目录
- 概述
- AlexNet特点
- 激活函数
- sigmoid激活函数
- ReLu激活函数
- 数据增强
- 层叠池化
- 局部相应归一化
- Dropout
- Alexnet网络结构
- 网络结构分析
- AlexNet各层参数及其数量
- 模型框架形状结构
- 关于数据集
- 训练学习
- keras代码示例
概述
由于受到计算机性能的影响,虽然LeNet在图像分类中取得了较好的成绩,但是并没有引起很多的关注。 知道2012年,Alex等人提出的AlexNet网络在ImageNet大赛上以远超第二名的成绩夺冠,卷积神经网络乃至深度学习重新引起了广泛的关注。
Alex Krizhevsky等人训练了一个大型的卷积神经网络用来把ImageNet LSVRC-2010比赛中120万张高分辨率的图像分为1000个不同的类别。在测试卷上,获得很高准确率(top-1 and top-5 error rates of 37.5%and 17.0% ).。通过改进该网络,在2012年ImageNet LSVRC比赛中夺取了冠军,且准确率远超第二名(top-5 test error rate of 15.3%,第二名26.2%。这在学术界引起了很大的轰动,开启了深度学习的时代,虽然后来大量比AlexNet更快速更准确的卷积神经网络结构相继出现,但是AlexNet作为开创者依旧有着很多值得学习参考的地方,它为后续的CNN甚至是R-CNN等其他网络都定下了基调,所以下面我们将从AlexNet入手,理解卷积神经网络的一般结构。
AlexNet特点
AlexNet网络包括了6000万个参数和65000万个神经元,5个卷积层,在一些卷积层后面还有池化层,3个全连接层,输出为softmax层。
AlexNet是在LeNet的基础上加深了网络的结构,学习更丰富更高维的图像特征。AlexNet的特点:
1、更深的网络结构
2、使用层叠的卷积层,即卷积层+卷积层+池化层来提取图像的特征
3、使用Dropout抑制过拟合
4、使用数据增强Data Augmentation抑制过拟合
5、使用Relu替换之前的sigmoid的作为激活函数
6、多GPU训练
激活函数
在最初的感知机模型中,输入和输出的关系如下:
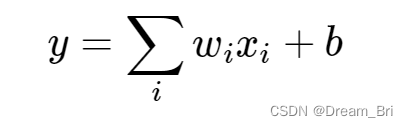
上面函数式只是单纯的线性关系,这样的网络结构有很大的局限性。即使用很多这样结构的网络层叠加,其输出和输入仍然是线性关系,无法处理有非线性关系的输入输出。

