梦里不知身是客,一晌贪欢
文章目录
- 5.6.1 指令流水线的基本概念
- 5.6.2 指令流水线的影响因素和分类
- 五段式指令流水线
- 5.7.1 多处理器的基本概念
- 5.7.2 硬件多线程的基本概念
5.6.1 指令流水线的基本概念
想要对指令的过程进行优化,一条指令的执行过程可以被分成多个过程,根据计算机的不同,具体的分法也不同,这里可以分成三个部分,取指,分析,执行,
取指:根据PC内容访问主存储器,取出一条指令送到IR中
分析:对指令操作码进行译码,按照给定的寻址方式和地址字段中的内容形成操作数的有效地址EA,并从有效地址EA中取出操作数
执行:根据操作码字段,完成指令规定的功能,即把运算结果写到通用寄存器或主存中
设取指,分析,执行,三个阶段的时间都相等,用T表示,按以下几种执行方式分析n条指令的执行时间
顺序执行方式

一次重叠执行方式
这里总耗时第一个需要3T,;后面每两个T完成一个指令所以剩下的n-1 需要(n-1)*T

二次重叠执行方式
在这种最理想的方式,某一个时刻可能同时在进行取指,分析,执行,这里是分成3个阶段,如果说分成4,5个阶段,并且若是我们能实现各个阶段所使用的部件相互独立,也就意味着同一时刻最多可以4,5个指令在执行
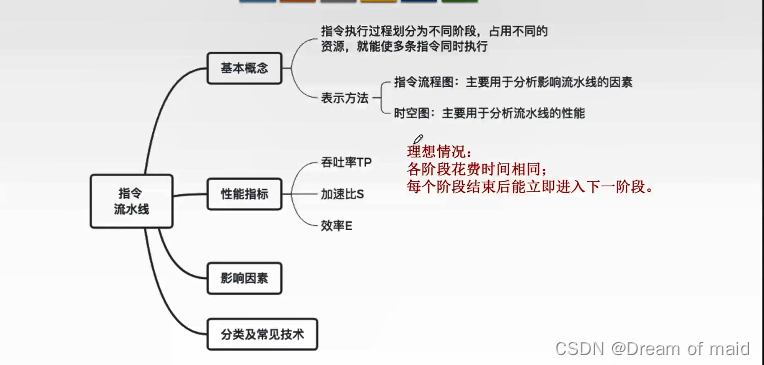
流水线的表示方式
一种是指令执行过程图,主要用于分析影响流水线的因素,一种是时空图,如何度量指令流水线的性能 主要用的是时空图
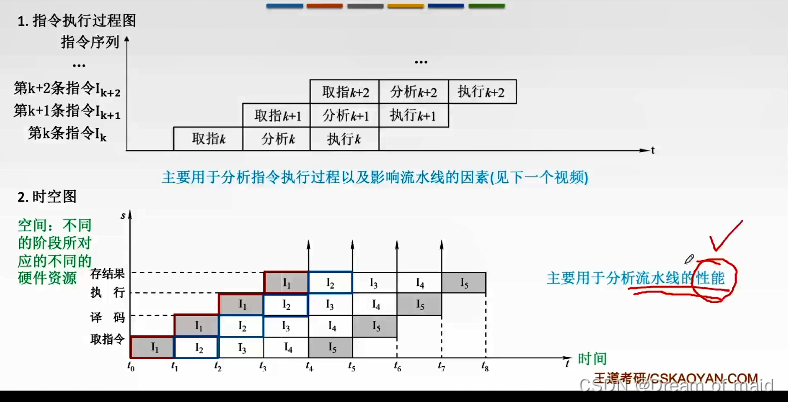
