的。DNA的可变序列与保守的核心序列一起构成了更复杂的泛基因组,代表了一个物种中所有非冗余DNA的集合。随着基因组测序技术的快速发展,植物泛基因组研究正在加快。我们回顾了植物泛基因组学的最新进展:包括促成可变序列的结构变异及其主要驱动力、表征泛基因组的方法创新,和构建植物泛基因组的主要成功案例。我们还总结了最近通过端到端或无缝隙基因组的方式解码基因组中剩余暗物质的努力。这些新的基因组资源相比于许多以前组装的不太完美的基因组具有显著的优势,有望成为遗传学研究和植物育种的新参考。
植物基因组具有超高的复杂性、多样性和重要性,它们已经被广泛研究了数十年。第一个植物基因组是2000年发布的小型开花植物拟南芥的基因组草图,耗费了大量人力、时间和财力 (《拟南芥基因组计划》,2000年)。在最近测序技术和组装方法的进步之前,植物基因组组装仍是比较困难的。由于这些技术的创新,我们现在拥有大约800种植物的1000多套植物基因组组装。这些基因组广泛分布在主要植物谱系中,其中70%以上是在过去4年内发表的。通过跨物种比较,已经解码了植物基因组起源、组织和结构的关键特征,包括基因组大小从数兆碱基到数十至数万兆碱基的巨大变化、转座子谱系特异的活性以及物种形成和驯化过程中的频繁多倍体化和二倍体化事件。
除了这些努力,植物界还致力于对同一物种中的更多个体进行测序,因为植物的种内多样性可能非常高,甚至超过了人类和黑猩猩之间的跨种差异。在没有足够基因组序列的漫长时期,人们推测一个物种的多数DNA序列 (核心基因组)在种内的不同个体之间是一致的,只是具有大量单核苷酸多态性位点 (SNP)和少量InDel (插入和缺失)。这些简单的遗传变异经常被研究并用于剖析复杂性状的遗传基础和指导育种实践。然而,越来越多的证据表明,更多的DNA序列是可变的,并且仅在一个小群体中共享 (称为可变的基因组),这导致了“泛基因组”这一更复杂的概念。泛基因组代表了一个物种中所有DNA序列的集合,预计它比常用的单一线性参考基因组具有更好的完整性和准确性。自从首次尝试在大豆中进行泛基因组组装以来,泛基因组研究已扩展到许多其他植物物种,包括拟南芥、水稻、玉米、大麦、小麦、棉花、番茄、土豆、柑橘和油菜,揭示了出乎意料的高基因组变异性,即使对最近经历驯化瓶颈 (domestication bottlenecks)的作物也是如此,展现了泛基因组在功能基因组学发现方面的巨大潜力。分析日益复杂的植物泛基因组的计算方法也在迅速发展。除了这一进展,我们还正在解码之前未测通的基因组空白区域,并生成代表性的无间隙或T-2-T基因组组装,从而解码复杂植物基因组中长期未能探索的那些“暗物质”。
我们回顾了植物泛基因组和无间隙基因组研究的最新进展。我们讨论了基因组结构变异 (SVs)的主要驱动力,这与可变基因组密切相关,并对重要的表型变异做出了重大贡献。我们还总结了表征泛基因组的方法学进展,从早期的‘‘map-to-pan’’策略到最近的基于“图”的基因组方法。最后,我们讨论了这些新开发的基因组资源的应用,这些资源有望加速植物遗传研究和育种,解决世界的粮食危机。
植物泛基因组可变序列中结构变异 (SVs) 的主要驱动力
泛基因组的概念框架于2005年在研究微生物时首次提出;前缀 “pan” 来自希腊pan,意思是 “all”。然而,泛基因组分析直到2010年才进入高等真核生物领域,这时高通量短序列测序技术已经成熟,并且在人类、动物和植物中的从头组装也获得成功。通过组装七个野生大豆基因组在大豆中构建了第一个植物泛基因组;它揭示了在栽培的大豆基因组中缺失了一些与抗病性、种子组成 (seed composition)和开花时间相关的基因。在描述可变基因组时,大多数早期工作集中于蛋白质编码基因的存在和缺失。最近,测序和计算算法的进步已经实现了在全基因组范围进行复杂基因结构变异 (通常大于50 bp)的识别,包括InDels、拷贝数变异 (CNVs)、存在/缺失变异 (PAV)、倒位 (inversions)和易位 (translocations),这些共同导致了泛基因组的组成多样性。经过全基因组范围的分析后,那些在现有参考基因组中没有同源性且与基因结构变异相关的序列可以沿着线性基因组迭代堆叠或锚定,作为基因组图中的替代路径,并可以持续优化,以纳入更多新的序列变体。
植物中SVs的产生涉及四种主要驱动力 (图1):转座子活动 (TE activity)、非等位基因同源重组 (NAHR)、基因渐渗/基因水平转移 (HGT) 和多倍体植物中的偏向性基因丢失 (biased gene loss (fractionation))。转座子是最初在玉米中作为“控制元件”被发现的,也是大部分植物基因组中最丰富的功能元件。植物中的转座子可分为I类逆转录元件、II类DNA转座子和Helitron,它们分别通过“复制-粘贴”、“剪切-粘贴”和“滚动循环”机制进行转座。转座易位时会频繁诱导中等或长的InDels (数百个碱基至数万个碱基)和其他复杂结构变异。某些类型的转座子,如玉米中的Helitrons,可以在易位过程中捕获外显子片段,导致基因移动和种内基因共线性的破坏。
