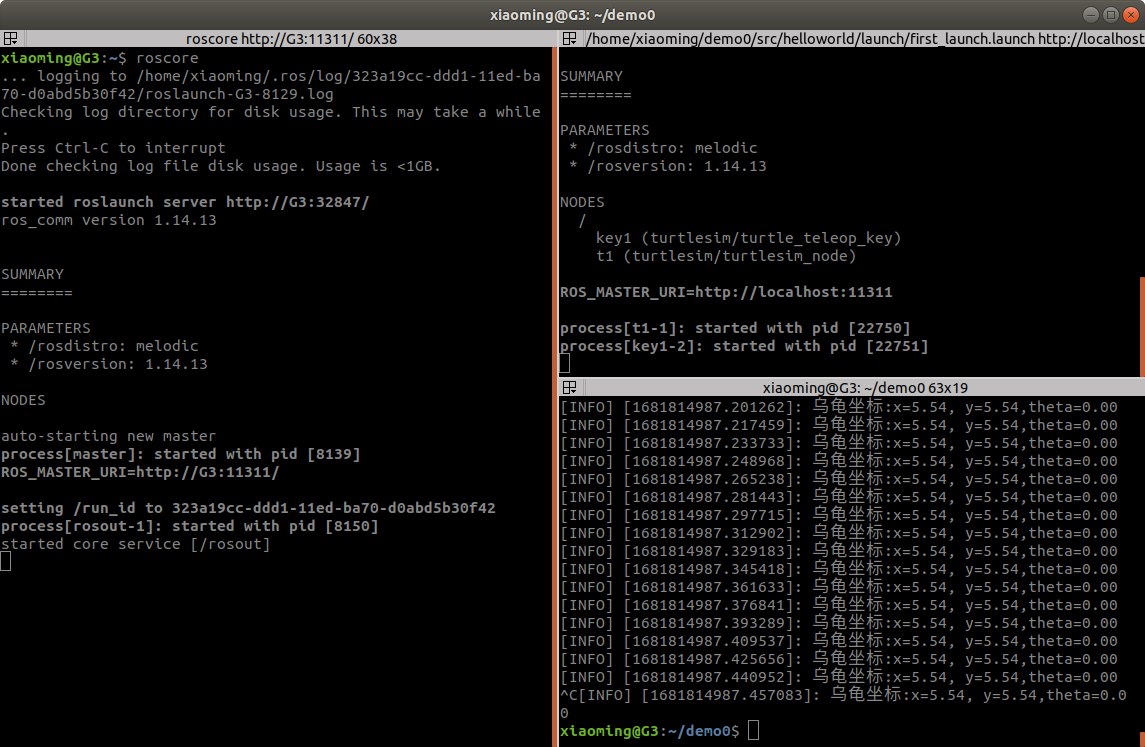
双向广搜是BFS的一种优化方式,就是起点和终点同时往中间搜索。
假设每搜一步,都会有6种新的状态进入队列,搜索10步才能得到答案,总状态数是
1
+
6
+
6
2
+
6
3
+
.
.
.
