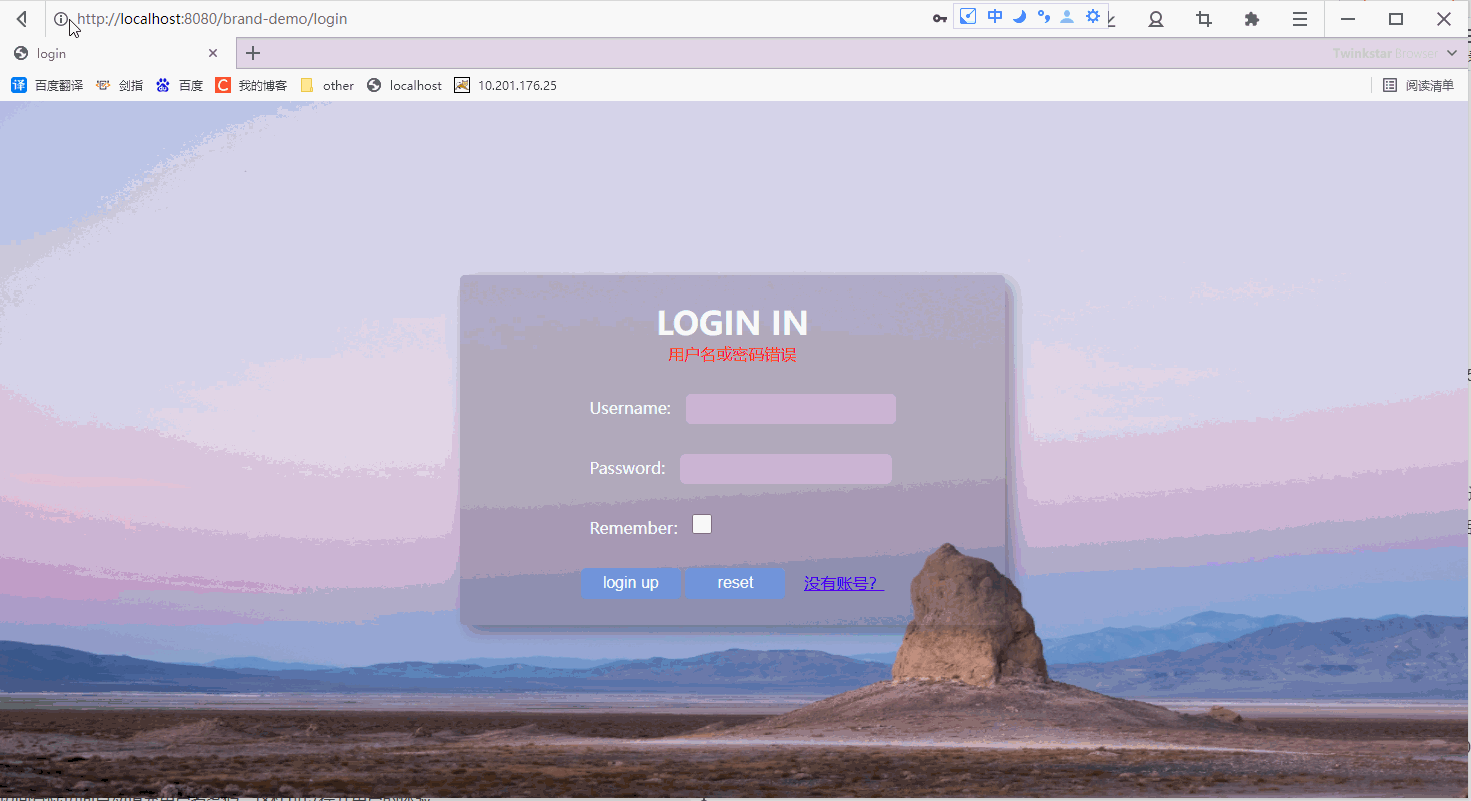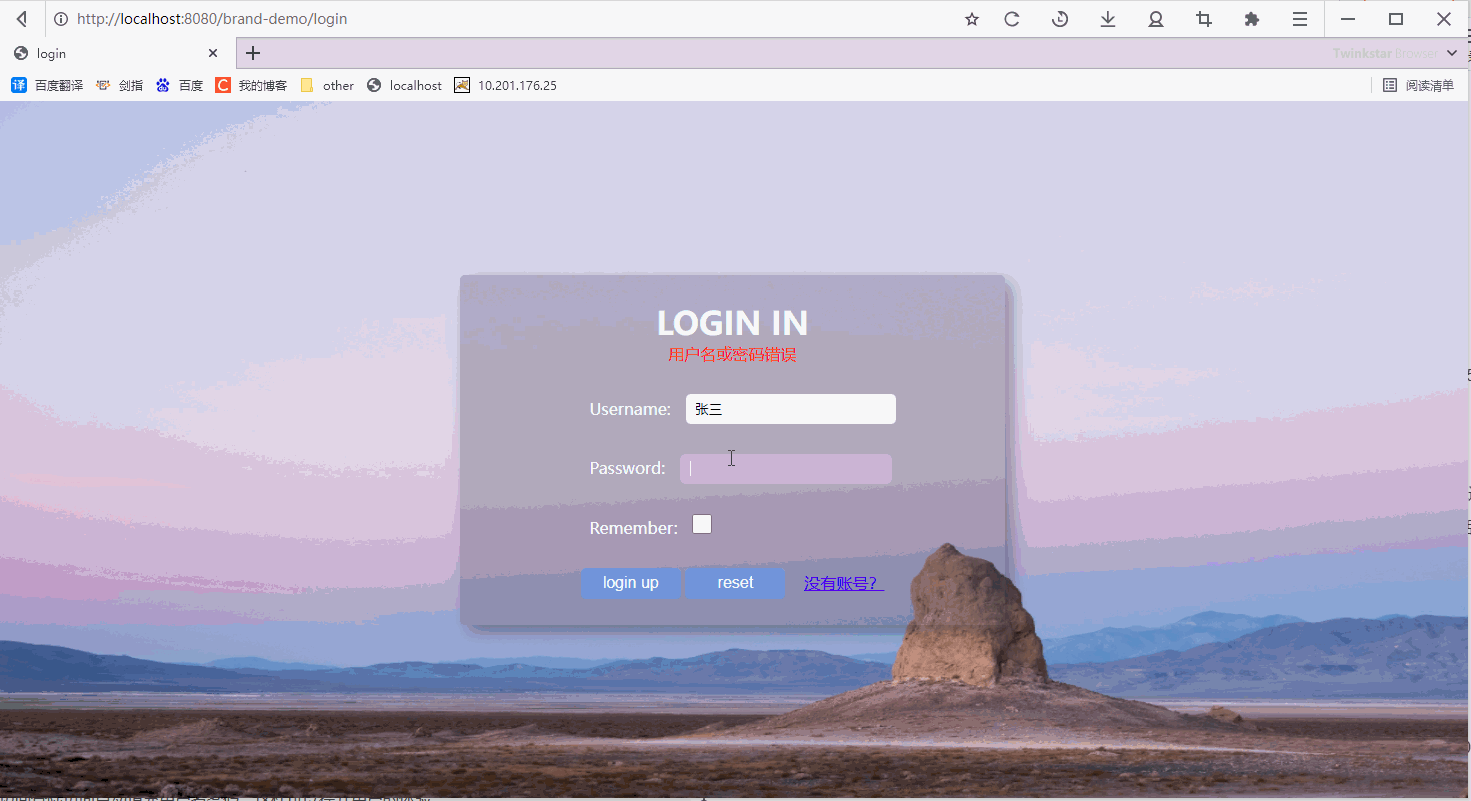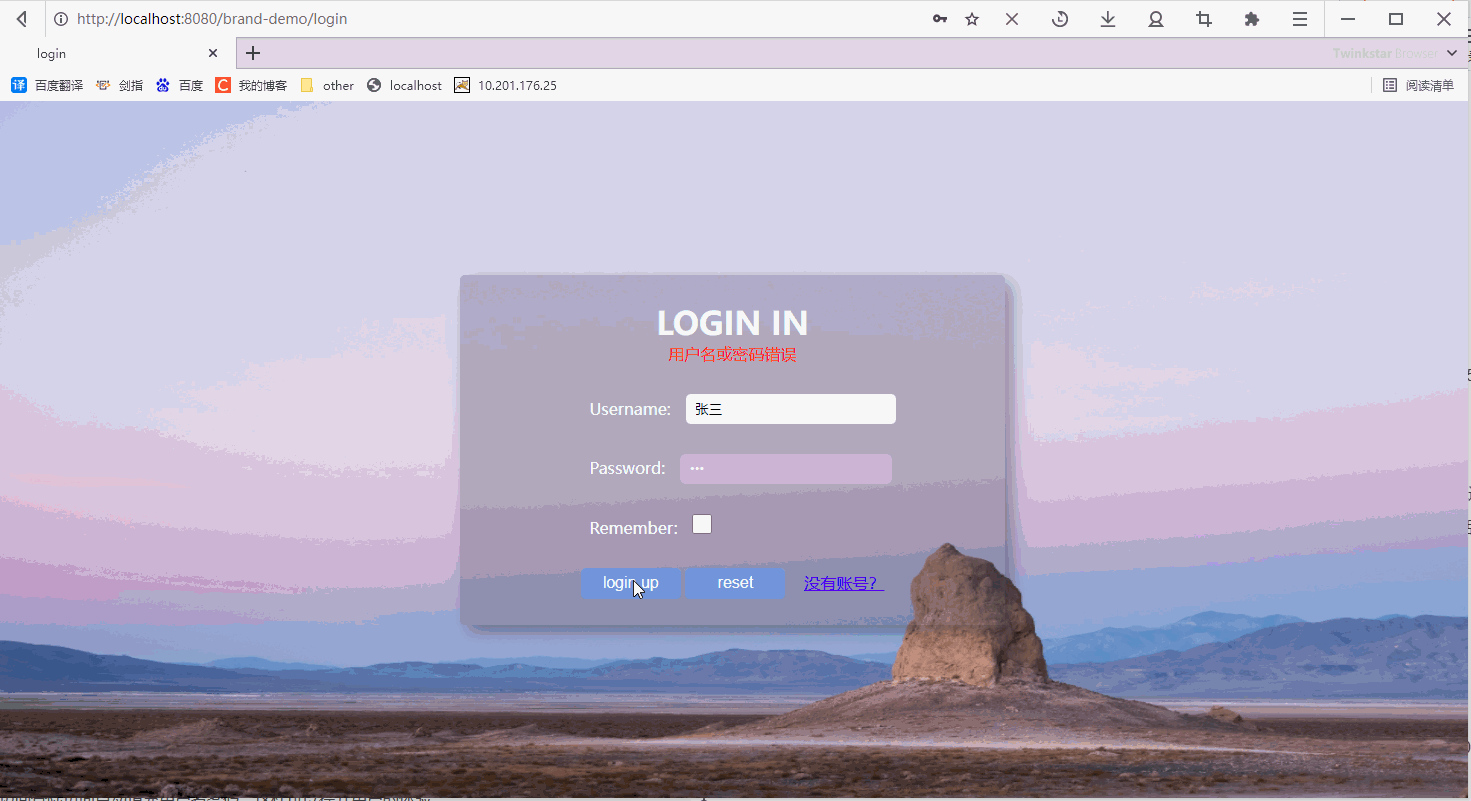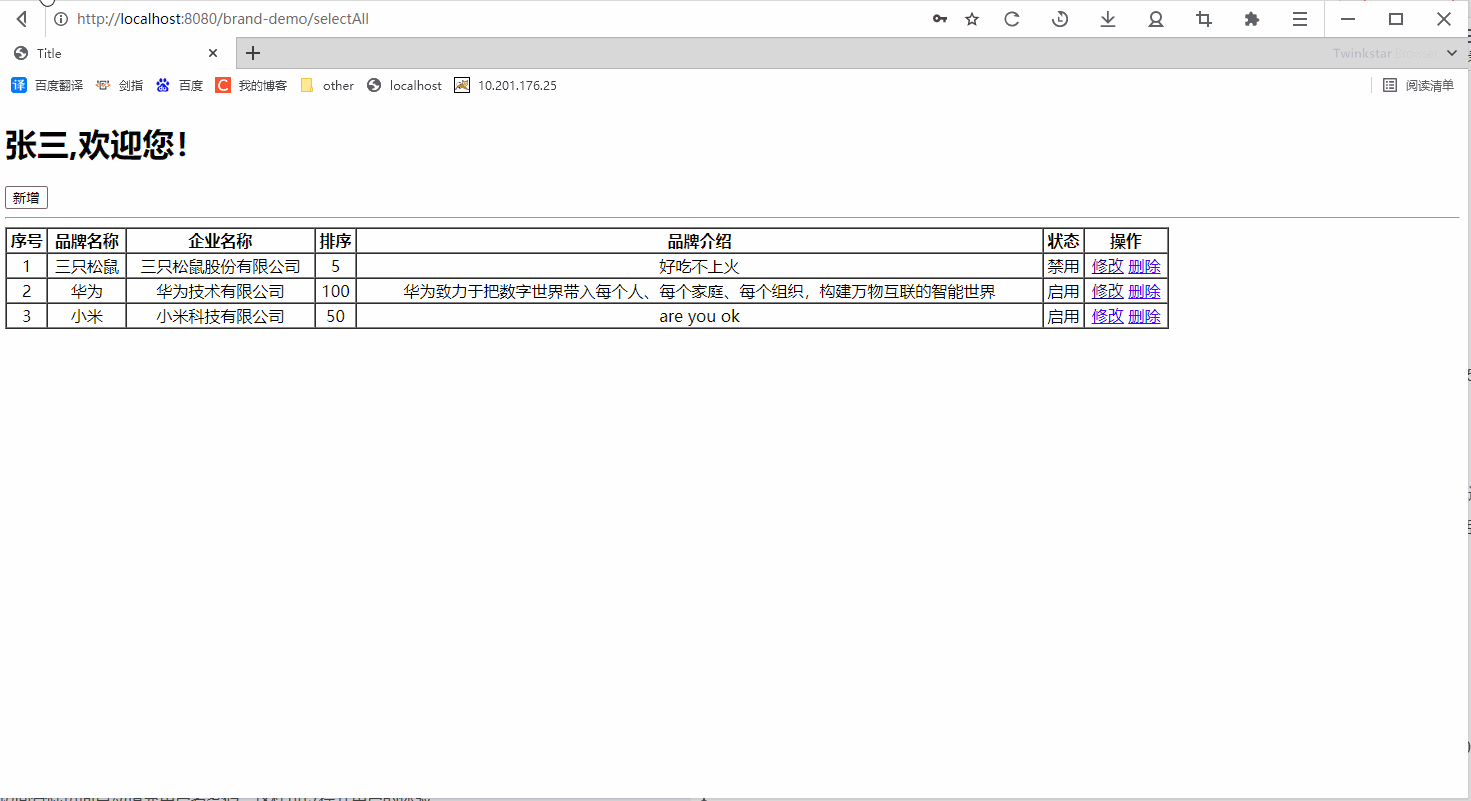
数据排序
1,全局排序(order by):类似于标准SQL,只使用一个Reducer执行全局数据排序;速度慢,应提前做好数据过滤 ;支持使用case when或表达式;支持按位置编号排序
desc升序,asc降序,不写desc和asc情况下,就是默认asc降序排列
select * from t_window order by cost;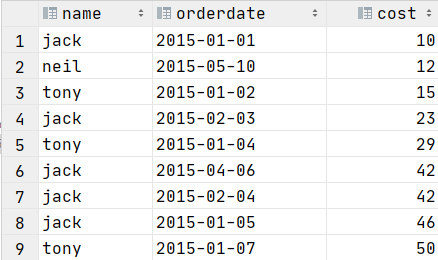
2,每个reduce内部排序(sort by):对于大规模的数据集 order by 的效率非常低。在很多情况下,并不需要全局排序,此时可以使用 sort by。
//设置reduce个数为3个,当个数设置为1的时候,等于全局排序order by
set mapreduce.job.reduces=3;
//查看设置reduce个数
set mapreduce.job.reduces;3,分区排序(distribute by):在有些情况下,我们需要控制某个特定行应该到哪个 reducer,通常是为了进行后续的聚集操作。