流水线的性能指标
这里的任务数也就是指令数,为什么一般取德它T=一个时钟周期:按照之前的学习 一个指令被分成多个阶段,每一个阶段应该对应一个机器周期,而一个机器周期可能包含多个时钟周期,也就是多个节拍,但是理论上一个最理想的情况 一个机器周期也是可以包括一个时钟周期,既然我们这里探讨的就是理想情况,所以这里也可以取一个阶段等于一个时钟周期
吞吐率

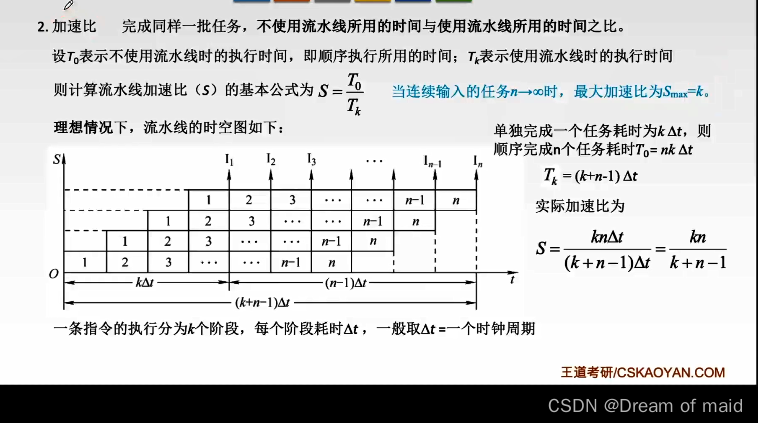
加速比
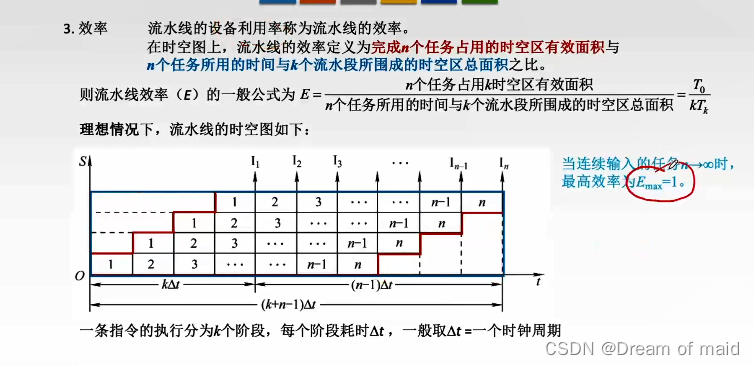
效率
红色的表示利用这些设备的时间,蓝色的框表示整体的一个时间
本节回顾
5.6.2 指令流水线的影响因素和分类
上节中我们假设一个阶段到下一个阶段都是理想状态,有的时候指令流水线可能并不是那么完美,本节来分析一些影响流水线的影响因素,最后再来介绍一下指令流水线的分类
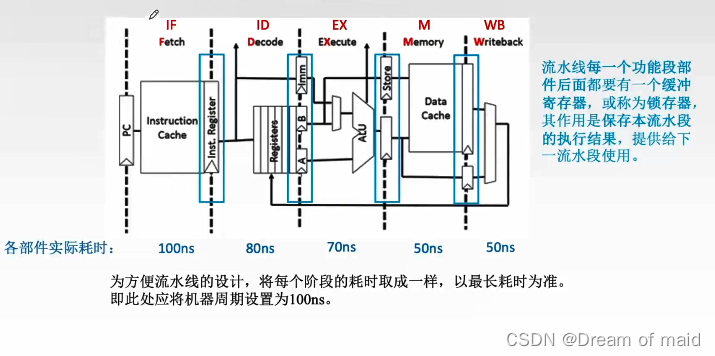
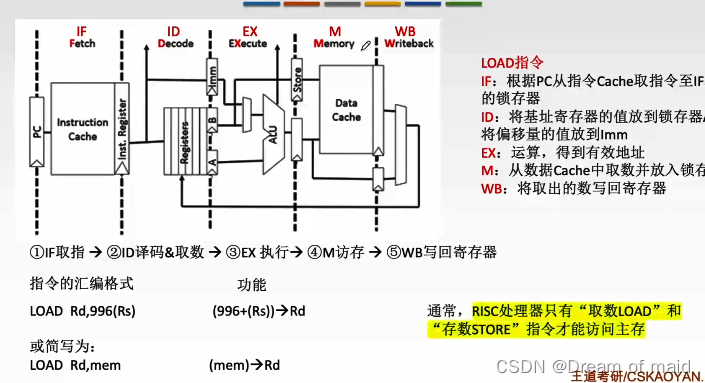
五段式流水线结构
这里有两个Cache,并且一个存放指令,一个存放数据,也就意味着可以并行的执行的,若是Cache没有命中,则会出现断流的情况
IF:取指令阶段,根据PC从Cache中取指令,放到这个功能段的锁存器里面,Cache会保留主存的一个副本,并且由于局部性原理,命中率很高
ID:指令译码阶段,指令译码阶段除了译码的阶段,还有就是需要取数,这里取数也是从通用寄存器中取,若是这个数来自于主存,那么这个数也一定是先存放于通用寄存器中,在从通用寄存器中取出这个数据