因此,对每个神经元的输出做个非线性的转换也就是,将上面就加权求和的结果输入到一个非线性函数,也就是激活函数中。 这样,由于激活函数的引入,多个网络层的叠加就不再是单纯的线性变换,而是具有更强的表现能力。
sigmoid激活函数
在最初,sigmoid和tanh函数最常用的激活函数。
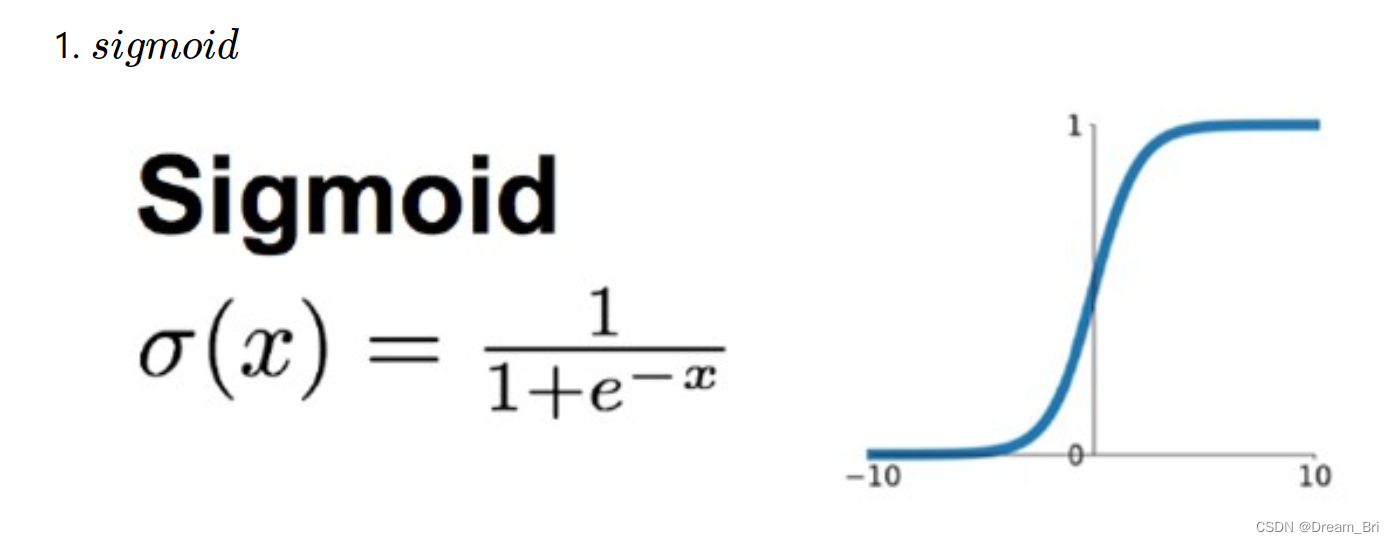
在网络层数较少时,sigmoid函数的特性能够很好的满足激活函数的作用:它把一个实数压缩至0到1之间,当输入的数字非常大的时候,结果会接近1;当输入非常大的负数时,则会得到接近0的结果。
这种特性,能够很好的模拟神经元在受刺激后,是否被激活向后传递信息(输出为0,几乎不被激活;输出为1,完全被激活)。
sigmoid一个很大的问题就是梯度饱和。 观察sigmoid函数的曲线,当输入的数字较大(或较小)时,其函数值趋于不变,其导数变的非常的小。这样,在层数很多的的网络结构中,进行反向传播时,由于很多个很小的sigmoid导数累成,导致其结果趋于零,更新速度更慢。
ReLu激活函数
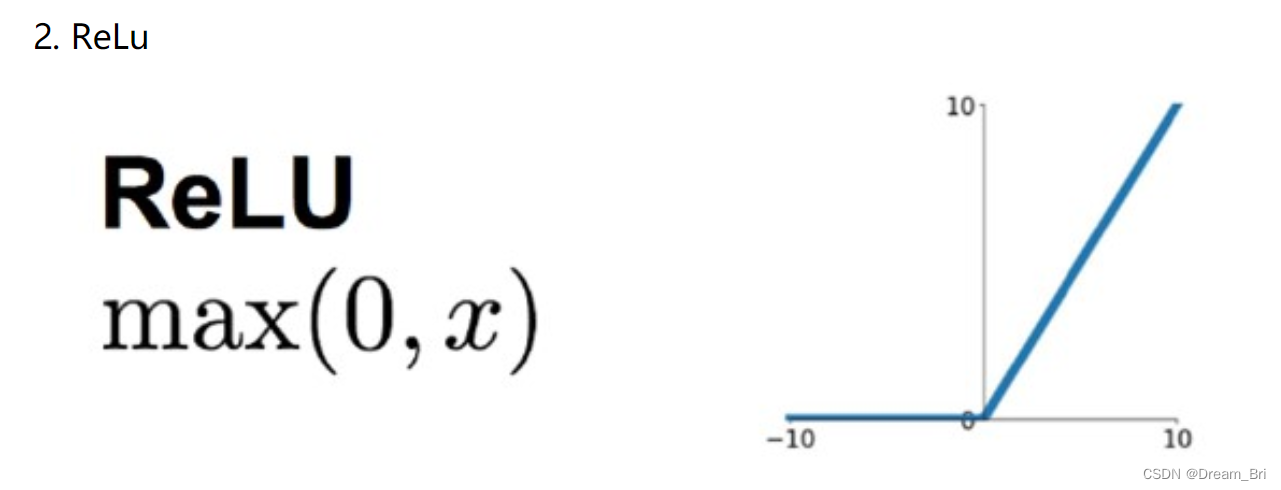
针对sigmoid梯度饱和导致训练收敛慢的问题,在AlexNet中引入了ReLU。ReLU是一个分段线性函数,小于等于0则输出为0;大于0的则恒等输出。
相比于sigmoid,ReLU有以下优点:
1、计算开销下:sigmoid的正向传播有指数运算,倒数运算,而ReLu是线性输出;反向传播中,sigmoid有指数运算,而ReLU有输出的部分,导数始终为1;
2、梯度饱和问题;
3、稀疏性:Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
这里有个问题,前面提到,激活函数要用非线性的,是为了使网络结构有更强的表达的能力。那这里使用ReLU本质上却是个线性的分段函数,是怎么进行非线性变换的。
这里把神经网络看着一个巨大的变换矩阵M,其输入为所有训练样本组成的矩阵A,输出为矩阵B,则有:B=M⋅A。这里的M是一个线性变换的话,则所有的训练样本A进行了线性变换输出为B。
那么对于ReLU来说,由于其是分段的,0的部分可以看着神经元没有激活,不同的神经元激活或者不激活,其神经玩过组成的变换矩阵是不一样的。
