文章目录
- 基本概念
- 两阶段目标检测算法
- R-CNN
- Fast R-CNN
- Faster R-CNN
- FPN
- Mask R-CNN
- 一阶段目标检测算法
- SSD
- YOLOv1
- YOLOv2
- YOLOv3
- 目标检测的常用数据集
- 目标检测的标注工具
基本概念
目标检测是计算机视觉中的一个重要问题,它的目的是从图像或视频序列中识别出特定的目标,并将其从背景中分离出来。目标检测的任务包括:
- 检测出图像或视频序列中的目标,例如人、车辆、动物等。
- 对目标进行分类,例如将人分为人类、车辆、动物等。
- 确定目标的位置和大小,例如在图像中标记出目标的位置和大小。
基于深度学习的目标检测算法主要分为两类:
- 两阶段目标检测算法
先进行区域生成(region proposal,RP)(一个有可能包含待检物体的预选框),再通过卷积神经网络进行样本分类。
任务:特征提取—>生成RP—>分类/定位回归。
常见的两阶段目标检测算法有:R-CNN、SPP-Net 、Fast R-CNN、Fast er R-CNN和R-FCN等。 - 一阶段目标检测算法
不用RP,直接在网络中提取特征来预测物体分类和位置。
任务:特征提取—>分类/定位回归。
常见的一阶段目标检测算法有:SSD、YOLOv1、YOLOv2、YOLOv3和RetinaNet 等
两阶段目标检测算法
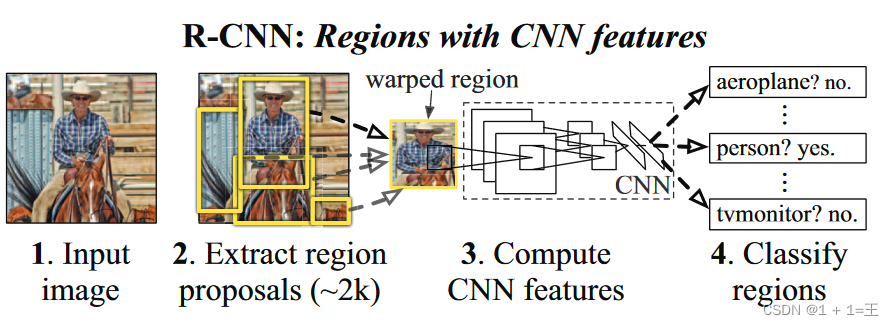
R-CNN
原文链接:Rich feature hierarchies for accurate object detection and semantic segmentation:https://ieeexplore.ieee.org/document/6909475

RCNN主要存在两个创新点:
- 使用CNN(ConvNet )对 region proposals 计算特征向量。从经验驱动特征到数据驱动特征(CNN),提高特征对样本的表示能力。
- 采用大样本下有监督预训练和小样本微调的方法解决小样本难以训练甚至过拟合等问题。
原文中RCNN只要有四个步骤:
- 预训练模型。选择一个预训练神经网络(如AlexNet 、VGG)。
- 重新训练全连接层。使用需要检测的目标重新训练最后全连接层。
- 提取 proposals并计算CNN 特征。利用选择性搜索(Select ive Search)算法提取所有proposals(大约2000幅
images),调整(resize/warp)它们成固定大小,以满足 CNN输入要求(因为全连接层的限制),然后将特征图保存到本地磁盘。 - 训练SVM。利用特征图训练SVM来对目标和背景进行分类。
Fast R-CNN
原文链接:Fast R-CNN:https://arxiv.org/pdf/1506.01497.pdf

