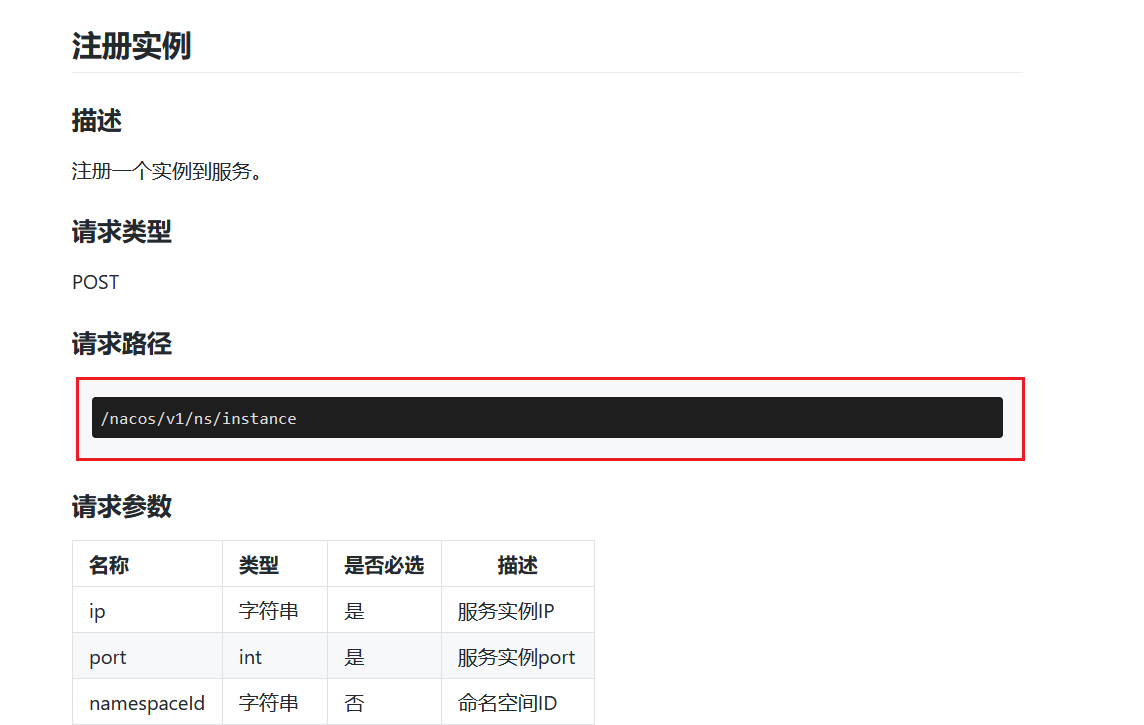
目录
一、计数排序
二、桶排序
三、基数排序
一、计数排序
算法步骤:
-
找出待排序数组
arr中的最小值和最大值(分别用 min 和 max 表示)。 -
创建一个长度为 max - min + 1、元素初始值全为 0 的计数器数组
count。 -
扫描一遍原始数组,将
arr[i] - min作为下标,并将该下标的计数器增 1。 -
扫描一遍计数器数组,按顺序把值收集起来。
void CountSort(int* arr, int n)
{
// 找出待排序数组中的最小值和最大值
int min = arr[0];
int max = arr[0];
for (int i = 1; i < n; ++i)
{
if (arr[i] < min)
{
min = arr[i];
}
if (arr[i] > max)
{
max = arr[i];
}
}
// 创建一个长度为 max - min + 1,元素初始值全为 0 的计数器数组
int* count = (int*)calloc(max - min + 1, sizeof(int));
if (NULL == count)
{
perror("malloc failed!");
return;
}
// 扫描原始数组
for (int i = 0; i < n; ++i)
{
count[arr[i] - min]++;
}