EX:指令的执行阶段,使用ALU 处理数据的,然后将数据存放于这个阶段的锁存器中,iMM中存放的是立即数,
M:需要进行访存的一个阶段,这里同样的也是存在一个Cache
WB:把最终的结果写回到通用寄存器
当然这五个阶段并不是必需的,比如有的就不需要访存这个阶段
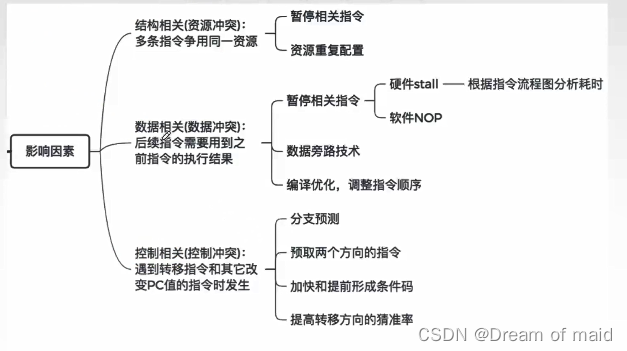
影响流水线的因素
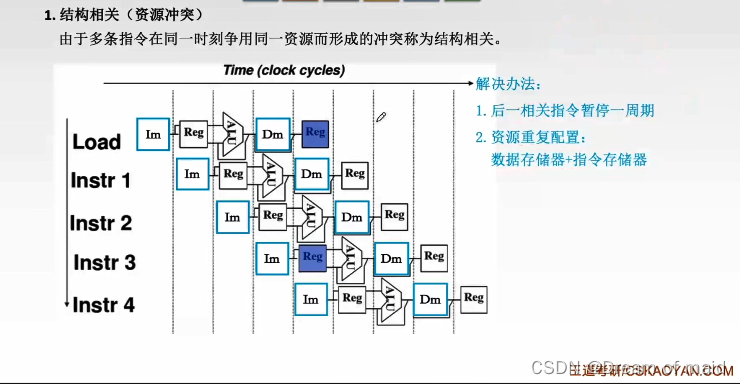
1,结构相关(资源冲突)
也就是操作系统中的互斥,某些资源是不能共享的
资源重复配置也就是上面的两个Cache,一个是指令Cache,一个是数据Cache
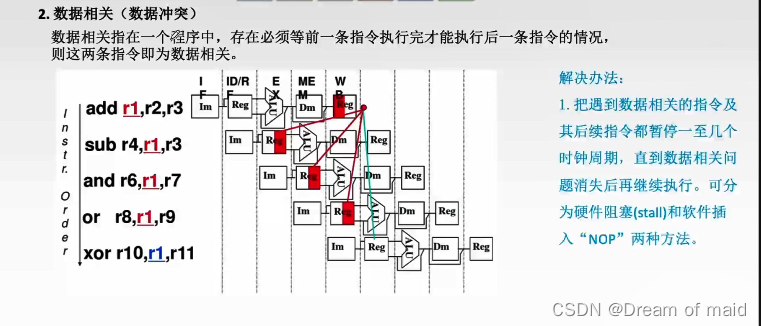
2,数据相关(数据冲突)
也就是操作系统的同步,不同的指令它们之间可能有一前一后的关系
如下图红色部分就是还未写入就使用数据,此时的数据是不正确的,NOP指令也同样需要5个周期
硬件阻塞
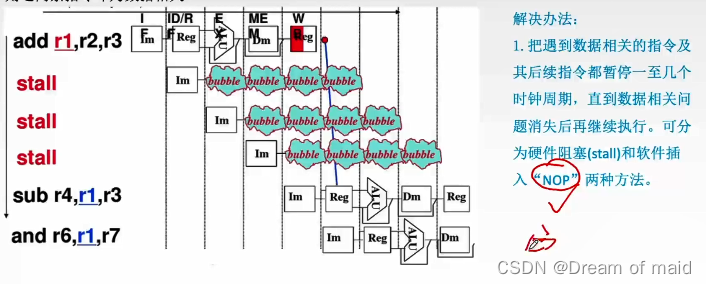
软件插入
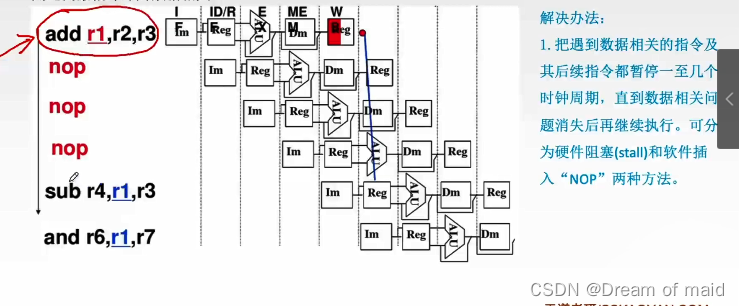
数据旁路技术
在第一条指令,它的加法出来之后,我们会连出来一个数据旁路,将这个数据直接送到ALU输入端,作为下一个指令的操作数,这样我们就不需要上一个指令的写回操作
编译优化
若是后面某些指令不需要用到R1数据,我们就可以将后面的指令适当的修改位置,通过编译器调整指令顺序来解决数据相关
