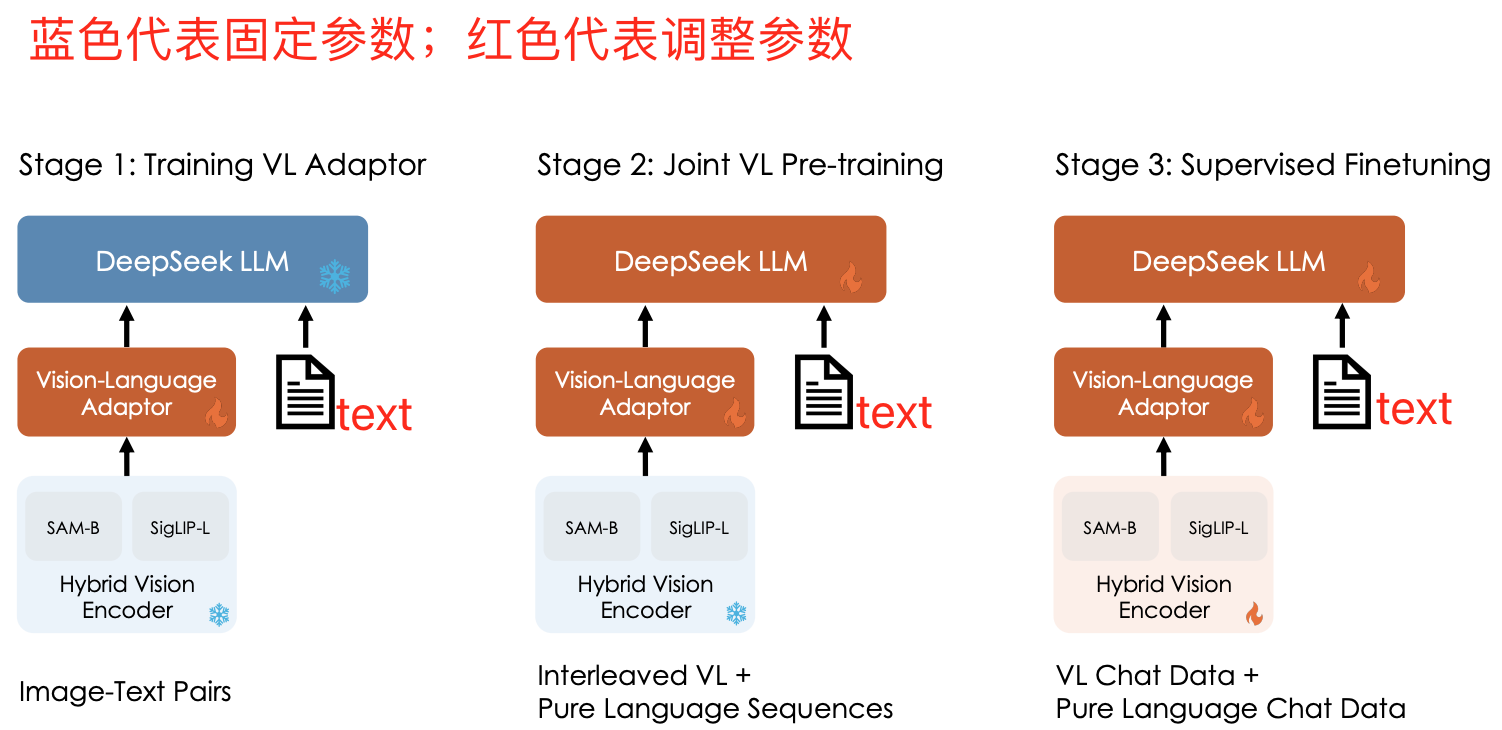
【图问答】DeepSeek-VL 论文阅读笔记
news2026/2/13 15:03:32
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/2341106.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

【专题刷题】滑动窗口(二):水果成篮,所有字母异位词,乘积小于 K 的子数组
📝前言说明:
本专栏主要记录本人的基础算法学习以及LeetCode刷题记录,按专题划分每题主要记录:(1)本人解法 本人屎山代码;(2)优质解法 优质代码;ÿ…

深入理解React中的Props与State:核心区别与最佳实践
在React开发中,props和state是构建交互式UI的两大基石。许多React初学者常常混淆这两者的概念,导致组件设计出现反模式。本文将全面剖析props与state的本质区别,通过实际场景说明它们的适用边界,并分享高效管理组件数据的实践经验…
![STM32单片机入门学习——第46节: [14-1] WDG看门狗](https://i-blog.csdnimg.cn/direct/26edd52d9c6d44abbed01355e6a26031.png)
STM32单片机入门学习——第46节: [14-1] WDG看门狗
