性能测试,监控磁盘读写iostat
iostat是I/O statistics(输入/输出统计)的缩写,iostat工具将对系统的磁盘操作活动进行监视。它的特点是汇报磁盘活动统计情况,同时也会汇报出 CPU使用情况。同vmstat一样,iostat也有一个弱点,就是它不能对某个进程进行深入分析,仅对系统的整体情况进行分析。
iostat的语法如下:
iostat [ -c | -d ] [ -k ] [ -t ] [ -V ] [ -x [ device ] ] [ interval [ count ] ]
其中,-c为汇报CPU的使用情况;-d为汇报磁盘的使用情况;-k表示每秒按kilobytes字节显示数据;-t为打印汇报的时间;-v表示打印出版本信息和用法;-x device指定要统计的设备名称,默认为所有的设备;interval指每次统计间隔的时间;count指按照这个时间间隔统计的次数。
1、性能测试过程中用到的命令
命令:iostat -d -x -k 1
-d:仅显示磁盘统计信息,与-c选项互斥
-x:显示更详细的磁盘报告信息,默认只显示六列,加上该参数后会显示更详细的信息(该参数仅在linux内核版本2.4以后数据才是准确的)
-k:以 kb 为单位显示,默认情况下,iostat的输出是以block作为计量单位,加上这个参数可以以kb作为计量单位显示。(该参数仅在linux内核版本2.4以后数据才是准确的)
1 :数据显示每隔1秒刷新一次。
2、监控结果
100线程,循环执行300s(5分钟),对数据库进行更新操作的IO监控
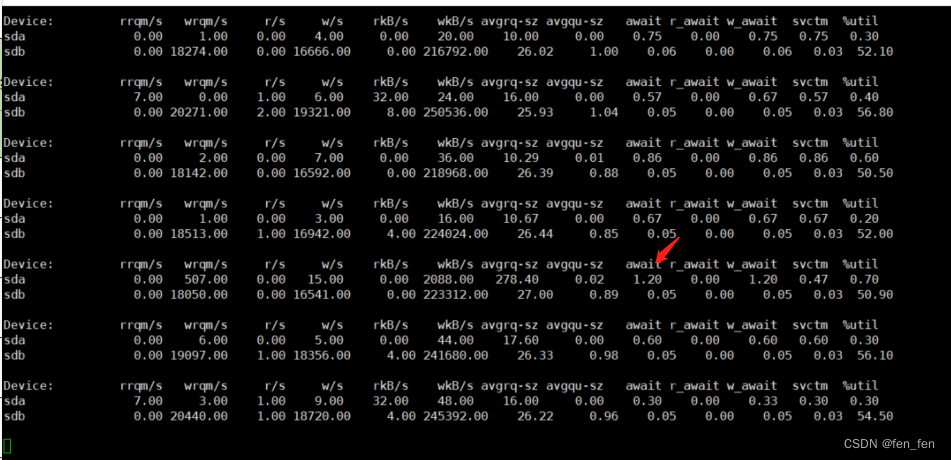
上面图说明:
磁盘:dba 1、wkB/s的值为2088,表示每秒写入2088KB 2、await的值为1.2,svctm的值0.47,await的值>svctm的值,则表示I/O队列有等待。 如果svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好,如果await的值远高于svctm的值,则表示I/O队列等待太长,系统上运行的应用程序将变慢。 3、a_wait的值为1.2,表示每个写操平均所需要的时间1.2ms 磁盘:dbb 1、w/s的值为16541,表示每秒向该设备发出的写请求数为16541. 2、wkB/s的值为223312KB/s,表示每秒写入223312KB 3、avgqu-sz为0.89,表示平均队列长度为0.89[队列里的平均I/O请求数量,更恰当的理解应该是平均未完成的I/O请求数量。] 4、%util为50.9%如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;如果 await 远大于 svctm,说明I/O 队列太长,io响应太慢,则需要进行必要优化。如果avgqu-sz比较大,也表示有当量io在等待。如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。
3、结果参数说明
参考:Linux高阶—磁盘性能分析iostat
如何通过以上指标数据判断磁盘有没有瓶颈呢?
