摘要:安全帽检测系统用于自动化监测安全帽佩戴情况,在需要佩戴安全帽的场合自动安全提醒,实现图片、视频和摄像头等多种形式监测。在介绍算法原理的同时,给出Python的实现代码、训练数据集,以及PyQt的UI界面。安全帽检测系统主要用于自动化监测安全帽佩戴情况,检测佩戴安全帽的数目、位置、预测置信度等;可采取图片、视频和摄像头等多种形式监测佩戴情况,并实时显示标记和结果;博文提供了完整的Python代码和使用教程,适合新入门的朋友参考,完整代码资源文件请转至文末的下载链接。本博文目录如下:
文章目录
- 前言
- 1. 效果演示
- 2. 检测模型与训练
- 3. 安全帽检测识别
- 下载链接
- 结束语
➷点击跳转至文末所有涉及的完整代码文件下载页☇
基于深度学习的安全帽检测系统演示与介绍
前言
近年来,随着计算机视觉的飞速发展,越来越多的目标检测算法被应用到生活中,对人体安全的研究尤为有价值。建筑业是劳动密集型行业,工作环境复杂,安全事故频发。据《国家统计年鉴》统计,我国建筑业每年发生的事故数量高达600起,每年死亡人数超过700人。坠落的物体是最致命的,研究表明,所有建筑工人因脑外伤而死亡的人数中有24%是由高空物体坠落造成的。由于它直接威胁到工人的头部,而头部是最重要的身体部位,因此头盔佩戴检测在现实生活场景中具有重要意义。
计算机视觉的快速发展应用在各个方面,具有广阔的前景,尤其是在安全工程方面。在建筑工地,头盔是保护工人生命的重要工具,而实际上,由于没有戴头盔,事故时有发生。为了解决这个问题,基于深度学习的安全帽检测系统以最及时的方式进行告警,同时最大限度降低误报和漏报现象,极大的节约了生产成本,提高了工作效率。
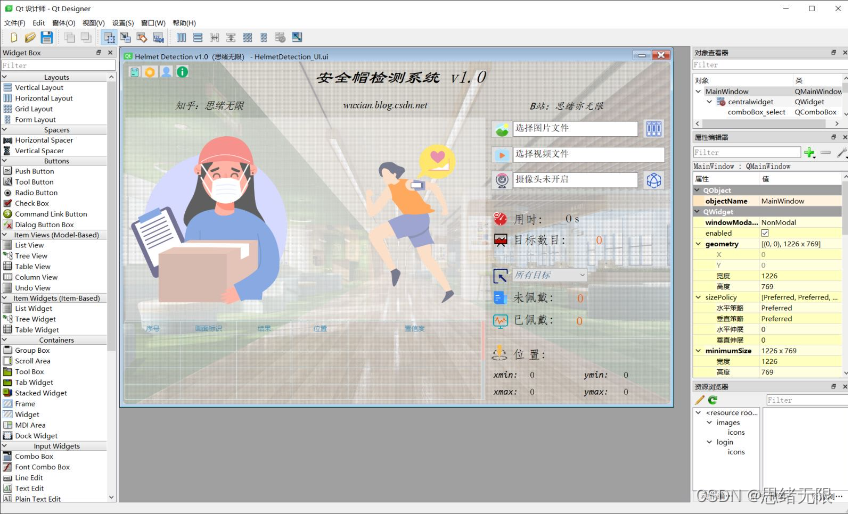
这里给出博主设计的软件界面,同款的简约风,功能也可以满足图片、视频和摄像头的识别检测,希望大家可以喜欢,初始界面如下图:

检测安全帽时的界面截图(点击图片可放大)如下图,可识别画面中存在的多个目标,也可开启摄像头或视频检测:

详细的功能演示效果参见博主的B站视频或下一节的动图演示,觉得不错的朋友敬请点赞、关注加收藏!系统UI界面的设计工作量较大,界面美化更需仔细雕琢,大家有任何建议或意见和可在下方评论交流。
1. 效果演示
首先我们还是通过动图看一下识别安全帽的效果,系统主要实现的功能是对图片、视频和摄像头画面中的安全帽属性进行识别,识别的结果可视化显示在界面和图像中,另外提供多个安全帽的显示选择功能,演示效果如下。
(一)用户注册登录界面
这里设计了一个登录界面,可以注册账号和密码,然后进行登录。界面还是参考了当前流行的UI设计,左侧是一个头盔的LOGO图,右侧输入账号、密码、验证码等等。

(二)安全帽图片识别
系统允许选择图片文件进行识别,点击图片选择按钮图标选择图片后,显示所有安全帽识别的结果,可通过下拉选框查看单个安全帽检测的结果。本功能的界面展示如下图所示:

(三)安全帽视频识别效果展示
很多时候我们需要识别一段视频,这里设计了视频选择功能。点击视频按钮可选择待检测的视频,系统会自动解析视频逐帧识别安全帽佩戴情况,并将结果记录在右下角表格中,效果如下图所示:

