1 SparkSession
Spark Core: SparkContext
Spark SQL: 难道就没有SparkContext?
2.x之后统一的
package com.javaedge.bigdata.chapter04
import org.apache.spark.sql.{DataFrame, SparkSession}
object SparkSessionApp {
def main(args: Array[String]): Unit = {
// DF/DS编程的入口点
val spark: SparkSession = SparkSession.builder()
.master("local").getOrCreate()
// 读取文件的API
val df: DataFrame = spark.read.text("/Users/javaedge/Downloads/sparksql-train/data/input.txt")
// TODO 业务逻辑处理,通过DF/DS提供的API完成业务
df.printSchema()
df.show() // 展示出来 只有一个字段,string类型的value
spark.stop()
}
}
1.x的Spark SQL编程入口点
- SQLContext
- HiveContext
Spark SQL中,SQLContext、HiveContext都是用来创建DataFrame和Dataset主要入口点,二者区别如下:
- 数据源支持:SQLContext支持的数据源包括JSON、Parquet、JDBC等等,而HiveContext除了支持SQLContext的数据源外,还支持Hive的数据源。因此,如果需要访问Hive中的数据,需要使用HiveContext。
- 元数据管理:SQLContext不支持元数据管理,因此无法在内存中创建表和视图,只能直接读取数据源中的数据。而HiveContext可以在内存中创建表和视图,并将其存储在Hive Metastore中。
- SQL语言支持:SQLContext和HiveContext都支持Spark SQL中的基本语法,例如SELECT、FROM、WHERE等等。但HiveContext还支持Hive中的所有SQL语法,例如INSERT、CREATE TABLE AS等等。
- 数据格式支持:HiveContext支持更多的数据格式,包括ORC、Avro、SequenceFile等等。而SQLContext只支持JSON、Parquet、JDBC等几种常用的数据格式。
如若访问Hive中数据或在内存中创建表和视图,推荐HiveContext;若只需访问常见数据源,使用SQLContext。
Spark 2.x后,HiveContext已被SparkSession替代,因此推荐SparkSession创建DataFrame、Dataset。
package com.javaedge.bigdata.chapter04
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{DataFrame, SQLContext}
/**
* 了解即可,已过时
*/
object SQLContextApp {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setAppName("SQLContextApp").setMaster("local")
// 此处一定要把SparkConf传进来
val sc: SparkContext = new SparkContext(sparkConf)
val sqlContext: SQLContext = new SQLContext(sc)
val df: DataFrame = sqlContext.read.text("/Users/javaedge/Downloads/sparksql-train/data/input.txt")
df.show()
sc.stop()
}
}
output:
+-------------+
| value|
+-------------+
| pk,pk,pk|
|jepson,jepson|
| xingxing|
+-------------+
2 DataFrame
最早在R语言数据分析包中提出,表示一种类似表格的数据结构,其中行和列都可以有命名。
Spark的DataFrame是基于RDD(弹性分布式数据集)的一种高级抽象,类似关系型数据库的表格。Spark DataFrame可看作带有模式(Schema)的RDD,而Schema则是由结构化数据类型(如字符串、整型、浮点型等)和字段名组成。
2.1 命名变迁
Spark 1.0的Spark SQL的数据结构称为SchemaRDD,具有结构化模式(schema)的分布式数据集合。
Spark 1.3版本开始,SchemaRDD重命名为DataFrame,以更好反映其API和功能实质。因此,DataFrame曾被称为SchemaRDD,但现已不再使用这名称。
2.2 Spark SQL的DataFrame优点
- 可通过SQL语句、API等多种方式进行查询和操作,还支持内置函数、用户自定义函数等功能
- 支持优化器和执行引擎,可自动对查询计划进行优化,提高查询效率