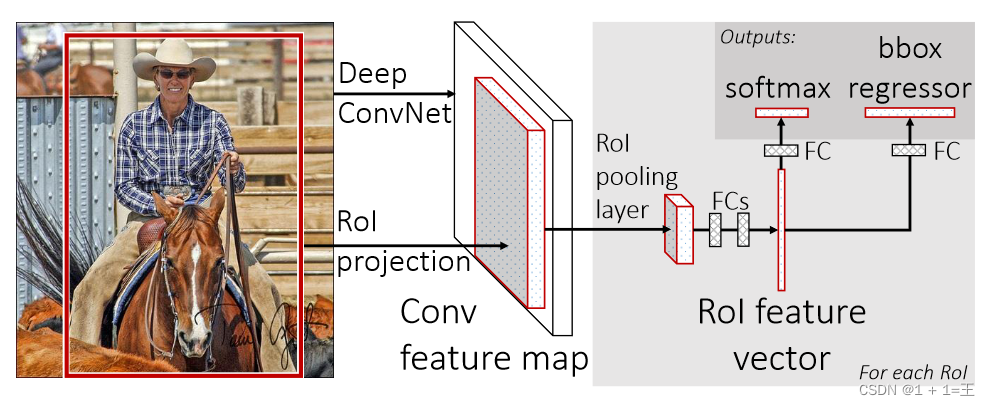
Fast R-CNN有以下创新点:
- 只对整幅图像进行一次特征提取,避免R-CNN中的冗余特征提取
- 用RoI pooling层替换最后一层的max pooling层,同时引入建议框数据,提取相应建议框特征
- Fast R-CNN网络末尾采用并行的不同的全连接层,可同时输出分类结果和窗口回归结果,实现了end-t o-end的多任务
训练【建议框提取除外】,也不需要额外的特征存储空间【R-CNN中的特征需要保持到本地,来供SVM和Bounding-box
regression进行训练】 - 采用SVD对Fast R-CNN网络末尾并行的全连接层进行分解,减少计算复杂度,加快检测速度。
Faster R-CNN
原文链接:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks:https://arxiv.org/pdf/1506.01497.pdf

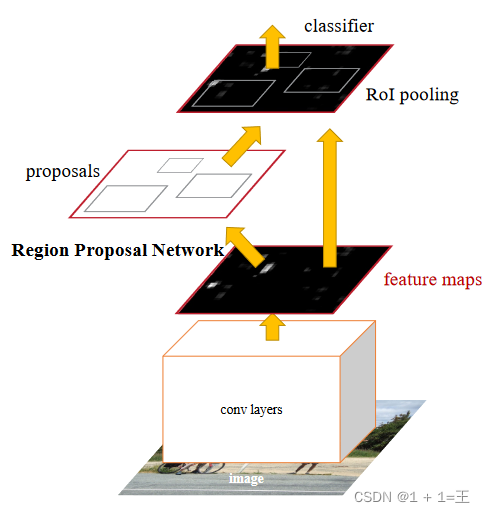
Faster R-CNN的检测步骤如下:
- 输入:将尺寸大小为 M×N 的图片输入 Faster-RCNN 网络进行resize操作,处理图片的尺寸到 H×W,适应模型要求。
- 数据预处理:首先,将尺寸大小为 M×N 的图片输入 Faster-RCNN 网络进行resize操作,处理图片的尺寸到 H×W,适应模型要求。然后,将图片输入 RoI Pooling 层进行特征的尺寸变换,并将图片输入 Classifier 进行分类。
- 区域提取:对输入的图片进行区域提取,得到每个object的特征图。
- RPN:将得到的特征图输入 RPN,得到每个object的预测概率。
- Classifier:通过全连接层得到最后的概率,计算得到类别,同时再次bounding box regression获得检测框最终的精确位置。
- 输出:根据检测框的位置,计算得到目标在图片中的精确位置,并输出目标的类别。
通过以上步骤,就可以得到目标在图片中的精确位置,从而实现目标检测。
FPN
论文原文:Feature Pyramid Networks for Object Detection:https://openaccess.thecvf.com/content_cvpr_2017/papers/Lin_Feature_Pyramid_Networks_CVPR_2017_paper.pdf

FPN网络直接在Faster R-CNN单网络上做修改,每个分辨率的 feature map 引入后一分辨率缩放两倍的 feature map 做element -wise 相加的操作。通过这样的连接,每一层预测所用的 feature map 都融合了不同分辨率、不同语义强度的特征,融合的不同分辨率的 feature map 分别做对应分辨率大小的物体检测。这样保证了每一层都有合适的分辨率以及强语义特征。同时,由于此方法只是在原网络基础上加上了额外的跨层连接,在实际应用中几乎不增加额外的时间和计算量。
Mask R-CNN
论文原文:Mask R-CNN:https://arxiv.org/pdf/1703.06870.pdf

Mask R-CNN是对Faster R-CNN的直观扩展,网络的主干有RPN转换为主干网络为ResNet的特征金字塔网络(FPN),同时添加了一个分支用于预测每个感兴趣区域(RoI)上的分割掩模,与现有的用于分类和边界盒回归的分支并行。掩模分支是一个应用于每个RoI的小FCN,以像素-顶像素的方式预测分割掩模。 但是,Faster RCNN并不是为网络输入和输出之间的像素对像素对齐而设计的。 这一点最明显的是RoIPool[18,12],事实上的处理实例的核心操作,如何执行特征提取的粗空间量化。 为了解决这种错位,网络使用了一个简单的、无量化的层,称为RoI Align,它忠实地保留了精确的空间位置。FPN构造特征包括自下而上(bottom-up)、自上而下(top-down)以及同层连接3个过程,自下而上的过程实质上是卷积网络前向传播的过程。
一阶段目标检测算法
SSD
论文原文:SSD: Single Shot MultiBox Detector:https://arxiv.org/pdf/1512.02325.pdf

