在配置类中配置页面解析器
之前我们使用页面解析器是在XML配置文件中使用的,但是当我们试用了纯注解式的整合之后,我们没有了配置文件,要如何去将之前我们在配置文件中编写的前端控制器,以及静态资源的释放这些功能配置添加到项目中呢?
这时候我们就需要使用到一个新的接口,叫做WebMvcConfig,这个接口的作用就是用来添加一些对于MVC的配置。当我们自己自己定义的类去实现了这个接口之后,MVC在启动的时候,就会加载这个类中的配置,并应用到项目中,我们可以进入这个接口文件中去看看它具体都可以进行什么配置:
// // Source code recreated from a .class file by IntelliJ IDEA // (powered by FernFlower decompiler) // package org.springframework.web.servlet.config.annotation; import java.util.List; import org.springframework.format.FormatterRegistry; import org.springframework.http.converter.HttpMessageConverter; import org.springframework.lang.Nullable; import org.springframework.validation.MessageCodesResolver; import org.springframework.validation.Validator; import org.springframework.web.method.support.HandlerMethodArgumentResolver; import org.springframework.web.method.support.HandlerMethodReturnValueHandler; import org.springframework.web.servlet.HandlerExceptionResolver; public interface WebMvcConfigurer { default void configurePathMatch(PathMatchConfigurer configurer) { } default void configureContentNegotiation(ContentNegotiationConfigurer configurer) { } default void configureAsyncSupport(AsyncSupportConfigurer configurer) { } default void configureDefaultServletHandling(DefaultServletHandlerConfigurer configurer) { } default void addFormatters(FormatterRegistry registry) { } default void addInterceptors(InterceptorRegistry registry) { } default void addResourceHandlers(ResourceHandlerRegistry registry) { } default void addCorsMappings(CorsRegistry registry) { } default void addViewControllers(ViewControllerRegistry registry) { } default void configureViewResolvers(ViewResolverRegistry registry) { } default void addArgumentResolvers(List<HandlerMethodArgumentResolver> resolvers) { } default void addReturnValueHandlers(List<HandlerMethodReturnValueHandler> handlers) { } default void configureMessageConverters(List<HttpMessageConverter<?>> converters) { } default void extendMessageConverters(List<HttpMessageConverter<?>> converters) { } default void configureHandlerExceptionResolvers(List<HandlerExceptionResolver> resolvers) { } default void extendHandlerExceptionResolvers(List<HandlerExceptionResolver> resolvers) { } @Nullable default Validator getValidator() { return null; } @Nullable default MessageCodesResolver getMessageCodesResolver() { return null; } }
当我们继承了这个类之后,他并没有报错提示我们必须继承的方法,因为这个接口中的方法都是被default修饰的,可以不用必须实现,只需要实现我们想要实现的配置方法即可。我们需要使用的就是配置页面解析器和静态资源的释放。
如果我们是不知道有这个类,我们可以来到官方的帮助文档去查找有没有对应的配置

这就表示在Spring中确实有一个类负责使用Java的方式,也就是使用类的方式去设置一些基础设置,然后我们继续向下找:
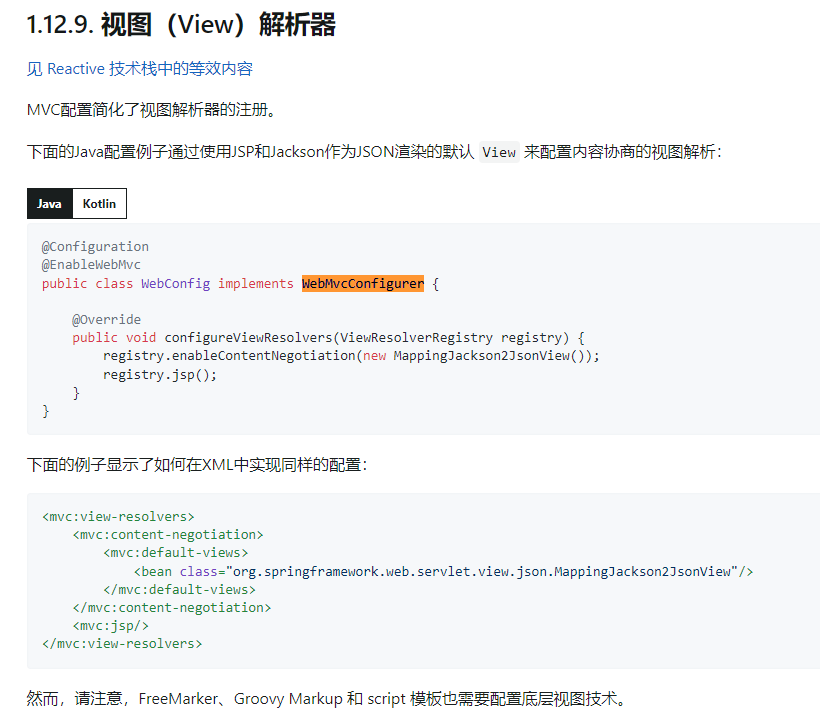
可以看到,当我们搜索解析器的时候,就可以看到有一个视图解析器,并且已经给我们列出了方法和对比XML配置文件,我们只需要重写这个方法,并且根据自己的项目在方法中填写参数即可。这样我们就完成了对于页面解析器的配置。
对于静态资源的释放也是一样的,我们在官方的帮助文档中找到对应的方法,然后实现方法,在方法中编写配置即可。
