此软件包处于维护模式,请使用Stable-Baselines3 (SB3)获取最新版本。您可以在 SB3 文档中找到迁移指南。
本节的目的是帮助您进行强化学习实验。它涵盖了有关 RL 的一般建议(从哪里开始、选择哪种算法、如何评估算法等),以及使用自定义环境或实现 RL 算法时的提示和技巧。
使用强化学习时的一般建议
长话短说
- 阅读有关 RL 和稳定基线的信息
- 如果需要,进行定量实验和超参数调整
- 使用单独的测试环境评估性能
- 为了更好的表现,增加培训预算
与任何其他主题一样,如果你想使用 RL,你应该首先阅读它(我们有一个专门的资源页面来帮助你入门)以了解你正在使用什么。我们还建议您阅读稳定基线 (SB) 文档并完成教程。它涵盖了基本用法并指导您了解该库的更高级概念(例如回调和包装器)。
强化学习在几个方面不同于其他机器学习方法。用于训练代理的数据是通过代理本身与环境的交互收集的(例如,与具有固定数据集的监督学习相比)。这种依赖会导致恶性循环:如果智能体收集到质量差的数据(例如,没有奖励的轨迹),那么它就不会改进并继续积累不良轨迹。
除其他因素外,这个因素解释了 RL 的结果可能会因一次运行而异(即,只有伪随机生成器的种子发生变化时)。因此,您应该始终进行多次运行以获得定量结果。
RL 中的好结果通常取决于找到合适的超参数。最近的算法(PPO、SAC、TD3)通常需要很少的超参数调整,但是,不要指望默认算法在任何环境下都能工作。
因此,我们强烈建议您查看RL zoo(或原始论文)以了解已调整的超参数。将 RL 应用于新问题时的最佳做法是进行自动超参数优化。同样,这包含在RL zoo中。
将 RL 应用于自定义问题时,您应该始终规范化代理的输入(例如,对 PPO2/A2C 使用 VecNormalize)并查看在其他环境(例如,Atari、frame -stack 等)上完成的常见预处理。有关自定义环境的更多建议,请参阅下面创建自定义环境段落时的提示和技巧。
强化学习的当前局限性
你必须意识到强化学习目前的局限性。
无模型 RL 算法(即 SB 中实现的所有算法)通常样本效率低下。他们需要大量样本(有时是数百万次交互)来学习有用的东西。这就是为什么 RL 中的大部分成功都是在游戏或模拟中取得的。例如,在苏黎世联邦理工学院的这项工作中,ANYmal 机器人只接受了模拟训练,然后在现实世界中进行了测试。
作为一般建议,为了获得更好的性能,您应该增加代理的预算(训练时间步数)。
为了实现期望的行为,通常需要专家知识来设计足够的奖励函数。这种奖励工程(或Freek Stulp创造的RewArt)需要多次迭代。作为奖励塑造的一个很好的例子,你可以看看Deep Mimic 论文,它结合了模仿学习和强化学习来做杂技动作。
RL 的最后一个限制是训练的不稳定性。也就是说,您可以在训练期间观察到性能的大幅下降。这种行为特别存在于 中DDPG,这就是它的扩展TD3试图解决该问题的原因。其他方法,例如TRPO或PPO利用信任区域通过避免太大的更新来最小化该问题。
如何评估强化学习算法?
因为大多数算法在训练期间使用探索噪声,所以您需要一个单独的测试环境来评估您的代理在给定时间的性能。建议定期评估您的智能体的n测试集(n通常在 5 到 20 之间)并平均每个集的奖励以获得良好的估计。
由于某些策略默认是随机的(例如 A2C 或 PPO),您还应该在调用.predict()方法时尝试设置deterministic=True,这通常会带来更好的性能。查看训练曲线(时间步长的情节奖励函数)是一个很好的代理,但低估了代理的真实表现。
笔记
我们提供了一个EvalCallback用于进行此类评估的方法。您可以在回调部分相关信息。
我们建议您阅读Deep Reinforcement Learning that Matters以获得关于 RL 评估的良好讨论。
您还可以查看Cédric Colas 的这篇博文和这一期。
我应该使用哪种算法?
RL 中没有灵丹妙药,根据您的需要和问题,您可以选择其中之一。第一个区别来自你的行动空间,即你有离散的(例如左,右,......)还是连续的行动(例如:达到一定速度)?