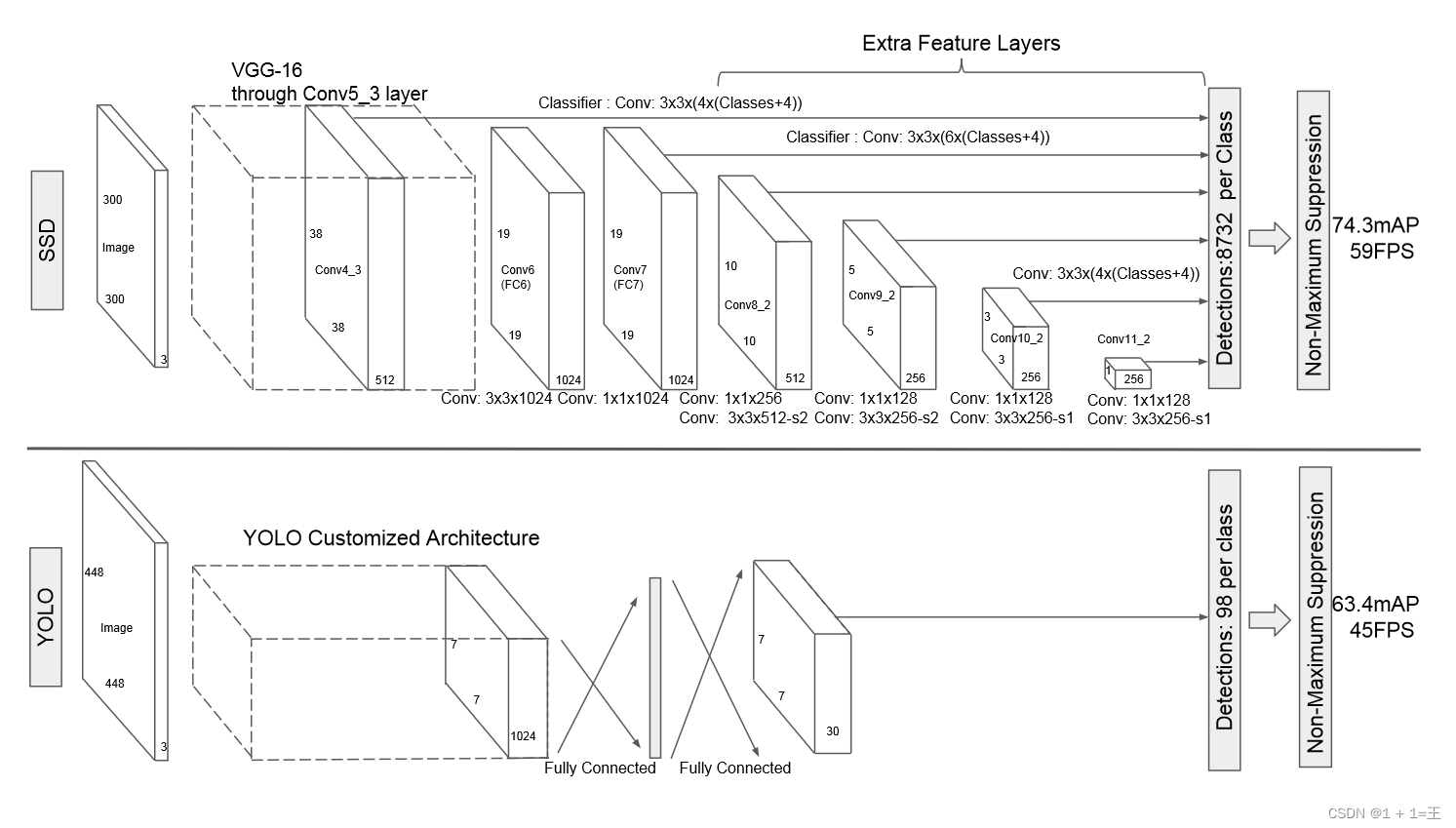
不同于前面的R-CNN系列,SSD属于one-stage方法。SSD使用 VGG16 网络作为特征提取器,将后面的全连接层替换成卷积层,并在之后添加自定义卷积层,并在最后直接采用卷积进行检测。在多个特征图上设置不同缩放比例和不同宽高比的先验框以融合多尺度特征图进行检测,靠前的大尺度特征图可以捕捉到小物体的信息,而靠后的小尺度特征图能捕捉到大物体的信息,从而提高检测的准确性和定位的准确性。
YOLOv1
论文原文:You Only Look Once:Unified, Real-Time Object Detection:https://arxiv.org/pdf/1506.02640.pdf

