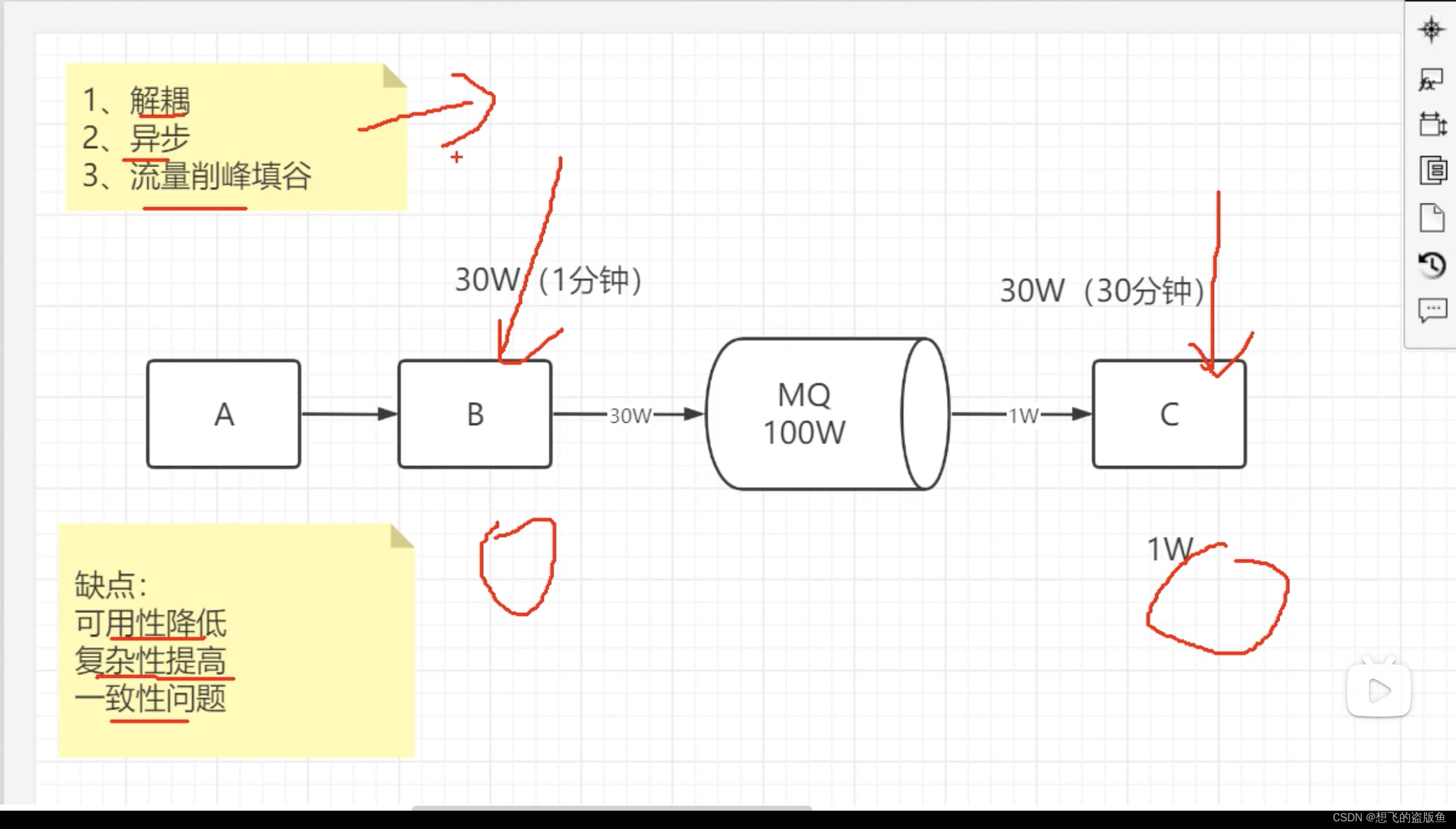
1.为什么要使用消息队列?

2.消息队列有什么优点和缺点?
3.如何解决重复消费?