在两个植物亲缘分离后,转座子还会导致某些谱系特异性基因组扩增和染色体重排。除了来自比较基因组学的大量证据外,一系列精细基因组绘图工作也表明,源自TEs的SVs在作物驯化和适应中发挥了关键作用。例如,与其祖先蜀黍相比,玉米中tb1、vgt1、ZmCCT10和ZmCCT9基因的基因间调控区中插入的Hopscotch、MITE、CACTA和Harbinger-like转座子,降低了其分枝和光周期敏感性。除了插入外,从其原始基因座中切除TEs也能够产生与玉米和葡萄种子颜色变化相关的恢复性InDel突变。由于其广泛存在,TEs在几乎所有的植物泛基因组中都有发现,并且构成了很大比例的可变序列,例如,在水稻中约占68.7%,在玉米中约占60%。
非等位基因同源重组 (NAHR, non-allelic homologous recombination),也称为不对等交换 (unequal crossing over),诱发于减数分裂过程中非等位基因重复序列的错误排布时,进而导致序列的缺失、重复或其他类型的基因结构变异。植物基因组包含大量来自转座子 (玉米~85%,小麦~85%,大麦~80%)和多倍体化的重复序列,因此更可能经历NAHR。值得注意的是,简单的基因重复序列足以在没有转座子参与的情况下独立诱导NAHR,如拟南芥中所报道的。重复和缺失的大小以及受NAHR影响的基因的数量在很大程度上取决于这些错位的重复序列,甚至当它们发生在不同的染色体上时,也会触发易位或染色体融合。尽管一些精细规模的研究已经报道了大豆和玉米中的一系列可能起源于NAHR的CNV基因,但由于NAHR和TEs的影响有些相似,它们对可变基因组序列的贡献通常很难区分。
尽管转座子和非等位基因同源重组都可以产生基因结构变异,但它们很少能够直接引入新的DNA序列。相比之下,原本不存在于物种基因库中的DNA序列可以通过基因渐渗 (genetic introgression)或基因水平转移 (HGT)获得。基因渐渗和HGT在植物中普遍存在,尽管它们通常发生频率相对较低。除了通常起源于近亲间杂交的渗入外,HGT也可能发生在亲缘关系较远的物种之间,甚至跨界从真菌、细菌转移到植物。通过这两个过程获得的外源基因可能为受体植物提供新的功能或表型,使其能够更好地适应环境变化。一个众所周知的例子是Fhb7基因,该基因从镰刀菌水平转移到长柄偃麦草,然后在小麦育种计划中被人工选择,以提高抗赤霉病能力。尽管已经开发了用于鉴定HGT的全基因组方法,但它们尚未应用于植物泛基因组研究以评估HGT对可变基因组序列产生的贡献。
多倍体植物基因组复制后的分离是基因和非编码序列存在和缺失变异(PAV , presence/absence variations)背后的另一个主要推动力。多倍体化在植物中普遍存在,约35%的植物物种经历了一次近期的多倍体起源事件。全基因组复制事件产生的基因冗余可以缓冲基因组变异的有害影响;因此,这些重复序列在单个拷贝上的选择性压力可能会降低,使该拷贝更容易积累突变或形成新功能。来自一个亚基因组 (subgenome)的重复基因拷贝也往往更频繁地丢失,这一现象被称为基因组缩减 (genome fractionation, 也被称为二倍化)。据报道,玉米是一种异源四倍体作物,目前仍在进行二倍化,差异二倍化可能是导致不同玉米个体中广泛存在的PAV基因的原因。一些可变DNA序列也可能是从头产生的,正如在Oryza中所显示的,蛋白质编码基因和非编码功能元件 (如长非编码RNA)都是如此。
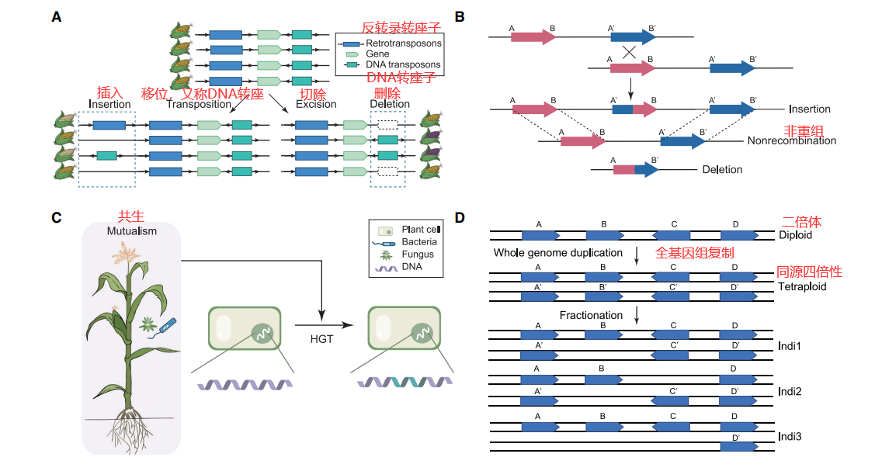
图1. 概述与植物泛基因组中可变DNA序列相关的结构变异 (SVs)的主要驱动力。(A) 转座子的活动 (转座和切除)导致共同的SVs,这可能与表型变异有关 (以玉米种子颜色变化为例)。(B) 两个非等位基因重复序列 (A-B和A’-B’)之间的NAHR产生两个重组等位基因,一个是插入 (A’-B),另一个是删除两个位点 (B-A’)。(C) HGT可以快速获得最初不存在于植物基因库中的基因,甚至跨界从真菌和细菌转移到植物。(D) 多倍体植物全基因组复制后重复基因的差异分离在个体之间产生PAV基因。
植物泛基因组的方法学发展
与易于识别和分类的单核苷酸多态性位点 (SNP)和少量InDels相比,即使基因组分析和计算技术得到了显着改进,与泛基因组相关的复杂遗传变异的正确表示仍然具有挑战性。在这里,我们总结了植物泛基因组研究的三个主要阶段:最早的方法主要依赖于高通量短序列的比对和组装来探索植物泛基因组的普遍性和复杂性;第二种方法是使用超高质量的基因组序列尽可能完整地揭示可变序列,以及最近出现的基因组“图”的方法通过提供统一的坐标系有望简化泛基因组的应用。