因此,DataFrame已成Spark SQL核心组件,广泛应用于数据分析、数据挖掘。
3 数据分析选型:PySpark V.S R 语言
- 数据规模:如果需要处理大型数据集,则使用PySpark更为合适,因为它可以在分布式计算集群上运行,并且能够处理较大规模的数据。而R语言则可能会受限于单机内存和计算能力。
- 熟练程度:如果你或你的团队已经很熟悉Python,那么使用PySpark也许更好一些,因为你们不需要再去学习新的编程语言。相反,如果已经对R语言很熟悉,那么继续使用R语言也许更为方便。
- 生态系统:Spark生态系统提供了许多额外的库和工具,例如Spark Streaming和GraphX等,这些库和工具可以与PySpark无缝集成。而R语言的生态系统也有一些类似的库和工具,但相对来说可选择性就更少一些。
总之,选择使用哪种工具进行数据分析应该基于具体情况进行考虑。如果需要处理大规模数据集,并需要与Spark生态系统集成,那么PySpark可能更适合;如果更加熟悉R语言,或者数据量较小,那么使用R语言也可以做到高效的数据分析。
4 深入理解
Dataset是一个分布式数据集,提供RDD强类型和使用强大的lambda函数的能力,并结合了Spark SQL优化的执行引擎。Dataset可以从JVM对象构建而成,并通过函数式转换(如map、flatMap、filter等)进行操作。Scala和Java都支持Dataset API,但Python没有对Dataset API提供支持。由于Python是一种动态语言,许多Dataset API的优点已经自然地可用,例如可以通过名称访问行的字段。R语言也有类似的特点。
DataFrame,具有命名列的Dataset,类似:
- 关系数据库中的表
- Python中的数据框
但内部有更多优化功能。DataFrame可从各种数据源构建,如:
- 结构化数据文件
- Hive表
- 外部数据库
- 现有RDD
DataFrame API 在 Scala、Java、Python 和 R 都可用。在Scala和Java中,DataFrame由一组Rows组成的Dataset表示:
- Scala API中,DataFrame只是Dataset[Row]的类型别名
- Java API中,用户需要使用Dataset表示DataFrame
通常将Scala/Java中的Dataset of Rows称为DataFrame。
5 实战
People.json
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
package com.javaedge.bigdata.chapter04
import org.apache.spark.sql.{DataFrame, SparkSession}
object DataFrameAPIApp {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local").appName("DataFrameAPIApp")
.getOrCreate()
import spark.implicits._
val people: DataFrame = spark.read.json(
"/Users/javaedge/Downloads/sparksql-train/data/people.json")
// 查看DF的内部结构:列名、列的数据类型、是否可以为空
people.printSchema()
// 展示出DF内部的数据
people.show()
}
}
output:
root
|-- age: long (nullable = true)
|-- name: string (nullable = true)
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
// DF里面有两列,只要name列 ==> select name from people
// 两个 API 一样的,只是参数不同,使用稍有不同
people.select("name").show()
people.select($"name").show()
output:
+-------+
| name|
+-------+
|Michael|
| Andy|
| Justin|
+-------+
// select * from people where age > 21
people.filter($"age" > 21).show()
people.filter("age > 21").show()
output:
+---+----+
|age|name|
+---+----+
| 30|Andy|
+---+----+
// select age, count(1) from people group by age
people.groupBy("age").count().show()
output:
+----+-----+
| age|count|
+----+-----+
| 19| 1|
|null| 1|
| 30| 1|
+----+-----+
createOrReplaceTempView
若现在,我就想完全使用 SQL 查询了,怎么实现 DF 到表的转换呢?