写这个文章是用来学习的,记录一下我的学习过程。希望我能一直坚持下去,我只是一个小白,只是想好好学习,我知道这会很难,但我还是想去做! 本文写于:2025.04.23 STM32开发板学习——第46节: [14-1] WDG看门狗 前言开发板说明引用解答和科普一、…

n8n 中文系列教程_05.如何在本机部署/安装 n8n(详细图文教程)
n8n 是一款强大的开源工作流自动化工具,可帮助你连接各类应用与服务,实现自动化任务。如果你想快速体验 n8n 的功能,本机部署是最简单的方式。本教程将手把手指导你在 Windows 或 MacOS 上通过 Docker 轻松安装和运行 n8n,无需服务…
2025第十六届蓝桥杯python B组满分题解(详细)
目录 前言
A: 攻击次数 解题思路:
代码:
B: 最长字符串
解题思路:
代码:
C: LQ图形
解题思路:
代码:
D: 最多次数 解题思路:
代码: E: A * B Problem
解题思路&…
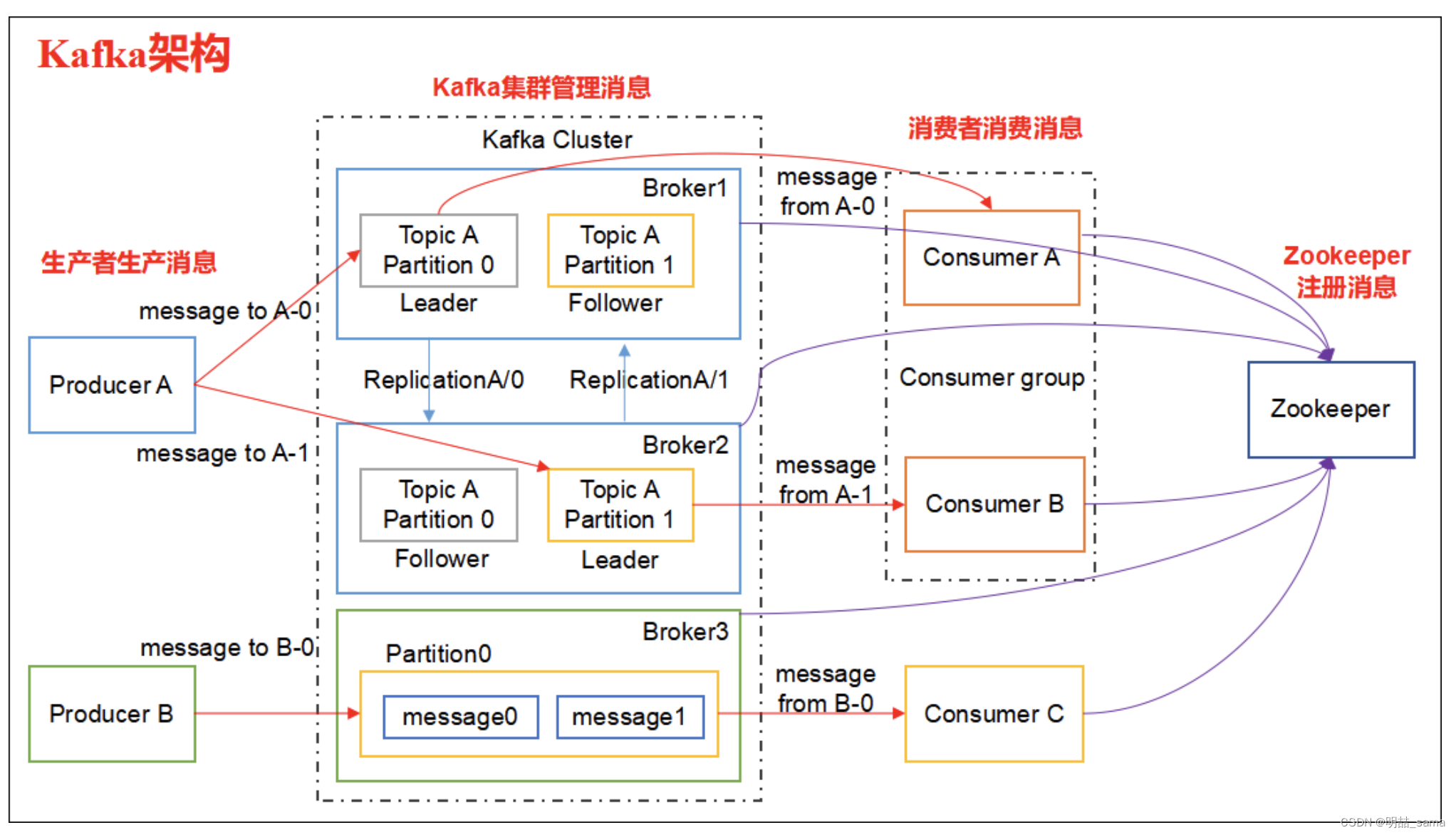
Kafka 面试,java实战贴
面试问题列表
Kafka的ISR机制是什么?如何保证数据一致性? 如何实现Kafka的Exactly-Once语义? Kafka的Rebalance机制可能引发什么问题?如何优化? Kafka的Topic分区数如何合理设置? 如何设计Kafka的高可用跨…

linux多线(进)程编程——(9)信号量(一)