早期尝试用短测序序列/读长鉴定全基因组结构变异
长期以来,人们都知道植物的基因组成在有限的基因座上可能存在显著差异,但直到高通量短序列测序技术出现之前,基因组范围结构变异的鉴定仍然很困难。然而,尽管大多数短序列结构变异发现方法足够灵敏,可以发现多达数万个碱基的缺失,但它们通常无法识别相对较大的插入 (30 bp或更长)和其他复杂基因结构变异。一系列计算算法通过将短序列比对到参考基因组来鉴定基因组结构变异 (图2);例如,区域覆盖深度方法使用短序列在相关 DNA 片段中覆盖深度的波动来推断拷贝数变异 (CNVs)或PAVs。使用双端配对序列是另一种直接的方法;明显偏离整体插入片段尺寸分布的序列对中可能存在SVs。Pindel等其他工具使用了一种序列分割方法,以逐步将分割后的序列比对到被基因组结构变异打乱的不连续基因组区域。除了通过短序列比对来鉴定SVs外,短序列也可以转化为更短的k-mers,以研究个体之间的遗传组成差异,并且已经开发了方法来识别与植物性状相关的k-mers。
为了提高短序列识别SVs的能力,一种替代方法是首先将这些海量数据组装成相对较长的重叠群 (contigs) (高达数十万碱基),通常能够揭示植物中的大多数SVs。因此,组装短序列可以提高鉴定SVs的灵敏度和准确性,并减少假阳性SV的发现,这对于罕见SVs的研究至关重要。然而,大量短序列的组装主要依赖于de Bruijn图算法,该算法耗时且计算量大。因此,有人提出了一种简化的‘‘map-to-pan’’方法,通过首先将所有短序列与参考基因组比对,然后将数百甚至数千个个体的未比对到参考基因组的片段组装起来,来提高泛基因组构建的效率。通过这种策略组装的重叠群代表了所有个体的新序列的混合物,需要进一步重新把短序列比对上去,以明确特定个体的PAV状态。map-to-pan可能是最常用的方法之一,已成功在许多作物中构建了泛基因组,包括水稻、玉米、小麦、高粱、棉花和番茄 (表1)。
通过高质量基因组组装构建泛基因组
尽管基因区在短序列组装的基因组草图中基本都已覆盖,但基因间区往往是不完整的,这限制了其中SVs的识别。PacBio和Nanopore技术为代表的第三代长读长测序,以及Hi-C和BioNano等先进的遗传和物理图谱方法,很大程度上解放了基因组组装领域。这些最先进的技术可以常规性地产生N50高达数十兆碱基的重叠群 (contigs);这些重叠群保证了可以获得高质量的与蛋白质编码基因间隔分布的复杂非基因区的序列。特别是,最新的PacBio High-Fidelity (HiFi)和纳米孔超长技术已经实现了人类和复杂植物基因组的近乎完整组装 (稍后将详细讨论)。同时,已经开发了许多先进的基因组组装工具,如HiCanu、Hifiasm、MECAT、NECAT、NextDenovo、wtdbg2和Shasta,大大简化了组装程序 (与基于短序列的组装相比),并最大限度地提高了序列连续性和准确性。迄今为止,长度长测序已经帮助组装了拟南芥、水稻、玉米、小麦、大麦、高粱和大豆等主要植物物种的数十至数百个高质量基因组。
通过对这些高质量基因组进行全基因组比对 (WGA),SV鉴定的灵敏度和准确性得到了提高。为了更好的分析具有高重复序列且相对较大的植物基因组,比对工具Mummer、LastZ、Minimp2和AnchorWave等进行了开发或升级。一个基因组中存在而另一个基因组中缺失的序列,特别是那些通过多个比对工具交叉验证的序列,可以被归类为潜在的PAVs序列。滑动窗口方法也可用于将基因组分成相互重叠的短DNA片段来识别PAVs,与WGA相比,这加快了比对过程。除了PAVs,还可以使用Assemblytics、MUM&Co和smartie-sv等工具在两个基因组比对好的共线性区域内识别一些其他SVs。
然而,准确识别更复杂的SVs (如倒位、重复和易位)仍然具有挑战性,因为植物中存在许多容易引入错配的同源序列。因此,建议使用来自BioNano光学图谱、Hi-C染色质互作矩阵和长序列比对获得的独立数据来验证这些复杂SVs并细化其断点。也可以直接进行长序列的比对而不是组装来识别SVs,或者通过使用类似于短序列的“map-to-pan”策略来组装未比对回基因组的长序列来识别SVs。一些工作还试图通过结合多个染色体水平的高质量基因组的同源区域和共线性区域来直接构建泛基因网络。
新兴的基于图的泛基因组方法
对于通过‘‘map-to-pan’’或全基因组比较方法构建的泛基因组,可变序列被线性地附加到主干基因组序列上用于下游遗传分析。但是这种泛基因组受到每个SV基因座仅代表单个单倍型的限制。最近,将SVs的位置和替代序列沿着线性参考基因组存储为可缩放和紧凑的基因组图,被认为是更有效的泛基因组分析的的方法 (图2)。在基因组图中,SVs及其替代序列被记录为节点和边,从而改善了与SVs所在区域的序列的局部比对。基因组图可以通过将更多新识别的SVs合并到固定的线性参考基因组上来迭代升级,从而为不同工作的比较提供统一的坐标系统。尽管基因组图对人类和传统分析工具的可读性仍然较低,但Vg、SevenBridges、GraphAligner和minigrapher等新工具正在迭代开发中,以实现快速准确的序列比对和变异识别。