幂等性:
概念:一次和多次请求某一个资源对于资源本身应该具有同样的结果(网络超时等问题除外)。也就是说,其任意多次执行对资源本身所产生的影响均与一次执行的影响相同。
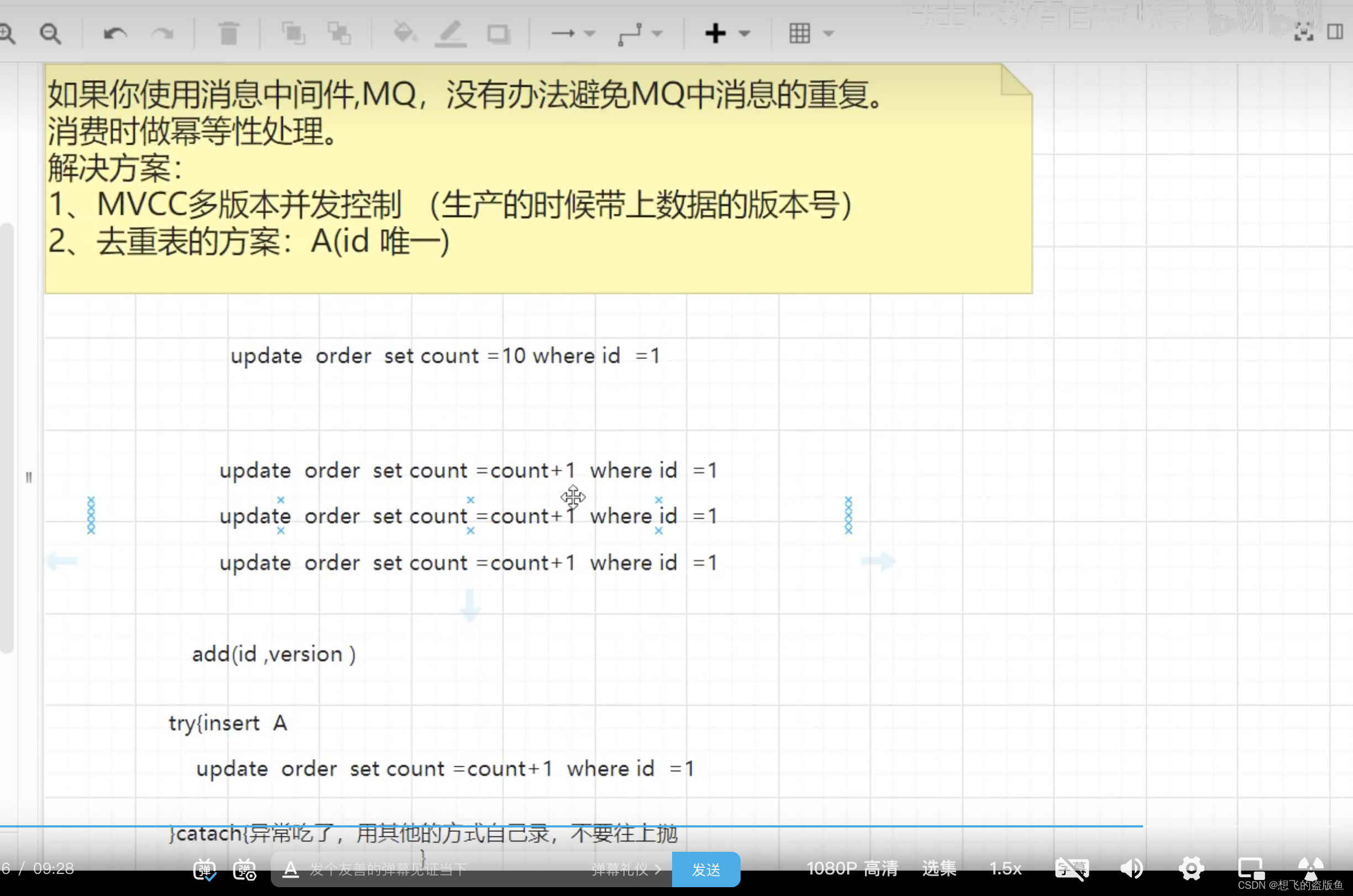
要保证消息的幂等性,这个要结合业务的类型来进行处理。下面提供几个思路供参考:
- 可在内存中维护一个set,只要从消息队列里面获取到一个消息,先查询这个消息在不在set里面,如果在