(四)摄像头检测效果展示
在真实场景中,我们往往利用设备摄像头获取实时画面,同时需要对画面中是否佩戴安全帽进行识别,因此本文考虑到此项功能。如下图所示,点击摄像头按钮后系统进入准备状态,系统显示实时画面并开始检测画面中的安全帽,识别结果展示如下图:

2. 检测模型与训练
管理人员可以直接了解工人是否正确、安全佩戴头盔的信息,及时采取措施,避免不必要的损失。本文的系统采用了基于YOLOV5的安全帽检测与识别的方法,头盔上的测试结果达到了95.2%,基于此的预警功能可以帮助减少工地事故的危害。本文借助YoloV5算法,实现安全帽检测识别,这里首先对实现原理进行介绍。
(一)原理简介
前文已经介绍过YoloV5中的Backbone结构,Backbone可以被称作YoloV5的主干特征提取网络,根据它的结构以及之前Yolo主干的叫法,我一般叫它CSPDarknet,输入的图片首先会在CSPDarknet里面进行特征提取,提取到的特征可以被称作特征层,是输入图片的特征集合。在主干部分,我们获取了三个特征层进行下一步网络的构建,这三个特征层我称它为有效特征层。

FPN可以被称作YoloV5的加强特征提取网络,在主干部分获得的三个有效特征层会在这一部分进行特征融合,特征融合的目的是结合不同尺度的特征信息。在FPN部分,已经获得的有效特征层被用于继续提取特征。在YoloV5里依然使用到了Panet的结构,我们不仅会对特征进行上采样实现特征融合,还会对特征再次进行下采样实现特征融合。

Yolo Head是YOLOv5的分类器与回归器,通过CSPDarknet和FPN,我们已经可以获得三个加强过的有效特征层。每一个特征层都有宽、高和通道数,此时我们可以将特征图看作一个又一个特征点的集合,每一个特征点都有通道数个特征。Yolo Head实际上所做的工作就是对特征点进行判断,判断特征点是否有物体与其对应。与以前版本的Yolo一样,YoloV5所用的解耦头是一起的,也就是分类和回归在一个1X1卷积里实现。
# YOLOv5 neck and head
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, BottleneckCSP, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, BottleneckCSP, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, BottleneckCSP, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, BottleneckCSP, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
利用以上网络进行训练,所有层中的权重均采用标准偏差为0.01,均值为0的高斯随机值初始化。训练时不使用预训练模型,不使用基准可用的图像和标签之外的任何数据,网络从头开始进行训练。训练的目标值用与真实类别相对应的稀疏二进制向量表示。
(二)安全帽数据集与训练过程
这里我们使用的安全帽识别数据集,包含训练集910张图片,验证集304张图片,共计1214张图片。部分数据集图片及其标注信息如下图所示。

每张图像均提供了图像类标记信息,图像中安全帽的bounding box,安全帽的关键part信息,以及安全帽的属性信息,数据集并解压后得到如下的图片。

在python环境配置完成后,我们运行train.py进行训练。YOLOv5训练时主要包含三个方面的损失:矩形框损失(box_loss)、置信度损失(obj_loss)和分类损失(cls_loss),下图为博主训练安全帽识别的模型训练曲线图。

我们通过设定不同的置信度的阈值,可以得到在模型在不同的阈值下所计算出的p值和r值,一般情况下,p值和r值是负相关的,绘制出来可以得到如下图所示的曲线,其中曲线的面积我们称AP,目标检测模型中每种目标可计算出一个AP值,对所有的AP值求平均则可以得到模型的mAP值。