注:distribute by 的分区规则是根据分区字段的 hash 码与 reduce 的个数进行模除后,余数相同的分到一个区。
Hive 要求 DISTRIBUTE BY 语句要写在 SORT BY 语句之前
//设置reduce个数
set mapreduce.job.reduces=3;
//先按日期分区,再按金额降序
select * from t_window distribute by orderdate sort by cost desc;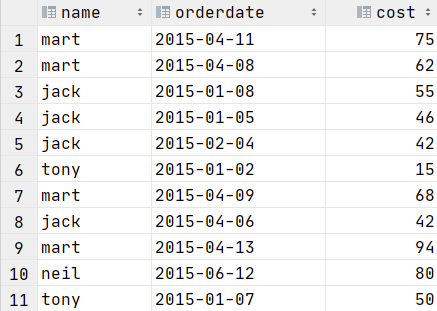
4,簇排序(cluster by):当 distribute by 和 sorts by 字段相同时,可以使用 cluster by 方式。
cluster by 除了具有 distribute by 的功能外还兼具 sort by 的功能。但是排序只能是升序排序,不能指定排序规则为 asc 或者 desc。
cluster by = distribute by +sort by
select * from t_window cluster by cost
select * from t_window distribute by orderdate sort by cost desc;窗口函数
窗口函数简单的说就是在执行聚合函数的时候指定一个操作窗口,这个窗口由over来进行控制。接下来重点介绍一下over()函数。