表示已消费过,直接丢弃;如果不在,则在消费后将其加入set当中。
- 如何要写数据库,可以拿唯一键先去数据库查询一下,如果不存在在写,如果存在直接更新或者丢弃消息。
- 如果是写redis那没有问题,每次都是set,天然的幂等性。
- 让生产者发送消息时,每条消息加一个全局的唯一id,然后消费时,将该id保存到redis里面。消费时先去redis里面查一下有么有,没有再消费。
- 数据库操作可以设置唯一键,防止重复数据的插入,这样插入只会报错而不会插入重复数据。
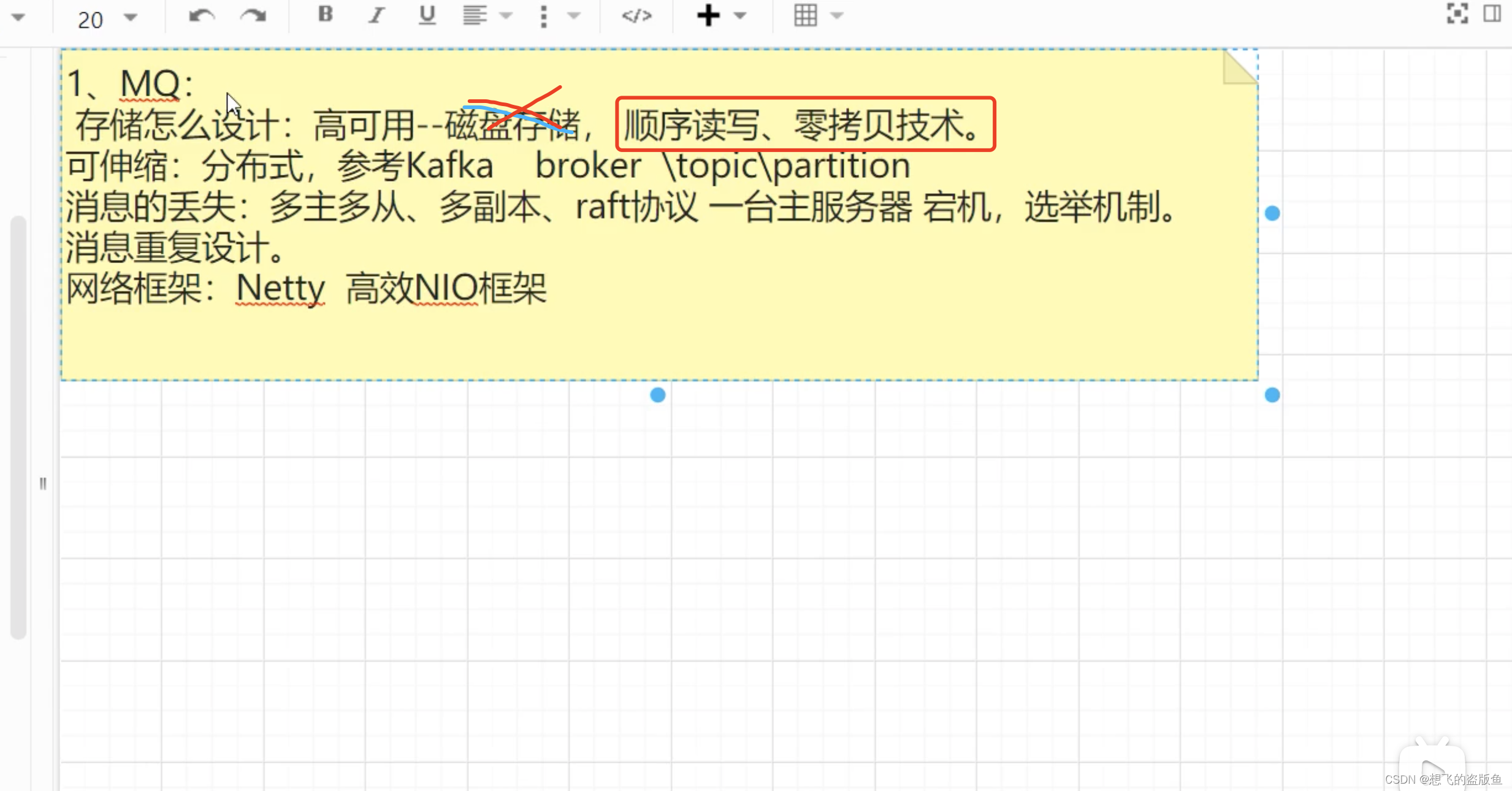
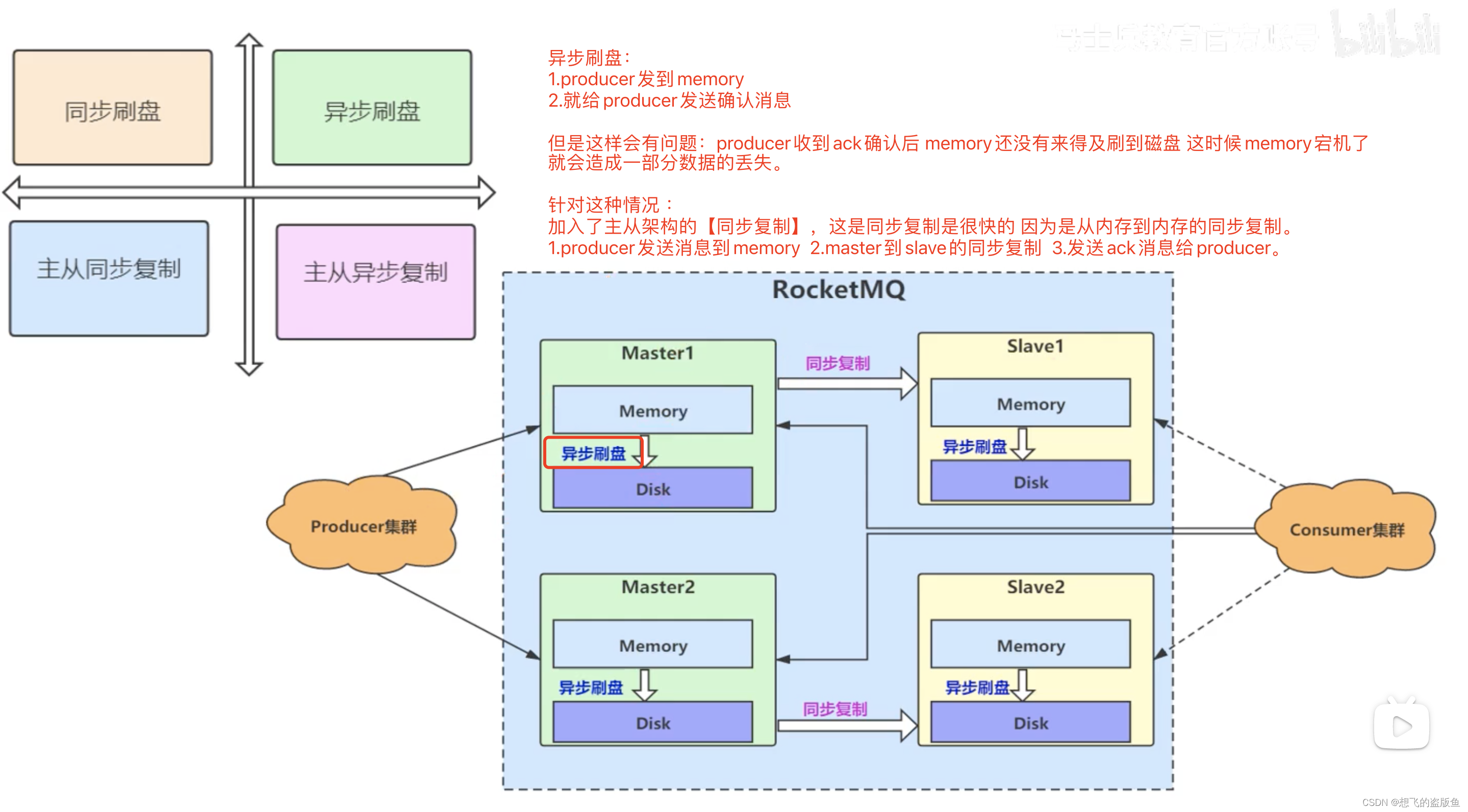
4.RocketMQ如何保证高可用?
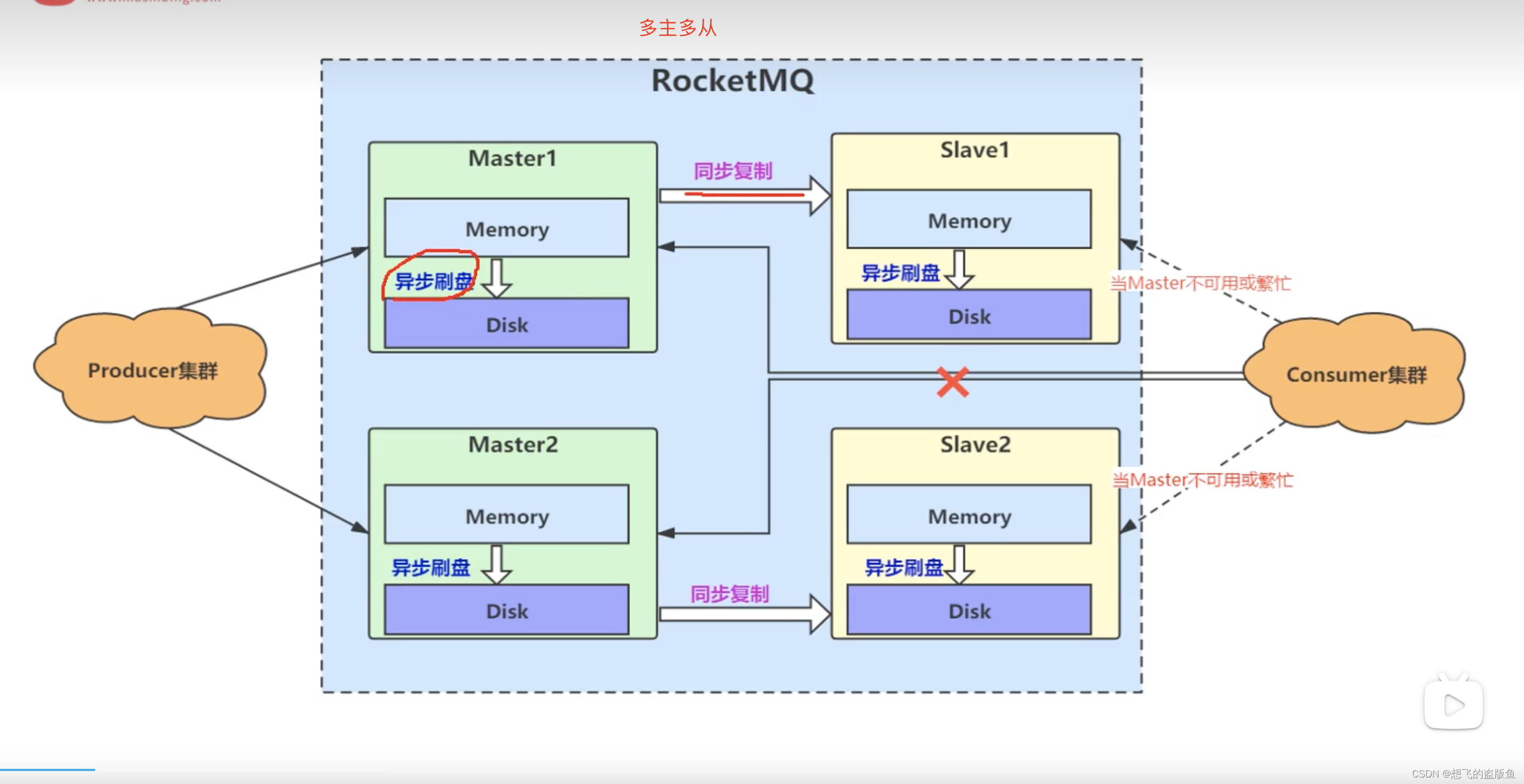
同步复制:保证了我们的热数据。也就是说 主和从保持的数据一致性。
5.RocketMQ的存储机制了解吗?