Spark SQL用来将一个 DataFrame 注册成一个临时表(Temporary Table)的方法。之后可使用 Spark SQL 语法及已注册的表名对 DataFrame 进行查询和操作。
允许为 DataFrame 指定一个名称,并将其保存为一个临时表。该表只存在于当前 SparkSession 的上下文,不会在元数据存储中注册表,也不会在磁盘创建任何文件。因此,临时表在SparkSession终止后就会被删。
一旦临时表被注册,就可使用 SQL 或 DSL 对其查询。如:
people.createOrReplaceTempView("people")
spark.sql("select name from people where age > 21").show()
大文件处理
val zips: DataFrame = spark.read.json("/Users/javaedge/Downloads/sparksql-train/data/zips.json")
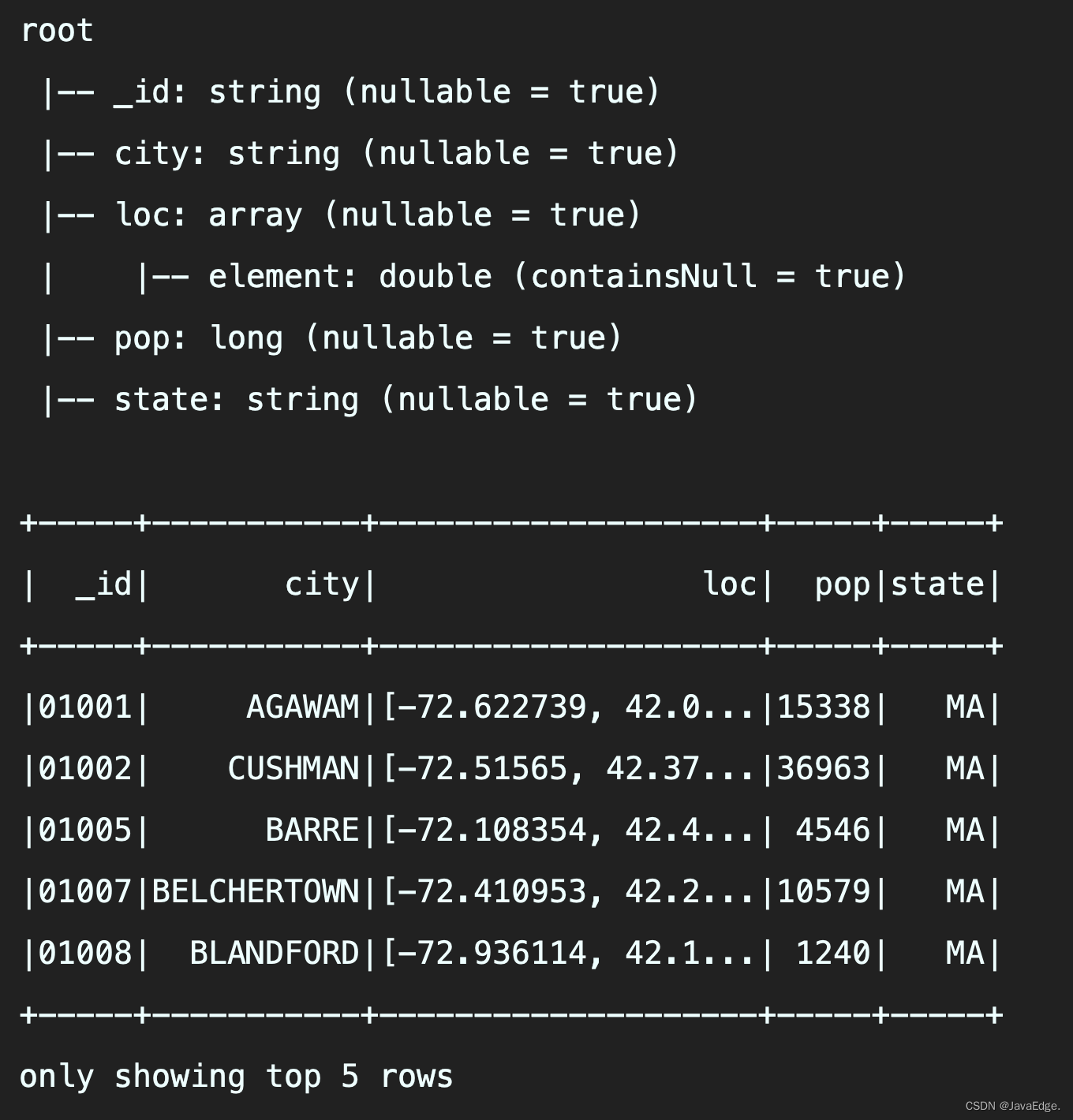
zips.printSchema()
zips.show(5)
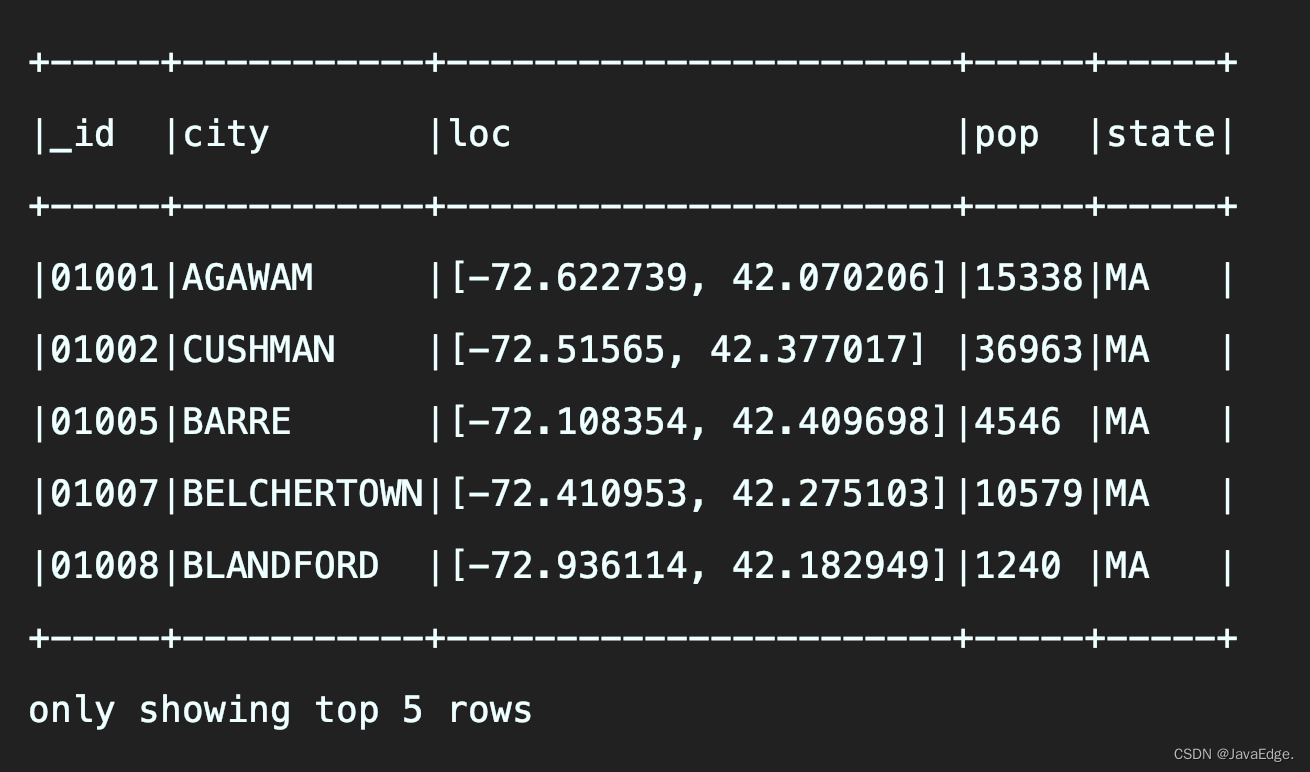
loc信息没用展示全,超过一定长度就使用…来展示,默认只显示前20条:show() ==> show(20) ==> show(numRows, truncate = true)
不想被截断就这样:
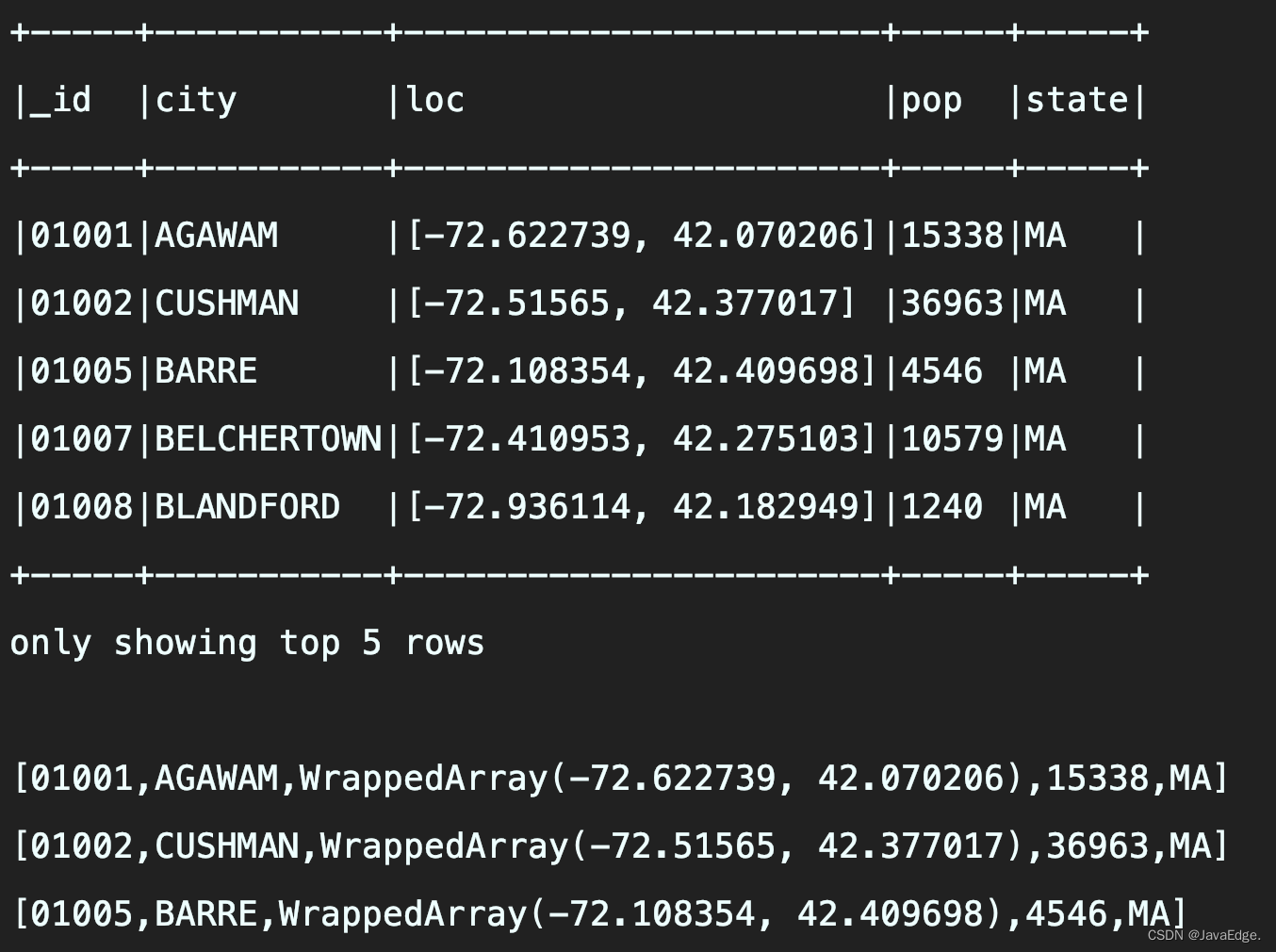
zips.head(3).foreach(println)
zips.first()
zips.take(5)
Output:
head(n: Int)
Spark的DataFrame API中的一个方法,可以返回一个包含前n行数据的数组。这个方法通常用于快速检查一个DataFrame的前几行数据,以了解数据集的大致结构和内容。
- 先对DataFrame使用
