文章目录
- 一、Set
- 1. 概述
- 2. 哈希值
- 3. 元素唯一性
- 4. 哈希表
- 5. 遍历学生对象
- 6. LinkedHashSet
- 7. TreeSet
- 7.1 自然排序
- 7.2 比较器排序
- 8. 不重复的随机数
- 二、泛型
- 1. 概述
- 2. 泛型类
- 3. 泛型方法
- 4. 泛型接口
- 5. 类型通配符
- 6. 可变参数
- 7. 可变参数的使用
一、Set
1. 概述
Set 集合特点:
① 不包含重复元素的集合;
② 没有带索引的方法,所以不能使用普通 for 循环遍历;
③ HashSet 是 Set 的一个实现类,HashSet 对集合的迭代顺序不作任何保证,输出的元素可能是乱序的。
//Test.java
package com.an;
import java.util.HashSet;
import java.util.Set;
public class Test {
public static void main(String[] args) {
Set<String> set = new HashSet<String>();
set.add("a");
set.add("b");
set.add("c");
set.add("c");
for (String s : set) {
System.out.println(s);
}
}
}

可以看到当出现重复的元素时,控制台只会输出一个!
2. 哈希值
哈希值是 JDK 根据对象的地址或者字符串或者数字算出来的 int 类型的数值。
Object 类中有一个方法可以获取到对象的哈希值:
public int hashCode(); //返回对象的哈希码值
//Test.java
package com.an;
public class Test {
public static void main(String[] args) {
Student s1 = new Student("刘德华", 50);
System.out.println(s1.hashCode());
System.out.println(s1.hashCode());
Student s2 = new Student("张学友", 53);
System.out.println(s2.hashCode());
}
}
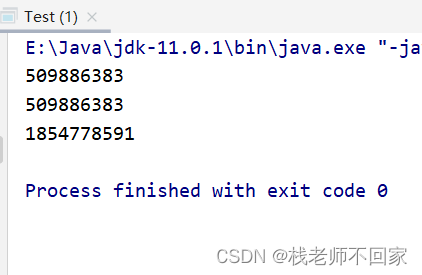
同一个对象多次调用 hashCode() 方法返回的哈希值是相同的,不同对象的哈希值在默认情况下是不相同的!
通过方法重写,可以使不同的对象拥有相同的哈希值:
@Override
public int hashCode() {
return Objects.hash(name, age);
}
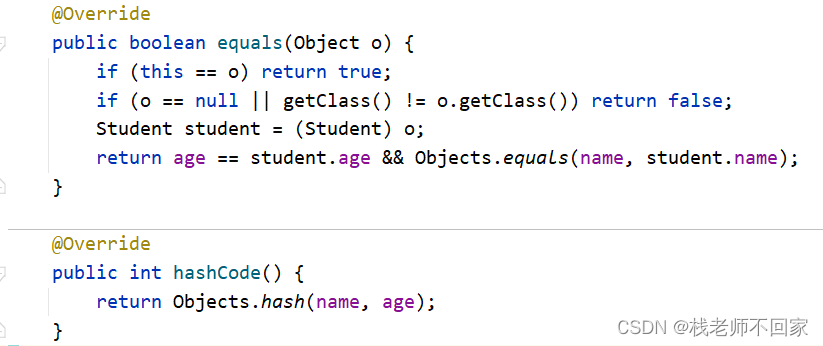
在学生类里面 Alt + Insert,equals() and hasCode(),一直按下一步,这里会自动帮我们生成 equals() 方法和 hasCode() 方法,equals() 方法就是我们前面常用 API 里面讲过的用于比较两个对象是否相等,hasCode() 方法即可使不同的对象拥有相同的哈希值,return 后面的内容自定义。
3. 元素唯一性
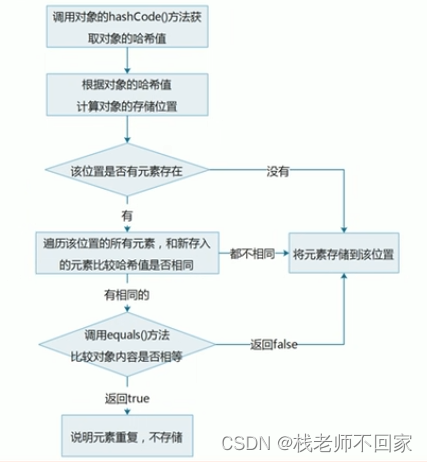
HashSet 集合存储元素要保证元素的唯一性,就需要重写 equals() 方法和 hasCode() 方法!