查看await值,响应时间是不是长期响应慢,如果是那肯定有问题;
查看svctm的值与await很接近,说明IO任务提交之后,IO立即响应了,表示几乎没有I/O等待,磁盘性能很好,反之则有问题;
查看aqu-sz队列值,越小越好,反之差值越大,队列越大,说明有问题;
参考说明:http://www.xaprb.com/blog/2010/09/06/beware-of-svctm-in-linuxs-iostat/
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
rrqm/s:每秒合并读操作的次数,如果两个读操作读取相邻的数据块时,可以被合并成一个,以提高效率。合并的操作通常是I/O scheduler(也叫elevator)负责的。每秒这个设备相关的读取请求有多少被Merge了(当系统调用需要读取数据的时候,VFS将请求发到各个FS,如果FS发现不同的读取请求读取的是相同Block的数据,FS会将这个请求合并Merge); wrqm/s:每秒这个设备相关的写入请求有多少被Merge了。 r/s 每秒向该设备发出的读请求数 w/s 同样,它是每秒向该设备发出的写请求数 rsec/s:每秒读取的扇区数; wsec/s:每秒写入的扇区数。 rKB/s:每秒读取的字节数(KB) wKB/s:每秒写入的字节数(KB) avgrq-sz:平均请求扇区的大小 avgqu-sz:是平均请求队列的长度。毫无疑问,队列越短越好。 这里使用超市购物来比较iostat的输出。当我们在超市结账时,通常会有很多人排队。排队长度在一定程度上反应了收银台的繁忙程度。那么这个变量就反映在avgqu-sz的输出上,值越大,排队等待处理的io越多。 await:await是单个I/O所消耗的时间,包括硬盘设备处理I/O的时间和I/O请求在kernel队列中等待的时间: await = IO 平均处理时间 + IO在队列的平均等待时间 每一个IO请求的处理的平均时间(单位是毫秒)。这里可以理解为IO的响应时间,一般地系统IO响应时间应该低于5ms,如果大于10ms就比较大了。 这个时间包括了队列时间和服务时间,也就是说,一般情况下,await大于svctm,它们的差值越小,则说明队列时间越短,反之差值越大,队列时间越长,说明系统出了问题。 r_await:每个读操作平均所需要的时间,包括硬盘设备读操作的时间,也包括在内核队列中的时间。(单位ms) w_wait:每个写操平均所需要的时间,包括硬盘设备写操作的时间,也包括在队列中等待的时间。(单位ms) svctm:表示平均每次设备I/O操作的服务时间(以毫秒为单位)。 如果svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好,如果await的值远高于svctm的值,则表示I/O队列等待太长,系统上运行的应用程序将变慢。 如果svctm比较接近await,说明I/O几乎没有等待时间;如果await远大于svctm,说明I/O队列太长,应用得到的响应时间变慢, 如果响应时间超过了用户可以容许的范围,这时可以考虑更换更快的磁盘,md调整内核elevator算法,优化应用,或者升级CPU。 %util: 在统计时间内所有处理IO时间,除以总共统计时间。 例如,如果统计间隔1秒,该设备有0.8秒在处理IO,而0.2秒闲置,那么该设备的%util = 0.8/1 = 80%,所以该参数暗示了设备的繁忙程度 。一般地,如果该参数是100%表示设备已经接近满负荷运行了 (如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。) (当然如果是多磁盘,即使%util是100%,因为磁盘的并发能力,所以磁盘使用未必就到了瓶颈.)
其他参考:
一、重点关注参数
1、iowait% 表示CPU等待IO时间占整个CPU周期的百分比,如果iowait值超过50%,或者明显大于%system、%user以及%idle,表示IO可能存在问题。
2、avgqu-sz 表示磁盘IO队列长度,即IO等待个数。
3、await 表示每次IO请求等待时间,包括等待时间和处理时间
4、svctm 表示每次IO请求处理的时间
5、%util 表示磁盘忙碌情况,一般该值超过80%表示该磁盘可能处于繁忙状态。
二、另外还可以参考
一般:
svctm < await (因为同时等待的请求的等待时间被重复计算了),
svctm的大小一般和磁盘性能有关:CPU/内存的负荷也会对其有影响,请求过多也会间接导致 svctm 的增加。
await: await的大小一般取决于服务时间(svctm) 以及 I/O 队列的长度和 I/O 请求的发出模式。
如果 svctm 比较接近 await,说明I/O 几乎没有等待时间;
如果 await 远大于 svctm,说明 I/O队列太长,应用得到的响应时间变慢,