分析图基因组有两个主要步骤:首先存储和索引图,然后把测序序列比对到图基因组。迄今为止,植物中报告的所有图基因组都是使用Vg构建的。Vg是一种领先的基因组图形工具,可以整合复杂的SVs、简单的SNPs和小的InDels。也有其他工具可以优化数据结构和加速图基因组索引。基因组图在存储复杂的嵌套SVs方面具有独特的优势,例如带有SNPs的插入和源自同一位点的多个不同插入。然而,它们也面临着指数级的大量不真实单倍型的困扰,这些单倍型是由随机路径组合产生的,实际上并不存在于种群中。一个潜在的解决方案是给群体中确实存在的路径根据关键节点给予不同的颜色标记,以确保图中的所有路径都是“颜色一致”的,这一策略已经应用于使用de Bruijn图的组装和基因分型方法中。然而,分析“颜色”标记的基因组图的计算成本仍然相当高;例如,需要超过70,000个CPU小时和320 Gb RAM来为超过50,000个个体索引单条人类染色体 (chr17)。
构建和索引是基于图的泛基因组分析的主要限速步骤。一旦建立了图基因组,测序序列通常可以更快地与该图形参考基因组比对 (相比于传统的线性基因组比对)。HISAT2是一种常用的比对工具,已用于使用图FM索引算法将DNA和RNA测序序列比对到基因组图。其他工具包,包括Vg、SevenBridges和Graphtyper2,也能够将短序列片段比对到图中,并通过下游程序对SNPs和SVs进行鉴定和分型。我们预计专门为高保真长序列 (PacBio HiFi或ONT R10)或组装重叠群设计的图比对工具将更好地利用基于图的基因组来鉴定SVs。
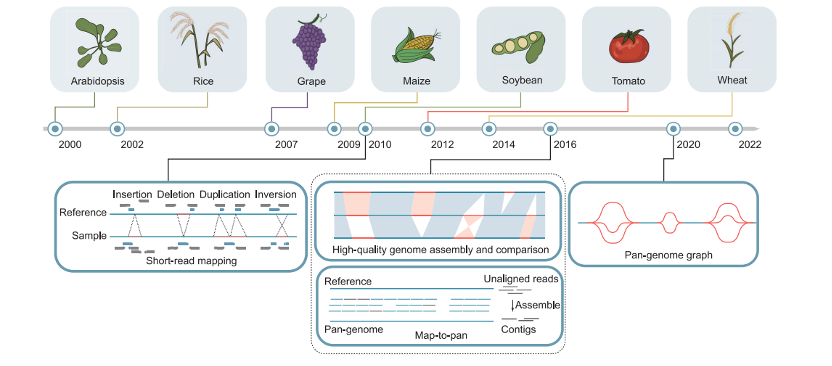
图2. 植物参考基因组构建中重大事件的时间表 (上)和植物泛基因组的表示方法 (下)。
2000年模式植物拟南芥的第一个参考基因组发布,随后多个重要作物包括水稻、葡萄、玉米、大豆、番茄和小麦的第一个参考基因组也发布。随着植物参考基因组的发布和短读长测序技术的成熟 (~2010),使用新颖的计算算法对复杂的SVs (插入、缺失、重复、倒位等)进行全基因组鉴定已经可以实现。2016年提出了一种‘‘map-to-pan’’策略,用于组装未对比回基因组的短序列来构建泛基因组。几乎与此同时,PacBio和Nanopore长读长测序技术的进步促进了高质量基因组的组装和比较,从而实现PAV序列的无偏鉴定和泛基因组构建。2020年,第一个基于图的植物泛基因组在大豆中构建,并且有望成为传统线性泛基因组方法的更好替代方案,以实现更有效的泛基因组分析。
主要植物物种的泛基因组学研究进展
近年来,随着泛基因组学方法的快速发展,植物泛基因组的主要特征被系统地研究。泛基因组大小可能是几乎所有研究中都涉及的最基本特征。在水稻3K项目中应用‘‘map-to-pan’’策略产生了在植物泛基因组中解析的首批序列之一 (约630 Mb),揭示了粳稻品种缺少的约268 Mb的新序列。最近的两项研究使用来自111种和251种不同水稻材料的基因组组合将这一估计值分别提升到约1250 Mb和约1520 Mb。这些研究揭示了水稻中惊人的高序列多样性,并表明之前使用的代表性的粳稻品种参考基因组仅占水稻基因组的一部分。
最近的水稻研究似乎也表明,通过比较多个长序列组装的泛基因组比通过‘‘map-to-pan’’方法构建的泛基因组具有更高的序列完整性,尽管它们使用的群体规模小于早期3K项目的群体规模。除水稻外,其他植物的泛基因组大小也做了研究,包括拟南芥、大豆、高粱、棉花、番茄和油菜 (表1),通常是其单个参考基因组大小的两到三倍。正如预期的那样,具有小而紧凑的基因组且最近没有多倍体化事件的植物物种,如拟南芥,往往具有相对较少的参考基因组外的新序列。除了构建基因组水平的泛基因组外,一种常用的替代方法,特别是对于具有复杂基因组的物种如玉米、大麦、小麦,是将蛋白质编码基因聚类成“泛基因”图中。
一般来说,随着更多基因组的加入,所有个体中存在的“核心”基因的百分比都会下降,最终到达一个约为35%的基准水平,就像在在二穗短柄草 (Brachypodium distachyon)中一样。这些“可有可无”的基因通常更值得注意,在水稻中的两项独立研究报告了类似数量的在粳稻品种中缺失的基因 (约1万个);这些基因通常富集在免疫和防御反应途径中,具有很大的抗药性育种潜力。玉米和小麦的泛基因数量更高,超过100,000 (表1)。考虑到玉米代表性参考基因组B73仅注释了约40000个基因,玉米似乎在26个不同的嵌套关联映射 (NAM)建立系 (diverse nested association mapping (NAM) founder lines)中具有最高比例的泛基因 (n=103 000)。