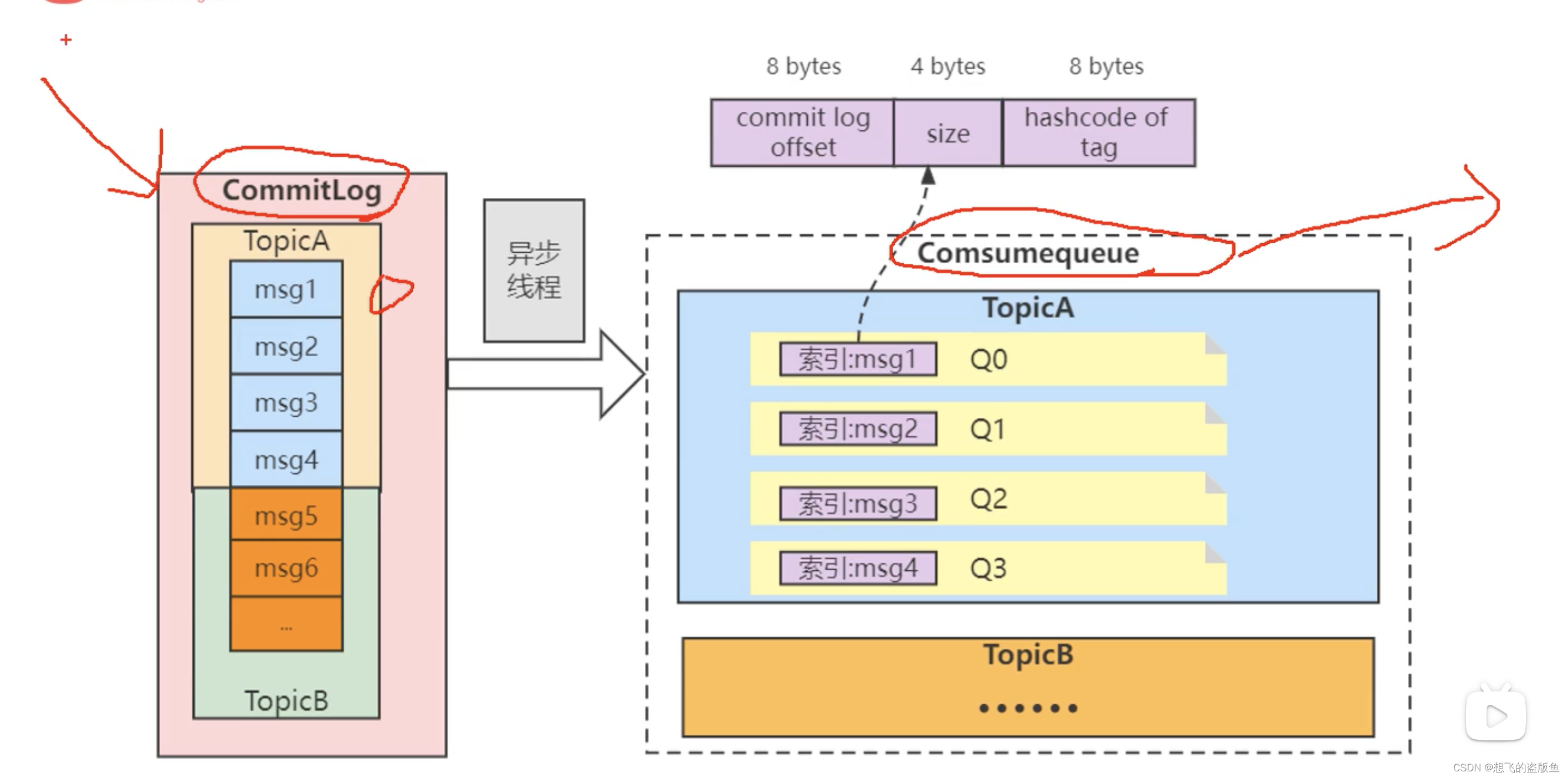

那么consumer怎么消费呢?