一些算法仅针对一个或另一个领域量身定制:DQN仅支持离散动作,其中SAC仅限于连续动作。
可以帮助您选择的第二个区别是您是否可以并行化训练,以及如何进行(有或没有 MPI?)。如果重要的是挂钟训练时间,那么你应该倾向于A2C及其衍生物(PPO、ACER、ACKTR,……)。查看矢量化环境,了解更多关于多人培训的信息。
把它们加起来:
离散动作
笔记
这包括Discrete, MultiDiscrete,Binary和MultiBinary空格
离散操作 - 单一进程
带扩展的 DQN(双 DQN、优先重放……)和 ACER 是推荐的算法。DQN 通常训练速度较慢(关于挂钟时间)但采样效率最高(因为它有回放缓冲区)。
离散操作 - 多处理
您应该尝试 PPO2、A2C 及其后续产品(ACKTR、ACER)。
如果您可以使用 MPI 对训练进行多处理,那么您应该检查 PPO1 和 TRPO。
连续动作
连续动作 - 单一过程
Current State Of The Art (SOTA) 算法是SAC和TD3。请使用RL zoo中的超参数以获得最佳结果。
连续动作 - 多处理
看看 PPO2、TRPO 或 A2C。同样,不要忘记从RL zoo中获取超参数以解决连续动作问题(参见Bullet envs)。
笔记
归一化对于这些算法至关重要
如果可以使用 MPI,则可以在 PPO1、TRPO 和 DDPG 之间进行选择。
目标环境
如果您的环境遵循GoalEnv接口(cf HER),那么您应该根据操作空间使用 HER + (SAC/TD3/DDPG/DQN)。
笔记
工人数量是 HER 实验的重要超参数。目前,只有 HER+DDPG 支持使用 MPI 进行多处理。
创建自定义环境时的提示和技巧
如果您想了解如何创建自定义环境,我们建议您阅读此页面。我们还提供了一个colab 笔记本,用于创建自定义健身房环境的具体示例。
一些基本建议:
- 尽可能规范化你的观察空间,即当你知道边界时
- 标准化你的动作空间并使其在连续时对称(参见下面的潜在问题)一个好的做法是重新调整你的动作以位于 [-1, 1] 中。这不会限制您,因为您可以轻松地重新调整环境内的动作
- 从形状奖励(即信息奖励)和问题的简化版本开始
- 使用随机操作进行调试以检查您的环境是否正常工作并遵循健身房界面:
我们提供了一个帮助程序来检查您的环境是否运行无误:
from stable_baselines.common.env_checker import check_env
