1、案例背景
一家互联网公司需要实时分析其服务器日志、应用日志和用户行为日志,以快速发现潜在问题并优化系统性能。
2、需求分析
- 目标:实时分析日志数据,快速发现问题并优化系统性能。
- 数据来源:
- 服务器日志:如 Nginx、Tomcat、Docker等日志。
- 应用日志:业务系统的运行日志。
- 用户行为日志:用户操作记录(如点击、浏览、下单等)。
- 输出:
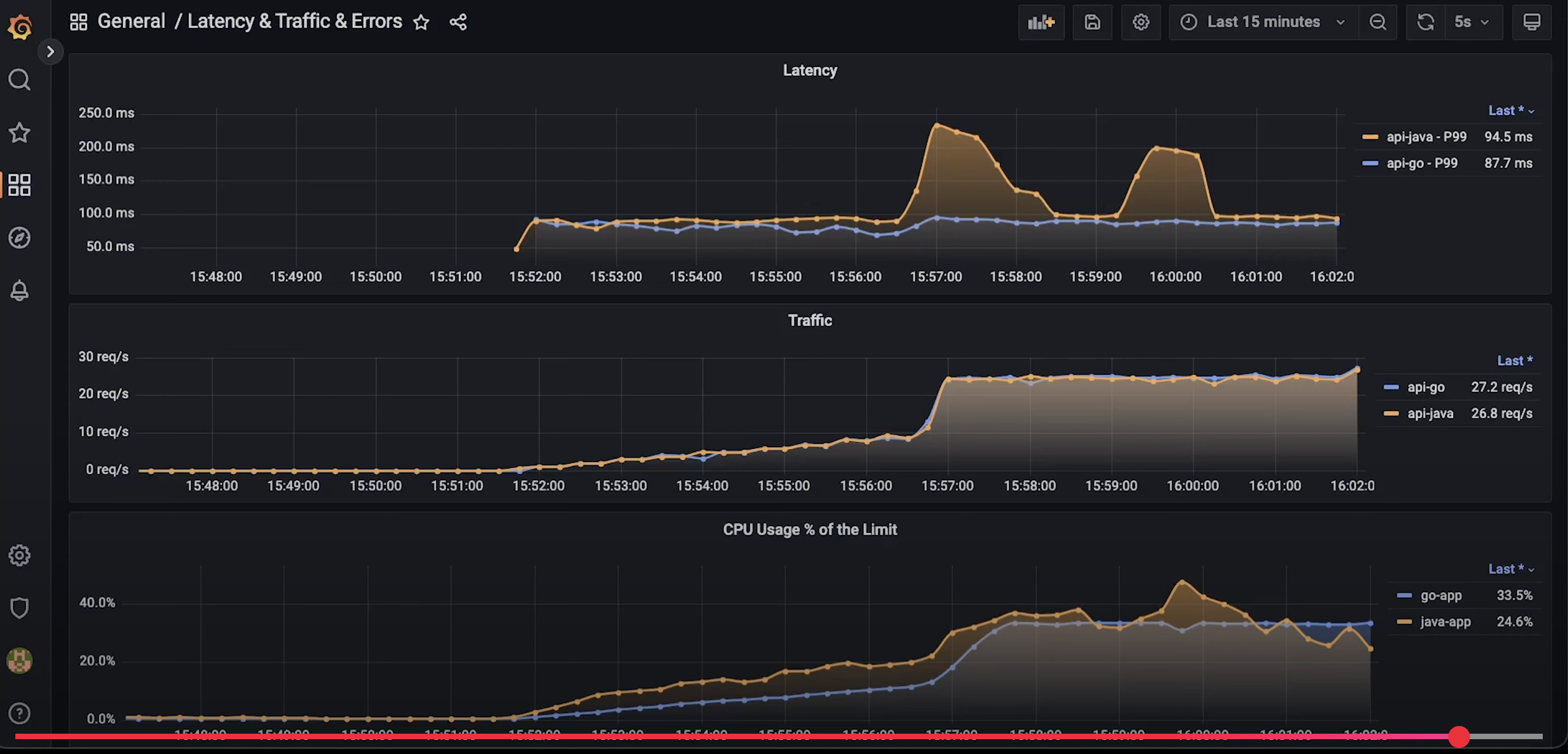
- 错误率、请求延迟、用户行为路径等关键指标。
- 实时监控仪表盘。
3、解决思路
- 日志采集:使用工具(如Filebeat或Fluentd)将日志数据写入Kafka。
- 数据存储与分析:Kafka中的数据被导入到ClickHouse,利用其高效的压缩和查询性能进行日志分析。
- 可视化:通过 Grafana 或 Redash 构建仪表盘,展示关键指标(如错误率、请求延迟等)。
4、技术选型
- 日志采集:Filebeat 或 Fluentd。
- 消息队列:Kafka(用于缓冲和传输日志数据)。
- 存储与分析:ClickHouse(高性能 OLAP 数据库)。
- 可视化:Grafana 或 Redash。
5、ClickHouse的作用
- 高效存储:日志数据量通常非常庞大,ClickHouse的列式存储和高压缩比显著降低了存储成本。
- 实时分析:支持毫秒级响应的复杂查询,适合对海量日志进行实时分析。
- 灵活扩展:支持分布式部署,能够处理PB级别的日志数据。
6、基本实现步骤
(1)、日志采集
1. 安装 Filebeat:
bash示例:
sudo apt-get install filebeat
2. 配置 Filebeat:
编辑 filebeat.yml 文件,指定日志文件路径和 Kafka 输出:
yaml示例:
filebeat.inputs:
- type: log
paths:
- /var/log/nginx/*.log
- /var/log/application/*.log
output.kafka:
hosts: ["kafka-broker:9092"]
topic: "logs"
解释:
Input为采集日志相关配置,如nginx的log日志文件,应用程序的log日志文件,output指定输出到kafka。
3. 启动 Filebeat:
bash示例:
sudo service filebeat start
(2)、消息队列(Kafka)
1. 安装 Kafka:
bash示例:
wget https://downloads.apache.org/kafka/3.0.0/kafka_2.13-3.0.0.tgz
tar -xzf kafka_2.13-3.0.0.tgz
cd kafka_2.13-3.0.0
2. 启动 Kafka:
bash示例:
bin/zookeeper-server-start.sh config/zookeeper.properties
bin/kafka-server-start.sh config/server.properties
(3)、数据消费与写入ClickHouse
1. 创建 ClickHouse 表:
sql示例:
CREATE TABLE logs (
timestamp DateTime,
level String,
message String,
source String
) ENGINE = MergeTree()
ORDER BY (timestamp);
(4)、可视化
1. 安装 Grafana:
bash示例:
sudo apt-get install grafana
sudo service grafana-server start
2. 配置 ClickHouse 数据源:
在 Grafana 中添加 ClickHouse 数据源,配置连接信息。
3. 构建仪表盘:
创建图表展示日志的关键指标,如错误率、请求延迟等。
7、Spring Boot代码示例
使用Spring Boot消费Kafka数据并写入 ClickHouse。
(1)、添加依赖
<dependencies>
<!-- Spring Boot Starter -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<!-- Kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<!-- ClickHouse JDBC -->