设有两个训练样本 a1,a2,其训练时神经网络组成的变换矩阵为M1,M2。 由于M1变换对应的神经网络中激活神经元和M2是不一样的,这样M1,M2实际上是两个不同的线性变换。也就是说,每个训练样本使用的线性变换矩阵Mi是不一样的,在整个训练样本空间来说,其经历的是非线性变换。
简单来说,不同训练样本中的同样的特征,在经过神经网络学习时,流经的神经元是不一样的(激活函数值为0的神经元不会被激活)。这样,最终的输出实际上是输入样本的非线性变换。
单个训练样本是线性变换,但是每个训练样本的线性变换是不一样的,这样整个训练样本集来说,就是非线性的变换。
数据增强
神经网络由于训练的参数多,表能能力强,所以需要比较多的数据量,不然很容易过拟合。当训练数据有限时,可以通过一些变换从已有的训练数据集中生成一些新的数据,以快速地扩充训练数据。对于图像数据集来说,可以对图像进行一些形变操作:翻转、随机裁剪、平移、颜色光照的变换…
AlexNet中对数据做了以下操作:
1、随机裁剪,对256×256的图片进行随机裁剪到227×227,然后进行水平翻转。
2、测试的时候,对左上、右上、左下、右下、中间分别做了5次裁剪,然后翻转,共10个裁剪,之后对结果求平均。
3、对RGB空间做PCA(主成分分析),然后对主成分做一个(0, 0.1)的高斯扰动,也就是对颜色、光照作变换,结果使错误率又下降了1%。
层叠池化
在LeNet中池化是不重叠的,即池化的窗口的大小和步长是相等的。
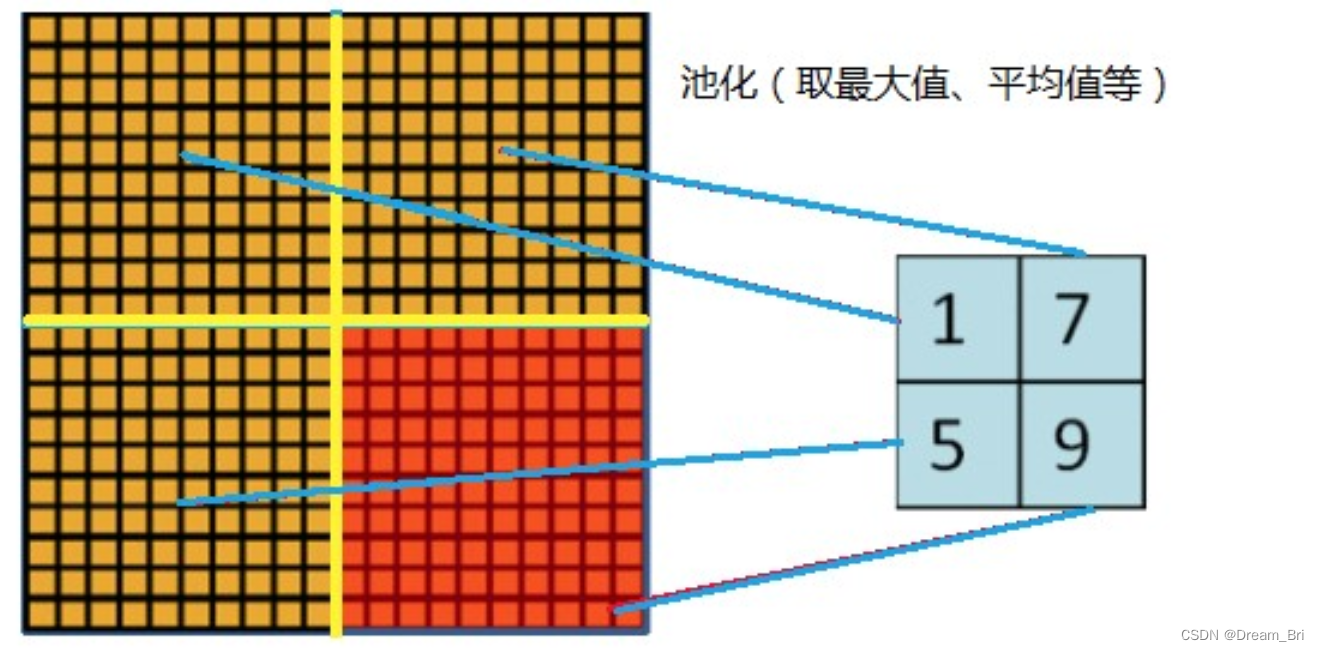
在AlexNet中使用的池化(Pooling)却是可重叠的,也就是说,在池化的时候,每次移动的步长小于池化的窗口长度。AlexNet池化的大小为3×3的正方形,每次池化移动步长为2,这样就会出现重叠。重叠池化可以避免过拟合,这个策略贡献了0.3%的Top-5错误率。与非重叠方案s=2,z=2相比,输出的维度是相等的,并且能够在一定程度上抑制过拟合。
局部相应归一化

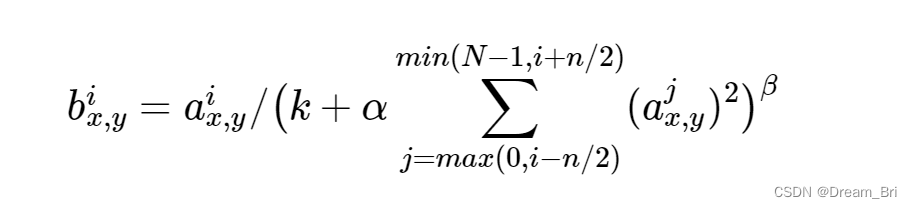

Dropout
这个是比较常用的抑制过拟合的方法了。
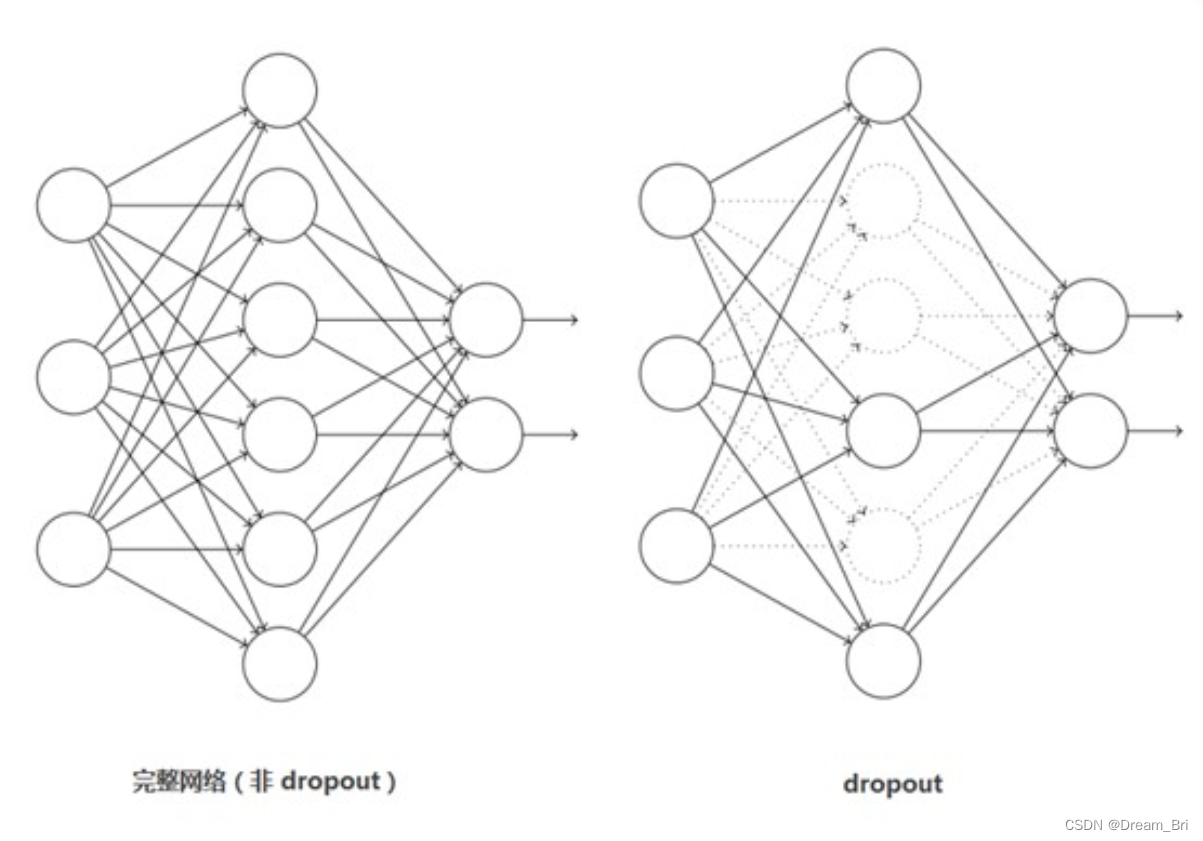
引入Dropout主要是为了防止过拟合。在神经网络中Dropout通过修改神经网络本身结构来实现,对于某一层的神经元,通过定义的概率将神经元置为0,这个神经元就不参与前向和后向传播,就如同在网络中被删除了一样,同时保持输入层与输出层神经元的个数不变,然后按照神经网络的学习方法进行参数更新。在下一次迭代中,又重新随机删除一些神经元(置为0),直至训练结束。