// 扫描计数器数组
int k = 0;
for (int i = 0; i < max - min + 1; ++i)
{
for (int j = 0; j < count[i]; ++j)
{
arr[k++] = i + min;
}
}
}计数排序适合范围集中,且范围不大的整型数组。
二、桶排序
桶排序(Bucket Sort)或所谓的箱排序,其工作原理是:假设输入数据服从均匀分布,将数据分到有限数量的桶里,然后对每个桶分别排序,最后把桶的数据合并。
桶排序的时间复杂度,取决于各个桶之间数据进行排序的时间复杂度,因为其他部分的时间复杂度都为 O(n)。很显然,桶划分地越小,各个桶之间的数据越少,排序所用的时间也会越少,但相应的空间消耗会增加。
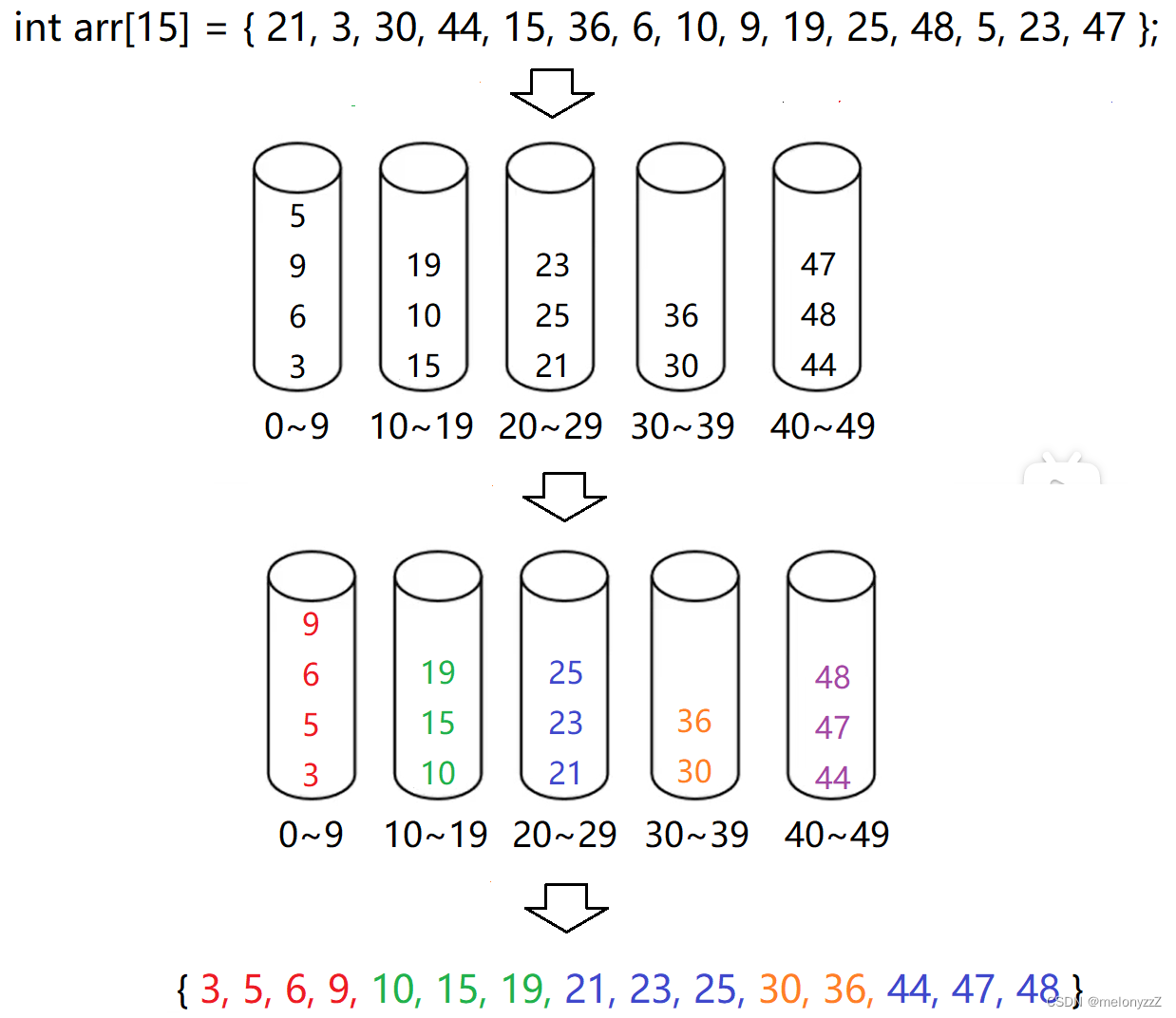
void BucketSort(int* arr, int n)
{
int bucket[5][5] = { 0 }; // 分配 5 个桶,每个桶最多放 5 个元素
int bucketCount[5] = { 0 }; // 这 5 个桶的计数器的计数器
// 将数据放入桶中
for (int i = 0; i < n; ++i)
{
bucket[arr[i] / 10][bucketCount[arr[i] / 10]++] = arr[i];
}
// 对每个桶进行排序
for (int i = 0; i < 5; ++i)
{
