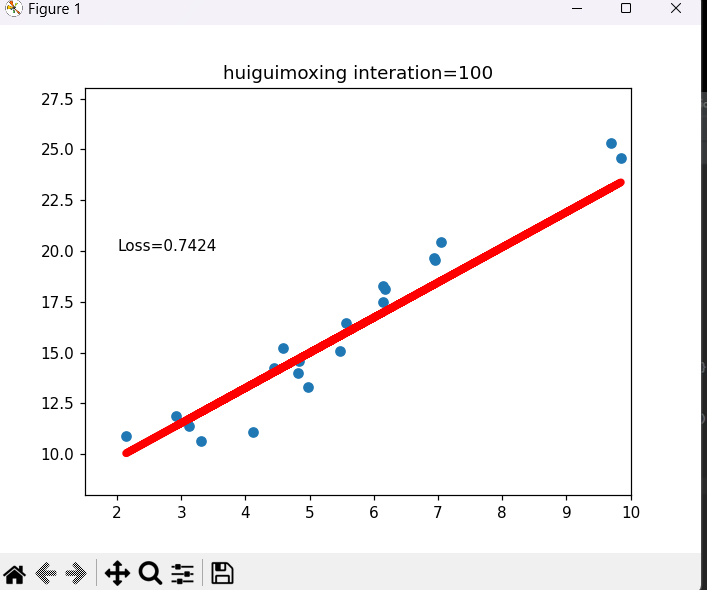
目录
1. 联合查询
1.1 内查询
1.2 外查询
1.3 自连接
1.4 子查询
1.5 合并查询

1. 联合查询
联合查询,简单的来讲就是多个表联合起来进行查询。这样的查询在我们实际的开发中会用到很多,因此会用笛卡尔积的概念。
啥是笛卡尔积?两张表经过笛卡尔积后得到的新表的列数是两表列数之和,行数是两表行数之积。
我们可以看到下图中两表形成一个笛卡尔积后,把这两张表组成情况的所有的可能性都罗列出来了。因此会造成出现很多无用数据,这就是笛卡尔积的一个简单理解。因此,我们在查询两个表时得使用一些方法来避免类似于笛卡尔积这种情况的出现,这些方法的总称就是联合查询。
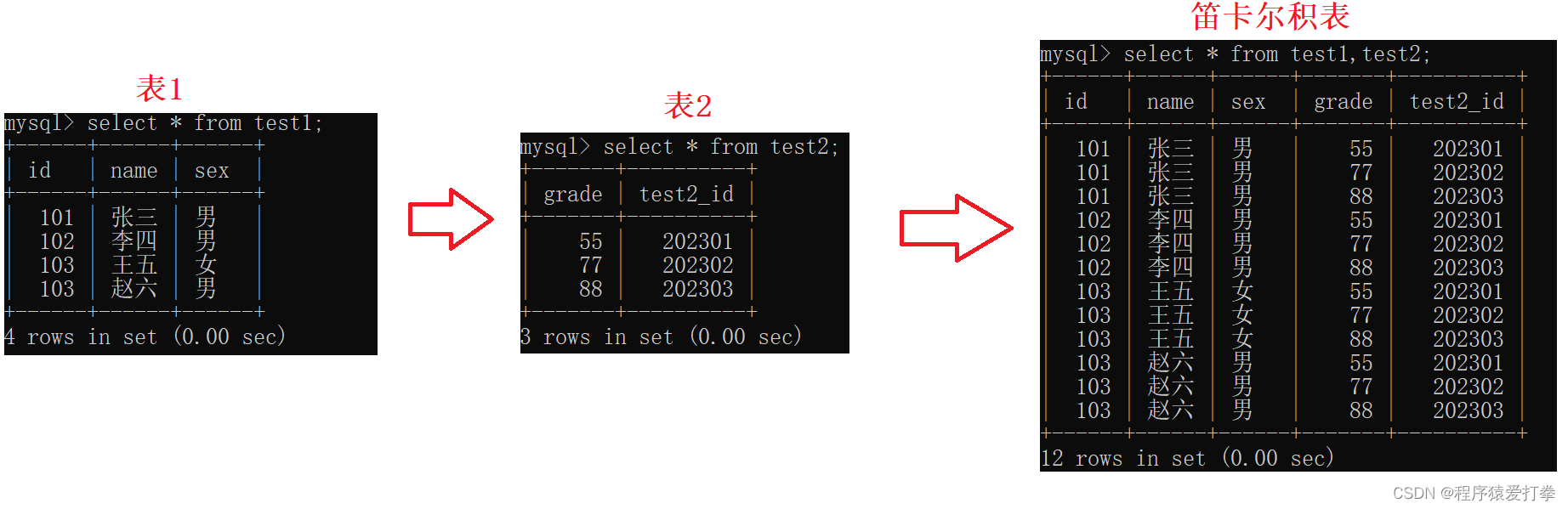
当然,上图两表中的数据没有任何关联,在此解释一下。
在我们进入联合查询的各个知识点讲解之前,我们先来创建几张表。下方的所有联合查询都是通过这几张表来进行演示的。
首先创建一个名为student的表作为学生表:
//创建student表
mysql> create table student(
-> id int primary key auto_increment,
-> sn varchar(20),
-> name varchar(20),
-> e_mail varchar(20),
-> classes_id int
-> );
Query OK, 0 rows affected (0.02 sec)
//往student表中插入数据
mysql> insert into student(id,sn,name,e_mail,classes_id) values
-> (1,23001,'阿三','asan@qq.com',1),
-> (2,23005,'李四','lisi@qq.com',2),
-> (3,23011,'王五',null,2),
-> (4,23002,'赵六','zhaoliu@qq.com',2),
-> (5,23015,'老八',null,1);
Query OK, 5 rows affected (0.00 sec)
Records: 5 Duplicates: 0 Warnings: 0student表的内容为:

创建一个名为classes的表作为成绩表:
//创建表classes
mysql> create table classes(
-> id int primary key auto_increment,
-> name varchar(20),
-> descr varchar(100)
-> );
Query OK, 0 rows affected (0.02 sec)
//往classes中插入数据
mysql> insert into classes(id,name,descr) values
-> (1,'计算机专业','学习了C、Java、数据结构与算法'),
-> (2,'医护专业','学习了康复相关知识');
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0classe表的内容为:

创建一个名为course的表作为课程表:
//创建course表
mysql> create table course(