consumer消费到consume queue中的第一个queue,找到第一个数据,怎么确保是第一个数据呢?因为每一个数据的:8 bytes+4 bytes + 8 bytes 也就是20个bytes,所以在queue中从头开始找 找20个bytes,拿到这个数据后,就可以在commitLog文件中找到msgId为1111的数据,则就会拿到commitLog文件中的消息体。
所以根据索引:在根据索引解析里面的偏移量和长度;再去找实际本体存储的commitlog—所以作为消费者也可以快速的消费到消息的。这时候找到消息的时间复杂度是o(1);
在comsume queue中找到消息的时间复杂度是o(1):因为每个消息的固定size是20固定的 所以要不找0-20,20-40,40-60,,,,所以这个找到消息的时间复杂度是o(1);找到消息之后 根据消息里面的8 bytes+4 bytes+8bytes,所以根据这个区commitLog文件中去对应这个具体的消息,其时间复杂度也是o(1);所以对于消费者来说 消费到具体的消息的时间复杂度是o(1)+o(1)=o(1)。
为什么不直接用队列放消息就行了?为什么 偏偏又用了commitLog和consum queue一起?
主要是为了应对多主题或者是海量主题的一个高并发写入。也就是说无论你有多少个主题,我也只有一个文件commitLog,在这个commitLog文件中按照顺序写入。所以这样会针对多个主题的高并发是非常有用的。
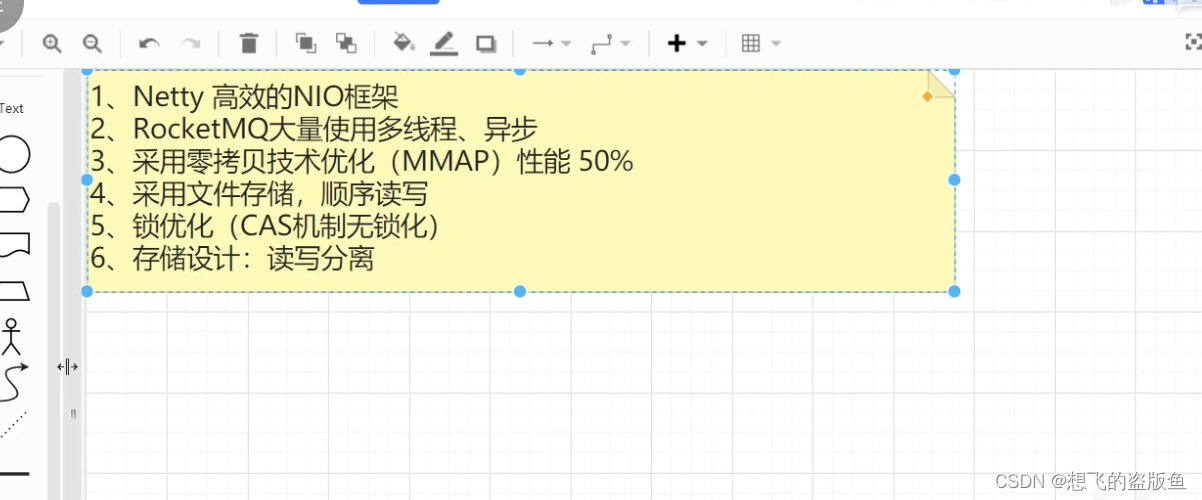
6.RocketMQ性能比较高的原因是什么?
7.让你来设计消费队列 你会怎么设计?