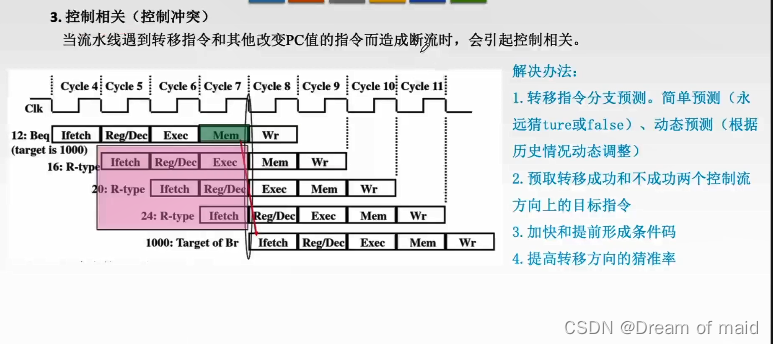
3,控制相关(控制冲突)
其实下图也即是如何控制指令进行if else 的转移指令
影响流水线的因素汇总
流水线分类
部件功能级的流水线:比如我们在指令的执行阶段,我们会将数据放于ALU,这里我们可以将ALU的计算再一次进行细分,也就是套娃,比如这里我们进行的是浮点数的运算,有四个子过程,也就是四个分段,并且每一个分段所使用的电路也是不一样的,所以也就又可以设计成一个流水线了,这里并不是指令流水线 而是功能流水线
处理机间的流水线:类似于每一个CPU专门负责一个工作 ,然后将结果传入下一个CPU 中
单功能流水线:是指实现一种专门的固定功能的流水线,如专门搞一个流水线单一来高浮点数的加法
多功能流水线:如指令流水线就是一个多功能流水线,因为可以完成多种指令,每一个指令所表示的功能也就是不一样的

静态流水线:我们在ALU内部实现一个浮点数加法的流水线,如果在ALU内部同一时间内只能完成浮点数加法的运算
动态流水线:次吃ALU中不仅进行着浮点数加法的运算,而且还有其它的电路也在进行其他的运算
非线性流水线:我们之前提过,我们解决数据冲突,我们可以直接将ALU中的数据重新接入到屁股上,作为下一个指令的输入信号,某些功能数次通过流水线可以理解为如使用加法来实现乘法,这个ALU只能通过多次的加法来实现

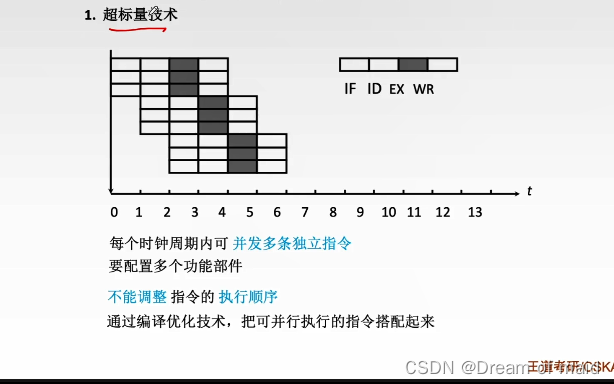
流水线的多发技术