over():指定分析函数工作的数据窗口大小,这个大小可能会随着行的变化而变化。
基本语法如下:<分析函数> over ( partition by <分组> order by <排序> desc/asc rows between 开始行 and 结束行 )
preceding:往前;following: 往后;current row:当前行;
unbounded :起点(一般结合preceding,following使用);
unbounded preceding: 表示该窗口最前面的行(起点);
unbounded following:该窗口最后面的行(终点)
rows between unbounded preceding and current row --(表示从窗口起点到当前行)
rows between unbounded preceding and unbounded following--(表示从窗口起点到终点)
rows between 2 preceding and 1 following --(表示往前2行到往后1行)
rows between 2 preceding and 1 current row --(表示往前两行到当前行)
rows between current row and unbounded following --(表示当前行到终点)案例
数据:字段分别为name,orderdate,cost
jack,2015-01-01,10
tony,2015-01-02,15
jack,2015-02-03,23
tony,2015-01-04,29
jack,2015-01-05,46
jack,2015-04-06,42
tony,2015-01-07,50
jack,2015-01-08,55
mart,2015-04-08,62
mart,2015-04-09,68
neil,2015-05-10,12
mart,2015-04-11,75
neil,2015-06-12,80
mart,2015-04-13,94
聚合函数+over
count(),sum(),max(),min(),avg()……over()
//方法一
select distinct name, count(*) over ()
from orders
where substring(orderdate, 1, 7) = '2015-04';
//方法二
select name, count(*) over ()
from orders
where substring(orderdate, 1, 7) = '2015-04'
group by name;
注:group by 有去重效果序列函数
ntile(n):用于将分组数据按照顺序切分成n片,返回当前切片值
select name,
orderdate,
cost,
-- 全局数据切片
ntile(5) over () as row1,
