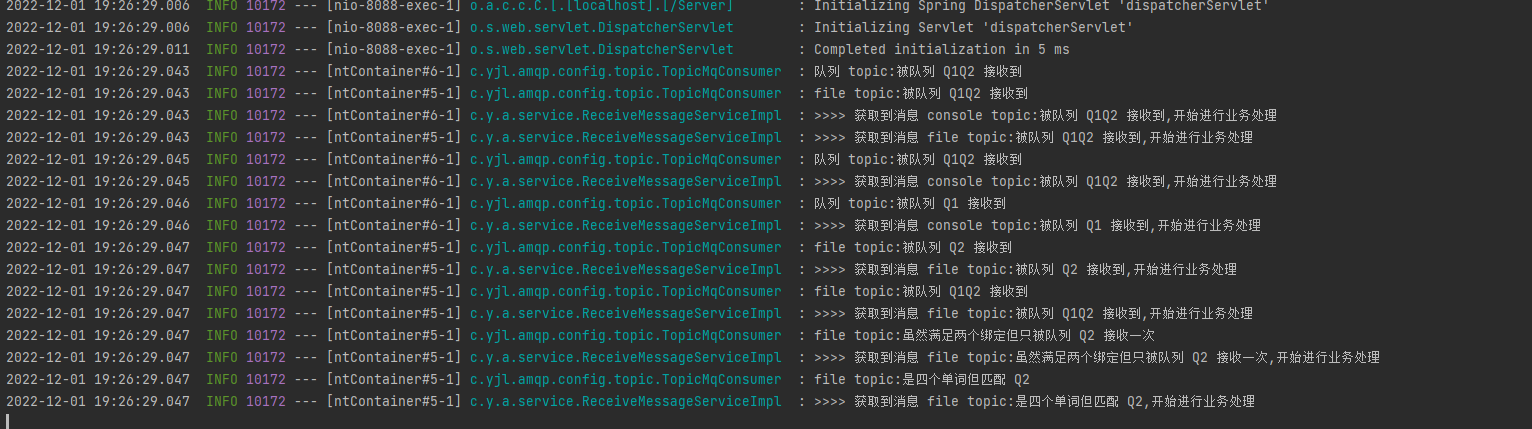
文章目录
- 专栏导读
- 1、KNN算法原理
- 2、实战案例-对鸢尾花类别分类预测
- 2.1确定特征和类别
- 2.2对特征进行处理
- 2.3对模型调参,选择最优参数
- 2.4使用分类模型进行预测
- 2.5评估模型,检验模型效果
- 3、完整代码及结果
专栏导读
✍ 作者简介:i阿极,CSDN Python领域新星创作者,专注于分享python领域知识。
✍ 本文录入于《数据分析之术》,本专栏精选了经典的机器学习算法进行讲解,针对大学生、初级数据分析工程师精心打造,对机器学习算法知识点逐一击破,不断学习,提升自我。
✍ 订阅后,可以阅读《数据分析之术》中全部文章内容,详细介绍数学模型及原理,带领读者通过模型与算法描述实现一个个案例。
✍ 还可以订阅基础篇《数据分析之道》,其包含python基础语法、数据结构和文件操作,科学计算,实现文件内容操作,实现数据可视化等等。
✍ 其他专栏:《数据分析案例》 ,《机器学习案例》
1、KNN算法原理
K最近邻(K-Nearest Neighbor,KNN)算法是一种用于分类和回归的非参数模型,它可以用于模式识别、图像处理、语音识别和推荐系统等领域。
KNN算法的基本思想是根据样本之间的距离和相似性进行分类,即将一个新的样本分类为其最近的K个邻居中最常见的类别。
KNN算法可以分为两个阶段:训练和预测。
-
训练阶段:训练数据集中的每个样本由特征和标签组成,KNN算法将其全部保存下来,构成训练模型。
-
预测阶段:给定一个新的样本,KNN算法首先计算其与训练集中每个样本的距离,并选取与其距离最近的K个训练集样本,然后根据这K个样本的标签来预测新样本的类别。
KNN算法中的距离通常使用欧氏距离来度量,其公式为:
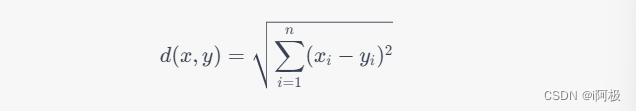
其中,
x
x
x和
y
y
y表示两个样本向量,
n
n
n表示特征的数量。
在KNN算法中,关键参数是K值的选择。K值的选择对于KNN算法的准确性和泛化能力有很大的影响。通常来说,K值较小会导致模型对噪声敏感,而K值较大会导致模型过于平滑。
确定K值的方法一般有两种:
- 网格搜索法:对于每个候选的K值,在训练集上进行交叉验证,找到最优的K值。
- 经验法则:通常将K设置为小于样本数平方根的整数,例如样本数为1000,则K取值范围可以为1-31之间的奇数。
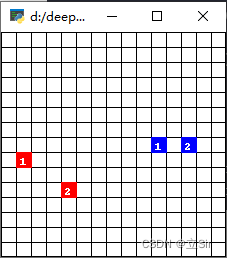
举个例子来说,假设有一个二维数据集,有两个类别,分别是红色和蓝色,如下图所示:
对于一个新样本点(绿色圆点),我们需要使用KNN算法来预测它所属的类别。首先,我们选择一个合适的K值,比如K=5。接着,我们计算新样本点与所有训练集中样本点的距离,并选择距离最近的5个点作为邻居,如下图所示:

由于这五个邻居中,有3个是蓝色的,2个是红色的,因此我们预测新样本点属于蓝色类别。如果K值为3,则预测结果是红色类别。
2、实战案例-对鸢尾花类别分类预测
我们将使用sklearn中的鸢尾花数据集来实现一个分类预测的案例。
2.1确定特征和类别
我们将使用鸢尾花数据集中的4个特征(花萼长度、花萼宽度、花瓣长度和花瓣宽度)来预测鸢尾花的类别(Setosa、Versicolor和Virginica)。
# 导入相关的库
from sklearn.datasets import load_iris