在一个时钟周期内同时并发多条独立的指令,我们增加了多个部件可以支持同一时刻多个部件进行操作
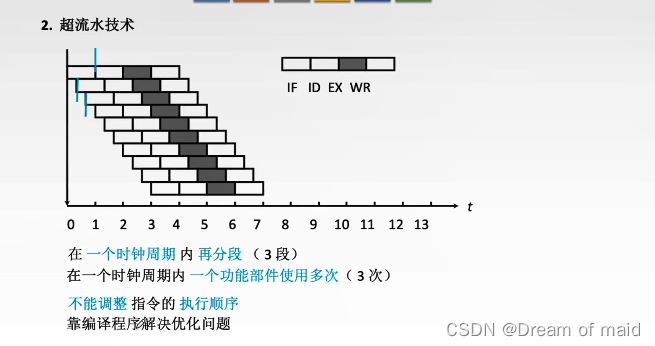
超流水技术
进一步把一个时钟周期在分段,也就是时分复用技术
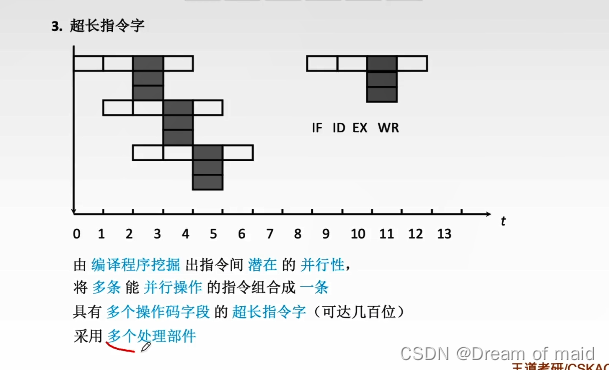
超长指令字
执行阶段有多个操作,当我们执行命令的时候 ,我们发现指令间潜在并行性,将多条整合成一条超长的指令,显然多种操作要同时进行,就需要多个处理部件
五段式指令流水线
本节主要这五个类型的指令 运算类指令,LOAD指令,STORE指令,条件转移指令,无条件转移指令,是如何使用这个五段式流水线来完成相应的工作的
加法注意
在加法指令中M是空段:运算的两个操作数一定是来自于寄存器,或者一个来自寄存器一个来自立即数,而且结果一定是存放于某一个寄存器而不是存于主存,因此对于精简指令集系统来说,访存类阶段是不需要做任何事情的,但这个时间是必须消耗的,我们之前说过为了方便流水线的安排,让所有的指令都统一的经过这样的五个阶段,即便其中的某个阶段是不需要做任何事情的,但是我们仍然需要消耗一样的时间

取数存数指令
RiSC处理器只有取数LOAD和存数SIORE指令才能访问主存,其他指令得到数据一定是来自于某一个寄存器,或者指令中包含一个立即数
注意LOAD 也是需要经过计算这个步骤的,因为我们需要根据基地址与偏移量才能得到有效地址,这里的M 阶段访问的是Cache中的数据,但是若是在Cache中没有命中,则一个时钟周期内,访问主存拿数据,这肯定是完成不了的,所以为了保证流水线的流畅工作,通常Cache 中是能命中的