env = CustomEnv(arg1, ...)
# It will check your custom environment and output additional warnings if needed
check_env(env)
如果您想在您的环境中快速试用随机代理,您还可以执行以下操作:
env = YourEnv()
obs = env.reset()
n_steps = 10
for _ in range(n_steps):
# Random action
action = env.action_space.sample()
obs, reward, done, info = env.step(action)
为什么要规范化动作空间?
大多数强化学习算法都依赖于高斯分布(最初以 0 为中心,std 为 1)来进行连续操作。因此,如果您在使用自定义环境时忘记规范化操作空间,这可能会损害学习并难以调试(参见附图和问题 #473)。
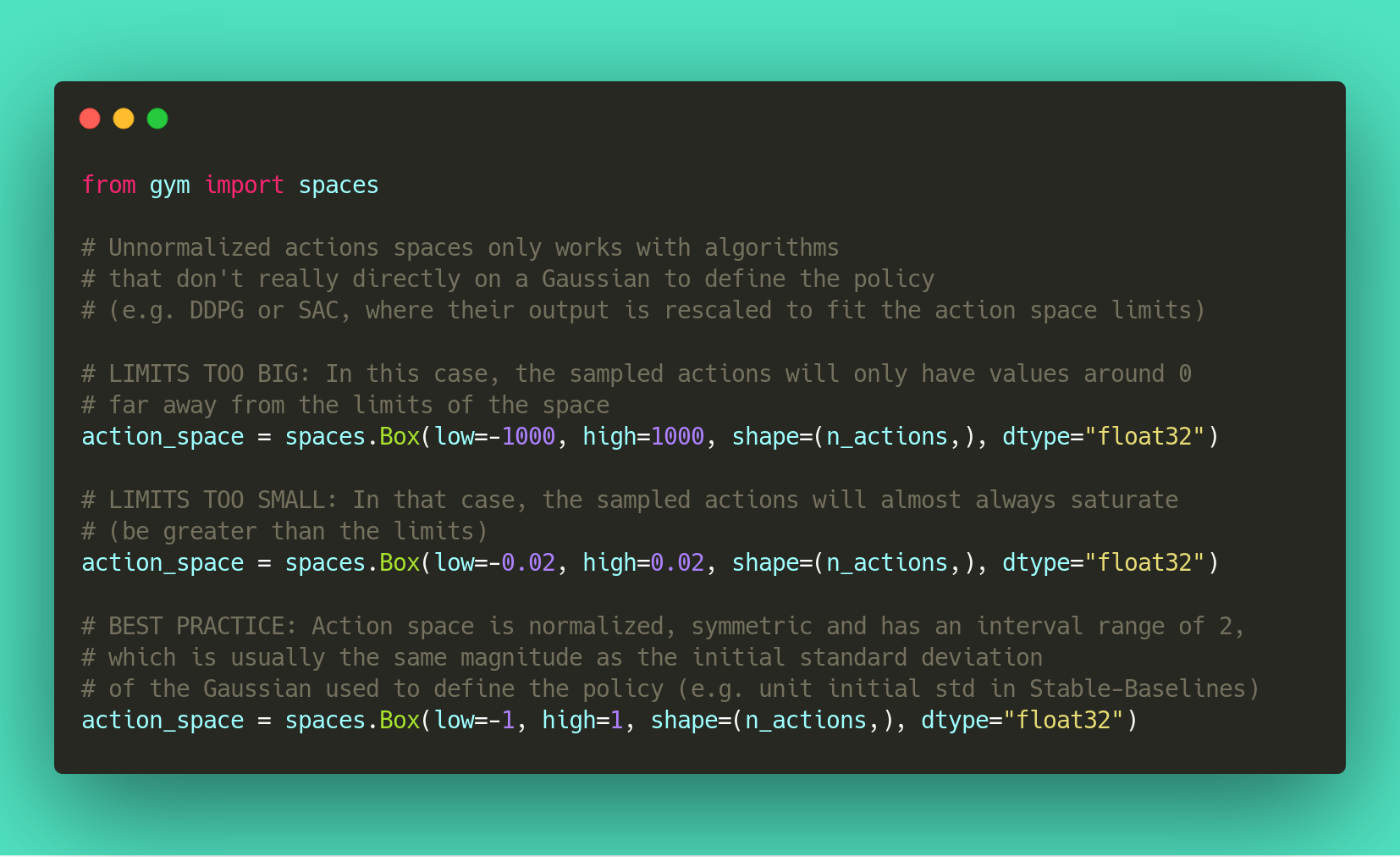
使用高斯的另一个结果是动作范围不受限制。这就是为什么剪裁通常用作绷带以保持有效间隔。更好的解决方案是使用压缩函数(cf SAC)或 Beta 分布(cf issue #112)。
笔记
此声明不正确DDPG或TD3因为它们不依赖于任何概率分布。
实施 RL 算法时的提示和技巧
当您尝试通过实现算法来重现 RL 论文时, John Schulman 的RL 研究的具体细节非常有用(视频)。
我们建议按照这些步骤来使用有效的 RL 算法:
- 多次阅读原始论文
- 阅读现有的实现(如果可用)
- 尝试在玩具问题上有一些“生命迹象”
-
通过使其在越来越难的环境中运行来验证实现(您可以将结果与 RL zoo 进行比较)
您通常需要为该步骤运行超参数优化。
您需要特别注意正在操作的不同对象的形状(广播错误将无提示地失败,参见问题 #75)以及何时停止梯度传播。
个人选择(来自@araffin),用于在 RL 中具有连续动作的逐渐困难的环境:
- 摆锤(容易解)
- HalfCheetahBullet(具有局部最小值和形状奖励的中等难度)
- BipedalWalkerHardcore(如果它适用于那个,那么你可以有一个 cookie)
在具有离散动作的 RL 中:
- CartPole-v1(比随机代理更容易,更难达到最大性能)
- 月球着陆器
- Pong(最简单的 Atari 游戏之一)
- 其他 Atari 游戏(例如 Breakout)