QuickSort(bucket[i], bucketCount[i]);
}
// 把每个桶中的数据填充到数组中
int k = 0;
for (int i = 0; i < 5; ++i)
{
for (int j = 0; j < bucketCount[i]; ++j)
{
arr[k++] = bucket[i][j];
}
}
}
在现实世界中,大部分的数据分布是均匀的,或者在设计的时候可以让它均匀分布,或者说可以转换为均匀地分布。当数据均匀地分布,桶排序的效率就能发挥出来。
理解桶思想可以设计出高效的算法。

三、基数排序
基数排序(Radix Sort)是一种借助多关键排序的思想对单逻辑关键字进行排序的方法。
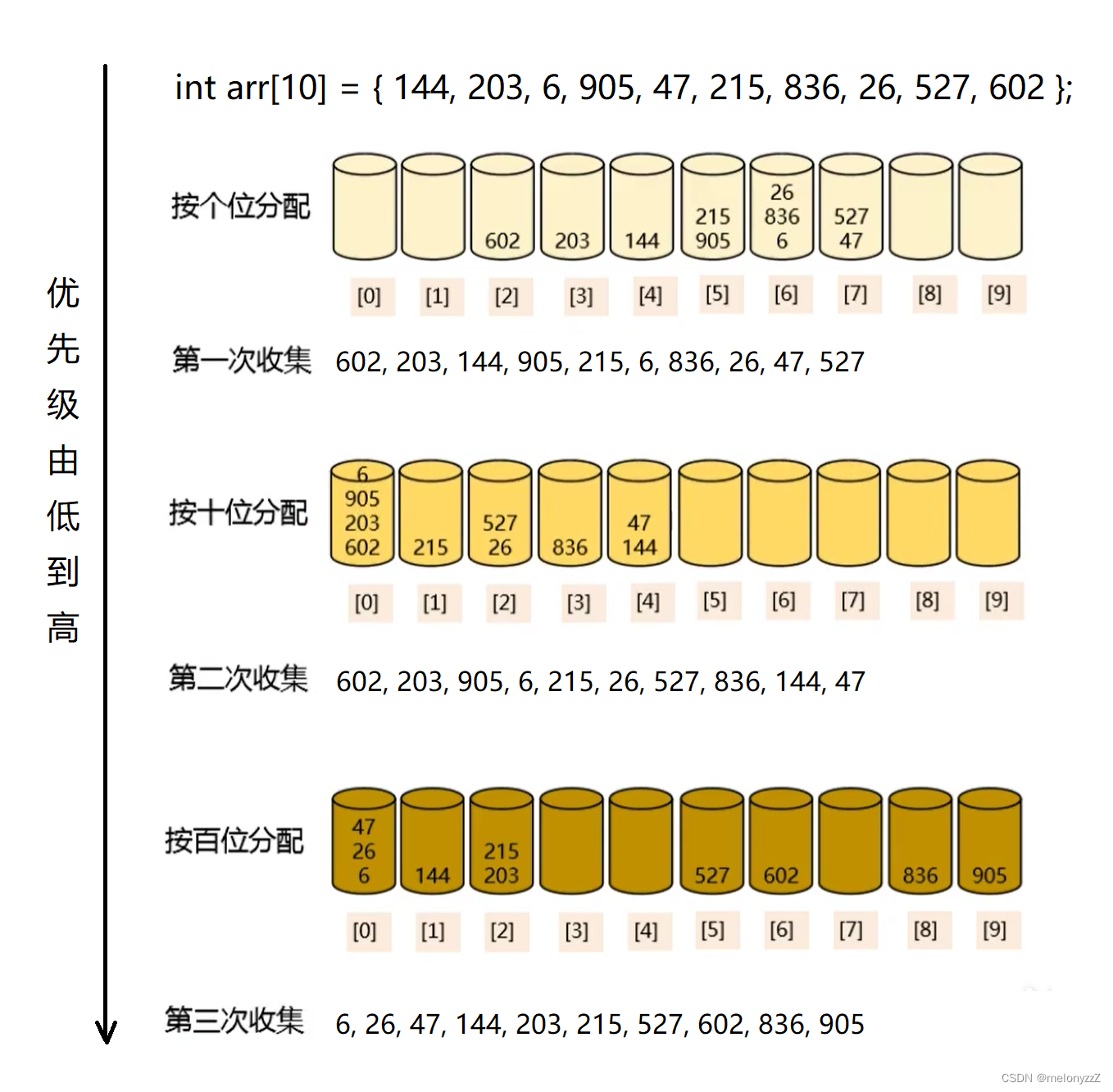
void DistrAndCollect(int* arr, int n, int exp)
{
Queue q[10];
for (int i = 0; i < 10; ++i)
{
QueueInit(&q[i]);
}
// 分配
for (int i = 0; i < n; ++i)
{
int j = (arr[i] / exp) % 10;
QueuePush(&q[j], arr[i]); // 将 arr[i] 分配到下标为 j 的队列(桶)中
}
// 收集
int j = 0;
for (int i = 0; i < 10; ++i)
{
while (!QueueEmpty(&q[i]))