前言
在找到了共享内存存在的问题后,进程君父子着手开始解决这些问题。他们发明了一个新的神通——信号量。
信号量
信号量是一个计数器,用于管理对共享资源的访问权限。主要特点包括: (1)是一个非负整数 ÿ…

PFLM: Privacy-preserving federated learning with membership proof证明阅读
系列文章目录 提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加 例如:第一章 Python 机器学习入门之pandas的使用 提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目…

图片转base64 - 加菲工具 - 在线转换
图片转base64 - 加菲工具
先进入“加菲工具” 网
打开 https://www.orcc.top, 选择 “图片转base64”功能
选择需要转换的图片 复制
点击“复制”按钮,即可复制转换好的base64编码数据,可以直接用于img标签。

opencv 对图片的操作
对图片的操作 1.图片镜像旋转(cv2.flip())2 图像的矫正 1.图片镜像旋转(cv2.flip())
图像的旋转是围绕一个特定点进行的,而图像的镜像旋转则是围绕坐标轴进行的。图像的镜像旋转分为水平翻转、垂直翻转、水平垂直翻转…
LabVIEW数据采集与传感系统
开发了一个基于LabVIEW的智能数据采集系统,该系统主要通过单片机与LabVIEW软件协同工作,实现对多通道低频传感器信号的有效采集、处理与显示。系统的设计旨在提高数据采集的准确性和效率,适用于各种需要高精度和低成本解决方案的工业场合。 项…
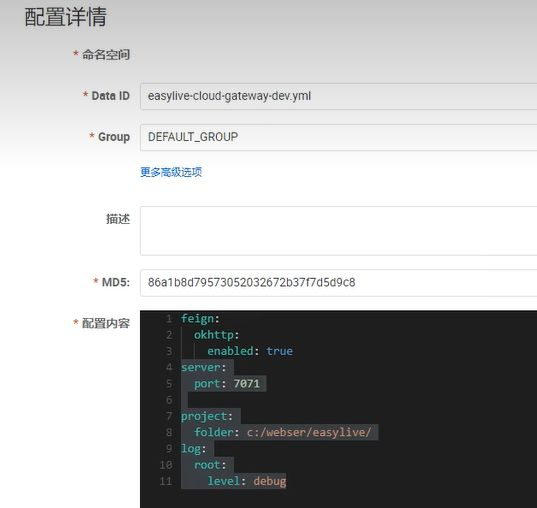
【Easylive】Gateway模块 bootstrap.yml 解析
【Easylive】项目常见问题解答(自用&持续更新中…) 汇总版
Gateway模块 bootstrap.yml 常规解析
该配置文件定义了 Spring Cloud Gateway 的核心配置,包括 环境配置、服务注册、动态路由规则 等。以下是逐项解析: 1. 基础配…
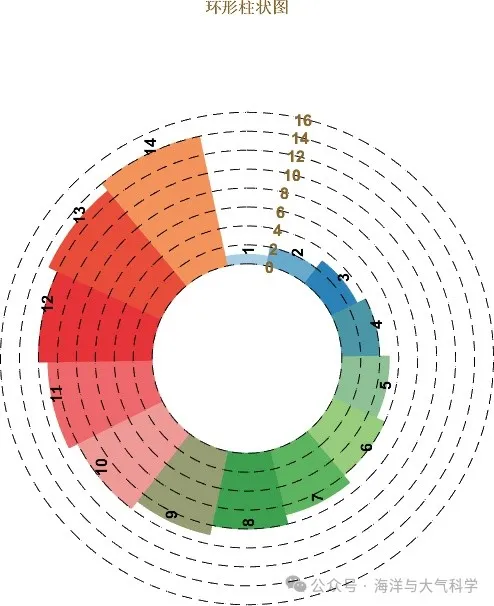
matlab 环形单层柱状图
matlab 环形单层柱状图
matlab 环形单层柱状图 matlab 环形单层柱状图
图片
图片 【图片来源粉丝】 我给他的思路是:直接使用风玫瑰图可以画出。
rose_bar 本次我的更新和这个有些不同!是环形柱状图,可调节细节多; 只需要函数…
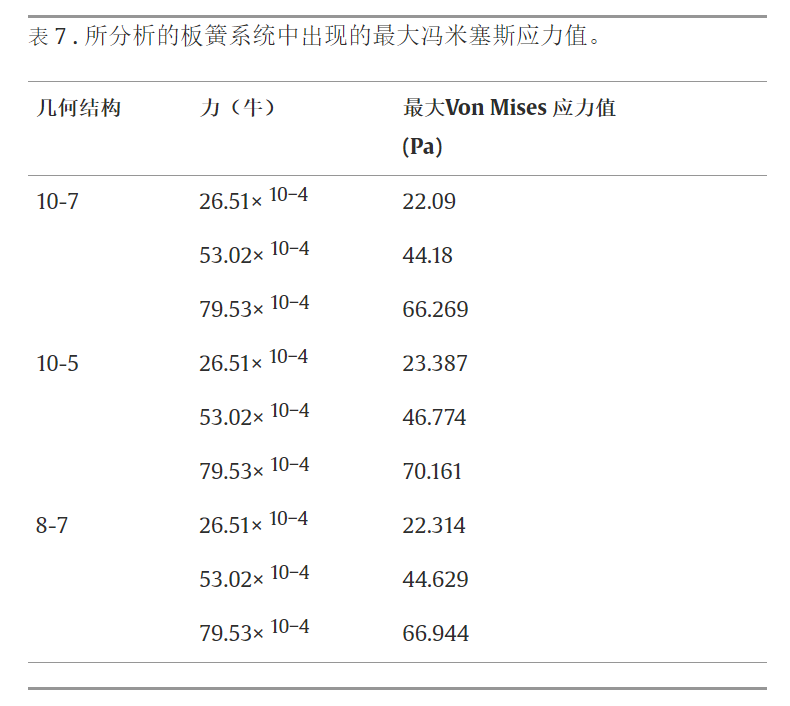
文献×汽车 | 基于 ANSYS 的多级抛物线板簧系统分析