Dropout应该算是AlexNet中一个很大的创新,现在神经网络中的必备结构之一。Dropout也可以看成是一种模型组合,每次生成的网络结构都不一样,通过组合多个模型的方式能够有效地减少过拟合,Dropout只需要两倍的训练时间即可实现模型组合(类似取平均)的效果,非常高效。如下图:
Alexnet网络结构
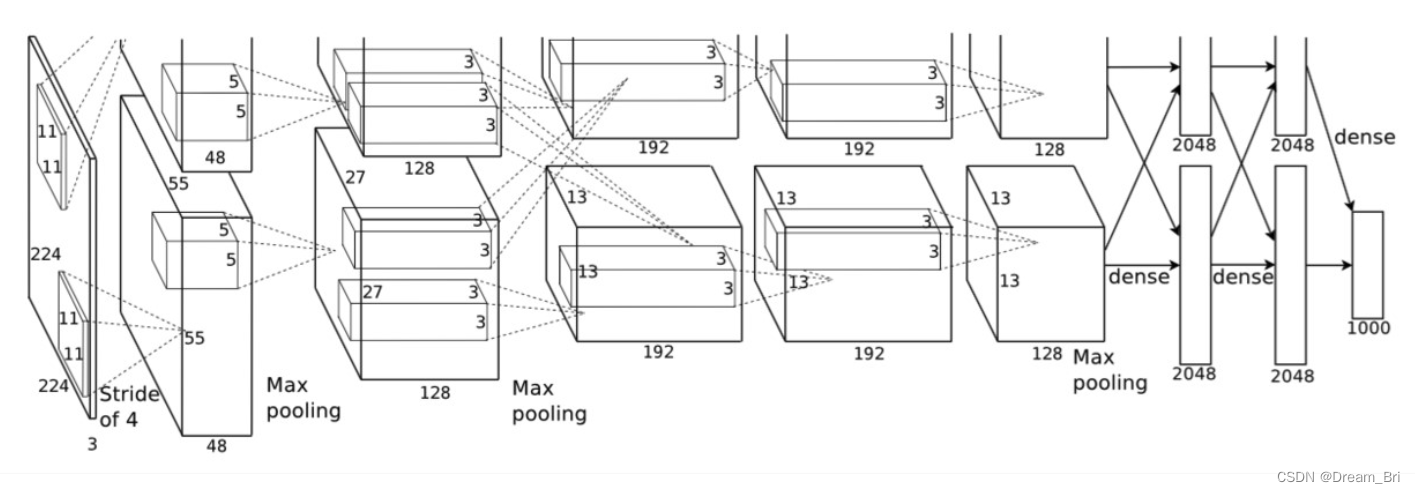
网络包含8个带权重的层;前5层是卷积层,剩下的3层是全连接层。最后一层全连接层的输出是1000维softmax的输入,softmax会产生1000类标签的分布网络包含8个带权重的层;前5层是卷积层,剩下的3层是全连接层。最后一层全连接层的输出是1000维softmax的输入,softmax会产生1000类标签的分布。
从图上可以明显看到网络结构分为上下两侧,这是因为网络分布在两个GPU上,这主要是因为NVIDIA GTX 580 GPU只用3GB内存,装不下那么大的网络。
需要说明的是,虽然AlexNet网络都用上图的结构来表示,但是其实输入图像的尺寸不是224x224x3,而应该是227x227x3,大家可以用244的尺寸推导下,会发现边界填充的结果是小数,这显然是不对的,在这里就不做推导了。
AlexNet各个层的参数和结构如下:
输入层:227x227x3
C1:96x11x11x3 (卷积核个数/高/宽/深度)
C2:256x5x5x48(卷积核个数/高/宽/深度)
C3:384x3x3x256(卷积核个数/高/宽/深度)
C4:384x3x3x192(卷积核个数/高/宽/深度)
C5:256x3x3x192(卷积核个数/高/宽/深度)
网络结构分析
1、卷积层C1
该层的处理流程是: 卷积–>ReLU–>池化–>归一化。
卷积,输入是227×227,使用96个11×11×3的卷积核,得到的FeatureMap为55×55×96。
ReLU,将卷积层输出的FeatureMap输入到ReLU函数中。
池化,使用3×3步长为2的池化单元(重叠池化,步长小于池化单元的宽度),输出为27×27×96((55−3)/2+1=27)
局部响应归一化,使用k=2,n=5,α=10−4,β=0.75进行局部归一化,输出的仍然为27×27×96,输出分为两组,每组的大小为27×27×48
2、卷积层C2
该层的处理流程是:卷积–>ReLU–>池化–>归一化