<dependency>
<groupId>com.clickhouse</groupId>
<artifactId>clickhouse-jdbc</artifactId>
<version>0.3.2</version>
</dependency>
<!-- Jackson for JSON Parsing -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
</dependencies>
(2)、配置 Kafka 和 ClickHouse
在 application.yml 中配置 Kafka 和 ClickHouse:
spring:
kafka:
bootstrap-servers: kafka-broker:9092
consumer:
group-id: clickhouse-group
auto-offset-reset: earliest
datasource:
url: jdbc:clickhouse://clickhouse-server:8123/default
driver-class-name: com.clickhouse.jdbc.ClickHouseDriver
username: default
password:
(3)、Kafka 消费者
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Service;
@Service
public class LogConsumer {
private final LogRepository logRepository;
public LogConsumer(LogRepository logRepository) {
this.logRepository = logRepository;
}
@KafkaListener(topics = "logs", groupId = "clickhouse-group")
public void consume(String message) {
// 解析日志消息
Log log = parseLog(message);
// 写入 ClickHouse
logRepository.save(log);
}
private Log parseLog(String message) {
// 假设日志是 JSON 格式
ObjectMapper objectMapper = new ObjectMapper();
try {
return objectMapper.readValue(message, Log.class);
} catch (Exception e) {
throw new RuntimeException("Failed to parse log message", e);
}
}
}
(4)、ClickHouse 数据访问层
创建Repository类。
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Repository;
@Repository
public class LogRepository {
private final JdbcTemplate jdbcTemplate;
@Autowired
public LogRepository(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
public void save(Log log) {
String sql = "INSERT INTO logs (timestamp, level, message, source) VALUES (?, ?, ?, ?)";
jdbcTemplate.update(sql, log.getTimestamp(), log.getLevel(), log.getMessage(), log.getSource());
}
}
(5)、日志实体类
import java.time.LocalDateTime;
public class Log {
private LocalDateTime timestamp;
private String level;