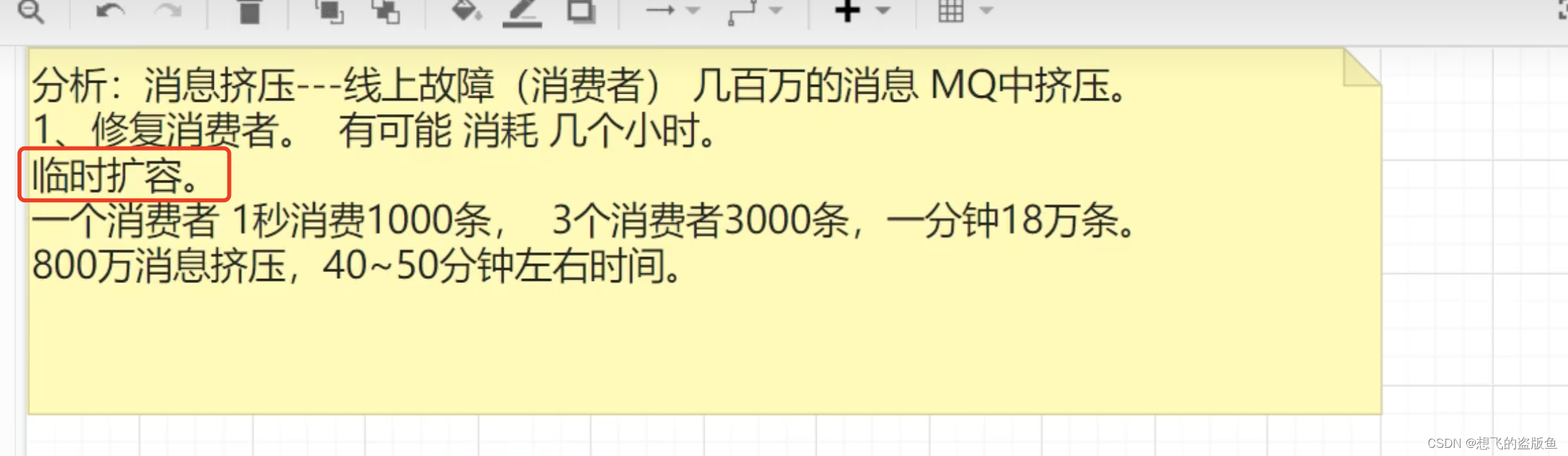
8.有几百万消息支持积压几小时,说说怎么解决?

9.RocketMQ中的broker的部署方式?

10.RocketMQ中的broker的刷盘策略有哪些?
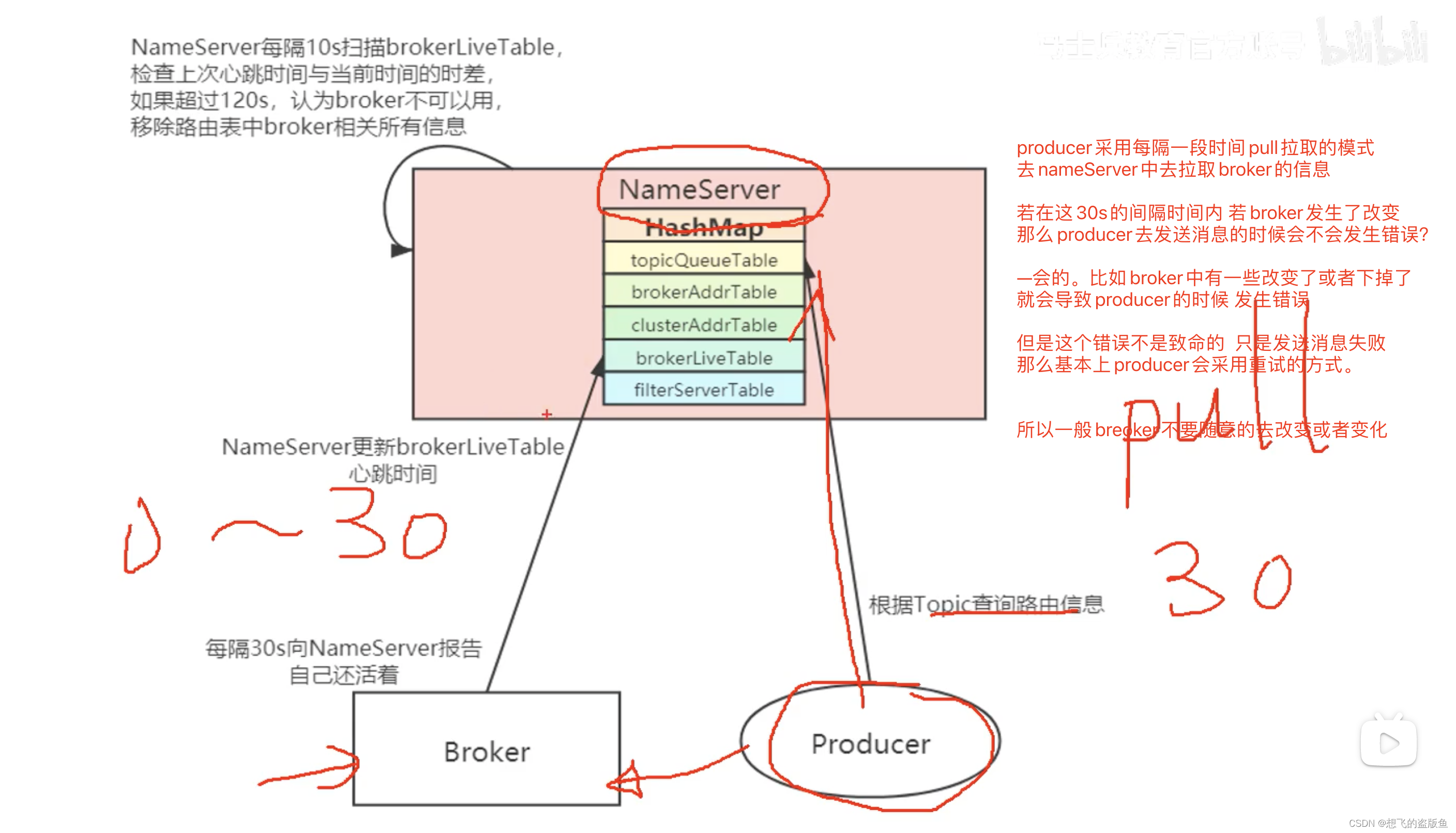
11.什么事路由注册?RocketMQ如何进行路由注册?