-- 按照name进行分组,在分组内将数据切成3份
ntile(3) over (partition by name) as row2,
-- 全局按照name升序排列,数据切成3份
ntile(3) over (order by name ) as row3,
-- 按照name分组,在分组内按照cost升序排列,数据切成3份
ntile(3) over (partition by name order by cost desc ) as row4
from orders;排名函数:rank(),dense_rank(),row_number()
rank() | 生成数据项在分组中的排名,排名相等会在名次中留下空位 |
dense_rank() | 生成数据项在分组中的排名,排名相等会在名次中不会留下空位 |
row_number() | 从1开始,按照顺序,生成分组内记录的序列,不会存在重复,当排序的值相同时,按照表中记录的顺序进行排列 |
select name,
orderdate,
cost,
row_number() over (partition by name order by cost desc ) as row1,
rank() over (partition by name order by cost desc ) as row2,
dense_rank() over (partition by name order by cost desc ) as row3
from orders;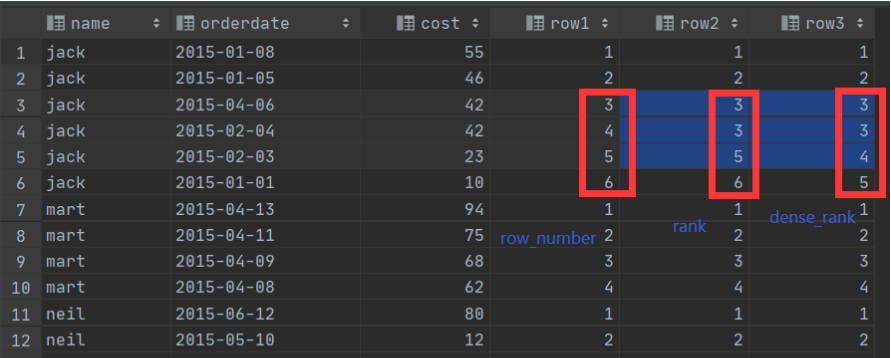
lag():分区内滞后当前行的参数值
lead():分区内当前行前导行的参数值
select name,
cost,
lag(orderdate, 1, '1900-01-01') over (partition by name order by orderdate) as row1,
orderdate,
lead(orderdate) over (partition by name order by orderdate) as row2
from orders;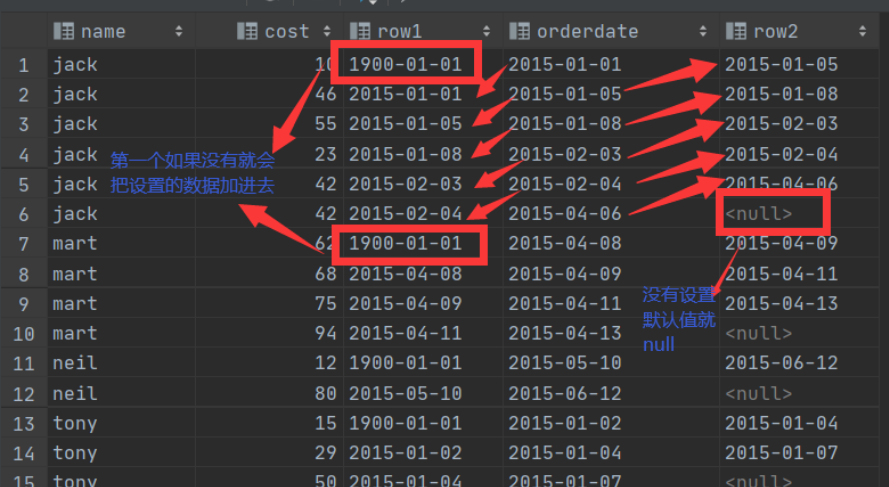
first_value取分组内排序后,截止到当前行,第一个值
last_value取分组内排序后,截止到当前行,最后一个值
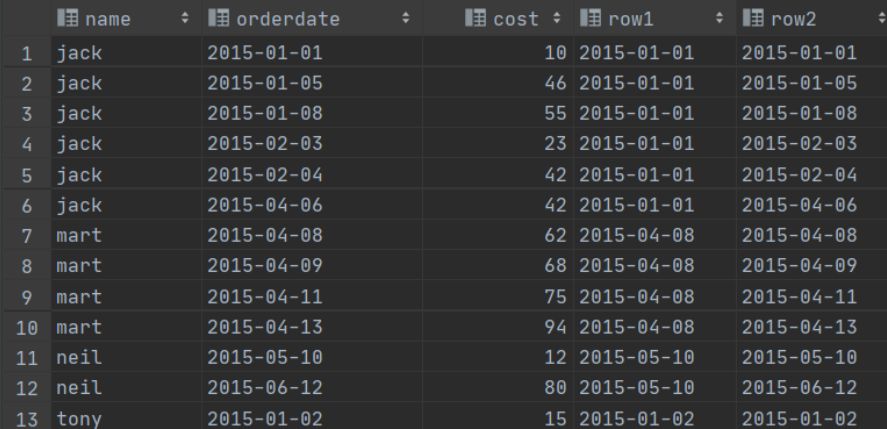
select name,
orderdate,
cost,
first_value(orderdate) over (partition by name order by orderdate) as row1,
last_value(orderdate) over (partition by name order by orderdate) as row2
from orders;