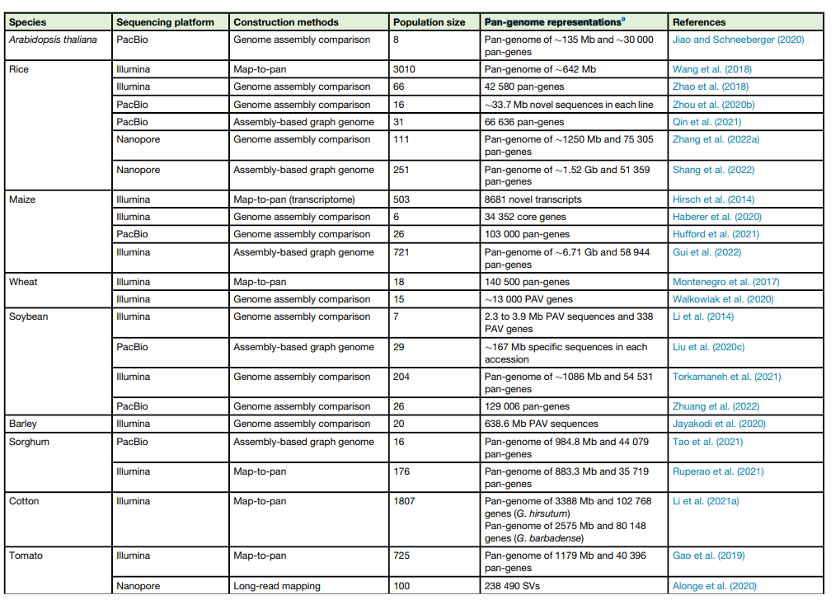
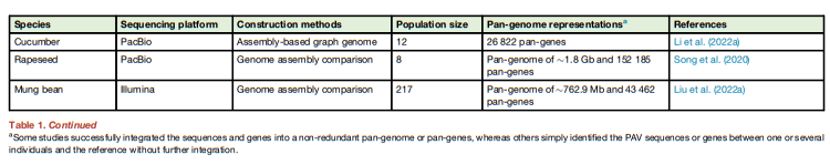
表1. 一些研究成功地将序列和基因整合到非冗余的泛基因组或泛基因中,另一些研究则简单地鉴定了一个或多个个体与参考序列之间的PAV序列或基因,而没有需进一步整合。
大豆、水稻、玉米、高粱、番茄和黄瓜中也报道了基于图的泛基因组。因为基于图的基因组可以使用短测序序列来发现SV,所以在这些工作中已经鉴定了大量新的SVs,并发现其与常见SNPs具有相对较低的连锁不平衡。进一步地,基于大豆和水稻中的这些SVs的全基因组关联研究 (GWAS)已经确定了许多农艺性状相关的新基因座。然而,基于图的基因组尚未被报道用于大型和复杂的植物基因组,例如大麦和小麦的基因组,这可能是因为它们的分析仍然需要大量的计算资源。
复杂植物基因组的绝大部分区域由非编码序列组成。用于研究非编码调控表观基因组的高通量基因组分析方法正在持续开发中,包括测序转座酶可接近的染色质 (ATAC-seq)、DNase I超敏位点测序 (DNase-I seq)、DNA亲和纯化测序、甲基化修饰测序、染色质免疫共沉淀测序 (ChIP-seq)、高通量染色体构象捕获测序 (Hi-C)、原位Hi-C偶联染色质免疫共沉淀和基于正电子发射断层扫描的染色质免疫共沉淀,已成功应用于各种植物物种。一个物种中多个个体的表观基因组可以揭示与种内转录动力学相关的调控元件的存在和缺失。
例如,ATAC-seq鉴定的约95%的调控区域在在26个玉米NAM之间是保守的。在水稻中,已经为20个品种产生了各种组蛋白修饰和RNA聚合酶II的染色质免疫沉淀测序数据,显示出不同组蛋白修饰标记的调节元件的保守性约为30%至80%。这些数据表明,在两个不同的玉米品系之间,非编码功能元件 (至少是与玉米中染色质可及性相关的功能元件)的保守度可能与蛋白质编码基因的保守度一样高,甚至更高。他们还表明,不同表观遗传标记的功能性非编码元件具有不同程度的序列保守性。然而,这些研究在很大程度上依赖于单个线性参考基因组来比对短序列,后续改进的分析工作流程将使用基于图的基因组作为分析多个个体的“表观泛基因组”数据的新参考序列。
虽然泛基因组最初被认为代表种内序列多样性,但最近已被扩展到包括来自多个相关物种的个体,以构建更全面的“超级泛基因组”。在作物中,超级泛基因组研究通常整合野生亲缘物种和栽培品种,因此它们是研究和利用野生等位基因进行作物改良的重要途径。不仅直系祖先 (比如Zea mays ssp. Parviglumis),其他作物亲属 (Zea mays ssp. mexicana, Zea perennis, Zea luxurians, etc.)也可以被纳入超级泛基因组分析,因为后者也可以对作物适应过程做出重大贡献。
最近发布了一个玉米属范围的超级泛基因组(约6.71 Gb),包含约4.57 Gb的不存在于B73参考基因组中的序列。大豆属、高粱属、柑橘属和萝卜属也构建了超级泛基因组。最近,亚洲和非洲水稻超级泛基因组项目共组装了251份野生 (O.rufipogon和O.barthii)和栽培 (O.sativa和O.glaberrima)样本,其中野生亚洲样本具有明显多于栽培样本的非必须NLR基因(Nucleotide-binding site, leucine-rich repeat ( NLR) genes play a critical role in rice disease resistance)。总的来说,野生种倾向于在作物超级泛基因组中贡献更多的序列多样性,特别是在作物驯化过程中由于遗传瓶颈而在栽培品种中丢失的野生等位基因。越来越多的证据还表明,这些野生等位基因可能在调节作物的适应性性状方面发挥着关键作用,再次突出了超级泛基因组对促进作物改良的重要性。
端粒-到-端粒(T-2-T)植物基因组的解码
尽管我们已经做出了巨大努力来提高植物基因组的完整性,但迄今为止发表的几乎所有植物基因组都是不完整的,序列缺口由多个连续的Ns表示。这些缺口主要来自端粒和端粒周围区域的长重复序列、核糖体DNA、串联基因重复序列和复杂的嵌套转座子,这些仍然难以使用传统的测序和组装策略进行准确和完整地组装。因此,在由这些不完整序列构建的植物泛基因组中,无法研究这些“硬核”区域的变异性;这些区域通常涉及减数分裂动力学、基因组稳定性、染色质可及性和其他基本生物过程的调控。最近,一系列T-2-T基因组计划被提出,其共同目标是获得从一个端粒到另一个端粒的所有染色体序列。T-2-T基因组对于构建基于图的泛基因组也将具有重要意义,因为它们可以用作图中的骨干序列,而无需进一步升级,从而为跨项目比较提供了统一的坐标系统,并使新识别的变体能够迭代合并。
