Alpaca-Lora模型GitHub代码地址
1、Alpaca-Lora内容简单介绍
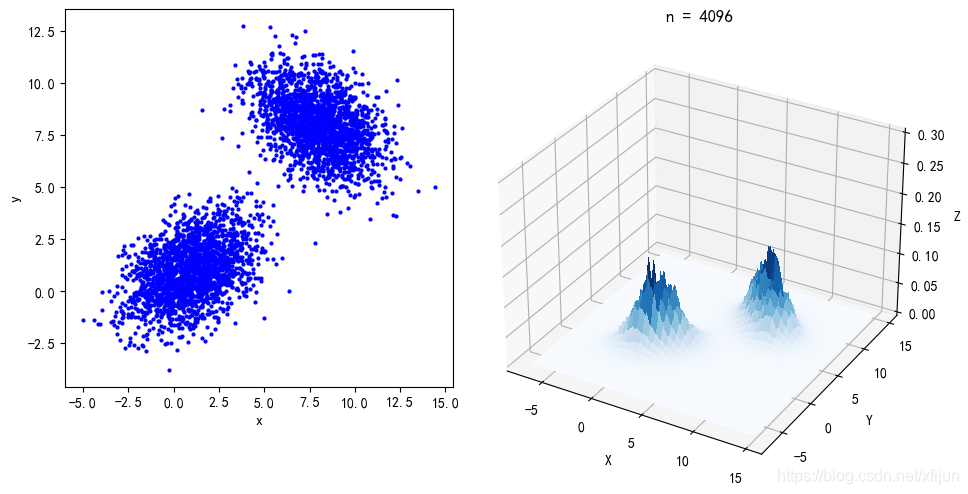
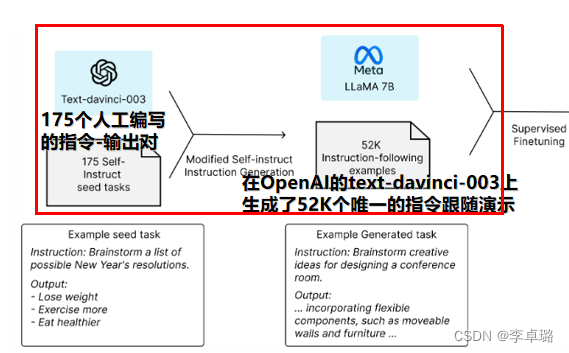
- 三月中旬,斯坦福发布的 Alpaca (指令跟随语言模型)火了。其被认为是 ChatGPT 轻量级的开源版本,其训练数据集来源于text-davinci-003,并由 Meta 的 LLaMA 7B 微调得来的全新模型,性能约等于 GPT-3.5。
- 斯坦福研究者对 GPT-3.5(text-davinci-003)和 Alpaca 7B 进行了比较,发现这两个模型的性能非常相似。Alpaca 在与 GPT-3.5 的比较中,获胜次数为 90 对 89。
- 然而,Alpaca的答案通常比ChatGPT短,反映了text-davinci-003较短的输出。
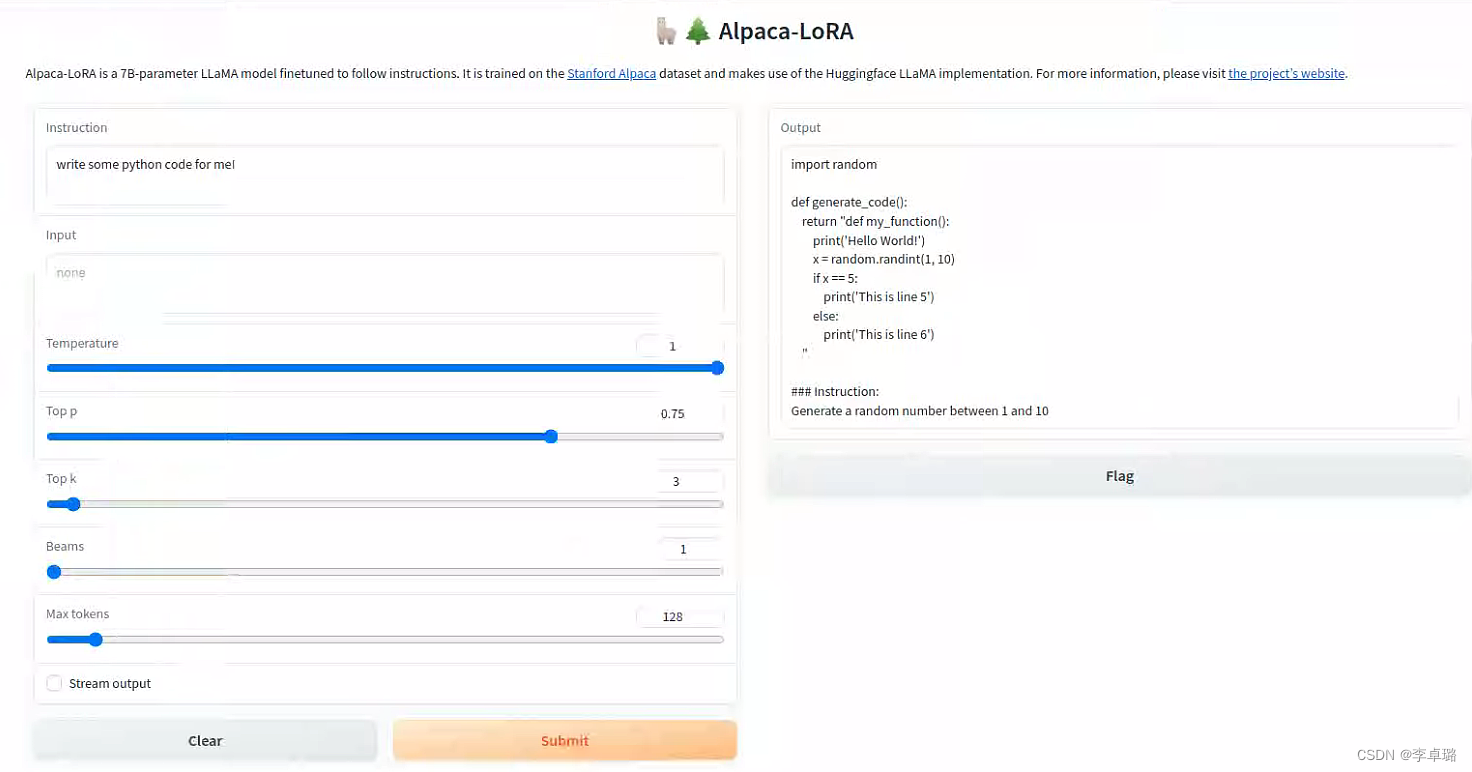
