目录
- LeNet
- 模型参数介绍
- 该网络特点
- 关于C3与S2之间的连接
- 关于最后的输出层
- 子采样
- 参考
LeNet
LeNet是一个用来识别手写数字的最经典的卷积神经网络,是Yann LeCun在1998年设计并提出的。Lenet的网络结构规模较小,但包含了卷积层、池化层、全连接层,他们都构成了现代CNN的基本组件。
网络模型结构图:

网络模型结构参数设计图:

模型参数介绍
LeNet-5 共5层:卷积层C1、C3、C5、全连接层 F6、输出层
输入:3232=1024的手写字体图片,相当于1024个神经元。这些手写字体包含0~9数字,也就是相当于10个类别的图片。3232的图像这要比Mnist数据库(caffe中的输入尺寸为28*28)中最大的字母还大。这样做的原因是希望潜在的明显特征,比如笔画断续、角点能够出现在最高层特征监测子感受野的中心。
C1层:卷积层使用6个特征卷积核,卷积核大小55,步长为1,无padding,这样我们可以得到6个特征图,然后每个特征图的大小为2828,也就是神经元的个数为62828=784。(32-5+1=28)
注:C1有156个可训练参数(每个滤波器55=25个unit参数和一个bias参数,一共6个滤波器,共(55+1)6=156个参数),共156(2828)=122,304个连接。
此处为什么要进行卷积?
卷积运算一个重要的特点就是:通过卷积运算,可以使原信号特征增强,并且降低噪音,同时不同的卷积层可以提取到图像中的不同特征,这层卷积我们就是用了6个卷积核。
S2层:MaxPooling下采样层,也就是使用最大池化进行下采样,池化的滤波器大小f选择(2,2),步长stride为2。这样我们可以得到输出大小为61414.
说明下为什么要进行下采样?
利用图像局部相关性的原理,对图像进行子抽样,可以减少数据处理量同时保留有用信息,从而降低了网络训练的参数和模型的过拟合程度
C3层:卷积层,卷积核大小55,步长为1,无padding,据此我们可以得到新的图片大小为1010,此处采用16个卷积核,所以最终输出161010。
S4层:MaxPooling下采样层,对C3的16张1010的图片进行最大池化,池化的滤波器大小f选择(2,2),步长stride为2。因此最后S4层为16张大小为55的图片。至此我们的神经元个数已经减少为:1655=400。
特征图中的每个单元与C3中相应特征图的22邻域相连接,跟C1和S2之间的连接一样。S4层有32(216)个可训练参数(每个特征图1个因子和一个偏置)和2000个连接。
C5层:将S4层的输出平铺为一个400的一维向量。然后用这400个神经元构建下一层,C5层有120个神经元。S4层的400个神经元与C5层的每一个神经元相连(C5层有120个神经元),这就是全连接层。C5层有48120个可训练连接((5516+1)*120)。
F6层:对C5层的120个神经元再添加一个全连接层,F6层含有84个神经元,之所以选这个数字的原因来自于输出层的设计。该层有10164个可训练参数((11120+1)*84=10164
输出:最后将F6层的84个神经元填充到一个SoftMax函数,得到输出长度为10的张量,张量中为1的位置代表所属类别。(例如[0,0,0,1,0,0,0,0,0,0]的张量,1在index=3的位置,故该张量代表的图片属于第三类)。
因此模型结构总体是由以下结构组成:输入->卷积->池化->卷积->池化->卷积->全链接->全链接(输出)
该网络特点
1)激活函数使用tanh
2)卷积核5x5,步长1,未使用padding
3)池化层使用最大池化MaxPooling
关于C3与S2之间的连接