卷积,输入是2组27×27×48。使用2组,每组128个尺寸为5×5×48的卷积核,并作了边缘填充padding=2,卷积的步长为1. 则输出的FeatureMap为2组,每组的大小为2727128. ((27+2∗2−5)/1+1=27)
ReLU,将卷积层输出的FeatureMap输入到ReLU函数中
池化运算的尺寸为3×3,步长为2,池化后图像的尺寸为(27−3)/2+1=13,输出为13×13×256
局部响应归一化,使用k=2,n=5,α=10−4,β=0.75进行局部归一化,输出的仍然为13×13×256,输出分为2组,每组的大小为13×13×128
3、卷积层C3
该层的处理流程是: 卷积–>ReLU
卷积,输入是13×13×256,使用2组共384尺寸为3×3×256的卷积核,做了边缘填充padding=1,卷积的步长为1.则输出的FeatureMap为1313384
ReLU,将卷积层输出的FeatureMap输入到ReLU函数中
4、卷积层C4
该层的处理流程是: 卷积–>ReLU
该层和C3类似。
卷积,输入是13×13×384,分为两组,每组为13×13×192.使用2组,每组192个尺寸为3×3×192的卷积核,做了边缘填充padding=1,卷积的步长为1.则输出的FeatureMap为13×13 times384,分为两组,每组为13×13×192
ReLU,将卷积层输出的FeatureMap输入到ReLU函数中
5、卷积层C5
该层处理流程为:卷积–>ReLU–>池化
卷积,输入为13×13×384,分为两组,每组为13×13×192。使用2组,每组为128尺寸为3×3×192的卷积核,做了边缘填充padding=1,卷积的步长为1.则输出的FeatureMap为13×13×256
ReLU,将卷积层输出的FeatureMap输入到ReLU函数中
池化,池化运算的尺寸为3×3,步长为2,池化后图像的尺寸为 (13−3)/2+1=6,即池化后的输出为6×6×256
6、全连接层FC6
该层的流程为:(卷积)全连接 -->ReLU -->Dropout
卷积->全连接: 输入为6×6×256,该层有4096个卷积核,每个卷积核的大小为6×6×256。由于卷积核的尺寸刚好与待处理特征图(输入)的尺寸相同,即卷积核中的每个系数只与特征图(输入)尺寸的一个像素值相乘,一一对应,因此,该层被称为全连接层。由于卷积核与特征图的尺寸相同,卷积运算后只有一个值,因此,卷积后的像素层尺寸为4096×1×1,即有4096个神经元。