4. 哈希表
JDK8 之前,底层采用数组+链表实现,可以说是一个元素为链表的数组;JDK8 以后,在长度比较长的时候,底层实现了优化。
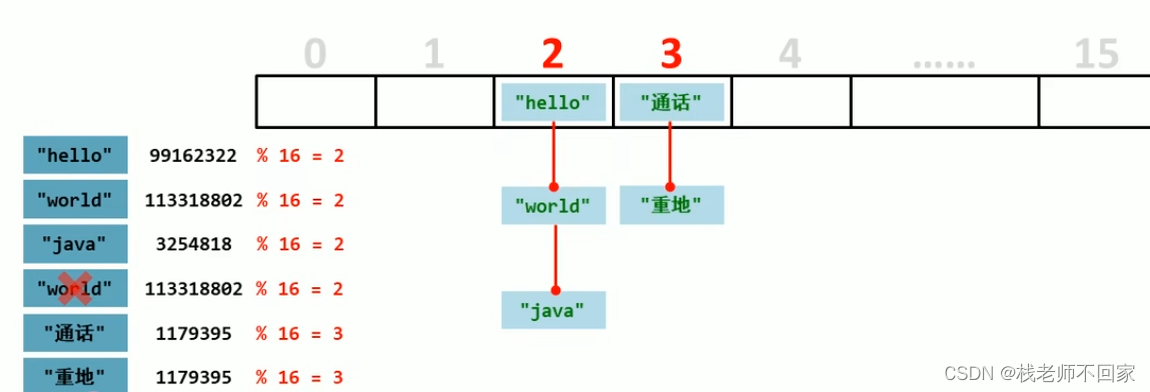
① 存储地址即哈希值对 16 取余;
② 当存储地址相同时,先比较哈希值,哈希值不同直接存储;
③ 哈希值相同时,比较存储内容,存储内容不同直接存储,内容相同则不存储。
5. 遍历学生对象
需求:创建一个存储学生对象的集合,存储多个学生对象,使用程序实现在控制台遍历该集合,当学生对象的成员变量值相同时,我们就认为是同一个对象。
//Student.java
package com.an;
import java.util.Objects;
public class Student {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return 2;
}
}
//Test.java
package com.an;
import java.util.HashSet;
public class Test {
public static void main(String[] args) {
Student s1 = new Student("刘德华", 50);
Student s2 = new Student("张学友", 53);
Student s3 = new Student("周杰伦", 46);
Student s4 = new Student("周杰伦", 46);
HashSet<Student> set = new HashSet<Student>();
set.add(s1);
set.add(s2);
set.add(s3);
set.add(s4);
for (Student s : set) {
System.out.println(s);
}
}
}

要注意,这里与我们前面说的元素唯一性是不同的,前面所讲是多次调用相同对象时,控制台不予输出,而本案例是当其成员变量的值相同时,我们就认为是同一个对象,就是说不会再控制台打印相同的内容。前者针对对象,后者针对内容,需在学生类中重写 equals() 及 hashCode()方法。
6. LinkedHashSet
LinkedHashSet 集合的特点:
① 由哈希表和链表实现的 Set 接口,具有可预测的迭代次序;
② 由链表保证元素有序,也就是说元素的存储和取出顺序是一致的;
由哈希表保证元素唯一,也就是说没有重复元素。
LinkedHashSet<String> l = new LinkedHashSet<String>();
往集合里面添加元素,输出的结果有序且唯一!