C3中的每个特征图是连接到S2中的所有6个或者几个特征map的,表示本层的特征图是上一层提取到的特征map的不同组合。
这里是组合,就像人的视觉系统一样,底层的结构构成上层更抽象的结构,例如边缘构成形状或者目标的部分。
在Yann的论文中说明了C3中每个特征图与S2中哪些特征图相连,连接情况如下表所示:
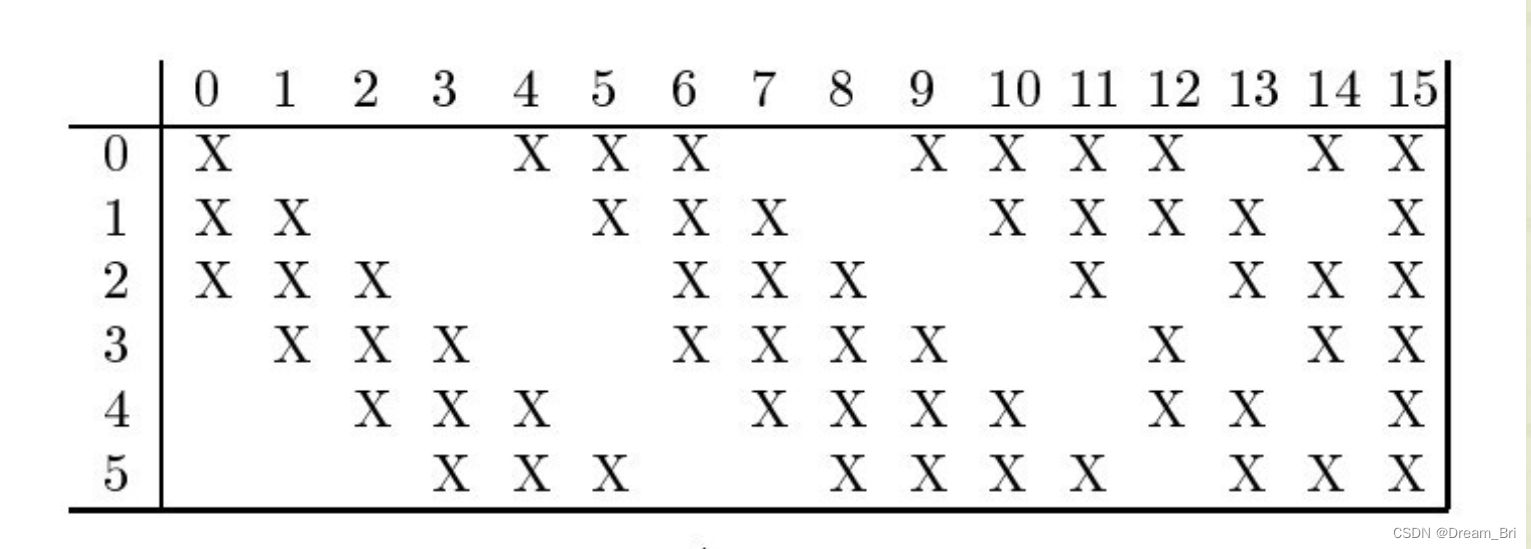
由上表可以发现C3的前6个特征图以S2中3个相邻的特征图为输入。接下来6个特征图以S2中4个相邻特征图为输入,下面的3个特征图以不相邻的4个特征图为输入。最后一个特征图以S2中所有特征图为输入。
这样C3层有1516个可训练参数((253+1)6+(254+1)9+(256+1)=1516)和151600(151610*10)个连接。
那么为什么不把S2中的每个特征图连接到每个C3的特征图呢?
原因有两个:
第一,不完全的连接机制将连接的数量保持在合理的范围内。
第二,也是最重要的,其破坏了网络的对称性。由于不同的特征图有不同的输入,所以迫使他们抽取不同的特征(希望是互补的)。
关于最后的输出层
输出层由欧式径向基函数(Euclidean Radial Basis Function)单元组成,每类一个单元,每个有84个输入。
换句话说,每个输出RBF单元计算输入向量和参数向量之间的欧式距离。输入离参数向量越远,RBF输出的越大。一个RBF输出可以被理解为衡量输入模式和与RBF相关联类的一个模型的匹配程度的惩罚项。
用概率术语来说,RBF输出可以被理解为F6层配置空间的高斯分布的负log-likelihood。给定一个输入模式,损失函数应能使得F6的配置与RBF参数向量(即模式的期望分类)足够接近。这些单元的参数是人工选取并保持固定的(至少初始时候如此)。
这些参数向量的成分被设为-1或1。虽然这些参数可以以-1和1等概率的方式任选,或者构成一个纠错码,但是被设计成一个相应字符类的7*12大小(即84)的格式化图片。这种表示对识别单独的数字不是很有用,但是对识别可打印ASCII集中的字符串很有用。
使用这种分布编码而非更常用的“1 of N”编码用于产生输出的另一个原因是,当类别比较大的时候,非分布编码的效果比较差。
原因是大多数时间非分布编码的输出必须为0。这使得用sigmoid单元很难实现。另一个原因是分类器不仅用于识别字母,也用于拒绝非字母。使用分布编码的RBF更适合该目标。因为与sigmoid不同,他们在输入空间的较好限制的区域内兴奋,而非典型模式更容易落到外边。
RBF参数向量起着F6层目标向量的角色。需要指出这些向量的成分是+1或-1,这正好在F6 sigmoid的范围内,因此可以防止sigmoid函数饱和。实际上,+1和-1是sigmoid函数的最大弯曲的点处。这使得F6单元运行在最大非线性范围内。必须避免sigmoid函数的饱和,因为这将会导致损失函数较慢的收敛和病态问题。
子采样
子采样具体过程如下:
每邻域四个像素求和变为一个像素,然后通过标量Wx+1加权,再增加偏置bx+1,然后通过一个sigmoid激活函数,产生一个大概缩小四倍的特征映射图Sx+1。
在整个网络中,S-层可看作是模糊滤波器,起到二次特征提取的作用。隐层与隐层之间空间分辨率递减,而每层所含的平面数递增,这样可用于检测更多的特征信息。
参考
https://blog.csdn.net/L888666Q/article/details/124490708
http://blog.csdn.net/qiaofangjie/article/details/16826849
https://blog.csdn.net/Chenyukuai6625/article/details/77872489