大家好,我是微学AI,今天给大家带来自然语言处理实战项目5-文本数据处理输入模型操作,以命名实体识别为例。今天我给出的案例是命名实体识别,假设我们有一个命名实体识别任务,需要从文本中识别人名、地点和组织等实体。我们有一些带有实体标签的样本数据。在这里,我们将展示如何处理和加载这些数据,以便将其输入到模型中。数据处理是第一步。
一、数据集样例
我们的数据集中的每个样本中一个字对应一个标签,其中包含一到多个实体。数据样式如下:
陈 B-NAME 学 M-NAME 明 E-NAME : O 1 O 9 O 7 O 7 O 年 O 5 O 月 O 出 O 生 O , O 大 B-EDU 学 E-EDU 毕 O 业 O , O 高 B-TITLE 级 M-TITLE 经 M-TITLE 济 M-TITLE 师 E-TITLE 。 O
这里,每行包含一个单词和它对应的标签(实体标签)。标签遵循BMEO格式,即实体的开头使用B(如B-NAME表示人名的开头),实体的内部使用M(如M-NAME表示人名的内部),实体的结尾使用E(如E-NAME表示人名的结尾),不表示任何实体的位置使用O。
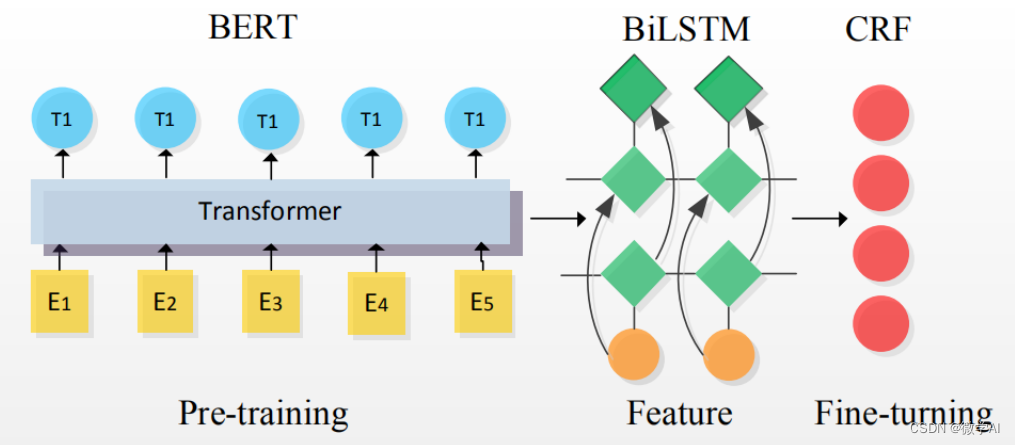
二、数据处理与加载
这里我们详细讨论处理数据的过程。
1.读取数据:
首先,我们需要从文件中读取数据。我们可以按行读取数据,同时将单词和标签分开存储。使用以下代码:
import numpy as np
import random
#加载数据
with open(“data.txt”, “r”) as f:
data = f.readlines()
#加载词表
with open("vocab.txt", "r",encoding='utf-8') as fs:
vocab = fs.readlines()
vocablist =[]
for lines in vocab:
if lines.strip(): # not empty line
word= lines.split()
vocablist.append(word)
words, labels = [], []
for line in data:
if line.strip(): # not empty line
word, label = line.split()
words.append(word)
labels.append(label)
else: # new sentence
sentences.append((words, labels))
words, labels = [], []2.词汇和标签编码:
我们需要将单词和标签转换为数字表示。在这之前,首先从数据集中创建词汇表和标签表。
word_vocab = set(word[0] for word in vocablist)
label_vocab = set(label for sentence in sentences for label in sentence[1])
word2idx = {word: idx + 2 for idx, word in enumerate(word_vocab)}
word2idx["<PAD>"] = 0
word2idx["<UNK>"] = 1
print(word2idx)
label2idx = {label: idx for idx, label in enumerate(label_vocab)}将单词和标签转换为它们的数字表示
data = []
for words, labels in sentences:
word_ids = [word2idx.get(word, 1) for word in words] # 1 is the index for <UNK>
label_ids = [label2idx[label] for label in labels]
data.append((word_ids, label_ids))3.分割数据集
为了训练和评估模型,我们需要将数据集分为训练集、验证集和测试集。此时data列表中的每个项目是一个(word_ids,label_ids)元组。下面将数据拆分为训练集、验证集和测试集
def split_data(data, train_ratio=0.8, valid_ratio=0.1):
"将数据拆分为训练集、验证集和测试集"
total_samples = len(data)
train_samples = int(train_ratio * total_samples)
valid_samples = int(valid_ratio * total_samples)
train_data = data[:train_samples]
valid_data = data[train_samples: train_samples + valid_samples]
test_data = data[train_samples + valid_samples:]
return train_data, valid_data, test_data
random.shuffle(data)
train_data, valid_data, test_data = split_data(data)4.补全序列
由于神经网络的输入需要具有相同的长度,所以我们需要补全输入序列。我们可以使用<PAD>标记(它的索引是0)来补全单词和标签的序列。
def pad_sequences(sequences, maxlen=None, padding="post"):
if maxlen is None:
maxlen = max(len(seq) for seq in sequences)
padded_sequences = np.zeros((len(sequences), maxlen))
for i, seq in enumerate(sequences):
if padding == "post":
padded_sequences[i, :len(seq)] = seq
else: # pre-padding