以PR-curve为例,可以看到我们的模型在验证集上的均值平均准确率为0.910。
3. 安全帽检测识别
在训练完成后得到最佳模型,接下来我们将帧图像输入到这个网络进行预测,从而得到预测结果,预测方法(predict.py)部分的代码如下所示:
def predict(img):
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float()
img /= 255.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
t1 = time_synchronized()
pred = model(img, augment=False)[0]
pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes,
agnostic=opt.agnostic_nms)
t2 = time_synchronized()
InferNms = round((t2 - t1), 2)
return pred, InferNms
得到预测结果我们便可以将帧图像中的安全帽框出,然后在图片上用opencv绘图操作,输出安全帽的类别及安全帽的预测分数。以下是读取一个安全帽图片并进行检测的脚本,首先将图片数据进行预处理后送predict进行检测,然后计算标记框的位置并在图中标注出来。
if __name__ == '__main__':
# video_path = 0
video_path = "UI_rec/test_/test.mp4"
# 初始化视频流
vs = cv2.VideoCapture(video_path)
(W, H) = (None, None)
frameIndex = 0 # 视频帧数
try:
prop = cv2.CAP_PROP_FRAME_COUNT
total = int(vs.get(prop))
# print("[INFO] 视频总帧数:{}".format(total))
# 若读取失败,报错退出
except:
print("[INFO] could not determine # of frames in video")
print("[INFO] no approx. completion time can be provided")
total = -1
fourcc = cv2.VideoWriter_fourcc(*'XVID')
ret, frame = vs.read()
vw = frame.shape[1]
vh = frame.shape[0]
print("[INFO] 视频尺寸:{} * {}".format(vw, vh))
output_video = cv2.VideoWriter("./results.avi", fourcc, 20.0, (vw, vh)) # 处理后的视频对象
# 遍历视频帧进行检测
while True:
# 从视频文件中逐帧读取画面
(grabbed, image) = vs.read()
# 若grabbed为空,表示视频到达最后一帧,退出
if not grabbed:
print("[INFO] 运行结束...")
output_video.release()
vs.release()
exit()
# 获取画面长宽
if W is None or H is None:
(H, W) = image.shape[:2]
image = cv2.resize(image, (850, 500))
img0 = image.copy()
img = letterbox(img0, new_shape=imgsz)[0]
img = np.stack(img, 0)
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
img = np.ascontiguousarray(img)
pred, useTime = predict(img)
det = pred[0]
p, s, im0 = None, '', img0
if det is not None and len(det): # 如果有检测信息则进入
det[:, :4] = scale_coords(img.shape[1:], det[:, :4], im0.shape).round() # 把图像缩放至im0的尺寸
number_i = 0 # 类别预编号
detInfo = []
for *xyxy, conf, cls in reversed(det): # 遍历检测信息
c1, c2 = (int(xyxy[0]), int(xyxy[1])), (int(xyxy[2]), int(xyxy[3]))
# 将检测信息添加到字典中
detInfo.append([names[int(cls)], [c1[0], c1[1], c2[0], c2[1]], '%.2f' % conf])
number_i += 1 # 编号数+1
label = '%s %.2f' % (names[int(cls)], conf)
# 画出检测到的目标物
plot_one_box(image, xyxy, label=label, color=colors[int(cls)])
# 实时显示检测画面
cv2.imshow('Stream', image)
image = cv2.resize(image, (vw, vh))
output_video.write(image) # 保存标记后的视频
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# print("FPS:{}".format(int(0.6/(end-start))))
frameIndex += 1
执行得到的结果如下图所示,图中安全帽的种类和置信度值都标注出来了,预测速度较快。基于此模型我们可以将其设计成一个带有界面的系统,在界面上选择图片、视频或摄像头然后调用模型进行检测。

博主对整个系统进行了详细测试,最终开发出一版流畅得到清新界面,就是博文演示部分的展示,完整的UI界面、测试图片视频、代码文件,以及Python离线依赖包(方便安装运行,也可自行配置环境),均已打包上传,感兴趣的朋友可以通过下载链接获取。
下载链接
若您想获得博文中涉及的实现完整全部程序文件(包括测试图片、视频,py, UI文件等,如下图),这里已打包上传至博主的面包多平台,见可参考博客与视频,已将所有涉及的文件同时打包到里面,点击即可运行,完整文件截图如下:

在文件夹下的资源显示如下,下面的链接中也给出了Python的离线依赖包,读者可在正确安装Anaconda和Pycharm软件后,复制离线依赖包至项目目录下进行安装,离线依赖的使用详细演示也可见本人B站视频:win11从头安装软件和配置环境运行深度学习项目、Win10中使用pycharm和anaconda进行python环境配置教程。

注意:该代码采用Pycharm+Python3.8开发,经过测试能成功运行,运行界面的主程序为runMain.py和LoginUI.py,测试图片脚本可运行testPicture.py,测试视频脚本可运行testVideo.py。为确保程序顺利运行,请按照requirements.txt配置Python依赖包的版本。Python版本:3.8,请勿使用其他版本,详见requirements.txt文件;
完整资源中包含数据集及训练代码,环境配置与界面中文字、图片、logo等的修改方法请见视频,项目完整文件下载请见参考博客文章里面,或参考视频的简介处给出:➷➷➷
参考博客文章:https://zhuanlan.zhihu.com/p/615605821
参考视频演示:https://www.bilibili.com/video/BV1fb411f7u1/
离线依赖库下载链接:https://pan.baidu.com/s/1hW9z9ofV1FRSezTSj59JSg?pwd=oy4n (提取码:oy4n )
界面中文字、图标和背景图修改方法:
在Qt Designer中可以彻底修改界面的各个控件及设置,然后将ui文件转换为py文件即可调用和显示界面。如果只需要修改界面中的文字、图标和背景图的,可以直接在ConfigUI.config文件中修改,步骤如下:
(1)打开UI_rec/tools/ConfigUI.config文件,若乱码请选择GBK编码打开。
(2)如需修改界面文字,只要选中要改的字符替换成自己的就好。
(3)如需修改背景、图标等,只需修改图片的路径。例如,原文件中的背景图设置如下:
mainWindow = :/images/icons/back-image.png
可修改为自己的名为background2.png图片(位置在UI_rec/icons/文件夹中),可将该项设置如下即可修改背景图:
mainWindow = ./icons/background2.png
结束语
由于博主能力有限,博文中提及的方法即使经过试验,也难免会有疏漏之处。希望您能热心指出其中的错误,以便下次修改时能以一个更完美更严谨的样子,呈现在大家面前。同时如果有更好的实现方法也请您不吝赐教。