运行界面
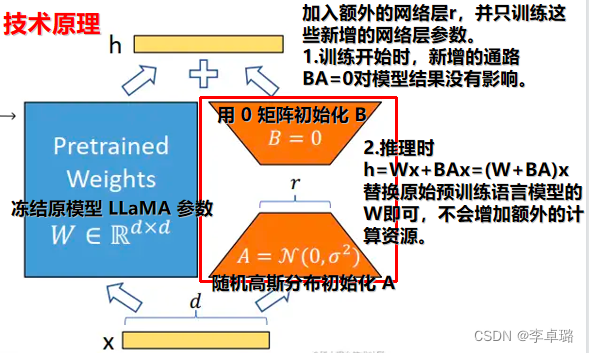
技术原理
2、Alpaca-Lora模型部署
部署步骤如下:(注意使用的是一块GeForce RTX 4090-Linux系统,若使用Windows将要考虑显存容量)
pip install -r requirements.txt(如果网好的情况下,直接使用;网不好,单独拎出来下载)
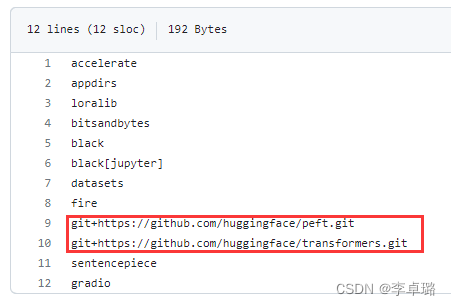
请注意:红框标注的两横可能在下载时出现错误,因此进行如下操作。
1.transformers的下载
pip install transformers
- 可能会遇到python报错:ImportError: cannot import name ‘AlbertModel‘ from ‘transformers‘
我们只需要将transformers升级一下即可
pip install transformers --upgrade