-> id int primary key auto_increment,
-> name varchar(20)
-> );
Query OK, 0 rows affected (0.02 sec)
//往course表中插入数据
mysql> insert into course(id,name) values
-> (1,'Java'),
-> (2,'英语'),
-> (3,'数学'),
-> (4,'中华传统文化'),
-> (5,'摆烂');
Query OK, 5 rows affected (0.00 sec)
Records: 5 Duplicates: 0 Warnings: 0course表的内容为:

创建一个名为score的表作为成绩表:
//创建一个score表
mysql> create table score(
-> score int,
-> student_id int,
-> course_id int
-> );
Query OK, 0 rows affected (0.02 sec)
//插入相应的数据
mysql> insert into score(score,student_id,course_id) values
-> (80,1,1),
-> (60,1,2),
-> (70,1,5),
-> (66,2,4),
-> (88,2,1),
-> (99,3,5),
-> (20,3,1),
-> (78,4,4),
-> (66,4,2),
-> (89,4,1),
-> (99,5,2),
-> (77,5,3),
-> (76,5,4);
Query OK, 13 rows affected (0.01 sec)
Records: 13 Duplicates: 0 Warnings: 0score表中的内容为:

通过上面创建的四张表,我们可以知道这几张表之间的联系。
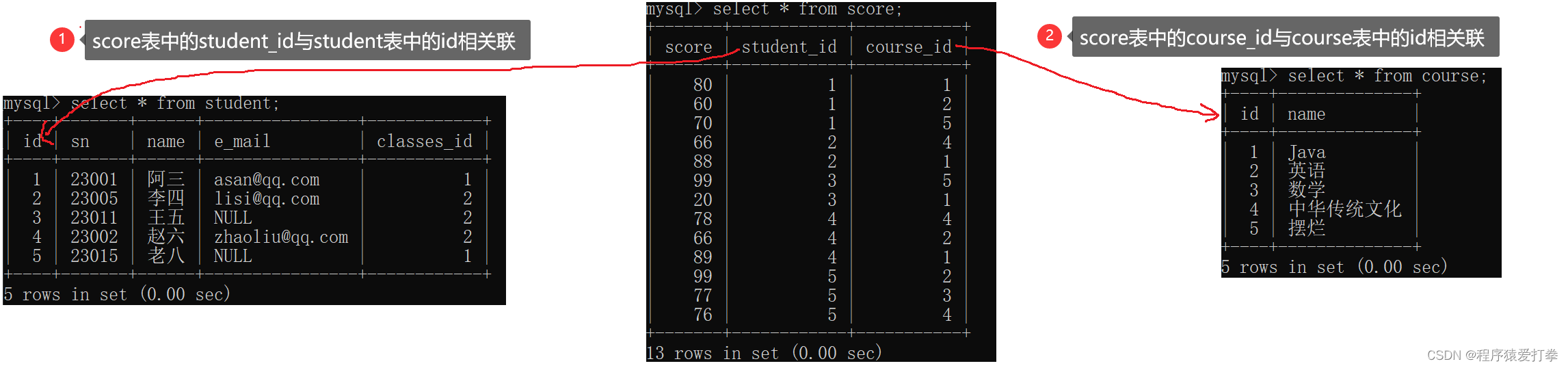
当然不止上图三表中之间有联系,student表中的classes_id与classes表中的id也是有关联。因此,这四张表之间都是相互关联的,那么我们就可以通过联合查询来操作相应的数据。
1.1 内查询
内查询是表与表之间通过一些内部相同数据的关联进行查询,因此当我们把需要查询的表进行笛卡尔积后,可以根据表之间内部相同的字段来作为连接条件从而筛选到要想的数据。内连接语法为:
- select 字段 from 表1 别名1 join 表2 别名2 on 连接条件 and 其他连接条件;
- select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他连接条件;
如果查我们要找名为阿三同学的成绩,这时就会使用到两张表:student、score。这两张表进行笛卡尔积后数据非常的冗杂:
mysql> select * from student,score;
足足有65行数据,我们要查找阿三的同学的成绩会使用到两个条件:第一个条件为name='阿三',第二个条件就是student.id = score.student_id。这样就能避免出现其他无效的数据。
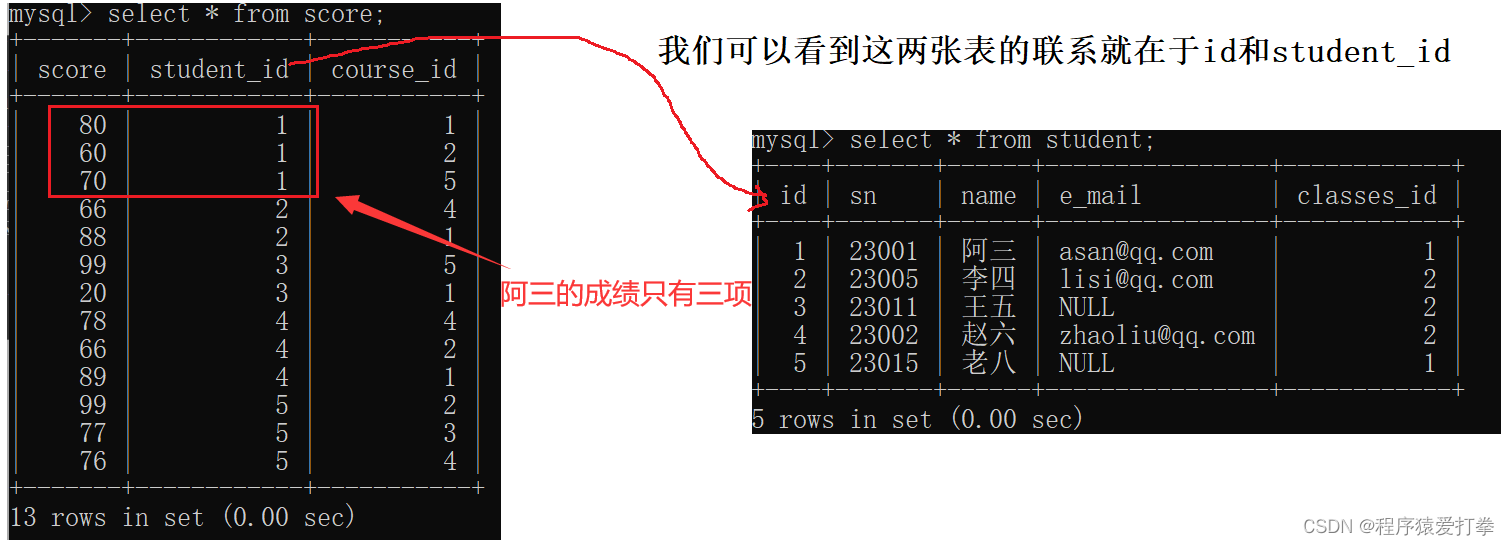