.limit(n)方法,限制返回行数前n行 - 然后使用
queryExecution方法生成一个Spark SQL查询计划 - 最后使用
collectFromPlan方法收集数据并返回一个包含前n行数据的数组
该 API 可能导致数据集的全部数据被加载到内存,因此在处理大型数据集时应该谨慎使用。若只想查看数据集结构和内容,使用:
.show()- 或
.take()
获取前几行数据,而非.head()。
// 过滤出大于40000,字段重新命名
zips.filter(zips.col("pop") > 40000)
.withColumnRenamed("_id", "new_id")
.show(5, truncate = false)
output:
+------+----------+-----------------------+-----+-----+
|new_id|city |loc |pop |state|
+------+----------+-----------------------+-----+-----+
|01040 |HOLYOKE |[-72.626193, 42.202007]|43704|MA |
|01085 |MONTGOMERY|[-72.754318, 42.129484]|40117|MA |
|01201 |PITTSFIELD|[-73.247088, 42.453086]|50655|MA |
|01420 |FITCHBURG |[-71.803133, 42.579563]|41194|MA |
|01701 |FRAMINGHAM|[-71.425486, 42.300665]|65046|MA |
+------+----------+-----------------------+-----+-----+
import org.apache.spark.sql.functions._
// 统计加州pop最多的10个城市名称和ID desc是一个内置函数