package com.spring.dao; import org.springframework.web.servlet.config.annotation.DefaultServletHandlerConfigurer; import org.springframework.web.servlet.config.annotation.ViewResolverRegistry; import org.springframework.web.servlet.config.annotation.WebMvcConfigurer; public class config implements WebMvcConfigurer { // 视图解析器的配置 @Override public void configureViewResolvers(ViewResolverRegistry registry) { // 第一个参数表示前缀,第二个参数表示后缀 registry.jsp("/SpringMVC/pages",".jsp"); } // 配置静态资源的释放,其实就是将静态资源交给服务器的默认的servlet处理,这里就是将对静态资源的请求交给了Tomcat默认的servlet去处理,也就是不处理 /*官方的原话翻译就是下面这样,我是没看懂 * Spring MVC允许将 映射到 (从而覆盖容器的默认Servlet的映射),同时仍然允许静态资源请求由容器的默认Servlet处理。它配置了一个 ,其URL映射为 ,相对于其他URL映射,其优先级最低。DispatcherServlet/DefaultServletHttpRequestHandler/** 这个 handler 将所有请求转发到默认的 Servlet。因此,它必须在所有其他URL 的顺序中保持最后。如果你使用 ,情况就是这样。 */ @Override public void configureDefaultServletHandling(DefaultServletHandlerConfigurer configurer) { configurer.enable(); } }
对于这种的,如果我们不确定是否存在一个操作可以方便我们的代码的编写,我们最直观的方法就是去百度,或者去官方文档去找有没有对应的操作。
对于拦截器和过滤器的配置
之前我们说过,JavaEE的拦截器就相当于是JavaWeb的过滤器,但是两者的配置还是有一些区别的,比如我们要在一个项目中要同时出现拦截器和过滤器的时候。
一般来讲,过滤器的作用是修改请求和响应的编码的统一,而拦截器的作用是进行权限校验,比如你没有登录我就不会让你访问除了登陆资源之外的其他资源,知道你登陆为止。这样我们就需要去创建自定义的拦截规则。
我们要配置过滤器只需要像之前那样,在拦截的类名上面添加过滤器注解@WebFilter,然后配置过滤路径即可。
当我们配置拦截器的时候,需要首先定义一个拦截器类,在类中定义拦截规则,然后还是通过实现WebMvcConfig接口去通过方法配置拦截器。
自定义过滤器类:
package com.spring.interceptor;// 拦截器类 import org.springframework.web.servlet.HandlerInterceptor; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; public class ResourcesInterceptor implements HandlerInterceptor { @Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { // 如果用户已经登陆直接放行 Object userSession = request.getSession().getAttribute("USER_SESSION"); if(userSession!=null){ // 返回true表示放行 return true; } // 如果没有登录,判断是否访问的登录相关功能 String requestURI = request.getRequestURI(); if(requestURI.indexOf("login")>0){ return true; } // 如果没有登录,访问的也不是登录相关的功能,则给出错误信息后,跳转到登陆页面 request.setAttribute("msg","请先登录"); request.getRequestDispatcher("/admin/login.jsp").forward(request,response); return false; } }
然后我们需要在**实现了WebMvcConfigurer接口的类中重写一个方法:
@Override public void addInterceptors(InterceptorRegistry registry) { // 为拦截器添加拦截路径和排除路径 registry.addInterceptor(new ResourcesInterceptor()) .addPathPatterns("/**") .excludePathPatterns("/css/**","/js/**","/img/**"); }
通过这个配置,来加载拦截器的拦截路径和放行路径,最终完成拦截器的功能。
分页器的使用
在开发环境中,我们还有一个控件是我们会用到的,就是分页插件,比如在这页中我们要显示几行,将我们的查询结果分多少个页展示,这就需要用到我们的分页插件。虽然这个功能我们的SQL语句也可以实现,使用limit关键字也是可以实现的,但是我们要学习在Java中如何使用分页插件去完成分页的功能。
首先,我们要先在pom文件中引入一个依赖坐标,这个依赖就是我们完成分页的插件:
<!-- 分页插件--> <dependency> <groupId>com.github.pagehelper</groupId> <artifactId>pagehelper</artifactId> <version>5.2.0</version> </dependency>
添加依赖之后,我们就开始配置我们的分页插件,首先,我们需要声明一个分页器,在我们的MyBatis的配置类中,我们需要写入这样的代码:
// 配置分页插件的拦截器 @Bean public PageInterceptor pageInterceptor(){ PageInterceptor pageInterceptor = new PageInterceptor(); // 分页插件配置 Properties properties = new Properties(); // 开启分页 properties.setProperty("value","true"); // 加载properties配置进pageInterceptor pageInterceptor.setProperties(properties); return pageInterceptor; }
这样表示我们创建一个一个分页器,然后需要将它交给我们的SqlSessionFaction,在之前我们添加的SqlSessionFactionBean中,我们除了要添加一个数据源的变量,还要添加一个分页器的变量,我们通过调用对应的添加分页器的方法,但是这个方法的值是一个对象数组,而我们只需要添加数组中的其中一个,所以我们首先要把我们的自定义分页器自动注入到一个变量中,然后在对象数组中添加这个变量,我们就可以将我们自己编写的分页器添加进去了。
完整的MyBatis配置类的内容如下:
package com.spring.config; import com.github.pagehelper.PageInterceptor; import org.apache.ibatis.plugin.Interceptor; import org.mybatis.spring.SqlSessionFactoryBean; import org.mybatis.spring.annotation.MapperScan; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import javax.sql.DataSource;import java.util.Properties; // 相关的配置类@Configuration@MapperScan("com.spring.dao") //使用注解的方式进行包扫描,和MapperScannerConfigurer类功能一样 public class MyBatis { @Autowired // 分页拦截器插件变量 private PageInterceptor pageInterceptor; // 配置sqlSessionFactory @Bean public SqlSessionFactoryBean sqlSessionFactoryBean(DataSource dataSource){ SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean(); sqlSessionFactoryBean.setDataSource(dataSource); // 将分页拦截器插件交给MyBatis sqlSessionFactoryBean.setPlugins(new Interceptor[]{pageInterceptor}); return sqlSessionFactoryBean; } 配置分页插件的拦截器 @Bean public PageInterceptor pageInterceptor(){ PageInterceptor pageInterceptor = new PageInterceptor();// 分页插件配置 Properties properties = new Properties(); // 开启分页 properties.setProperty("value","true"); // 加载properties配置进pageInterceptor pageInterceptor.setProperties(properties); return pageInterceptor; } }
现在只是完成了分页器的定义的部分,那么具体要如何去啥用呢?
首先,我们查询的时候,对于结果集的封装,就不能直接封装到实体类中了,而是要封装进一个能被分页器识别的列表中去,我们只需要修改一下我们的结果集封装类即可:
// 根据上架时间查询书籍 @Select("select * from book where book_status != 3 order by book_upload_time desc") @Results(id = "bookMap",value = {@Result(column = "book_id" , property = "id") , @Result(column = "book_name" , property = "name"), @Result(column = "book_isbn" , property = "isbn"),@Result(column = "book_press" , property = "press"), @Result(column = "book_author" , property = "author"),@Result(column = "book_pagination" , property = "pagination"), @Result(column = "book_price" , property = "price"),@Result(column = "book_upload_time" , property = "uploadTime"), @Result(column = "book_status" , property = "status"),@Result(column = "book_borrower" , property = "borrower"), @Result(column = "book_borrower_time" , property = "borrowerTime"),@Result(column = "book_return_time" , property = "returnTime"),}) public Page<book> selectNewBook();
这个能被识别到的集合的名称叫Page,然后泛型还是之前我们的结果集映射类,之后我们就来处理这个集合:
要处理这个集合,我们只需要声明一个集合解析类,然后使用分页解析器,将我们存储在分页中的数据,根据我们传入的参数,这个参数主要是页数和我们一页中显示的商品的列表这两个变量。
首先我们先来看我们的集合解析类:
package com.spring.entity; // 分页结果实体类 import java.io.Serializable; import java.util.List; public class PageResult implements Serializable { // 总数 private long total; // 分页的集合 private List rows; @Override public String toString() { return "PageResult{" + "total=" + total + ", rows=" + rows + '}'; } public long getTotal() { return total; } public void setTotal(long total) { this.total = total; } public List getRows() { return rows; } public void setRows(List rows) { this.rows = rows; } public PageResult(long total, List rows) { this.total = total; this.rows = rows; } public PageResult() { } }
然后就是如何解析我们已经存放在Page列表中的数据:
@RequestMapping("/selectNewbooks") public ModelAndView selectNewBook(){ ModelAndView modelAndView = new ModelAndView(); // 数据和视图 int pageNum = 1; int pageSize = 5; PageResult pageResult = bookService.selectNewBook(pageNum, pageSize); modelAndView.addObject("pageResult",pageResult); modelAndView.setViewName("books_new"); return modelAndView; }
分页器的大概流程
首先我们自下而上,从MyBatis层开始,我们将查询的数据封装进Page集合中,这个集合的泛型是我们自定的结果集映射类。然后来到Service层,在这一层中,我们的方法要返回我们自定义的分页解析类,这个类负责将我们的集合中的数据解析出来,交给前端读取。读取的方式就是讲我们集合中的页数,以及数据交给我们的解析类中,然后构建我们的解析类对象,返回这个对象。然后我们在Controller层中调用Service中的方法,在调用的时候,传入我们要分几页,以及每一页中有几行数据,这样就完成了分页查询。