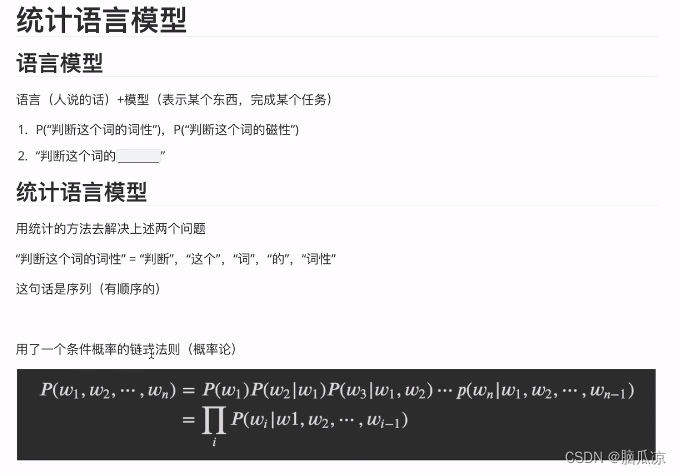
6. 树的入门
之前我们实现的符号表中,不难看出,符号表的增删查操作,随着元素个数N的增多,其耗时也是线性增多的,时间复杂度都是O(n),为了提高运算效率,接下来我们学习树这种数据结构。
6.1 树的基本定义
树是我们计算机中非常重要的一种数据结构,同时使用树这种数据结构,可以描述现实生活中的很多事物,例如家
谱、单位的组织架构、等等。
树是由n(n>=1)个有限结点组成一个具有层次关系的集合。把它叫做“树”是因为它看起来像一棵倒挂的树,也就
是说它是根朝上,而叶朝下的。
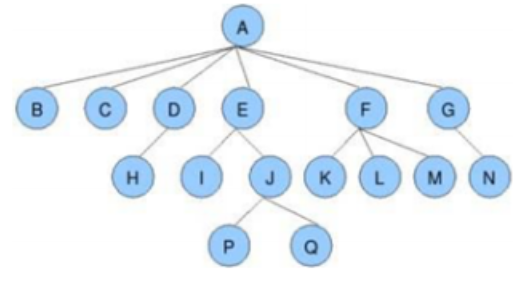
树具有以下特点:
1.每个结点有零个或多个子结点;
2.没有父结点的结点为根结点;
3.每一个非根结点只有一个父结点;
4.每个结点及其后代结点整体上可以看做是一棵树,称为当前结点的父结点的一个子树;
6.2 树的相关术语
结点的度:
一个结点含有的子树的个数称为该结点的度;
叶结点:
度为0的结点称为叶结点,也可以叫做终端结点
分支结点:
度不为0的结点称为分支结点,也可以叫做非终端结点
结点的层次:
从根结点开始,根结点的层次为1,根的直接后继层次为2,以此类推
结点的层序编号:
将树中的结点,按照从上层到下层,同层从左到右的次序排成一个线性序列,把他们编成连续的自然数。
树的度:
树中所有结点的度的最大值
树的高度(深度):
树中结点的最大层次
森林:
m(m>=0)个互不相交的树的集合,将一颗非空树的根结点删去,树就变成一个森林;给森林增加一个统一的根
结点,森林就变成一棵树。
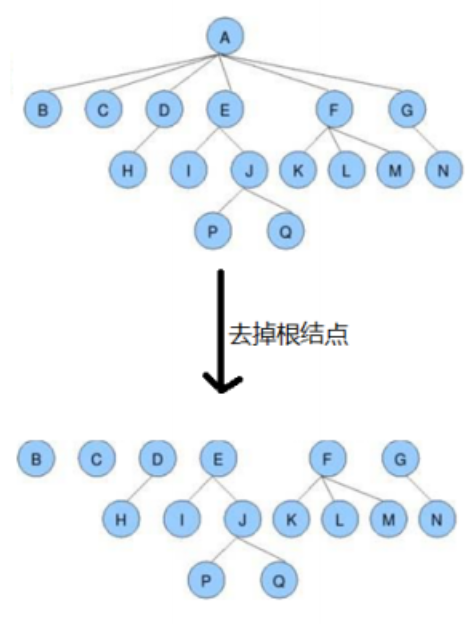
孩子结点:
一个结点的直接后继结点称为该结点的孩子结点
双亲结点(父结点):
一个结点的直接前驱称为该结点的双亲结点
兄弟结点:
同一双亲结点的孩子结点间互称兄弟结点
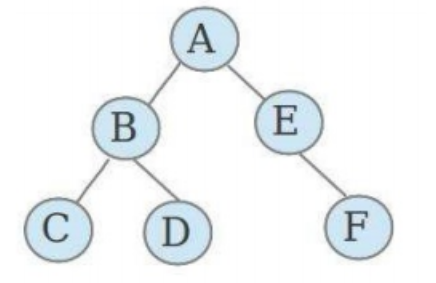
6.3 二叉树的基本定义
二叉树就是度不超过2的树(每个结点最多有两个子结点)
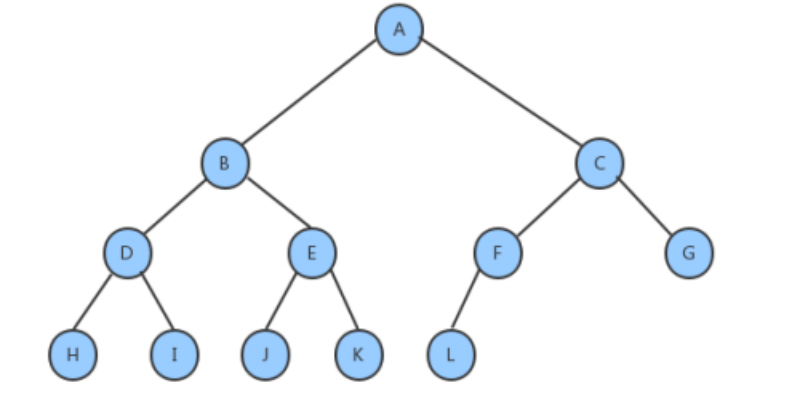
满二叉树:
一个二叉树,如果每一个层的结点树都达到最大值,则这个二叉树就是满二叉树。

完全二叉树:
叶节点只能出现在最下层和次下层,也就是说除了最下层别的层都是满的,并且最下面一层的结点都集中在该层最左边的若干位置的二叉树。
6.4 二叉查找树的创建
6.4.1 二叉树的结点类
根据对图的观察,我们发现二叉树其实就是由一个一个的结点及其之间的关系组成的,按照面向对象的思想,我们
设计一个结点类来描述结点这个事物。
结点类API设计:

代码实现:
package com.ynu.Java版算法.U6_树的入门.T4_二叉查找树的创建.S1_二叉树的节点类;
// 二叉树的节点类
// 存放的是键值对
public class Node<Key,Value> {
//存储键
public Key key;
//存储值 -- 值是私有的 不能直接 对象+点 访问
private Value value;
//记录左子结点
public Node left;