如果响应时间超过了用户可以容许的范围,这时可以考虑更换更快的磁盘,调整内核 elevator算法,优化应用,或者升级 CPU。
队列长度(avgqu-sz)也可作为衡量系统 I/O 负荷的指标,但由于 avgqu-sz 是按照单位时间的平均值,所以不能反映瞬间的 I/O 洪水。三、使用iostat -xz 1还是使用sar -d 1,对于磁盘重要的参数是:
avgqu-sz: 发送给设备I/O请求的等待队列平均长度,对于单个磁盘如果值>1表明设备饱和,对于多个磁盘阵列的逻辑磁盘情况除外;
await(r_await、w_await): 平均每次设备I/O请求操作的等待时间(ms),包含请求排列在队列中和被服务的时间之和;
svctm: 发送给设备I/O请求的平均服务时间(ms),如果svctm与await很接近,表示几乎没有I/O等待,磁盘性能很好,否则磁盘队列等待时间较长,磁盘响应较差;
%util: 设备的使用率,表明每秒中用于I/O工作时间的占比,单个磁盘当%util>60%的时候性能就会下降(体现在await也会增加),当接近100%时候就设备饱和了,但对于有多个磁盘阵列的逻辑磁盘情况除外;
四、其他说明:
svctm参数代表平均每次设备I/O操作的服务时间 (毫秒),反应了磁盘的负载情况,如果该项大于15ms(或者20ms),并且util%接近100%,那就说明,磁盘现在是整个系统性能的瓶颈了。await 参数代表平均每次设备I/O操作的等待时间 (毫秒),也要多和 svctm 来参考。差的过高就一定有 IO 的问题。如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;如果 await 远大于 svctm,说明 I/O 队列太长,应用得到的响应时间变慢。
await值的大小一般取决与svctm的值和I/O队列长度以及I/O请求模式,如果svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好,如果await的值远高于svctm的值,则表示I/O队列等待太长,系统上运行的应用程序将变慢,此时可以通过更换更快的硬盘来解决问题。正常情况下svctm应该是小于await值的,而svctm的大小和磁盘性能有关,CPU、内存的负荷也会对svctm值造成影响,过多的请求也会间接的导致svctm值的增加。
%util项的值也是衡量磁盘I/O的一个重要指标,如果%util接近100%,表示磁盘产生的I/O请求太多,I/O系统已经满负荷的在工作,该磁盘可能存在瓶颈。长期下去,势必影响系统的性能。参考:深入理解iostat命令,哪些指标比较重要?
4、其他输入参数说明:
参数详解
-c: 仅显示CPU统计信息,与-d选项互斥
-d:仅显示磁盘统计信息,与-c选项互斥
-h:使用NFS(Network File System网络文件系统)的输出报告,更加友好可读。需要使用-n参数开启NFS。
-k:以 kb 为单位显示,默认情况下,iostat的输出是以block作为计量单位,加上这个参数可以以kb作为计量单位显示。(该参数仅在linux内核版本2.4以后数据才是准确的)
-m:以 mb 为单位显示(该参数仅在linux内核版本2.4以后数据才是准确的)
-N:显示磁盘阵列(LVM) 信息。
-V:显示版本信息
-x:显示更详细的磁盘报告信息,默认只显示六列,加上该参数后会显示更详细的信息(该参数仅在linux内核版本2.4以后数据才是准确的)
-n:显示NFS(Network File System网络文件系统) 使用情况(该参数仅在linux内核版本2.6.17以后有效)
-t:输出报告时显示系统时间
-p:[ { device [,…] | ALL } ] 显示磁盘分区的相关统计信息(默认粒度只到磁盘,没有显示具体的逻辑分区)
-y:跳过不显示第一次报告的数据,因为iostat使用的是采样统计,所以iostat的第一次输出的数据是自系统启动以来的累计的数据
-y 这个参数非常重要,因为第一次数据不属于正常数据,所以如果做数据统计时,计入了统计,会影响最终数据结果-z:只显示在采样周期内有活动的磁盘
-j:{ ID | LABEL | PATH | UUID | … } 磁盘列表的Device列要用什么维度来描述磁盘
示例
- 每隔 1秒刷新显示,显示3次
iostat 1 3 - 每隔 2秒刷新显示详细信息,显示3次
iostat -x 2 3 - 每隔 1秒刷新,显示CPU统计信息3次
iostat -c 1 3 - 每隔 1秒刷新显示详细信息,显示3次,去除第1次
iostat -x -y 1 3
参考:iostat 命令详解
Linux 中iostat 命令详解(重要),分析可看。
Linux iostate命令实战
https://blog.csdn.net/m369880395/article/details/127789732
磁盘性能指标—IOPS、吞吐量及测试_最大iops