板簧系统是用于减弱或吸收动态系统中发生的应力、应变、偏转和变形等破坏性因素的机械结构。板簧系统可能对外力产生不同的响应,具体取决于其几何结构和材料特性。板簧系统的计算机辅助分析对于高精度确定系统的变形特性和结构特性至关重要。 在这项工作中ÿ…
RHCE 练习二:通过 ssh 实现两台主机免密登录以及 nginx 服务通过多 IP 区分多网站
一、题目要求
1.配置ssh实现A,B主机互相免密登录
2.配置nginx服务,通过多ip区分多网站
二、实验
实验开始前需准备两台 linux 主机便于充当服务端以及客户端,两台主机 IP 如下图: 实验1:配置 ssh 实现 A࿰…
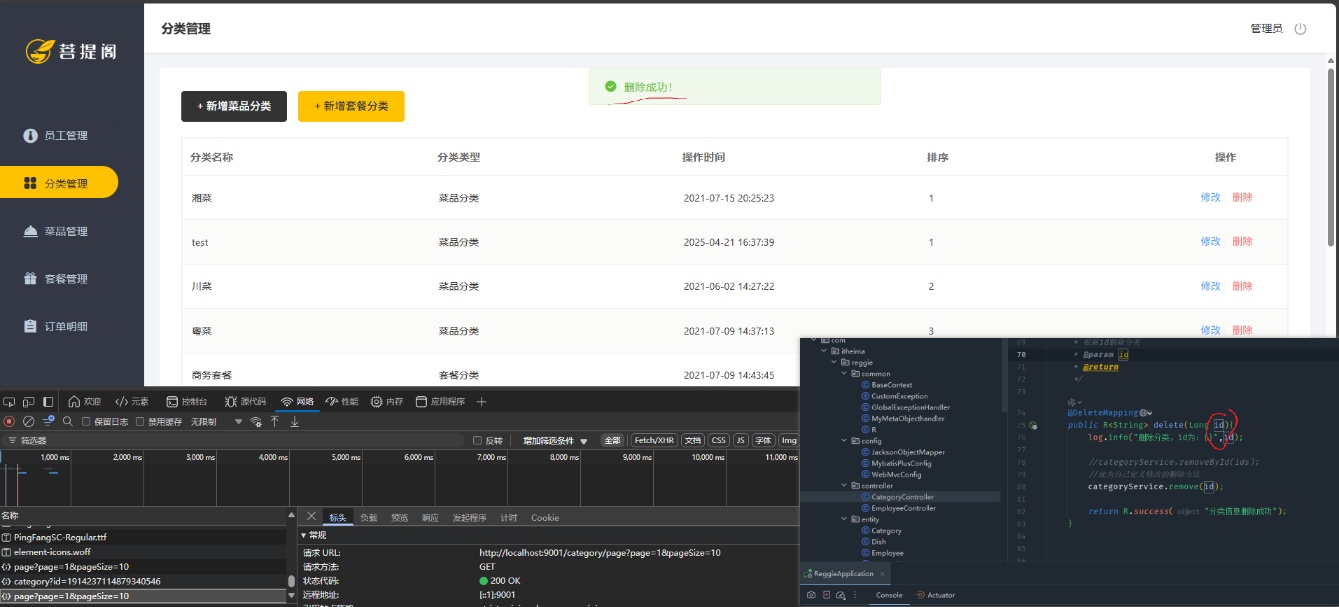
瑞吉外卖-分页功能开发中的两个问题
1.分页功能-前端页面展示显示500 原因:项目启动失败 解决:发现是Category实体类中,多定义了一个删除字段,但是我数据库里面没有is_deleted字段,导致查询数据库失败,所以会导致500错误。因为类是从网上其他帖…
工业物联网安全网关 —— 安全OTA升级签名验证
这里写目录标题 工业物联网安全网关 —— 安全OTA升级签名验证一、项目背景与简介1.1 背景介绍1.2 OTA升级的安全挑战1.3 项目目标二、理论基础与关键技术2.1 数字签名基础2.2 OTA升级签名验证原理2.3 关键技术与安全算法三、系统架构设计3.1 系统模块划分3.2 系统架构图(Merm…

探索 Flowable 后端表达式:简化流程自动化
什么是后端表达式?