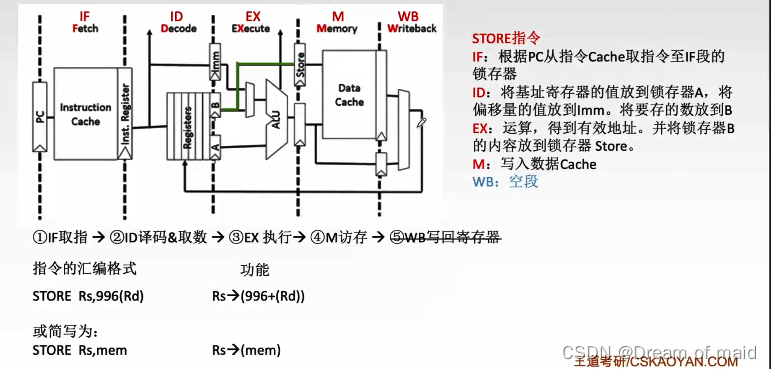
条件转移指令
beq:当我们指向的两个寄存器相等的时候,就满足了这个条件,就需要转移到这个相对于相对位置偏移量的位置,这里的偏移量通常是指往前或者往后偏移多少个指令,而从下一个地址开始偏移,通常这pc加一通常在取值结束之后就自动加一了
bne:当两个寄存器中的值不相等的时 候,我们才会让程序的执行流进行改变
这里没有访问主存的阶段,同样的也没有写回的阶段,因为通常写回都是写回到通用寄存器,而pc这个寄存器不是通用寄存器

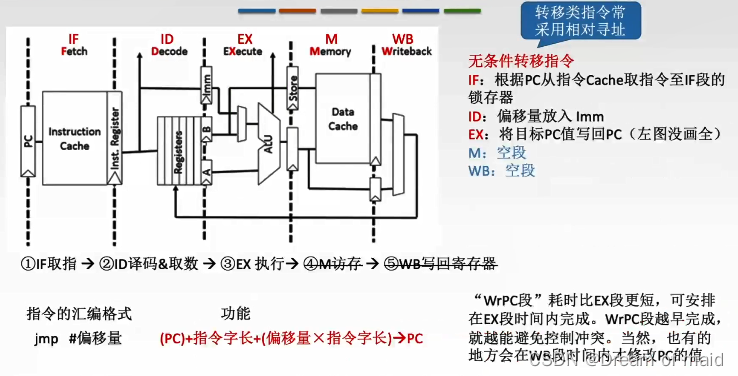
无条件转移指令
这里的偏移量通常用补码表示,可以是正或者负
5.7.1 多处理器的基本概念
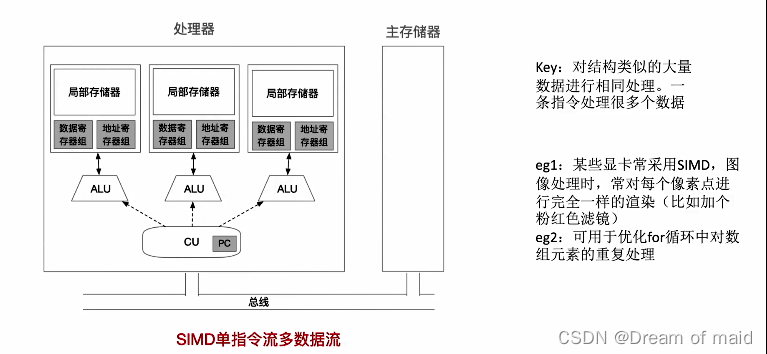
SISD(单指令流单数据流):计算机组成原理中我们一直学习的就是这种,只有一个处理器,一个主存储器,一个控制单元,CU负责取指令,然后根据指令向执行部件发出执行信号,单指令流(同一时间段内只能处理一个指令序列),单数据流(同一个时间只能处理特定的一到两个数据)
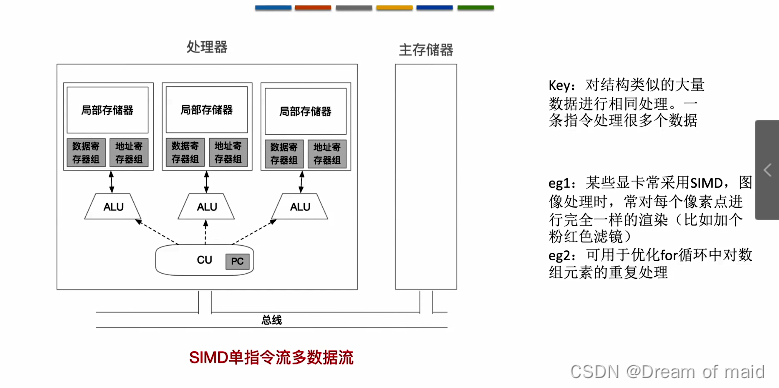
SIMD(单指令流多数据流):CU每次取出一个指令,根据这个指令发出控制信号,并且可以同时向多个执行部件发出信号,各个执行部件在各自的局部存储器中处理各自的数据,这样就可以使得对各块数据的存储并行起来了