7. TreeSet
TreeSet():根据其元素的自然排序进行排序;
TreeSet(Comparator comparator):根据指定的比较器进行排序。
TreeSet 集合的特点:
① 元素有序,这里的顺序不是指存储和取出的顺序,而是按照一定的规则进行排序,具体排序方式取决于构造方法;
② 没有带索引的方法,所以不能使用普通 for 循环遍历;
③ 由于是 Set 集合,所以不包含重复元素的集合。
//Test.java
package com.an;
import java.util.TreeSet;
public class Test {
public static void main(String[] args) {
TreeSet<Integer> ts = new TreeSet<Integer>();
ts.add(10);
ts.add(40);
ts.add(30);
ts.add(50);
ts.add(20);
for (Integer i : ts) {
System.out.println(i);
}
}
}

可以看到这里遍历到的结果并不是按我们存取的顺序来取出的,这就是自然排序,从小到大排。
集合里面存储的只能是引用类型的元素,对于基本类型存储的时候,我们用的是它的包装类类型!
7.1 自然排序
需求:存储学生对象并遍历,创建 TreeSet 集合使用无参构造方法,要求按照年龄从小到大排序,年龄相同时,按照姓名的字母顺序排序。
//Student.java
package com.an;
import java.util.Objects;
public class Student implements Comparable<Student> {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
public int compareTo(Student s) {
int num = this.age - s.age;
int num2 = num == 0 ? this.name.compareTo(s.name) : num;
return num2;
}
}
//Test.java
package com.an;
import java.util.TreeSet;
public class Test {
public static void main(String[] args) {
Student s1 = new Student("xishi", 20);
Student s2 = new Student("zhangliang", 29);
Student s3 = new Student("diaochan", 31);
Student s4 = new Student("wuzetian", 34);
Student s5 = new Student("lvbu", 31);
Student s6 = new Student("xishi", 20);
TreeSet<Student> ts = new TreeSet<Student>();
ts.add(s1);
ts.add(s2);
ts.add(s3);
ts.add(s4);
ts.add(s5);
ts.add(s6);
for (Student s : ts) {
System.out.println(s);
}
}
}

① Comparable 该接口对实现它的每个类的对象强加一个整体排序,这个排序被称为类的自然排序。也就是说,如果我们要对学生对象做自然排序,就必须让学生类去实现该接口;
② 这里实现接口的时候需要加泛型,然后在学生类里面重写 compareTo 方法;
③ 注意它的返回值,返回 0 重复元素不添加,返回正数按照升序存储,返回负数按照降序来存储;
④ 同时我们可以看到当两个对象的内容相同时,程序会认为是同一个对象,所以不会存储,保证了元素的唯一性;
⑤ 若按成绩、年龄等数字型变量排序,num 值是 s.age - this.age,若按非数字型标准排序,num 值是 s.name.compareTo(this.name);
⑥ 写出主要条件,不要忘了次要条件。
//1.升序排序
public int compareTo(Student s) {
int num = this.age - s.age;
int num2 = num == 0 ? this.name.compareTo(s.name) : num;
return num2;
}
//2.降序排序
public int compareTo(Student s) {
int num = s.age - this.age;
int num2 = num == 0 ? s.name.compareTo(this.name) : num;
return num2;
}
在存储对象的时候,add() 方法内部会自动调用 compartTo() 方法!