padded_sequences[i, -len(seq):] = seq
return padded_sequences
train_inputs, train_labels = zip(*train_data)
train_inputs = pad_sequences(train_inputs)
train_labels = pad_sequences(train_labels)
valid_inputs, valid_labels = zip(*valid_data)
valid_inputs = pad_sequences(valid_inputs)
valid_labels = pad_sequences(valid_labels)
test_inputs, test_labels = zip(*test_data)
test_inputs = pad_sequences(test_inputs)
test_labels = pad_sequences(test_labels)三、构建模型与训练
现在我们准备好输入数据到模型中。这里使用Tensorflow/Keras等深度学习框架,可以将处理后的数据分批输入到模型中进行训练。使用Keras进行训练,训练模型可以自己更改哦。
from tensorflow.keras import Model, layers, Input
from tensorflow.keras.preprocessing import sequence
# … define your model
input_layer = Input(shape=(None,))
embedding_layer = layers.Embedding(input_dim=len(word2idx), output_dim=128)(input_layer)
lstm_layer = layers.Bidirectional(layers.LSTM(128, return_sequences=True))(embedding_layer)
output_layer = layers.TimeDistributed(layers.Dense(len(label2idx)))(lstm_layer)
model = Model(inputs=input_layer, outputs=output_layer)
model.compile(optimizer="adam", loss="sparse_categorical_crossentropy",metrics=['accuracy'])
# Train the model
num_epochs = 10
batch_size = 32
model.fit(x=train_inputs, y=train_labels, batch_size=batch_size, epochs=num_epochs, validation_data=(valid_inputs, valid_labels))运行结果:
...
Epoch 7/10
108/108 [==============================] - 4s 38ms/step - loss: 0.1368 - accuracy: 0.9654 - val_loss: 0.2655 - val_accuracy: 0.9324
Epoch 8/10
108/108 [==============================] - 4s 38ms/step - loss: 0.1882 - accuracy: 0.9491 - val_loss: 0.2092 - val_accuracy: 0.9370
Epoch 9/10
108/108 [==============================] - 4s 38ms/step - loss: 0.1552 - accuracy: 0.9587 - val_loss: 0.1423 - val_accuracy: 0.9672
Epoch 10/10
108/108 [==============================] - 4s 38ms/step - loss: 0.1401 - accuracy: 0.9680 - val_loss: 0.1787 - val_accuracy: 0.9674四、模型预测
idx2label = {idx: label for label, idx in label2idx.items()}
# 输入的原始文本句子
input_text = "陈明,男,1967年出生,本科学历,现在在微学软件有限公司上班,是董事长职位."
# 对输入文本进行预处理
input_words = list(input_text)#.split()
#print(input_words)
input_word_ids = [word2idx.get(word, 1) for word in input_words]
input_word_ids = np.array(input_word_ids)[None, :] # Add the batch dimension
# 使用模型进行预测
predictions = model.predict(input_word_ids)
pred_label_ids = np.argmax(predictions, axis=-1)
# 处理预测结果
predicted_labels = [idx2label[label_id] for label_id in pred_label_ids[0]]
# 显示原始文本及其预测的实体标签
for word, label in zip(input_words, predicted_labels):
print(f"{word} {label}")
本文写作的目的是让大家了解文本数据输入模型训练之前应该怎么操作,这个是关键。更精彩可持续关注。





![算法 - 随机 Coding 刷算法合集 [1]](https://img-blog.csdnimg.cn/6d75ca42295848198ec1a81c7d012a35.png)