zips.select("_id", "city", "pop", "state")
.filter(zips.col("state") === "CA")
.orderBy(desc("pop"))
.show(5, truncate = false)
output:
+-----+------------+-----+-----+
|_id |city |pop |state|
+-----+------------+-----+-----+
|90201|BELL GARDENS|99568|CA |
|90011|LOS ANGELES |96074|CA |
|90650|NORWALK |94188|CA |
|91331|ARLETA |88114|CA |
|90280|SOUTH GATE |87026|CA |
+-----+------------+-----+-----+
可惜啊,我不会写代码,可以使用 MySQL 语法吗?
zips.createOrReplaceTempView("zips")
spark.sql("select _id,city,pop,state" +
"from zips where state='CA'" +
"order by pop desc" +
"limit 10").show()
import spark.implicits._ 作用
在Scala中使用Apache Spark进行数据分析时经常用到的,它的作用是将隐式转换函数导入当前作用域中。这些隐式转换函数包含了许多DataFrame和Dataset的转换方法,例如将RDD转换为DataFrame或将元组转换为Dataset等。
具体来说,这行代码使用了SparkSession对象中的implicits属性,该属性返回了一个类型为org.apache.spark.sql.SQLImplicits的实例。通过调用该实例的方法,可以将各种Scala数据类型(如case class、元组等)与Spark SQL中的数据类型(如Row、DataFrame、Dataset等)之间进行转换,从而方便地进行数据操作和查询。