那么在对两张表进行笛卡尔积过后,我们有两种方式来进行查询阿三同学的成绩,第一种使用join on的方式进行查询:
mysql> select name,score from student join score on name='阿三' and student.id=score.student_id;
+------+-------+
| name | score |
+------+-------+
| 阿三 | 80 |
| 阿三 | 60 |
| 阿三 | 70 |
+------+-------+
3 rows in set (0.00 sec)第二种方式,使用where的方式进行查询:
mysql> select name,score from student,score where name='阿三' and student.id = score.student_id;
+------+-------+
| name | score |
+------+-------+
| 阿三 | 80 |
| 阿三 | 60 |
| 阿三 | 70 |
+------+-------+
3 rows in set (0.00 sec)通过上方代码之间的比较我们不难发现,join on和where这两种方式都能达到我们的目的,因此只要能掌握其中一种方式就能达到内查询的效果。注意,上述代码中我们可以通过.号来引用相关字段。当两张表中有相同字段name时我们可以通过表1.name来访问到表1中的name,通过表2.name来访问到表2中的name。
经过上方简单的程序相信大家已经对内查询有了初步的了解,下面我们来升级难度:查询所有同学的总成绩,及同学的个人信息。
首先我们要知道这些数据的来源于student和score这两张表,并且我们要得到student中的所有学生信息、score中的成绩总和,以及条件为student中的id等于score中的student_id。这样我们就可以写出以下代码:
mysql> select stu.id,stu.name,stu.e_mail,stu.classes_id,sum(sco.score)
-> from student stu join score sco on stu.id=sco.student_id
-> group by sco.student_id;
+----+------+----------------+------------+----------------+
| id | name | e_mail | classes_id | sum(sco.score) |
+----+------+----------------+------------+----------------+
| 1 | 阿三 | asan@qq.com | 1 | 210 |
| 2 | 李四 | lisi@qq.com | 2 | 154 |
| 3 | 王五 | NULL | 2 | 119 |
| 4 | 赵六 | zhaoliu@qq.com | 2 | 233 |
| 5 | 老八 | NULL | 1 | 252 |
+----+------+----------------+------------+----------------+