7.2 比较器排序
需求:存储学生对象并遍历,创建 TreeSet 集合使用无参构造方法,要求按照年龄从小到大排序,年龄相同时,按照姓名的字母顺序排序。
//Test.java
package com.an;
import java.util.Comparator;
import java.util.TreeSet;
public class Test {
public static void main(String[] args) {
TreeSet<Student> ts = new TreeSet<Student>(new Comparator<Student>() {
@Override
public int compare(Student s1, Student s2) {
int num = s1.getAge() - s2.getAge();
int num2 = num == 0 ? s1.getName().compareTo(s2.getName()) : num;
return num2;
}
});
Student s1 = new Student("xishi", 20);
Student s2 = new Student("zhangliang", 29);
Student s3 = new Student("diaochan", 31);
Student s4 = new Student("wuzetian", 34);
Student s5 = new Student("lvbu", 31);
Student s6 = new Student("xishi", 20);
ts.add(s1);
ts.add(s2);
ts.add(s3);
ts.add(s4);
ts.add(s5);
ts.add(s6);
for (Student s : ts) {
System.out.println(s);
}
}
}
① 学生类即基础学生类,比较器排序法不用在学生类中实现接口;
② 自然排序是在学生类中重写接口方法,比较器排序采用的是匿名内部类的方式,让集合构造方法接收 Comparator 的实现类对象,这两个方法的功能效果一模一样;
③ 注意测试类中访问成员变量要使用其 get 方法,设置了权限不能直接访问。
8. 不重复的随机数
需求:编写一个程序,获取 10 个 1~20 之间的随机数,要求随机数不能重复,并在控制台输出。
思路:
① 创建 Set 集合对象;
② 创建随机数对象;
③ 判断集合的长度是不是小于 10,如果小于 10 就产生一个随机数,添加到集合,通过循环不断判断,直到集合长度为 10;
④ 遍历集合。
//Test.java
package com.an;
import java.util.HashSet;
import java.util.Random;
import java.util.Set;
public class Test {
public static void main(String[] args) {
Set<Integer> s = new HashSet<>();
Random r = new Random();
while (s.size() < 10) {
Integer random = r.nextInt(20) + 1;
s.add(random);
}
for (Integer i : s) {
System.out.println(i);
}
}
}

二、泛型
1. 概述
泛型是 JDK5 引入的特性,它提供了编译时类型安全检测机制,该机制允许在编译时检测到非法的类型,它的本质是参数化类型,也就是说,所操作的数据类型被指定为一个参数。
一提到参数,最熟悉的就是定义方法时有形参,然后调用此方法时传递实参。那么参数化类型怎么理解呢?
顾名思义,就是将类型由原来的具体的类型参数化,然后在使用 / 调用时传入具体的类型。
这种参数类型可以用在类、方法和接口中,分别被称为泛型类、泛型方法和泛型接口。
泛型的定义格式:
① <类型>,指定一种类型的格式,这里的类型可以看成是形参;
② <类型1, 类型2 … >,指定多种类型的格式,多种类型之间用逗号隔开,这里的类型可以看成是形参;
③ 将来具体调用时候给定的类型可以看成是实参,并且实参的类型只能是引用数据类型。
Collection c = new ArrayList();
直接这样创建集合,集合对象默认的数据类型是 Object,所以遍历集合元素写 String 类型时就会报错,需要把 String 改成 Object 或者进行强制类型转换!
使用泛型后:
Collection<String> c = new ArrayList<String>();
泛型的好处:
① 把运行时期的问题提前到了编译期间;
② 避免了强制类型转换。
2. 泛型类
//此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型
public class Generic<T> {}
//Generic.java
package com.an;
public class Generic<T> {
private T t;
public T getT() {
return t;
}
public void setT(T t) {
this.t = t;
}
}
//Test.java
package com.an;
public class Test {
public static void main(String[] args) {
Generic<String> g1 = new Generic<>();
g1.setT("熊二");
System.out.println(g1.getT());
Generic<Integer> g2 = new Generic<>();
g2.setT(20);
System.out.println(g2.getT());
}
}

泛型类让我们传入的参数可以是任意类型的数据类型!