//记录右子结点
public Node right;
public Node() {
}
public Node(Key key, Value value, Node left, Node right) {
this.key = key;
this.value = value;
this.left = left;
this.right = right;
}
}
6.4.2 二叉查找树API设计

6.4.3 二叉查找树实现
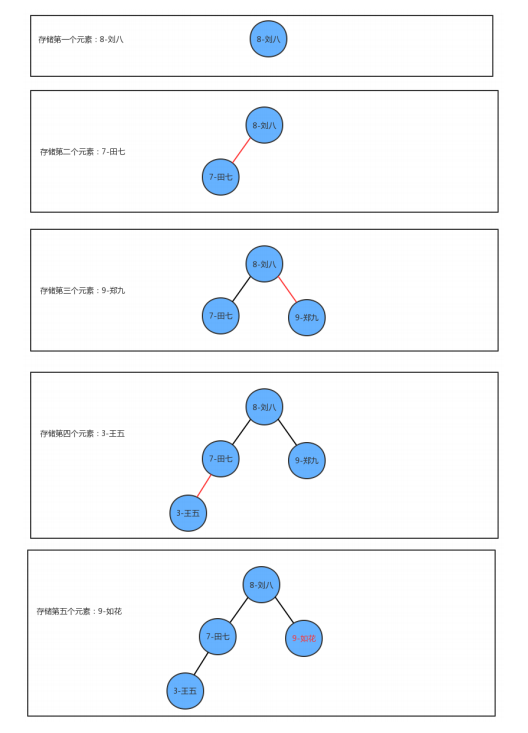
查询方法get实现思想:
从根节点开始:
-
如果要查询的key小于当前结点的key,则继续找当前结点的左子结点;
-
如果要查询的key大于当前结点的key,则继续找当前结点的右子结点;
-
如果要查询的key等于当前结点的key,则树中返回当前结点的value。
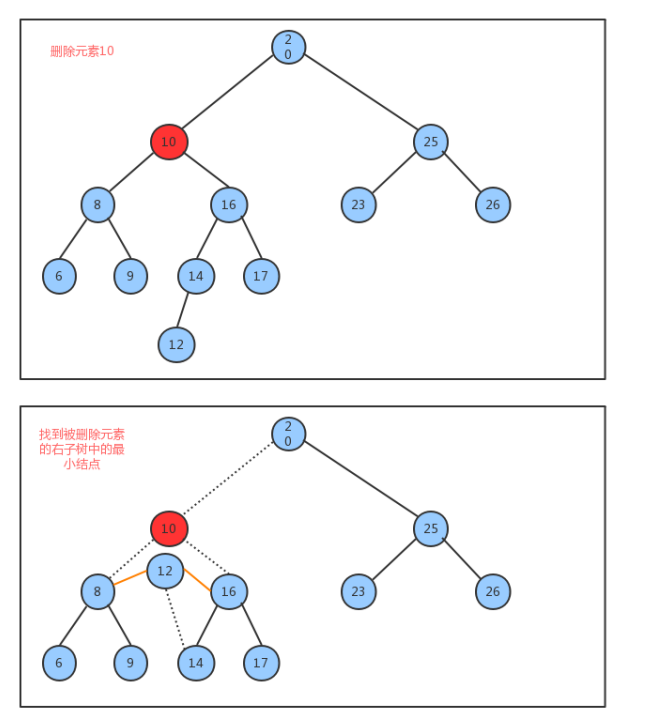
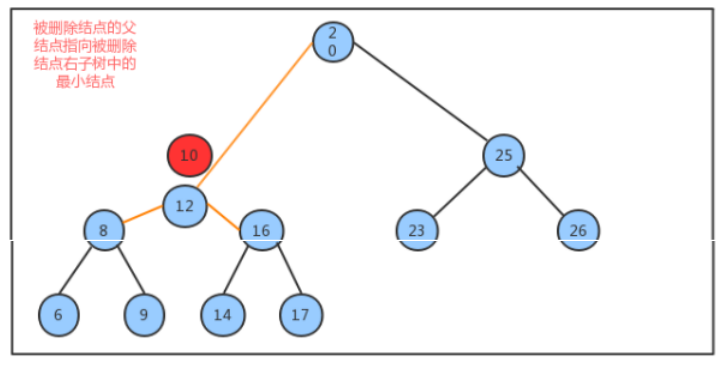
删除方法delete实现思想:
-
找到被删除结点;
-
找到被删除结点右子树中的最小结点minNode
-
让被删除结点的左子树成为最小结点minNode的左子树,让被删除结点的右子树成为最小结点minNode的右子树
-
让被删除结点的父节点指向最小结点minNode
二叉树的增删改查都和递归有关系。
package com.ynu.Java版算法.U6_树的入门.T4_二叉查找树的创建.S2_二叉查找树API设计;
public class BinaryTree<Key extends Comparable<Key>,Value> {
//记录根结点
private Node root;
//记录树中元素的个数
private int N;
// 获取树种元素的个数
public int size(){
return N;
}
//向当前的树x中添加key-value,并返回添加元素后新的树
public void put(Key key,Value value){
root = put(root,key,value);
}
// 增
//向指定的树x中添加key-value,并返回添加元素后新的树
public Node put(Node node,Key key,Value value){
// 这就是递归的出口
if (node==null){
N++; //树的节点个数加1
return new Node(key,value,null,null);
}
int cmp = key.compareTo(node.key);
if (cmp>0){
//新结点的key大于当前结点的key,继续找当前结点的右子结点
// 下一层递归
node.right = put(node.right, key, value);
}else if (cmp < 0){
//新结点的key小于当前结点的key,继续找当前结点的左子结点
// 下一层递归
node.left = put(node.left,key,value);
}else {
//新结点的key等于当前结点的key,修改值
node.value = value;