YOLO v1是单阶段目标检测方法,不需要像Faster R-CNN这种两阶段目标检测方法一样,需要生成先验框。 Yolo算法采用一个单独的CNN模型实现end-to-end的目标检测。 整个YOLO目标检测pipeline如下图所示:首先将输入图片resize到448x448,然后送入CNN网络,最后处理网络预测结果得到检测的目标。 YOLO为一种新的目标检测方法,该方法的特点是实现快速检测的同时还达到较高的准确率。 作者将目标检测任务看作目标区域预测和类别预测的回归问题。 该方法采用单个神经网络直接预测物品边界和类别概率,实现端到端的物品检测。

YOLOv2
论文原文:YOLO9000: Better, Faster, Stronger:https://arxiv.org/pdf/1612.08242.pdf

YOLOv2和YOLOv1的比较如下图所示:

YOLOv3
论文原文:YOLOv3: An Incremental Improvement:https://pjreddie.com/media/files/papers/YOLOv3.pdf
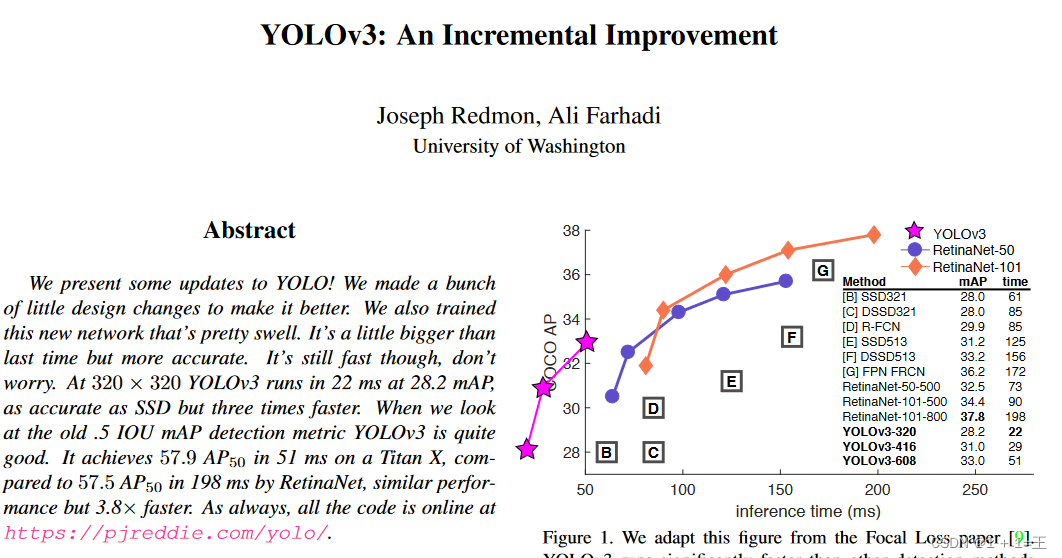
YOLOv3是一种改进的YOLO算法,相比YOLOv2,它在精度和速度之间进行了折中,从而获得了更好的效果。
- 改进了模型结构:YOLOv3引入了一个新的模块——SPP(Sample Point Proposal)模块,用于提高YOLOv3的精度。SPP模块将YOLOv2的SSD模块和YOLOv3的backbone模块合并在了一起,提高了YOLOv3的分类精度。同时,YOLOv3的backbone模块中的残差块数量从YOLOv2的512个减少到了256个,这进一步提高了YOLOv3的精度。
- 改进了分类器:YOLOv3在分类器方面进行了改进,它利用了YOLOv2的弱分类器,提高了分类的准确性。YOLOv3的弱分类器在每个batch中只利用一部分image,通过弱分类器进行预测,而YOLOv3+SSD则利用了SSD的预测能力,提高了分类的准确性。
- 改进了预测框生成:YOLOv3在预测框生成方面也进行了改进,它使用了一个单独的神经网络,将图像划分多个区域并且预测边界框和每个区域的概率。与YOLOv2相比,YOLOv3的预测框生成速度更快,同时也提高了边界框的准确性。
- 改进了弱分类器的参数调整:YOLOv3对弱分类器的参数进行了调整,使得它在不同尺寸的图片上都能够得到更好的表现。例如,YOLOv3使用了一个single large pool layer来替代YOLOv2中的3个small pool layers,从而减少了弱分类器的参数数量,进一步提高了定位的准确性。
目标检测的常用数据集
-
PASCAL VOC
PASCAL VOC(The Pascal VOC Challenge)是一个由欧盟资助的计算机视觉挑战赛,旨在促进计算机视觉技术的发展和应用。该挑战赛从2005年开始举办,每年的比赛内容都有所不同,从最开始的分类,到后面逐渐增加检测、分割、人体布局、动作识别等内容,数据集的容量以及种类也在不断增加和改善。 -
MS COCO
MS COCO(Microsoft Common Objects in Context)是一个由微软公司开发的目标检测数据集,它起源于2014年微软出资标注的Microsoft COCO数据集。COCO是一个具有非常高的行业地位且规模非常庞大的数据集,用于目标检测、分割、图像描述等等场景。特点包括:Object segmentation:对象级分割;Recognition in context:上下文识别;Superpixel stuff segmentation:超像素分割;330K images (>200K labeled):330万张图像(超过20万张已标注图像);1.5 million object instances:150万个对象实例;5 captions per image:每张图片有5段描述。MS COCO数据集包含了91个类别的图片,每个类别的图片数量在50万到200万之间。对于目标检测任务来说,COCO数据集中的80类是完全足够的。 -