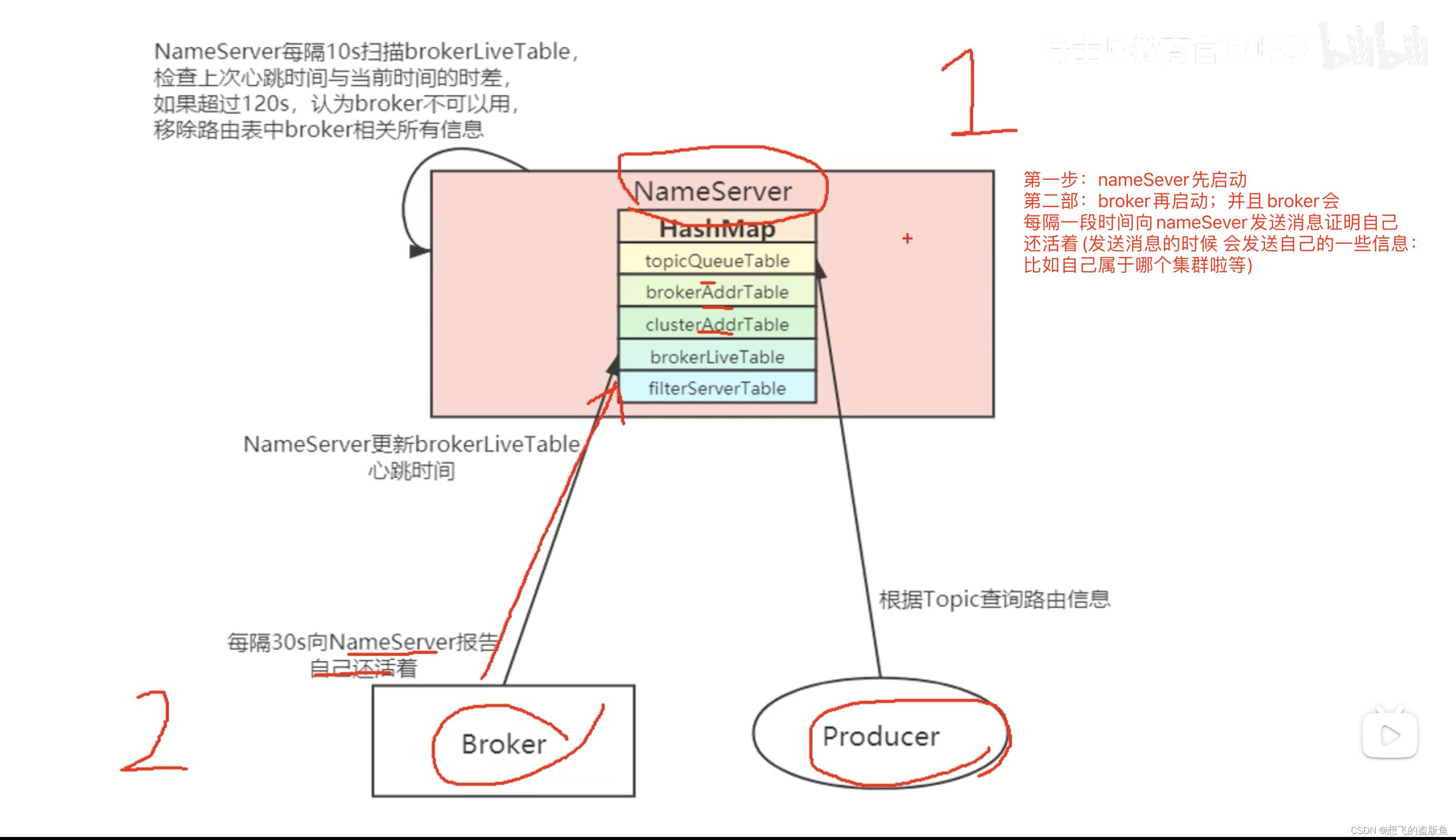
12.什么是路由发现?RocketMQ是如何进行路由发现的?