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import confusion_matrix, accuracy_score
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
2.2对特征进行处理
我们不需要对特征进行处理,因为鸢尾花数据集已经是一个规范化的数据集。
直接划分训练集和测试集并定义KNN分类模型和需要搜索的K值。
# 将数据集分成训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 定义KNN分类器
knn = KNeighborsClassifier()
# 定义需要搜索的K值
param_grid = {'n_neighbors': [1, 3, 5, 7, 9, 11]}
2.3对模型调参,选择最优参数
KNN算法有一个重要的参数K,用来确定最近邻居的数量。我们需要使用交叉验证的方法来选择最优的K值。在本案例中,我们将使用GridSearchCV函数来进行交叉验证和参数选择。
# 使用GridSearchCV函数进行交叉验证和参数选择
grid_search = GridSearchCV(knn, param_grid, cv=5)
grid_search.fit(X_train, y_train)
2.4使用分类模型进行预测
# 使用最优的K值重新训练模型
knn = KNeighborsClassifier(n_neighbors=grid_search.best_params_['n_neighbors'])
knn.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = knn.predict(X_test)
2.5评估模型,检验模型效果
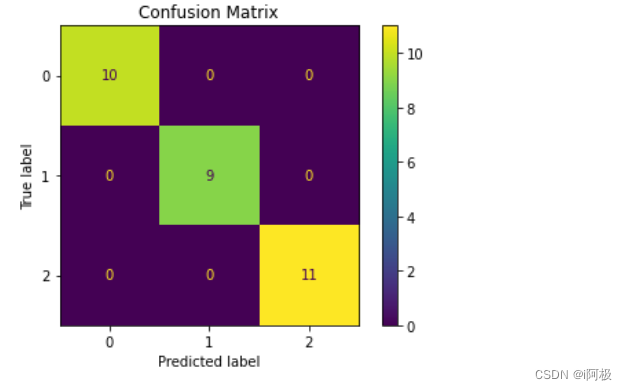
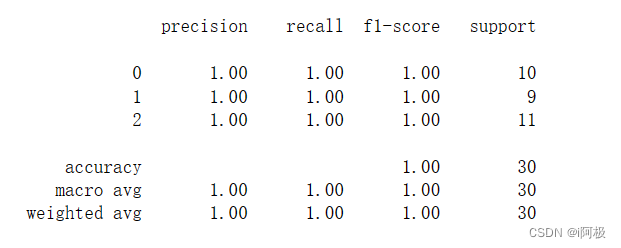
我们将使用混淆矩阵、准确率、召回率和F1值等指标来评估模型的效果。
# 输出混淆矩阵
plot_confusion_matrix(knn_model, X_test, y_test)
plt.title('Confusion Matrix')
plt.show()
# 输出分类报告
print(classification_report(y_test, y_pred))
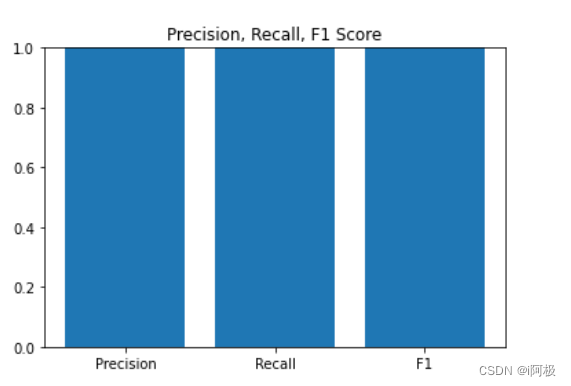
# 输出准确率、召回率和F1值的可视化
from sklearn.metrics import precision_recall_fscore_support
precision, recall, f1, _ = precision_recall_fscore_support(y_test, y_pred, average='weighted')
plt.bar(['Precision', 'Recall', 'F1'], [precision, recall, f1])
plt.ylim(0, 1)
plt.title('Precision, Recall, F1 Score')
plt.show()
3、完整代码及结果
# 导入相关的库
from sklearn.datasets import load_iris