在 Flowable 中,后端表达式是一种强大的工具,用于在流程、案例或决策表执行期间动态获取或设置变量。它还能实现自定义逻辑,或将复杂逻辑委托……
后端表达式在 Flowable 的后端运行,无法访问前端…

HDFS入门】HDFS安全与权限管理解析:从认证到加密的完整指南
目录
引言
1 认证与授权机制
1.1 Kerberos认证集成
1.2 HDFS ACL细粒度控制
2 数据加密保护
2.1 传输层加密(SSL/TLS)
2.2 静态数据加密
3 审计与监控体系
3.1 操作审计流程
3.2 安全监控指标
4 权限模型详解
4.1 用户/组权限模型
4.2 umask配置原理
5 安全最佳实…
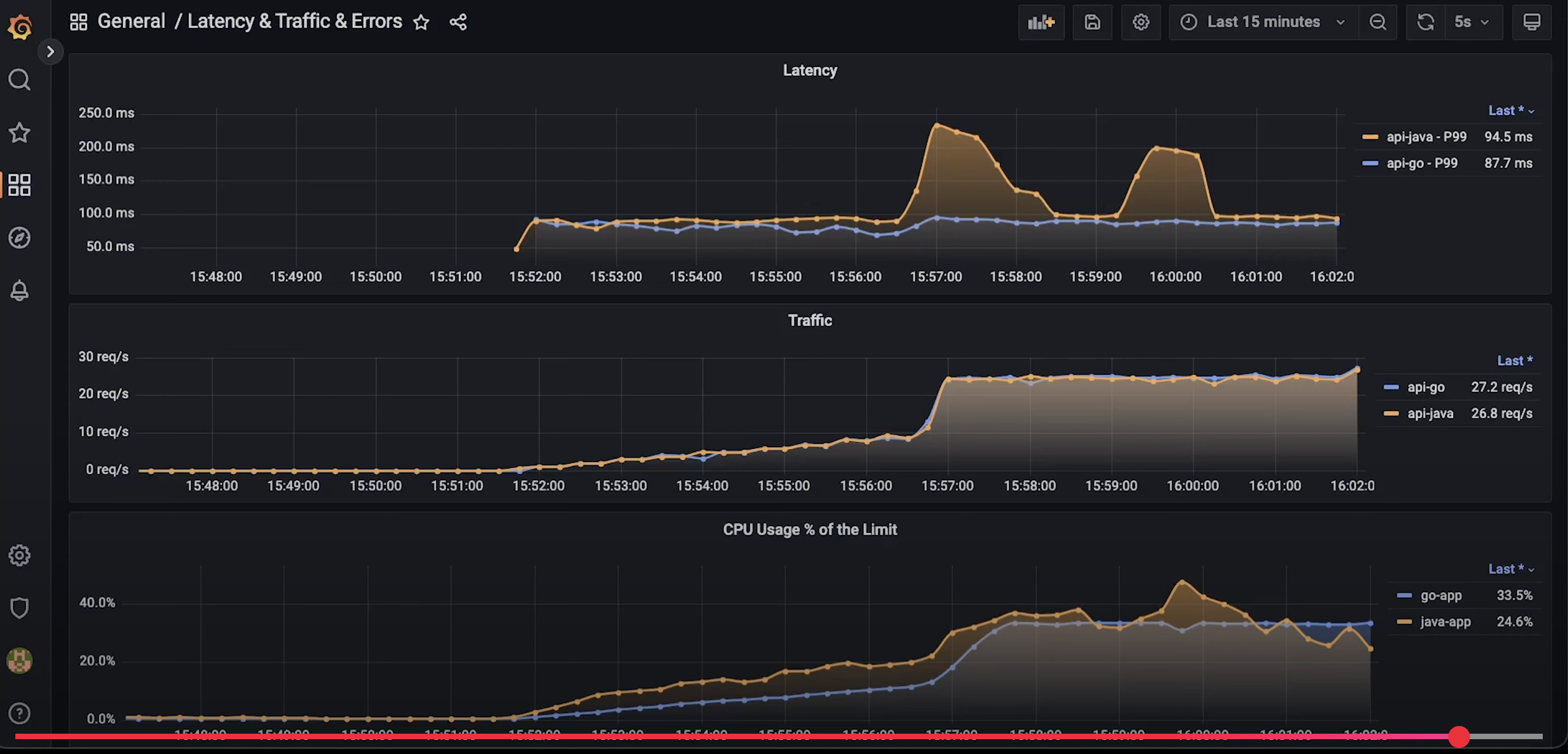
性能比拼: Go vs Java
本内容是对知名性能评测博主 Anton Putra Go (Golang) vs Java: Performance Benchmark 内容的翻译与整理, 有适当删减, 相关指标和结论以原作为准
在本视频中,我们将比较 Go 和 Java。
我们将基于 Golang 的 Fiber 框架和 Java 的 Spring Boot 创建几个简单的应用…