private String message;
private String source;
// Getters and Setters
}
(6)、 Service 层(LogService.java)
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.Map;
@Service
public class LogService {
@Autowired
private JdbcTemplate jdbcTemplate;
// 查询最近5分钟的错误率
public List<Map<String, Object>> getErrorRate() {
String sql = "SELECT program, error_count * 100.0 / total_requests AS error_percent " +
"FROM log_errors_mv " +
"WHERE minute >= now() - interval 5 minute " +
"GROUP BY program";
return jdbcTemplate.queryForList(sql);
}
// 查询指定时间段的响应时间分布
public List<Map<String, Object>> getResponseTimeStats(String startTime, String endTime) {
String sql = "SELECT percentileState(upstream_response_time, 0.95) AS p95 " +
"FROM log_main " +
"WHERE timestamp BETWEEN ? AND ?";
return jdbcTemplate.queryForList(sql, startTime, endTime);
}
}
(7)、Controller 层(LogController.java)
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
import java.util.Map;
@RestController
public class LogController {
@Autowired
private LogService logService;
@GetMapping("/error-rate")
public List<Map<String, Object>> getErrorRate() {
return logService.getErrorRate();
}
@GetMapping("/response-time")
public List<Map<String, Object>> getResponseTime(
@RequestParam String startTime,
@RequestParam String endTime
) {
return logService.getResponseTimeStats(startTime, endTime);
}
}
8、关键优化与注意事项
以上仅为简单的示例,实际生产中每一步都会比较复杂,需要结合实际需求在做详细的数据库设计以及接口设计等。这里我们主要是理解做的思路。
(1)、表设计优化
- 分区策略:按 toYYYYMMDD(timestamp) 分区,便于按天清理旧数据。
- 物化视图:预聚合高频查询指标(如错误率、响应时间),避免重复计算。
- 索引与排序:在 program 和 timestamp 字段上建立索引,加速过滤查询。
(2)、ClickHouse 配置优化
- 资源分配:增大 max_threads 和 max_memory_usage,提升并发处理能力。
- 日志压缩:使用 gzip 或 lz4 压缩日志数据,减少存储开销。
(3)、Spring Boot 性能调优
- 连接池配置:使用 HikariCP 管理数据库连接(通过 spring.datasource.hikari.* 配置)。
- 缓存机制:对高频查询结果使用 Redis 缓存(如错误率统计)。
逆风成长,Dare To Be!!!

![STM32单片机入门学习——第46节: [14-1] WDG看门狗](https://i-blog.csdnimg.cn/direct/26edd52d9c6d44abbed01355e6a26031.png)