Google Open Image
Open Images是由谷歌发布的一个开源图片数据集,在2022年10月份发布了最新的V7版本。 这个版本的数据集包含了900多万张图片,都有类别标记。 -
ImageNet
ImageNet是一个由很多研究人员和大学的贡献组成的开放数据集,用于研究各种类型的图像分类任务。它包含了多种类型的图像,例如花卉、动物、建筑物等等,每种类型的图像都有自己的子集,用于训练和测试各种不同的模型。ImageNet数据集始于2009年,由李飞飞教授等人发起,经过多年的发展,现在已经成为了研究图像分类的重要平台之一。
目标检测的标注工具
-
LabelImg
LabelImg 是一款开源的图像标注工具,标签可用于分类和目标检测,它是用 Pyt hon 编写的,并使用Qt 作为其图形界面,简单好用。注释以 PASCAL VOC 格式保存为 XML 文件,这是 ImageNet 使用的格式。 此外,它还支持 COCO 数据集格式。
在安装LabelImg之前,需要先下载并安装预编译的二进制库。可以使用以下命令进行安装:
pip install labelimg-i https://pypi.tuna.tsinghua.edu.cn/simple -
Labelme
Labelme 是麻省理工(MIT)的计算机科学和人工智能实验室(CSAIL)研发的图像标注工具,人们可以使用该工具创建定制化标注任务或执行图像标注,项目源代码已经开源。 -
Labelbox
Labelbox 是一个在线的标注工具,可以帮助用户对图片中的物体进行标注和注释,并将标注结果保存为xml、txt或者json格式的文件。用户可以通过访问Labelbox的官方网站,下载安装最新版本的Labelbox,然后打开Labelbox,选择要标注的图片文件,再选择标注类型(例如 VOC 标签、YOLO 标签和 createML 标签等),最后点击“标注”按钮即可完成标注操作。Labelbox还提供了图片预览功能,可以在标注前先预览标注后的图片效果。除此之外,Labelbox 还提供了一些其他的功能,例如可以设置标注文件的版本号、调整标注文件的保存路径等。 -
RectLabel
Rect Label 是一款在线免费图像标注工具,标签可用于目标检测、分割和分类。具有的功能或特点:
可用的组件:矩形框,多边形,三次贝塞尔曲线,直线和点,画笔,超像素
可只标记整张图像而不绘制
可使用画笔和超像素
导出为YOLO,KIT T I,COCO JSON和CSV格式
以PASCAL VOC XML格式读写
使用Core ML模型自动标记图像
将视频转换为图像帧
- CVAT
CVAT(Chinese Visual Assisted Text Annotation Tool)是一种基于计算机视觉和自然语言处理技术的文本标注工具,它可以快速准确地标注出图像中的文本信息,帮助用户快速准确地解析和分析图像。
CVAT的主要功能包括:
自动标注:支持批量标注,可以在一张图片中自动标注多个对象。
实时标注:可以实时地对图像进行标注,标注结果会实时显示在图像上方的标注框中。
多标签标注:可以对图像中的对象进行多标签标注,每个标签可以对应一个或多个对象。
图像分析:可以对标注结果进行图像分析,例如检测目标、分割图像等。
标注结果可视化:可以将标注结果以图像、文本、数字等形式进行可视化展示,方便用户查看和分析。
CVAT可以广泛应用于图像处理、自然语言处理、文本标注等领域,帮助用户快速准确地解决问题。