3. 泛型方法
public <T> void show(T t) {}
//Generic.java
package com.an;
public class Generic {
public <T> T show(T t) {
return t;
}
}
//Test.java
package com.an;
public class Test {
public static void main(String[] args) {
Generic g = new Generic();
System.out.println(g.show(2));
System.out.println(g.show("hhhh"));
System.out.println(g.show(false));
}
}

任何类型均可满足,直到传入实参之后,形参的数据类型才被确定!
4. 泛型接口
public interface Generic<T> {}
//Generic.java
package com.an;
public interface Generic<T> {
void show(T t);
}
//GenericImpl.java
package com.an;
public class GenericImpl<T> implements Generic<T> {
@Override
public void show(T t) {
System.out.println(t);
}
}
//Test.java
package com.an;
public class Test {
public static void main(String[] args) {
Generic<String> g1 = new GenericImpl<>();
g1.show("world");
Generic<Integer> g2 = new GenericImpl<>();
g2.show(12);
}
}
5. 类型通配符
为了表示各种泛型 List 的父类,可以使用类型通配符。
类型通配符:<?> List<?>:表示元素类型未知的 List,它的元素可以匹配任何的类型。
这种带通配符的 List 仅表示它是各种泛型 List 的父类,并不能把元素添加到其中!
如果说我们不希望 List<?> 是任何泛型 List 的父类,只希望它代表某一类泛型 List 的父类,可以使用类型通配符的上限。(它及其子类)
类型通配符上限:<? extends 类型>
List<? extends Number>:它表示的类型是 Number 或者其子类型
除了可以指定类型通配符的上限,我们也可以指定类型通配符的下限。(它及其父类)
类型通配符下限:<? super 类型>
List<? super Number>:它表示的类型是 Number 或者其父类型。
//类型通配符
List<?> list1 = new ArrayList<Object>();
List<?> list2 = new ArrayList<Number>();
//类型通配符上限
List<? extends Number> list3 = new ArrayList<Number>();
List<? extends Number> list4 = new ArrayList<Integer>();
//类型通配符下限
List<? super Number> list5 = new ArrayList<Number>();
List<? super Number> list6 = new ArrayList<Object>();
6. 可变参数
可变参数又称参数个数可变,用作方法的形参出现,那么方法参数个数就是可变的了。
public static int sum(int... a) {}
//Test.java
package com.an;
public class Test {
public static void main(String[] args) {
System.out.println(sum(1, 2));
System.out.println(sum(10, 2, 11, 9));
System.out.println(sum(8, 21, 10));
System.out.println(sum(2, 3, 8, 10, 10, 20));
}
public static int sum(int... a) {
int sum = 0;
for (int i : a) {
sum += i;
}
return sum;
}
}

可以看到不管传入多少个参数,我们始终只用一个 sum 方法即可,可变参数的好处就是使代码更加精简,这里 …a
实际上是把传入的数个参数都封装到一个数组中,而这个数组就是 a,求和?遍历数组然后累加。
如果一个方法中有多个参数,其中包含可变参数时,可变参数一定要放到最后,否则报错!
7. 可变参数的使用
//Test.java
package com.an;
import java.util.Arrays;
import java.util.List;
import java.util.Set;
public class Test {
public static void main(String[] args) {
// 1.返回由指定数组支持的固定大小的列表,不能增删可以修改
List<String> l1 = Arrays.asList("I", "love", "you");
// l1.add("w");
// l1.remove("love");
l1.set(0, "w");
System.out.println(l1);
// 2.返回包含任意数量元素的不可变列表,不能增删改
List<String> l2 = List.of("hello", "world", "hi", "world");
// l2.add("hh");
// l2.remove("hi");
// l2.set(1, "abc");
System.out.println(l2);
// 3.返回一个包含任意数量元素的不可变集合,不能增删改且元素不能重复
Set<String> s = Set.of("I", "am", "a", "good", "man");
// s.add("ai");
// s.remove("I");
System.out.println(s);
}
}