}
return node;
}
//查询当前树中指定key对应的value
public Value get(Key key){
return get(root,key);
}
//从指定的树x中,查找key对应的值
public Value get(Node node,Key key){
// 递归出口
if (node==null){
return null;
}
int cmp = key.compareTo(node.key);
if (cmp>0){
//如果要查询的key大于当前结点的key,则继续找当前结点的右子结点;
return get(node.right,key);
}else if (cmp<0){
//如果要查询的key小于当前结点的key,则继续找当前结点的左子结点;
return get(node.left,key);
}else {
//如果要查询的key等于当前结点的key,则树中返回当前结点的value。
return node.value;
}
}
//删除树中key对应的value
public void delete(Key key){
root = delete(root,key);
}
//删除指定树中key对应的value
public Node delete(Node node,Key key){
if (node==null){
return null;
}
int cmp = key.compareTo(node.key);
if (cmp>0){
//新结点的key大于当前结点的key,继续找当前结点的右子结点
return delete(node.right,key);
}else if (cmp<0){
//新结点的key小于当前结点的key,继续找当前结点的左子结点
return delete(node.left,key);
}else {
//新结点的key等于当前结点的key,当前x就是要删除的结点
//1.如果当前结点的右子树不存在,则直接返回当前结点的左子结点
if (node.left==null){
return node.right;
}
//2.如果当前结点的左子树不存在,则直接返回当前结点的右子结点
if (node.right==null){
return node.left;
}
// 都不存在其实就是返回空了 无需单独判断
// 3.左右节点都存在找到右子树中的最小节点替换当前节点
// 3.1 去寻找右子树的最小节点
Node pre = node; // 记录最小节点的父节点
Node minNode = node.right;
while (minNode.left!=null){
pre = minNode;
minNode = minNode.left;
}
//3.2 删除右子树的最小节点并且替换到当前节点
pre.left = null;
minNode.left = node.left;
minNode.right = node.right;
node = minNode;
N--;
}
return node;
}
private class Node {
//存储键
public Key key;
//存储值 -- 值是私有的 不能直接 对象+点 访问