ReLU,这4096个运算结果通过ReLU激活函数生成4096个值
Dropout,抑制过拟合,随机的断开某些神经元的连接或者是不激活某些神经元
7、全连接层FC7
流程为:全连接–>ReLU–>Dropout
全连接,输入为4096的向量
ReLU,这4096个运算结果通过ReLU激活函数生成4096个值
Dropout,抑制过拟合,随机的断开某些神经元的连接或者是不激活某些神经元
8、输出层
第七层输出的4096个数据与第八层的1000个神经元进行全连接,经过训练后输出1000个float型的值,这就是预测结果。
AlexNet各层参数及其数量
卷积层的参数 = 卷积核的数量 * 卷积核 + 偏置
C1: 96个11×11×3的卷积核,96×11×11×3+96=34848
C2: 2组,每组128个5×5×48的卷积核,(128×5×5×48+128)×2=307456
C3: 384个3×3×256的卷积核,3×3×256×384+384=885120
C4: 2组,每组192个3×3×192的卷积核,(3×3×192×192+192)×2=663936
C5: 2组,每组128个3×3×192的卷积核,(3×3×192×128+128)×2=442624
FC6: 4096个6×6×256的卷积核,6×6×256×4096+4096=37752832
FC7: 4096∗4096+4096=16781312
output: 4096∗1000=4096000
卷积层 C2,C4,C5中的卷积核只和位于同一GPU的上一层的FeatureMap相连。从上面可以看出,参数大多数集中在全连接层,在卷积层由于权值共享,权值参数较少。
模型框架形状结构
由于AlexNet是使用两块显卡进行训练的,其网络结构的实际是分组进行的。并且,在C2,C4,C5上其卷积核只和上一层的同一个GPU上的卷积核相连。 对于单显卡来说,并不适用,本文基于Keras的实现,忽略其关于双显卡的的结构,并且将局部归一化
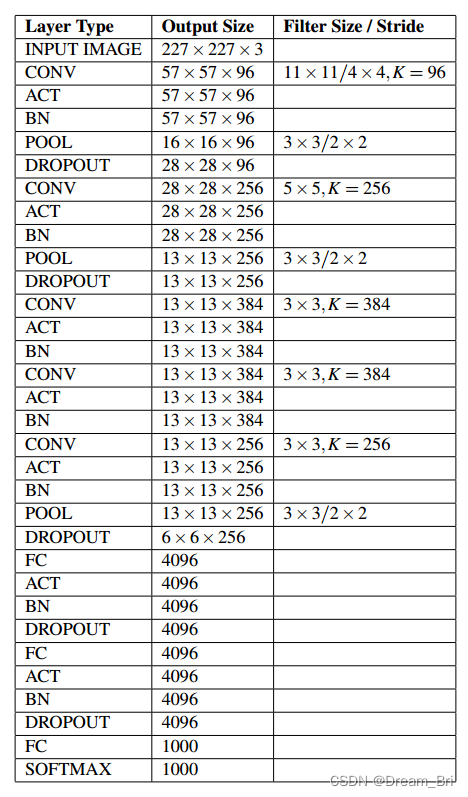
关于数据集
实验采用的数据集是ImageNet。ImageNet是超过1500万个标记的高分辨率图像的数据集,大约有22,000个类别。这些图像是从网上收集的,并使用亚马逊的Mechanical Turk众包服务进行了标记。