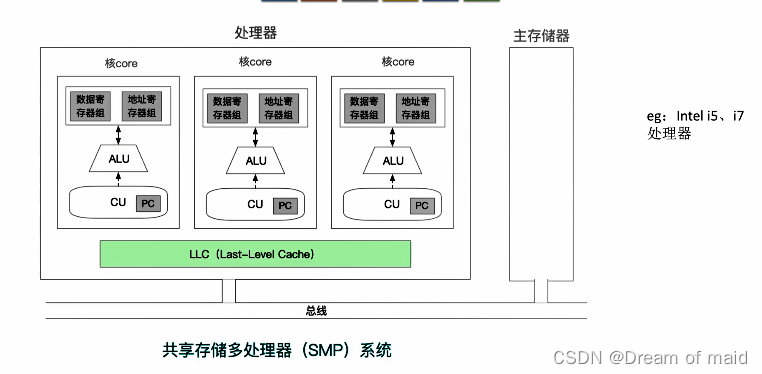
MIMD(多指令流多数据流)
线程级并行是指:每个核可以运行各自的线程,多个线程可以并行的执行,线程级以上也就是进程,之前我们说过Cache也是可以分级的,这里L1 L2这种更高的Cache就是专属某一个核 而L3就是共享的,共享同一个主存,以及最低一级的Cache
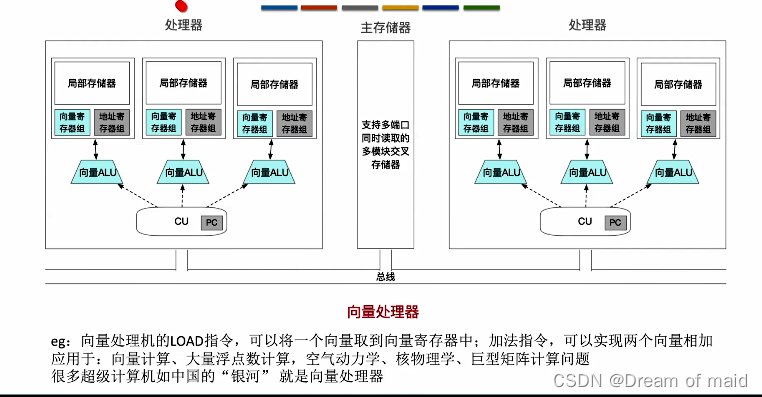
向量处理器
它里面的运算部件直接运算向量,同时里面的寄存器也可存取一个向量,一大特点就是以向量作为处理单位的,在普通的标量计算机中我们处理两个n维向量的相加需要执行n次 但是若是向量计算机我们就只需要执行一次
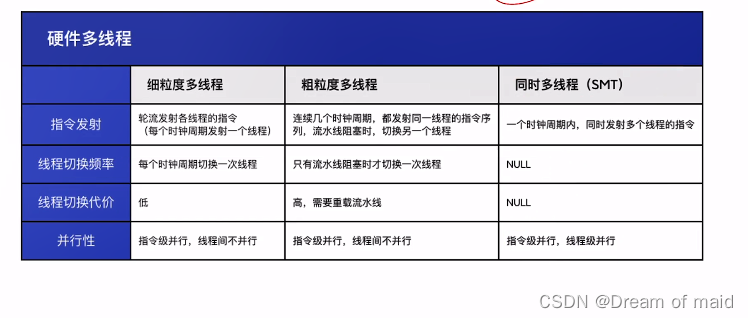
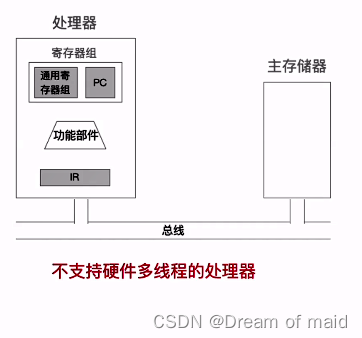
5.7.2 硬件多线程的基本概念
传统的不支持硬件多线程的切换
当我们从线程A 切换到线程B的时候,我们是不是需要将PC以及通用寄存器中的指放到主存中,当我们从线程B且换线程A的时候,我们需要从主存将数据进行恢复,这种保存恢复带来了不小的代价
支持硬件多线程的处理器
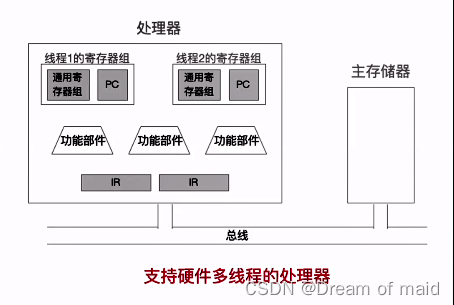
三种硬件多线程
同时多线程:对于线程A和线程B若是采用同时多线程的方式,那么一个时期内,我们会把A的指令取到左边,B的指令取到右边,A的这条指令与B的这条指令就可以并行的执行,我们在同一时刻在处理两个线程的指令