+
6
9
1+6+6^2+6^3+...+6^9
1+6+62+63+...+69。
但是假如已知终点的状态,起点终点同时搜索,则只要各搜索5步,总状态数是
2
∗
(
1
+
6
+
6
2
+
6
3
+
6
4
)
2*(1+6+6^2+6^3+6^4)
2∗(1+6+62+63+64)
具体实现时,可以开两个队列,分别存起点和终点搜索的状态,挑两者状态数更少的那个队列进行更新。
题目

代码
要对字符串操作,记录该字符串是否已经在队列中和其变换距离,可用map存储。
由于不想用string,用char*以获得更好的性能,结果踩了好几个坑
- strncpy在拷贝时,如果源数组长度>=输入的长度,则不会以
'\0'结尾,需要多拷1位 - queue的push虽然是值拷贝,但是传入char*时只会对指针拷贝,指针指向的内存在退出作用域后就会消失,所以newStr不能用数组形式分配在栈上,而要用new的形式分配在堆上
- 用
char*作为map的key时,比较的是指针的值,也就是地址。所以即便两个字符串相同,但是在不同内存时也无法比较,要重写map的hash和比较规则。 - 最后为了防止内存泄漏,要手动delete自己new的内存。通过遍历map的方式来delete,因为最先输入的起点A和终点B也会被delete,所以A和B也是通过new分配内存。
- 注意二维数组的实际含义。
strA的类型是指向包含M个char元素的数组指针,这样的数组指针有N个。表达式*(strA + i)(等价于strA[i])表示找到N个里的第i个数组指针,取出这个指针指向的值。
数组指针指向的是数组,数组名本质是一个常量指针,因此strA[i]的类型是指向char型的指针。
由于传的参数是strA,由上面的分析可以得到传参类型:指向包含M个char元素的数组指针。
数组指针的写法为:char (*strA)[M];在参数中也可写作char strA[][M]。注意M不可省略。
#include <iostream>
#include <cstring>
#include <queue>
#include <unordered_map>
using namespace std;
const int N = 10, M = 25;
char strA[N][M], strB[N][M];
int n;
struct ptrCmp
{
bool operator()(const char * s1, const char * s2) const {
return strcmp(s1, s2) == 0;
}
};
struct ptrHash
{
size_t operator()(const char *str) const {
size_t strLength = strlen(str);
size_t hash = std::_Hash_impl::hash(str, strLength);
return hash;
}
};
int add(queue<char *>& qA, unordered_map<char *, int, ptrHash, ptrCmp>& disA, unordered_map<char *, int, ptrHash, ptrCmp>& disB,
char (*strA)[M], char (*strB)[M]) { // 数组指针strA,strA是指向 包含M个char元素的数组的指针
char* str = qA.front();
qA.pop();
for (int i = 0; i < strlen(str); i++ ) {
for (int j = 0; j < n; j ++ ) {
if (!strncmp(str + i, strA[j], strlen(strA[j]))) {
// char newStr[M]; // 局部变量
char* newStr = new char[M];
strncpy(newStr, str, i);
strncpy(newStr + i, strB[j], strlen(strB[j]));
// +1把str最后的'\0'也拷贝过去
strncpy(newStr + i + strlen(strB[j]), str + i + strlen(strA[j]),strlen(str) - i - strlen(strA[j]) + 1 );
if (disB.count(newStr)) {
return disA[str] + disB[newStr] + 1;
}
if (strlen(newStr) > 20 || disA.count(newStr)) {
continue;
}
qA.push(newStr); // push的拷贝构造函数只拷贝了newStr的值,也就是指向字符串第一个位置的指针(浅拷贝)。newStr是局部变量时,随着退出函数就会消失,队列里字符串是错的。所以要用new分配在堆里。
disA[newStr] = disA[str] + 1;
}
}
}
return -1;
}
int bfs(char *A, char *B) {
if (strcmp(A, B) == 0) return 0;
queue<char *> qA, qB;
unordered_map<char *, int, ptrHash, ptrCmp> disA, disB;
qA.push(A); qB.push(B);
disA[A] = 0, disB[B] = 0;
int ans = 0;
while(!qA.empty() && !qB.empty()) {
if (qA.size() < qB.size()) {
ans = add(qA, disA, disB, strA, strB);
}
else {
ans = add(qB, disB, disA, strB, strA);
}
if (ans > 0 && ans <= 10) return ans;
}
// 释放堆上的内存
for (auto & it : disA) {
delete it.first;
}
disA.clear();
for (auto & it : disB) {
delete it.first;
}
disB.clear();
return ans;
}
int main() {
char *A, *B;
A = new char[M]; B = new char[M];
cin >> A >> B;
while(cin >> strA[n] >> strB[n]) n ++ ;
int ans = bfs(A, B);
if (ans < 0) cout << "NO ANSWER!";
else cout << ans << endl;
return 0;
}