private Value value;
//记录左子结点
public Node left;
//记录右子结点
public Node right;
public Node() {
}
public Node(Key key, Value value, Node left, Node right) {
this.key = key;
this.value = value;
this.left = left;
this.right = right;
}
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
return "BinaryTree{}";
}
}
package com.ynu.Java版算法.U6_树的入门.T4_二叉查找树的创建.S2_二叉查找树API设计;
public class Main {
public static void main(String[] args) {
BinaryTree<Integer,String> binaryTree = new BinaryTree<>();
binaryTree.put(10,"ybh");
binaryTree.put(9,"ybh");
binaryTree.put(12,"lmj");
binaryTree.put(7,"czx");
binaryTree.put(25,"lh");
binaryTree.put(11,"lh");
System.out.println(binaryTree.size());
binaryTree.delete(12);
System.out.println(binaryTree.size());
}
}
6.4.4 二叉查找树其他便捷方法
6.4.4.1 查找二叉树中最小的键
在某些情况下,我们需要查找出树中存储所有元素的键的最小值,比如我们的树中存储的是学生的排名和姓名数
据,那么需要查找出排名最低是多少名?这里我们设计如下两个方法来完成:

6.5 二叉树的基础遍历
很多情况下,我们可能需要像遍历数组数组一样,遍历树,从而拿出树中存储的每一个元素,由于树状结构和线性
结构不一样,它没有办法从头开始依次向后遍历,所以存在如何遍历,也就是按照什么样的搜索路径进行遍历的问
题。
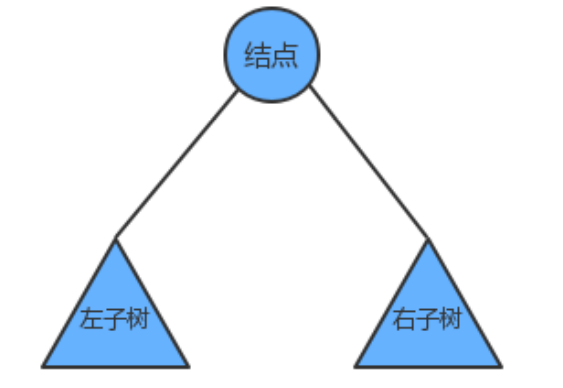
我们把树简单的画作上图中的样子,由一个根节点、一个左子树、一个右子树组成,那么按照根节点什么时候被访
问,我们可以把二叉树的遍历分为以下三种方式:
-
前序遍历;
先访问根结点,然后再访问左子树,最后访问右子树
-
中序遍历; 中序遍历二叉查找树得到的是升序序列
先访问左子树,中间访问根节点,最后访问右子树
-
后序遍历;
先访问左子树,再访问右子树,最后访问根节点
如果我们分别对下面的树使用三种遍历方式进行遍历,得到的结果如下:

6.5.1 前序遍历
我们在6.4中创建的树上,添加前序遍历的API:
public Queue <Key> preErgodic():使用前序遍历,获取整个树中的所有键