使用足够长的序列来跨越这些未测通的复杂缺口的能力是T-2-T基因组组装成功的关键。纳米孔测序技术现在可以产生大小达百万碱基的超长序列 (N50超过100 kb),因此是T-2-T组装的基础。做个类比,这些超长的序列与经典BAC序列一样长,这是构建金标准参考基因组的最佳方法之一。然而,即使在多轮序列叠联群自我一致性校正之后,仅来自纳米孔序列的组装仍然存在相对较高的碱基错误率。因此,PacBio HiFi序列通常被用来校正纳米孔测序技术获得的组装和修复残存的基因组空隙区域。
对于小而简单的基因组,如拟南芥和水稻的基因组,仅使用PacBio-HiFi序列就足以完成T-2-T组装。在基于长序列的初步组装之后,物理和遗传图谱 (BioNano、Hi-C和10X连锁图谱)可以独立用于检测和修复错误组装。但它们通常无法进一步提高序列的连续性,因为重叠群的大小通常远远超过物理和遗传图的大小。当有些区域始终难以完成组装时,可以尝试首先通过CRISPR-Cas9辅助切割来富集这些区域,然后独立地测序和组装它们,作为序列补丁完成无间隙组装。通过整合这些最先进的基因组技术,可以用成功穿过染色体臂和着丝粒周围区域的超长重叠群产生无间隙组装。然而,只有那些成功延伸到染色体两个端粒末端(由简单重复序列的长末端阵列 (水稻中为50-AAACCCT-30)表示)的组装,才能被归类为T-2-T组装。
人类T-2-T基因组协作组织报告了高等真核生物中的第一个T-2-T组装,即完整的人类X染色体,所有人类染色体的组装于2022年完成。在几乎同一时期,还构建了一系列无间隙或T-2-T植物基因组参考序列 (表2),特别是在模式植物拟南芥和水稻中。目前,经典拟南芥参考基因组Col-0有三种不同的T-2-T组装版本 (Col-CEN、Col-XJTU和Col-PEK),为着丝粒相关卫星变体 (CEN180)的序列组成和变异提供了重要信息。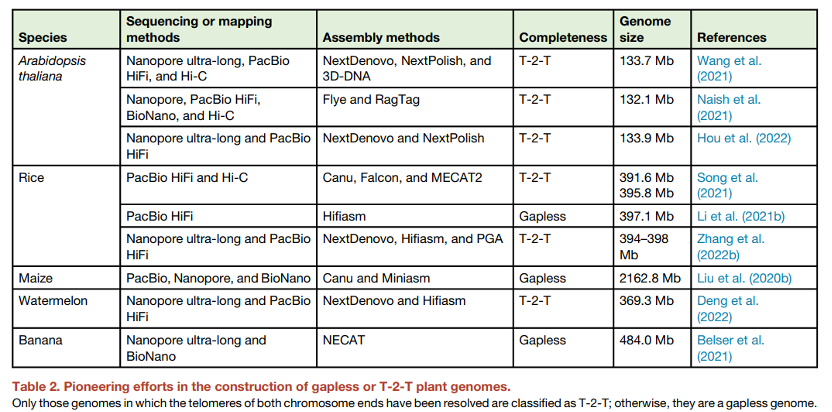
表2. 构建无间隙或T-2-T植物基因组方面的开创性努力。只有那些两条染色体末端的端粒都被解码的基因组才被归类为T-2-T;否则,它们就是一个无间隙的基因组。
Col CEN组装中的五个着丝粒之一显示了ATHILA逆转录元件的大量历史易位,这表明拟南芥中的着丝粒进化很快。对玉米B73-Ab10组装的两条无间隙染色体中的完整着丝粒的分析表明:与拟南芥不同,玉米中的着丝粒长简单重复序列 (CentC)相对较低,尤其是富含逆转录因子的三个着丝粒。除了这些对非基因区高拷贝重复序列的新认识外,最近还发现了功能重要的蛋白编码基因:ZS97和MH63无间隙水稻组装中发现了40和25个新基因,Col-PEK T-2-T组装中有213个新基因。香蕉和西瓜的T-2-T或无间隙组装也有报道,更复杂的玉米 (J.S.和J.L.未发表的结果)和大麦T-2-T基因组的重要进展正在进行中。T-2-T组装的成功是一个重要的里程碑,它填补了最终的“暗物质”,并能够解码所有DNA序列、结构、表观遗传特征和植物基因组的基因功能。
无论是二倍体还是多倍体,植物基因组总是来自两组亲代染色体的组合,在异花授粉的物种或杂交种中可能保持高度杂合状态。长期以来,很难组装一个高度杂合的基因组。因此,一个替代策略是简单地将两个亲代单倍型的测序片段折叠成一组“马赛克”重叠群。然而,这种策略可能导致与杂种优势和等位基因特异性基因表达相关的重要亲本遗传变异检测不到。借助长序列,特别是PacBio HiFi序列,现在技术上有可能产生单倍型解析的基因组组装。然而,这些组装中的大多数区域可能仍然代表两个单倍型的重叠群的混合,必须进一步分型 (phasing)。
家系分箱策略 (trio-binning)利用来自双亲的高通量短读长序列构建 k-mers,根据单倍型特异的 k-mer对F1代中测序的长读长序列进行亲本单倍型分箱,然后将分箱后的片段单独组装成两个单倍型组装。这一策略成功用于组装高度杂合的墨西哥类蜀黍基因组。此外,高密度遗传图谱可以很容易地在植物中构建,并用于将嵌合组装分型为两个单倍型,这在高度杂合的二倍体马铃薯和苹果中得到了证明。最近,使用改进的Hifiasm算法可以在不需要亲本信息的情况下单独使用Hi-C数据获得单倍体组装。除了二倍体植物物种外,还尝试在四倍体物种 (蓝莓和苜蓿)生成单倍型染色体组装,即同源染色体组装的四等位基因集合。单倍型解析基因组组装的成功对于许多无性繁殖的作物具有特别重要的意义,因为它们的基因组高度杂合,并且抗自交纯化。
泛基因组在植物遗传研究和育种中的应用
在过去二十年中,我们见证了作物育种的重大进展,这主要是因为基因组资源和技术的进步已经完全整合到标记辅助选择、基因聚合、基因组选择 (GS)和基因编辑方法中。然而,如果我们要为快速增长的世界人口生产足够的粮食,就必须不断加快作物育种。泛基因组与传统的单一参考基因组相比显示出许多优势,因此将在作物遗传研究和分子育种中发挥越来越重要的作用。