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import confusion_matrix, accuracy_score
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 将数据集分成训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 定义KNN分类器
knn = KNeighborsClassifier()
# 定义需要搜索的K值
param_grid = {'n_neighbors': [1, 3, 5, 7, 9, 11]}
# 使用GridSearchCV函数进行交叉验证和参数选择
grid_search = GridSearchCV(knn, param_grid, cv=5)
grid_search.fit(X_train, y_train)
# 输出最优的K值
print("Best K:", grid_search.best_params_)
# 使用最优的K值重新训练模型
knn = KNeighborsClassifier(n_neighbors=grid_search.best_params_['n_neighbors'])
knn.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = knn.predict(X_test)
# 输出混淆矩阵和准确率
print("Confusion matrix:")
print(confusion_matrix(y_test, y_pred))
print("Accuracy score:", accuracy_score(y_test, y_pred))
from sklearn.metrics import plot_confusion_matrix, classification_report
import matplotlib.pyplot as plt
# 输出混淆矩阵
plot_confusion_matrix(knn, X_test, y_test)
plt.title('Confusion Matrix')
plt.show()
# 输出分类报告
print(classification_report(y_test, y_pred))
# 输出准确率、召回率和F1值的可视化
from sklearn.metrics import precision_recall_fscore_support
precision, recall, f1, _ = precision_recall_fscore_support(y_test, y_pred, average='weighted')
plt.bar(['Precision', 'Recall', 'F1'], [precision, recall, f1])
plt.ylim(0, 1)
plt.title('Precision, Recall, F1 Score')
plt.show()

📢文章下方有交流学习区!一起学习进步!💪💪💪
📢首发CSDN博客,创作不易,如果觉得文章不错,可以点赞👍收藏📁评论📒
📢你的支持和鼓励是我创作的动力❗❗❗







![[Gitops--1]GitOps环境准备](https://img-blog.csdnimg.cn/92ab2f02fad146948d9e0eda8a2675c2.png)