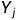刚刚开始学习MySQL的时候,连表查询直接使用left join或者更粗暴点,两个表直接查询,where过滤条件,组装笛卡尔积,最终出现自己想要的结果。
当然,现在left join也是会用的,毕竟嘛,方便!

犹记的当时身为初出茅庐去做的一个面试题,类似这种吧:
a表有100条记录,b表有10000条记录,两张表做关联查询时,是将a表放前面效率高,还是b表放前面效率高?
当然,当时虽然不太懂为啥,也没头铁的硬刚,直接是大表在前,小表在后回答,嘿嘿。
不过后来好像绕进了胡同,a*b和b*a有个啥子区别?为啥一定要小表驱动大表?
关于这个,看了不少的文章,其中讲的最深刻,最明了的应该是百度的百家号里面的一篇文章, 由简入深,很能说服人。
当然,后来有时候也会忘了,又在原地打转,今天就小记一下。
首先,连表查询肯定是需要至少把一张表的数据加载到内存的,然后关联查询,比如sql:
select u.* from order o left join user u on o.user_id = u.id where u.id = '9527';
查询的时候,首先将user表的数据加载到MySQL内存,然后去匹配Order表数据。假设user表的数据匹配量是a,Order表的数据匹配量是b,一般来说,on的条件必须是大表的索引,不然,查询速度贼慢,当然小表最好也是索引。还有就是where中的条件,最好也是和on条件的联合索引或者其他主键之类的,这样查询起来会轻松许多。说多了,继续。
那么根据查询的过程,时间复杂度是a*b吗?
当然!不是!
刚开始加载到内存不是还有个操作吗?没错,就是读取User表的操作,也就是a次操作!
所以:小表驱动大表的操作次数就是 a+a*b
那大表驱动小表的操作次数也就很容易得到为:b+b*a
都说了,b是大表,那么b >a,自然(b+b*a) >(a+a*b)
仅仅看扫描的次数,也能看到,小表驱动大表方案更优!
然后,仅仅是如此?

当然不!
先说内存方面,将数据加载的内存,然后进行对比,获取到最终的结果,如果大表驱动小表,需要将大表数据加载到内存,无疑,这必然占据大量的系统内存,要知道内存的每一分空间都是珍贵的,内存占用过大,必然会挤压其他线程可以使用的空间。而且如果表数据过大,内存放不下,还必须建立临时表,然后一部分一部分的取数据进行对比,那不用说,更慢!
再说,数据IO,将表数据加载到系统内存,肯定要消耗系统IO的。如果是小表驱动大表,也就是需要加载a条数据,然后去匹配过滤数据。反过来,就需要加载b条数据,虽然对比数据的时候都是 a*b次,但是明显加载小表更省IO。
然后,看下数据锁定,可以减少锁竞争的可能,当使用小表驱动大表时,可以避免大表上的锁竞争,因为这些锁会在更早的阶段被获取并且释放。而如果是直接访问大表,则需要在整个查询过程中保持锁定状态,这可能导致其他事务无法正常执行。
为防忘记,小记一下~
如有错误,还望斧正
no sacrifice,no victory~