5 rows in set (0.00 sec)在上述代码中stu是student的别名,sco是score的别名。因此我们from前就可以使用这两个别名进行.操作来获取字段,但这种代码的可读性并不太高,建议使用原表名来获取字段而不是使用别名来获取字段。如将上方代码修改为使用表名来.引用字段:
select student.id,student.name,student.e_mail,student.classes_id,sum(score.score)
from student join score on student.id = score.student_id
group by score.student_id;1.2 外查询
那么在上述内查询的使用时,其实都是表之间的“内连接”,在MySQL中还有一种联合查询叫作“外连接”,也就是现在我们要学的外查询。
何为外查询,如在两张表中有一部分数据是有关联的另一部分数据是没有关联的,我们可以通过外查询把表1中不存在的数据或表2中不存的的数据通过外查询显示出来。有些抽象,下面我就用实例来讲解。外查询分为左外连接与右外连接,语法为:
- select 字段 from 表1 left join 表2 on 连接条件; --左外连接,表1完全显示
- select 字段 from 表1 right join 表2 on 连接条件; --右外连接,表2完全显示
在mytest数据库中创建两张表,student学生表和score课程表:
//创建名为mytest的数据库
mysql> create database mytest charset utf8;
Query OK, 1 row affected (0.00 sec)
//使用该数据库
mysql> use mytest;
Database changed
//创建学生表
mysql> create table student(
-> id int,
-> name varchar(10),
-> sex varchar(10)
-> );
Query OK, 0 rows affected (0.02 sec)
//插入对应数据
mysql> insert into student values
-> (101,'张三','男'),
-> (102,'李四','女'),
-> (103,'王五','男');
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
//创建成绩表
mysql> create table score(
-> student_id int,
-> score int
-> );
Query OK, 0 rows affected (0.02 sec)
//插入相应数据
mysql> insert into score values (101,99),(102,89);
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0这两张表的内容为:
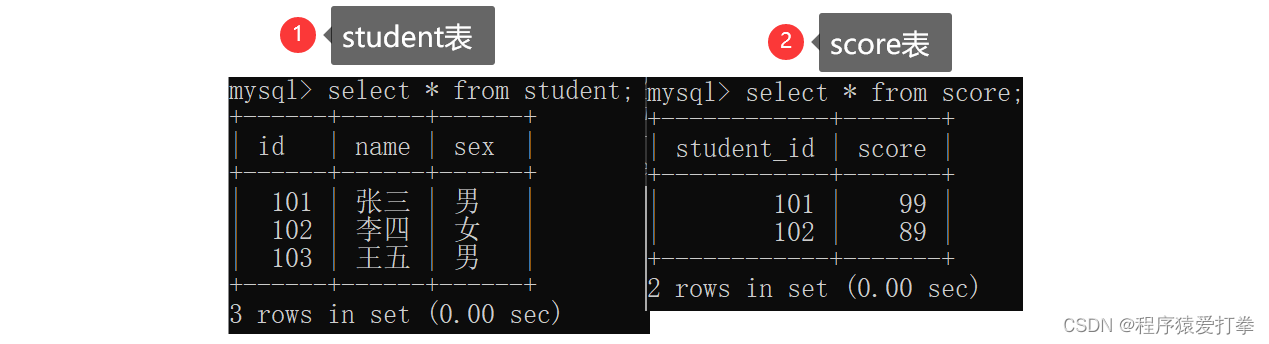
有一需求:查找这两张表的id,name,score这三条信息,要求为有效信息。当我们通过内连接,左外连接以及右外连接进行查询就会发现不同之处。
内连接查询:
mysql> select student.id,student.name,score.score from student join score on student.id = score.student_id;
+------+------+-------+
| id | name | score |
+------+------+-------+
| 101 | 张三 | 99 |
| 102 | 李四 | 89 |
+------+------+-------+
2 rows in set (0.00 sec)我们发现使用内连接进行查询得到的结果是正确的,关联性比较强。我们再来看左连接查询:
mysql> select student.id,student.name,score.score from student left join score on student.id = score.student_id;
+------+------+-------+
| id | name | score |
+------+------+-------+
| 101 | 张三 | 99 |
| 102 | 李四 | 89 |
| 103 | 王五 | NULL |
+------+------+-------+
3 rows in set (0.00 sec)通过上述代码我们发现,查询的结果并不有效。把score表中不存在的字段给查询出来了,我们可以把student和score这两张表看作两个数学里面的集合,这样就不难理解:
 当我们的连接条件为student.id=score.student_id时,我们通过左外连接时强制要得到左表也就是student表中的信息,那么student表中id为103的行中没有score值,此时就会显示null。右连接则不会出现这种情况:
当我们的连接条件为student.id=score.student_id时,我们通过左外连接时强制要得到左表也就是student表中的信息,那么student表中id为103的行中没有score值,此时就会显示null。右连接则不会出现这种情况:
mysql> select id,name,score from student right join score on student.id = score.student_id;
+------+------+-------+
| id | name | score |
+------+------+-------+
| 101 | 张三 | 99 |
| 102 | 李四 | 89 |
+------+------+-------+
2 rows in set (0.00 sec)因为右连接根据右表也就是score表进行查询,score表中关于id的信息有101和102因此通过条件为student.id=score.student_id进行查询后得到的结果也是存在的。
1.3 自连接
自连接是一种特殊情况下才使用的查询方式,它是一种取巧的查询方式,何为取巧?我们通过上方的内连接与外连接的学习知道了这两种都是表与表之间进行连接的,而自连接它是表自己和自己进行连接的,因此我认为它是取巧的一种方式。
如使用自连接查找Java成绩要大于摆烂成绩:
因为是自连接所以只能用到score这一张表。此外,我们需要知道Java成绩的课程id和摆烂成绩的课程id这样才能去比较它们的成绩。
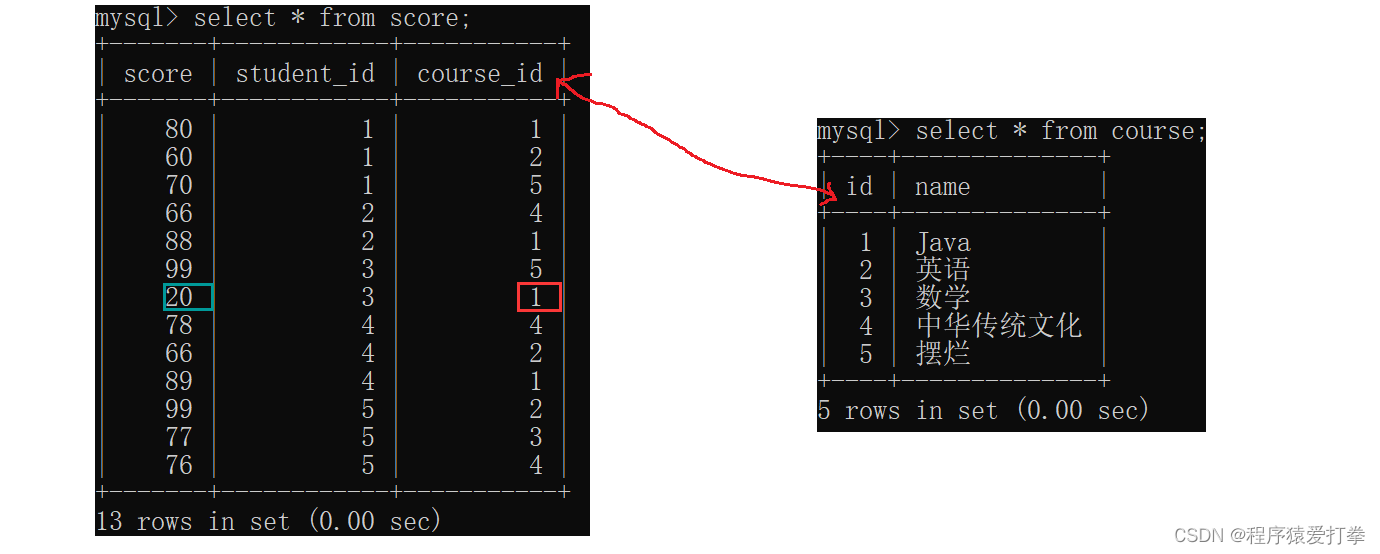