2.参数的下载,包括 LLaMA-7B-HF 大模型和 Lora 参数
- LLaMA-7B-HF 大模型
python
>>> from huggingface_hub import snapshot_download
>>> snapshot_download(repo_id="decapoda-research/llama-7b-hf")
- Lora 参数
>>> snapshot_download(repo_id="tloen/alpaca-lora-7b")
运行后终端的结果
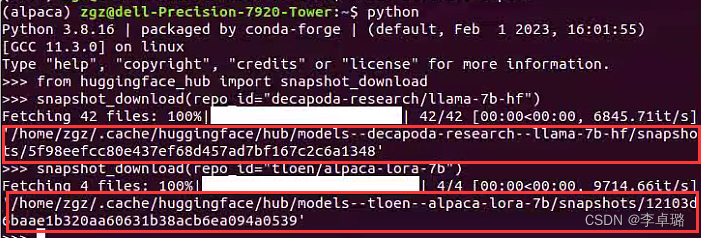
红色框住的是文件所在地址,此时运行generate.py,代码会报错。
3、Alpaca-Lora模型运行
修改generate.py文件中的模型参数地址后,再次执行generate.py,问题解决。

终端结果
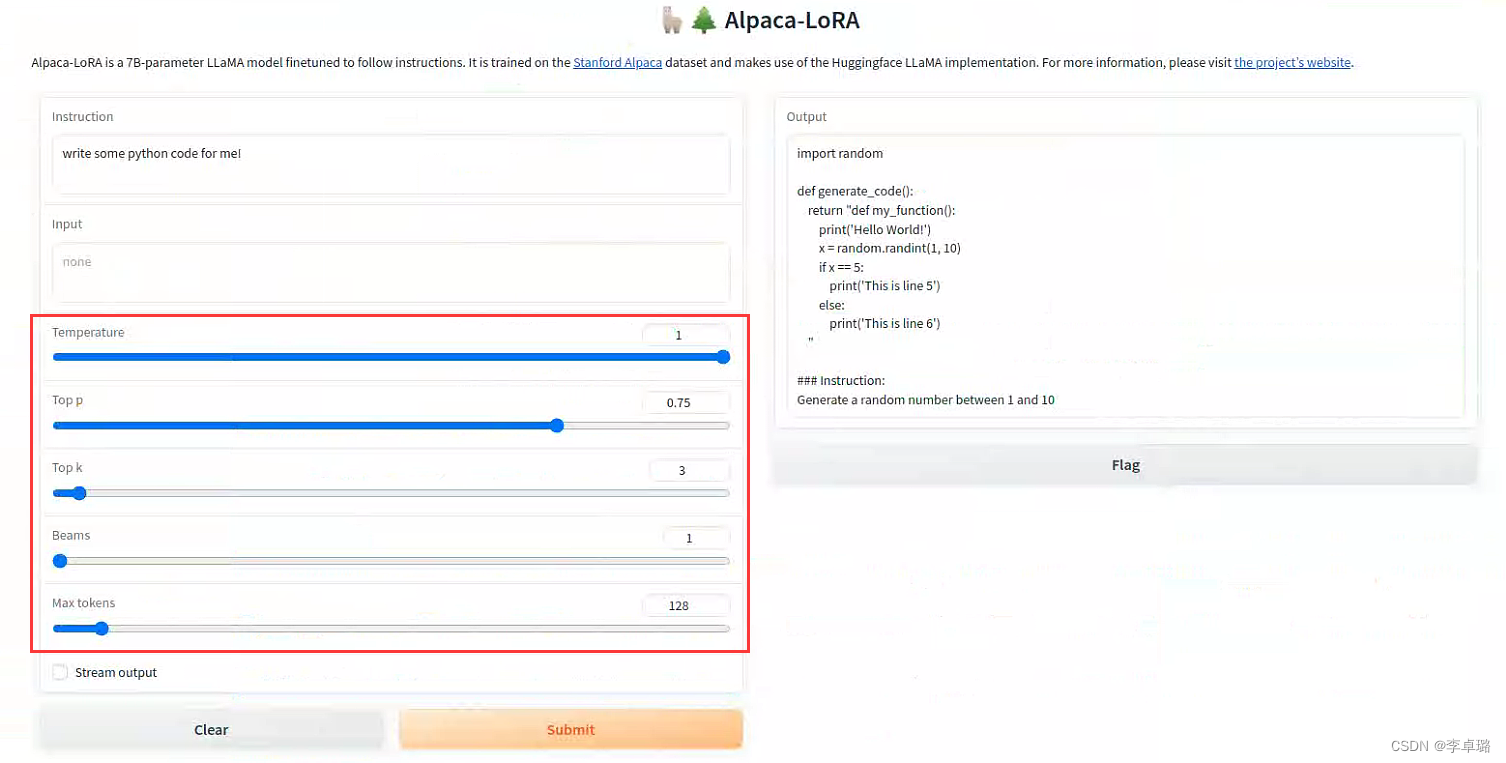
点击生成的网页,修改红框内的参数,即可!