关联定位
关联定位已被广泛用于剖析植物复杂性状的遗传基础。它利用自然群体 (例如核心种质集合)中的历史重组 (反映在相邻标记之间的连锁不平衡)来测试遗传标记和表型变异之间的关联。对研究群体进行基因分型,需要将群体的测序短序列正确地比对到参考基因组,这对关联定位的成功至关重要。使用泛基因组作为参考可以减少源自参考基因组中缺失的序列的错误比对,并揭示可变基因组序列中更多潜在的遗传变异 (图3)。例如,水稻3K项目通过将短测序序列与约374 Mb的粳稻品种基因组比对,识别了约2900万个高质量SNPs;如果将约642 Mb的水稻泛基因组作为参考,我们可能会识别出更多的SNPs,因为新添加的序列被认为比核心序列更“可变”。
关于准确性,基于图基因组的使用已被证明在将短序列与复杂SVs区域比对方面具有优势,并且已经开发了诸如Vg和Giraffe等下游工具,以实现群体SVs的快速基因分型。最近,基于泛基因组图的SVs已成功用于大豆、水稻、番茄和黄瓜的GWAS分析,鉴定了许多无法通过线性参考基因组SNP分析识别的新基因座。例如,使用水稻图基因组鉴定的一段长末端重复序列 (LTR)插入 (987 bp)被鉴定为叶片衰老的可能诱发变体,但使用基于单个线性参考基因组的常见SNPs分析则无法检测到。除了关联定位之外,泛基因组还可能在改善其他定位群体的基因分型方面具有巨大的前景,特别是那些涉及多个遗传远亲的群体,如联合连锁关联定位和NAM群体。
群体基因组分析
近年来,在作物中进行了许多大规模的重测序工作,揭示了与作物驯化、适应和育种过程相关的遗传多样性、种群结构、历史选择性清除 (historical selective sweeps)和种群历史 (demographic history)。然而,这些分析几乎完全基于群体SNPs或小InDels。越来越多的证据表明,用SVs估计的种群结构可能与用SNPs估计的种群结构有所不同。此外,一些大规模SVs,如B73参考基因组中缺失的兆碱基尺度的PAV序列,已被发现在玉米中处于进化选择中。由于泛基因组现在可用于广泛的植物物种 (表1),我们预计使用泛基因组作为参考,对已发表的大规模重测序数据进行重新分析的数量会增加,以确定更全面的一组遗传变异并更新先前的种群基因组结果。利用先前使用的线性基因组提供的统一坐标系统作为基因组图的主干,再使用基于图的基因组重新分析主要作物的选择性清除尤其有前景。
表观遗传学研究
表观遗传学特征,包括DNA甲基化、组蛋白修饰、小非编码RNA、染色质可及性和三维结构,都表现出强烈的组织和细胞类型特异性,这在植物中已被广泛研究。除了这种个体内的表观遗传变异外,表观遗传特征在个体间也存在差异,作为表观等位基因,可被捕获或创造用于作物改良。越来越多的研究探索了与作物驯化和育种过程相关的种群表观遗传变异。然而,当遗传距离较远的个体的短序列比对到线性参考基因组时,这些分析可能会受到比对偏差的影响,从而导致表观遗传信号的不公平比较。几项已发表的研究试图通过将带有SNPs的参考基因组替换为“伪”参考基因组而不改变基因组坐标来降低这种比对偏差,这一想法基本上类似于图基因组的概念。由于图基因组更为复杂,我们预计它将是一种更好的解决方案,用于比对群体表观遗传数据,同时还将提供新设计的工具用于识别表观遗传变异,并通过表观基因组范围的关联研究进一步发现功能性表观等位基因。
全基因组选择育种.
GS是使用训练群体的全基因组DNA标记和目标性状来预测表型未知的育种群体的基因组育种值的过程。由于GS是基于在幼年阶段就可以拿到的用于基因分型的DNA标记,它可以大大减少传统表型选择所需的大规模田间试验的时间和成本,并加快育种周期。许多因素,包括连锁不平衡、统计模型、群体组成、DNA标记和性状遗传力,都会影响GS的表现。与GWAS一样,全基因组SNPs也常用于GS。然而,早期研究表明,普通SNPs只能解释少数复杂性状的狭义遗传力,这引出了一个影响了临床应用和育种实践中的预测准确性的被称为“消失的遗传力”的问题。自从这个问题被提出以来,大量的研究工作一直致力于寻找“消失的遗传力”的潜在来源。最近在番茄上的一项研究表明,使用图基因组作为参考的SVs部分挽救了复杂性状的“消失的遗传力”,这可能是因为SVs和难以用常见SNPs捕获的驱动变异之间存在更强的连锁不平衡,以及长期以来的假设,即SVs更可能是驱动变异。这些新建立的基因分型程序,以及先进的预测算法,如深度学习方法,有望通过新的GS方法进一步提高作物的遗传增益。
基因聚合与分子育种