private void preErgodic(Node x,Queue <Key> keys):使用前序遍历,把指定树x中的所有键放入到keys队列中实现过程中,我们通过前序遍历,把每个结点的键取出,放入到队列中返回即可。
// 前序遍历指定的树
private void preErgodic(Node node){
if (node==null){
return;
}
queue.add(node.key); //遍历当前节点
// 遍历左子树
if (node.left!=null){
preErgodic(node.left);
}
// 遍历右子树
if (node.right!=null){
preErgodic(node.right);
}
}
6.5.1 中序遍历
我们在6.4中创建的树上,添加前序遍历的API:
public Queue<Key> midErgodic():使用中序遍历,获取整个树中的所有键
private void midErgodic(Node x,Queue<Key> keys):使用中序遍历,把指定树x中的所有键放入到keys队列中 。
// 中序遍历整棵树
public Queue<Key> midErgodic(){
queue.clear();
midErgodic(root);
return queue;
}
// 中序遍历整棵树
public void midErgodic(Node node){
if (node==null){
return;
}
if (node.left!=null){
midErgodic(node.left);
}
queue.add(node.key);
if (node.right!=null){
midErgodic(node.right);
}
}
6.5.3 后序遍历
我们在6.4中创建的树上,添加前序遍历的API:
public Queue<Key> afterErgodic():使用后序遍历,获取整个树中的所有键
private void afterErgodic(Node x,Queue<Key> keys):使用后序遍历,把指定树x中的所有键放入到keys队列中。
// 后序遍历这整棵树
public Queue<Key> afterErgodic(){
queue.clear();
afterErgodic(root);
return queue;
}
public void afterErgodic(Node node){
if (node==null){
return;
}
if (node.left!=null){
afterErgodic(node.left);
}
if (node.right!=null){
afterErgodic(node.right);
}
queue.add(node.key);
}
6.6 二叉树的层序遍历
所谓的层序遍历,就是从根节点(第一层)开始,依次向下,获取每一层所有结点的值,有二叉树如下:
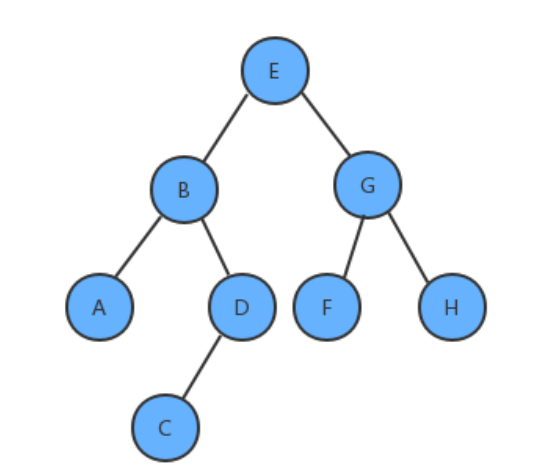
那么层序遍历的结果是:EBGADFHC
我们在6.4中创建的树上,添加层序遍历的API:
public Queue<Key> layerErgodic():使用层序遍历,获取整个树中的所有键
实现步骤:
1.创建队列,存储每一层的结点;