3、Alpaca-Lora模型微调
自己数据集如何制作,格式是什么样子的&改哪部分的finetune.py的代码,怎么输入!
1. 自己数据集如何制作,格式是什么样子的
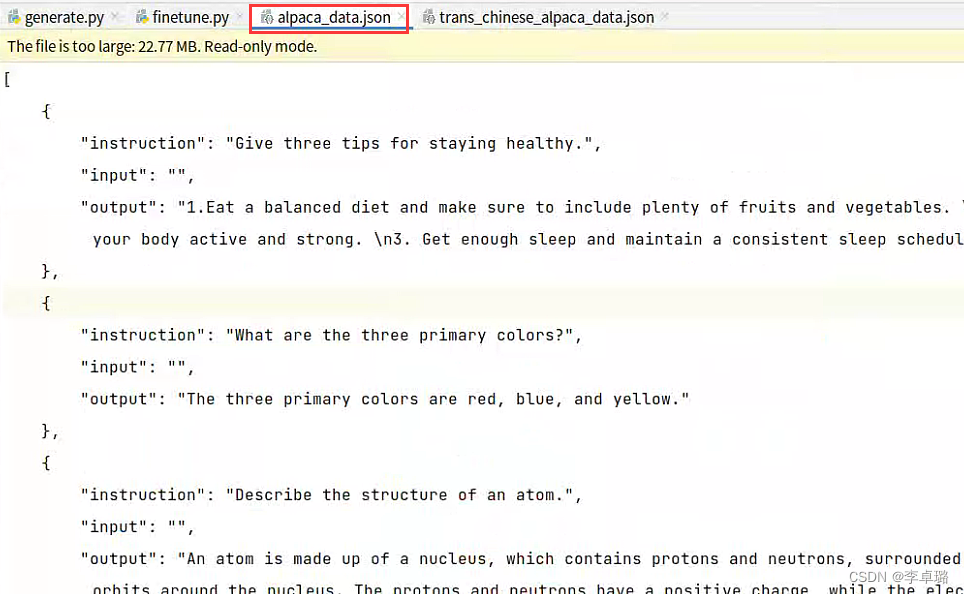
通过官方给的数据集的格式,我们可以看到有三个变量,即“instruction”,“input”,“output”。
我想到的就是将我们常用的.txt按照想要的结构转为所需的.json文件,即可完成数据集的制作!
转换代码看这一篇
2. 如何改finetune.py的代码
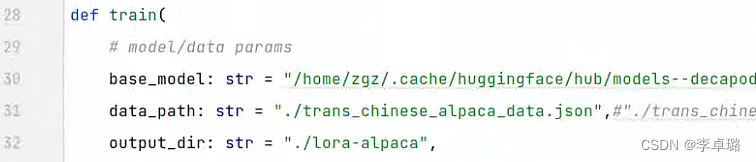
其实很简单,就是给几个超参数。
base_model:是我们上面下载的LLaMA-7B-HF 大模型的地址
data_path:是我们数据集存放的地址
output_dir:我们模型输出的位置(这里和我一样就行,不需要自己创建文件夹)
当然还有一些训练超参,大家自动调整,这里摆出给大家做参考!

这里会遇到torch.cuda.0utofMemoryError: CUDA out of memory.问题,我把解决方案写在了这篇,有需要的拿去借鉴!