因此,我们可以写出以下代码:
mysql> select
-> s1.*
-> from
-> score s1,
-> score s2
-> where
-> s1.student_id = s2.student_id
-> and s1.score<s2.score
-> and s1.course_id = 1
-> and s2.course_id = 5;
+-------+------------+-----------+
| score | student_id | course_id |
+-------+------------+-----------+
| 20 | 3 | 1 |
+-------+------------+-----------+
1 row in set (0.00 sec)当然,我们也可以使用join on方式来实现:
mysql> select
-> s1.*
-> from
-> score s1
-> join
-> score s2
-> on
-> s1.student_id = s2.student_id
-> and s1.score<s2.score
-> and s1.course_id = 1
-> and s2.course_id = 5;
+-------+------------+-----------+
| score | student_id | course_id |
+-------+------------+-----------+
| 20 | 3 | 1 |
+-------+------------+-----------+
1 row in set (0.00 sec)我们可以看到,Java小于摆烂的成绩只有一条。
1.4 子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询。什么意思呢,就是在查询一些数据的时候使用另一条select语句作为查询条件,从而达到特定的查询效果。
如查找老八及与同班级的学生,首先我们要查找student表中的所有信息,在where条件后面再加上条件。这个条件为classes_id=老八的classes_id,注意老八的classes_id可以使用另一条select语句来查询。因此可以写出以下代码:
mysql> select * from student where classes_id=(select classes_id from student where name = '老八');
+----+-------+------+-------------+------------+
| id | sn | name | e_mail | classes_id |
+----+-------+------+-------------+------------+
| 1 | 23001 | 阿三 | asan@qq.com | 1 |
| 5 | 23015 | 老八 | NULL | 1 |
+----+-------+------+-------------+------------+
2 rows in set (0.01 sec)使用in关键字也能做到嵌套查询这种效果,如查询与李四同班的同学信息:
mysql> select * from student where classes_id in (select classes_id from student where name = '李四');
+----+-------+------+----------------+------------+
| id | sn | name | e_mail | classes_id |
+----+-------+------+----------------+------------+
| 2 | 23005 | 李四 | lisi@qq.com | 2 |
| 3 | 23011 | 王五 | NULL | 2 |
| 4 | 23002 | 赵六 | zhaoliu@qq.com | 2 |
+----+-------+------+----------------+------------+
3 rows in set (0.00 sec)注意,in关键可以表示一个范围,只要是满足in()里面的内容就可以被查询出来,查询一个字段满足5,6,7这三个条件。则字段 in(5,6,7)即可。
1.5 合并查询
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all。使用union和union all时,前后查询的结果集中,字段需要一致。
union操作符:
查找id<3并且name=摆烂的课程,我们会用到course表,使用两个select语句进行查询我们会使用union这个操作符进行连接,因此有以下代码:
mysql> select * from course where id < 3 union select * from course where name = '摆烂';
+----+------+
| id | name |
+----+------+
| 1 | Java |
| 2 | 英语 |
| 5 | 摆烂 |
+----+------+
3 rows in set (0.00 sec)或者我们使用or来实现:
mysql> select * from course where id < 3 or name = '摆烂';注意,使用union操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行。
union all操作符:
该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行。如查询id<3或者name='Java'的课程:
mysql> select * from course where id < 3 union all select * from course where name = 'Java';
+----+------+
| id | name |
+----+------+
| 1 | Java |
| 2 | 英语 |
| 1 | Java |
+----+------+
3 rows in set (0.00 sec)我们可以看到,重复被查询的Java字段出现了两次。
今天这篇博文内容比较丰富,大家下来了可以自行测试每个查询所实现的效果,只有自己尝试了并且实现了一些效果,这样才会更好的掌握这些知识点。

本期博文到这里就结束,感谢各位的阅读。