2.使用循环从队列中弹出一个结点:
2.1 获取当前结点的key;
2.2 如果当前结点的左子结点不为空,则把左子结点放入到队列中
2.3 如果当前结点的右子结点不为空,则把右子结点放入到队列中
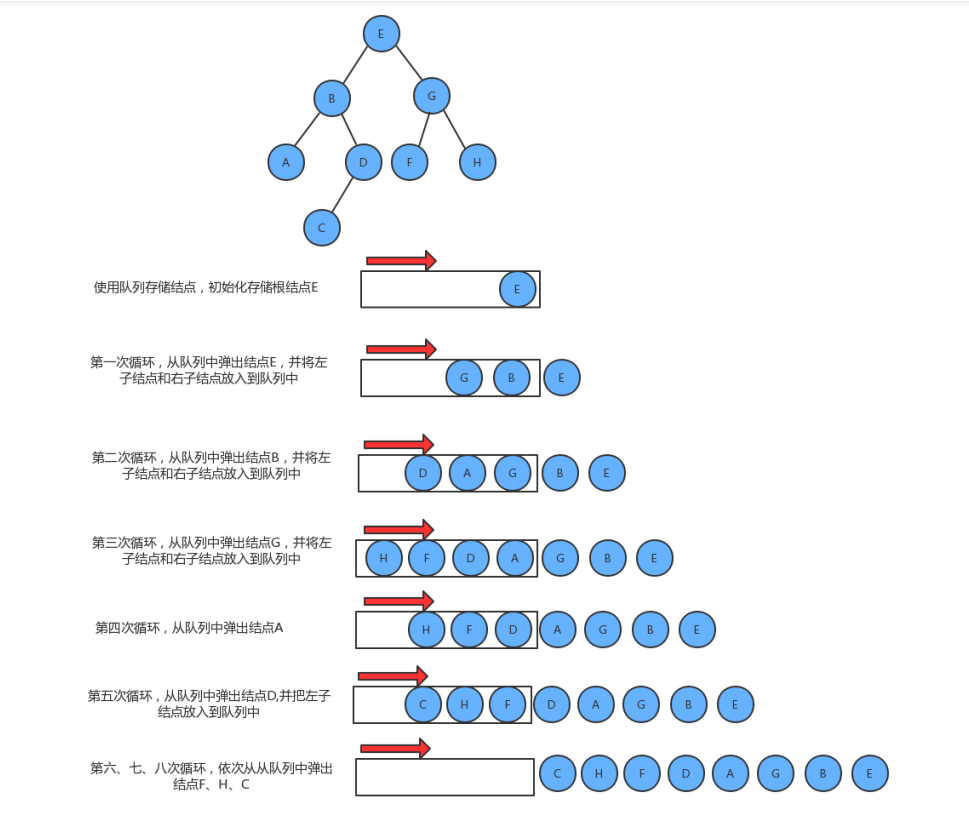
// 层次遍历
public Queue<Key> layerErgodic(){
Queue<Key> keys = new LinkedList<>();
Queue<Node> nodes = new LinkedList<>();
nodes.add(root);
while (!nodes.isEmpty()){
Node x = nodes.poll();
keys.add(x.key);
if (x.left!=null){
nodes.add(x.left);
}
if (x.right!=null){
nodes.add(x.right);
}
}
return keys;
}
6.7 二叉树的最大深度问题
需求:
给定一棵树,请计算树的最大深度(树的根节点到最远叶子结点的最长路径上的结点数);
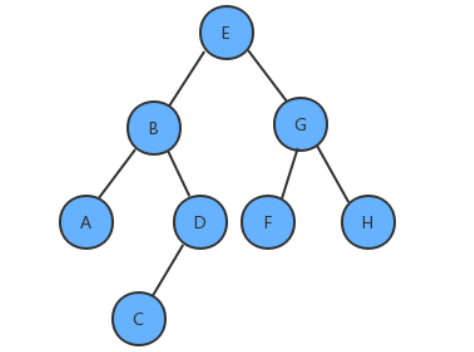
上面这棵树的最大深度为4。
实现:
我们在6.4中创建的树上,添加如下的API求最大深度:
public int maxDepth(): 计算整个树的最大深度
private int maxDepth(Node x): 计算指定树x的最大深度
// 计算整个树的最大深度
public int maxDepth(){
return maxDepth(root);
}
// 计算指定树x的最大深度
private int maxDepth(Node x){
//1.如果根结点为空,则最大深度为0;
if (x==null){
return 0;
}
int maxL = 0;
int maxR = 0;
//2.计算左子树的最大深度;
if (x.left!=null){
maxL = maxDepth(x.left);
}
//3.计算右子树的最大深度;
if (x.right!=null){
maxR = maxDepth(x.right);
}
//4.当前树的最大深度=左子树的最大深度和右子树的最大深度中的较大者+1
return maxL>maxR?maxL+1:maxR+1;
}
package com.ynu.Java版算法.U6_树的入门.T6_二叉树的层次遍历;
import java.util.Queue;
public class Main {
public static void main(String[] args) {
BinaryTree<Integer, String> bt = new BinaryTree<>();
bt.put(1,"A");
bt.put(5,"A");
bt.put(4,"A");
bt.put(6,"A");
bt.put(2,"A");
bt.put(3,"A");
bt.put(8,"A");
bt.put(7,"A");
// 树的高度
System.out.println(bt.maxDepth());
}
}