广泛的等位基因变异是重要性状变异的遗传基础,对基因聚合和作物育种至关重要。例如,数量性状基因及其因果变异 (数量性状核苷酸[QTNs]),包括SNPs、小InDels和其他复杂SVs,已经被系统地编目并集成到水稻基因组导航系统 (RiceNavi)中,以指导水稻育种设计。基因分型过程对于重新创建或改进现有的优良品种至关重要,这通常依赖于短测序序列的比对和变异检测来选择具有良好QTN的重组品系。如前所述,该策略对于从SNPs和小InDel中识别大多数QTN是很好的,但它在识别复杂的具有深刻的遗传效应的SVs方面则存在较大局限。因此,泛基因组有望进一步优化与更复杂SVs相关的基因的选择和聚合 (pyramiding),特别是对仅存在于野生亲缘关系中且在当前育种实践中很少使用的基因。
长期存在的自然遗传变异已普遍用于作物育种。基因组编辑,主要通过CRISPR-Cas9技术,通过创建以前不存在的等位基因为加速育种提供了一种强大的新策略。基因组编辑系统也在植物中快速发展,以提高编辑效率,并从更多样的遗传背景中扩展可编辑基因座和受体。在这方面,泛基因组不仅可以提供值得编辑的主要候选基因列表,还可以通过提供高质量的基因组序列来建立优化的编辑系统来扩展可行的作物物种或品种。作为案例,最近的一项研究报告了野生四倍体水稻 (O.alta)的基因组联合高效的基因组编辑系统,为新作物的重新驯化建立了一条实用的路线。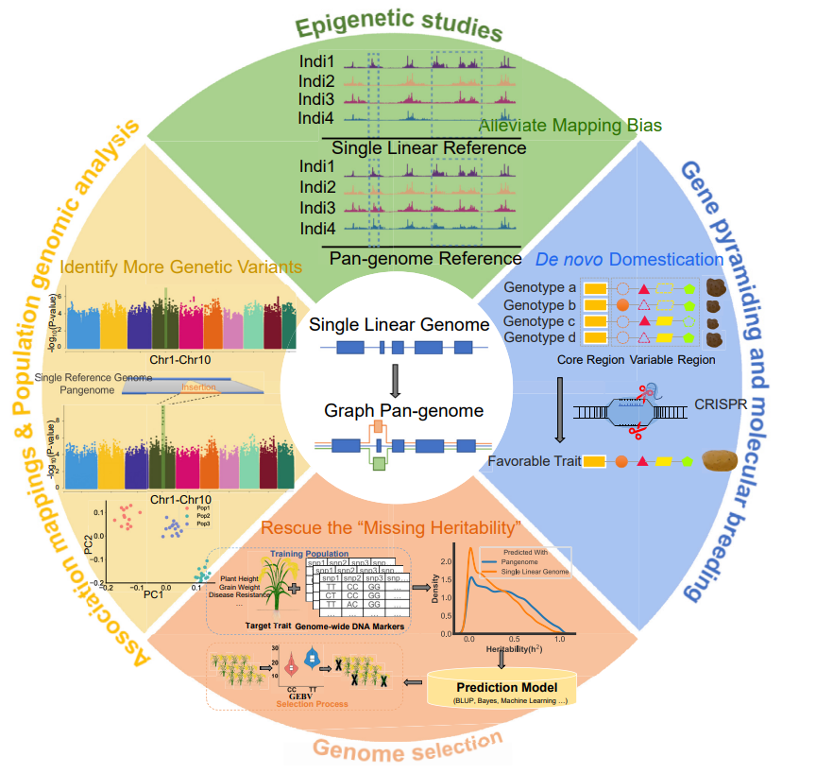
图3. 泛基因组在遗传研究和育种实践中的应用。
使用泛基因组作为新的参考可能会促进发现与重要性状相关的更多新位点,特别是对于线性参考基因组中不存在的复杂SVs (图3左边部分)。泛基因组因为鉴定的遗传变异的准确性更高,也可以改善群体基因组的分析。使用图基因组鉴定的群体SVs已被证明可以挽救部分复杂性状的“消失的遗传力”,这对于基因组选择很重要 (图3底部)。图基因组有希望降低比如来自远遗传距离个体的表观数据与单个线性参考基因组的比对偏差,进而促进表观等位基因的无偏差性鉴定 (图3上部)。最后,泛基因组可以帮助识别可用于基因编辑的重要可变基因,并在新作物物种或品种中建立新的编辑系统,以进行从头作物驯化 (图3右边部分)。
挑战和前景
植物泛基因组研究的兴起无疑是推动使用群体DNA序列作为补充甚至替代单一线性基因组作为新的参考基因组,并实现更有效的遗传分析的重要里程碑之一。随着表征泛基因组的测序和计算算法的不断进步,关于“植物泛基因组”主题的研究文章数量不断增加,揭示了与植物重要进化轨迹和性状变异相关的前所未有的高基因组变异性。尽管在少数已发表的高质量泛基因组的植物物种与已组装的1000多个植物参考基因组之间仍有很大差距,我们期望植物泛基因组在基础研究和育种应用中发挥越来越重要的作用。
在缺乏标准化分析流程的情况下,先前发表的一些植物泛基因组研究中的分析相对随意。在这里,我们建议植物泛基因组分析的三步流程:第一步是通过聚类所有可用的基因组序列来构建非冗余的泛基因组序列和泛基因集。强烈建议在该过程中使用PacBio HiFi或Nanopore超长测序技术,以确保测序序列和组装序列的高质量。然后,在第二步中,通过执行多组学分析,对所识别的可变和核心序列/基因进行深度注释,以揭示它们与转座子、染色质可及性、基因转录以及对性状变异和人工选择的贡献关系。最后,将所有基因组排列到超高质量的骨干基因组上,用于SVs的鉴定和泛基因组图的构建。植物T-2-T基因组是该图基因组的理想主干部分,不需要频繁升级,确保了可供后续比较的统一坐标系统。群体测序序列可以进一步与这些图基因组比对,以促进遗传图谱、GS、表观遗传学研究和分子育种,还需要进一步加快与图基因组兼容的更复杂工具的开发。
构建植物超级泛基因组的过程也应该加快。尽管大多数作物的总体等位基因变异很高,但在驯化后,野生亲属中存在的大量遗传多样性已经丧失,特别是在经常参与重要性状调控的选定基因中。因此,需要新的方法来发现和充分利用以前未开发的野生等位基因,以维持遗传增益。我们现在正在认识到未开发野生草类DNA中编码的巨大潜力,正在进行测序和组装这些野生基因组的研究工作。即将到来的植物超级泛基因组研究热潮可以帮助我们描绘过去的进化过程,并指导未来的设计育种。
每日书籍推荐 - R速成:统计分析和科研数据分析快速上手
《R速成:统计分析和科研数据分析快速上手》是挪威一位心理学教授和神经科学教授联手写成,第一次在国内推出中文版,由庄亮亮和赵子茜翻译,电子工业出版社于2023年4月出版。全书共 15 章,第 1 章详细介绍了 R 和 RStudio 的安装方法;第 2 章至第 3 章介绍了导入数据的方法,以及 R 的基本工作原理;第 4 章介绍了 R 中重要的数据 管理方法;第 5 章讲解数据可视化的知识;第 6 章至第 15 章介绍了统计知识点,如描述性统计、 简单线性回归、多元线性回归、虚拟变量回归等。

往期精品(点击图片直达文字对应教程)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|




























机器学习
后台回复“生信宝典福利第一波”或点击阅读原文获取教程合集