在使用许多Spark SQL API的时候,往往需要使用这行代码将隐式转换函数导入当前上下文,以获得更加简洁和易于理解的代码编写方式。
如果不导入会咋样
如果不导入spark.implicits._会导致编译错误或者运行时异常。因为在进行DataFrame和Dataset的操作时,需要使用到一些隐式转换函数。如果没有导入spark.implicits._,则这些隐式转换函数无法被自动引入当前上下文,就需要手动地导入这些函数,这样会使编码变得比较麻烦。
例如,在进行RDD和DataFrame之间的转换时,如果不导入spark.implicits._,则需要手动导入org.apache.spark.sql.Row以及org.apache.spark.sql.functions._等包,并通过调用toDF()方法将RDD转换为DataFrame。而有了导入spark.implicits._后,只需要直接调用RDD对象的toDF()方法即可完成转换。
因此,为了简化编码,通常会在Scala中使用Spark SQL时导入spark.implicits._,从而获得更加简洁易读的代码。
案例
people.select($"name").show()
如果不导入 spark.implicits._,则可以手动创建一个 Column 对象来进行筛选操作。例如,可以使用 col 函数来创建一个 Column 对象,然后在 select 方法中使用该列:
import org.apache.spark.sql.functions.col
val selected = people.select(col("name"))
selected.show()
这样就可以实现与 people.select($"name").show() 相同的效果,但需要手动创建 Column 对象。显然,在编写复杂的数据操作时,手动创建 Column 对象可能会变得非常繁琐和困难,因此通常情况下我们会选择使用隐式转换函数,从而更加方便地使用DataFrame的API。