{
arr[j++] = QueueFront(&q[i]);
QueuePop(&q[i]);
}
}
}
void RadixSort(int* arr, int n)
{
// 找出待排序数组中的最大值
int max = arr[0];
for (int i = 1; i < n; ++i)
{
if (arr[i] > max)
{
max = arr[i];
}
}
// 分配和收集
for (int exp = 1; max / exp > 0; exp *= 10)
{
// exp 表示排序指数,
// 当 exp 为 1 时,表示按个位分配,
// 当 exp 为 10 时,表示按十位分配,依次类推。
DistrAndCollect(arr, n, exp);
}
} 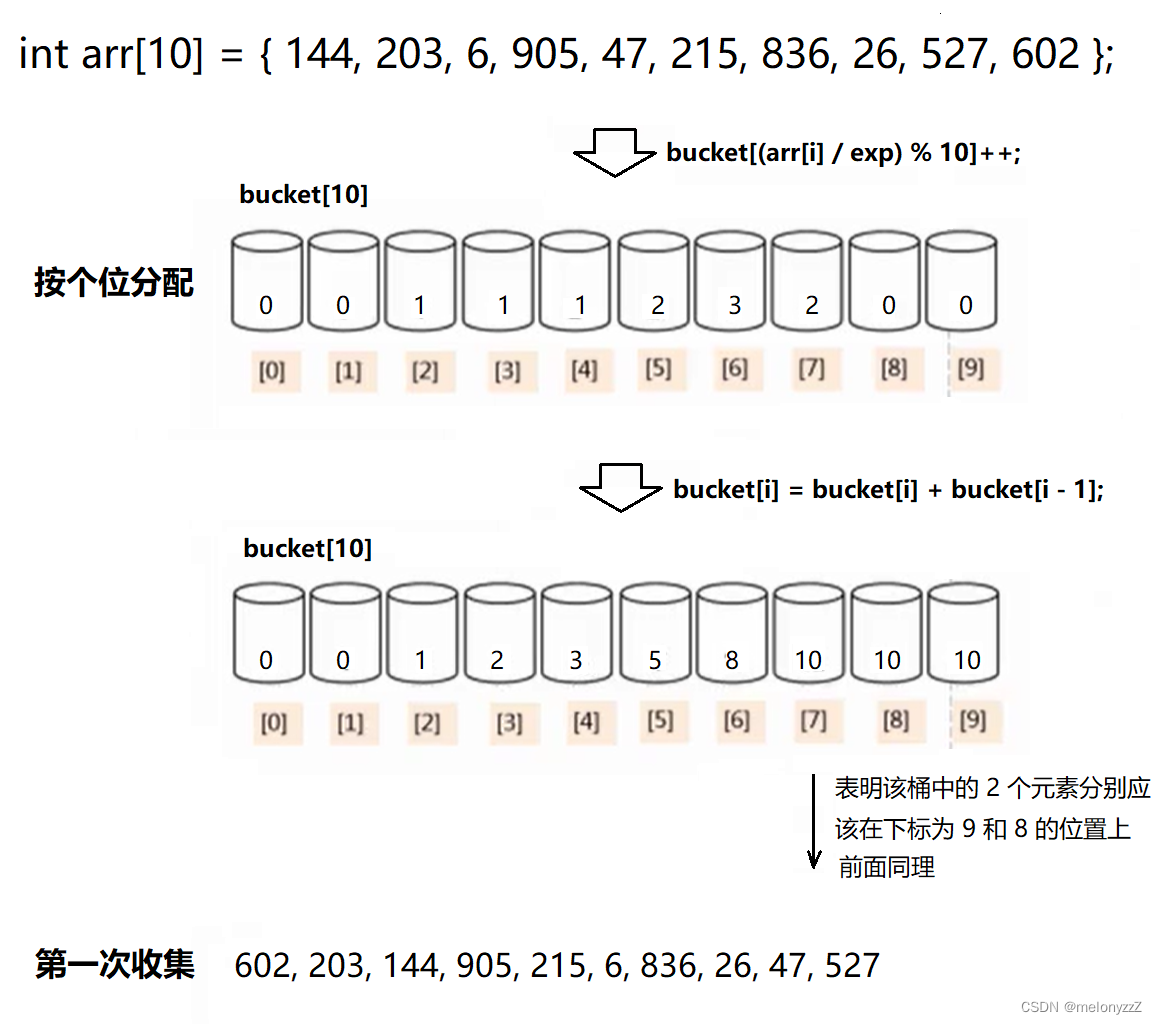
void DistrAndCollect(int* arr, int n, int exp)
{
int bucket[10] = { 0 }; // 初始化 10 个桶
int* result = (int*)malloc(sizeof(int) * n);
if (NULL == result)
{
perror("malloc failed!");
return;
}
// 分配
for (int i = 0; i < n; ++i)
{
bucket[(arr[i] / exp) % 10]++;
}
for (int i = 1; i < 10; ++i)
{
bucket[i] = bucket[i] + bucket[i - 1];
}
// 收集
for (int i = n - 1; i >= 0; --i) // 从后向前遍历数组 arr
{
int j = (arr[i] / exp) % 10;
result[bucket[j] - 1] = arr[i];
bucket[j]--;
}
memmove(arr, result, sizeof(int) * n);
}
void RadixSort(int* arr, int n)
{
// 找出待排序数组中的最大值
int max = arr[0];
for (int i = 1; i < n; ++i)
{
if (arr[i] > max)
{
max = arr[i];
}
}
// 分配和收集
for (int exp = 1; max / exp > 0; exp *= 10)
{
// exp 表示分配指数,
// 当 exp 为 1 时,表示按个位分配,
// 当 exp 为 10 时,表示按十位分配,依次类推。
DistrAndCollect(arr, n, exp);
}
}基数排序的其他应用,例如超女选秀活动,如果要把超女的出生日期排序:
年:1990 ~ 2005(15 个桶)
月:1 ~ 12(12 个桶)
日:1 ~ 31(31 个桶)
创作不易,可以点点赞,然后关注一下博主~