从2010年开始,举办ILSVRC比赛,数据使用的是ImageNet的 一个子集,每个类别大约有1000个图像,总共有1000个类别。总共有大约120万个训练图像,50000个验证图像,以及150000个测试图像。ImageNet比赛给出两个错误率,top-1和top-5,top-5错误率是指你的模型预测的概率最高的5个类别中都不包含正确的类别。
ImageNet由可变分辨率的图像组成,而神经网络输入维度是固定的。 因此,我们将图像下采样到256×256的固定分辨率矩形图像,我们首先重新缩放图像,使短边长度为256,然后从结果图像中裁剪出中心256×256的图片。 我们没有预先处理图像以任何其他方式,我们在像素的原始RGB值上训练了我们的网络。
训练学习
该模型训练使用了随机梯度下降法,每批图片有180张,权重更新公式如下:

其中i是迭代的索引,v是动量,0.9是动量参数,ε是学习率,0.0005是权重衰减系数,在这里不仅起到正则化的作用,而且减少了模型的训练误差。
所有的权重都采用均值为0,方差为0.01的高斯分布进行初始化。第2,4,5卷积层和所有全连接层的偏置都初始化为1,其他层的偏置初始化为0.学习率ε=0.01,所有层都使用这个学习率,在训练过程中,当错误率不在下降时,将学习率除以10,在终止训练之前减少3次,我们把120万张图片训练了90遍,总过花费了5到6天。
keras代码示例
class AlexNet:
@staticmethod
def build(width,height,depth,classes,reg=0.0002):
model = Sequential()
inputShape = (height,width,depth)
chanDim = -1
if K.image_data_format() == "channels_first":
inputShape = (depth,height,width)
chanDim = 1
model.add(Conv2D(96,(11,11),strides=(4,4),input_shape=inputShape,padding="same",kernel_regularizer=l2(reg)))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(3,3),strides=(2,2)))
model.add(Dropout(0.25))
model.add(Conv2D(256,(5,5),padding="same",kernel_regularizer=l2(reg)))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(3,3),strides=(2,2)))
model.add(Dropout(0.25))
model.add(Conv2D(384,(3,3),padding="same",kernel_regularizer=l2(reg)))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(384,(3,3),padding="same",kernel_regularizer=l2(reg)))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(256,(3,3),padding="same",kernel_regularizer=l2(reg)))
model.add(MaxPooling2D(pool_size=(3,3),strides=(2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(4096,kernel_regularizer=l2(reg)))
model.add(Activation("relu"))
model.add(BatchNormalization())
model.add(Dropout(0.25))
model.add(Dense(4096,kernel_regularizer=l2(reg)))
model.add(Activation("relu"))
model.add(BatchNormalization())
model.add(Dropout(0.25))
model.add(Dense(classes,kernel_regularizer=l2(reg)))
model.add(Activation("softmax"))
return model
参考:
https://blog.csdn.net/lcczzu/article/details/91991725
https://www.cnblogs.com/wangguchangqing/p/10333370.html
https://www.cnblogs.com/zyly/p/8781224.html
https://blog.csdn.net/chaipp0607/article/details/72847422