原博主 博客主页:https://xiaojujiang.blog.csdn.net/
原博客链接:https://blog.csdn.net/qq_43058685/article/details/117883940
本复习提纲只适用于JMU软件工程大数据课程(ckm授课)
具体内容参考老师提纲的考纲,18和20级的考纲就有部分变动
(老师还考了spark的运行流程还是运行原理来着,就这一题出考纲了,其他都在考纲范围内)
文章目录
- 第一章
- 第三章
- 3.6 数据存放策略和原因P51
- (新增)冗余复制因子为3时的数据存放策略
- 第四章
- (新增)4.2.3 HBASE概念视图与物理视图的不同,举例说明
- 4.5 (修改)HBASE的系统结构与客户端、Zookeeper服务器、Master服务器、Region服务器功能P74-75
- 4.6 (补充)RegionServer,Region
- 第五章
- 5.2 (纠错)关系型数据库不满足Web2.0应用的三大原因 P96
- 5.3(新增)NoSQL数据库与关系型数据库比较(优势与劣势)P97
- 第七章
- 7.1 (新增)MapReduce与Hadoop的关系 P134
- 7.4 (新增)什么是“计算向数据靠拢”?为什么采用这一思想?
- 第九章
- (补充)9.1 Hadoop的缺陷与Spark的优点,优点的实现方式P174
- 9.2 Spark生态系统的组件与其功能 P176
- 9.3 (补充)RDD与DAG的基本概念 P180
- 9.4 (新增)RDD转换操作与行动操作的区别 P180
- 9.4 (补充)RDD哪些操作属于转换操作,哪些操作属于行动操作(常用API表)
- (新增)9.5 RDD惰性调用与DAG的构建
- (新增)9.6 Spark宽依赖与窄依赖的定义,DAG阶段的划分
- 9.6.1 Spark宽依赖与窄依赖的定义
- 9.6.2 DAG阶段的划分
- 第十章
- (补充)10.5.3 Spark和Spark Streaming的差别
第一章
无变化
第三章
3.6 数据存放策略和原因P51
(新增)冗余复制因子为3时的数据存放策略
主要记住这个,策略了原因了解一下就行。
HDFS默认的冗余复制因子是3,每一个文件块会被同时保存到3个地方,其中,有两副本放在同一个机架的不同机器上,第三个副本放在不同机架的机器上,这样既可以保证机架发生异常时的数据恢复,也可以提高数据读写性能。
第四章
(新增)4.2.3 HBASE概念视图与物理视图的不同,举例说明
在HBASE的概念视图中,一个表可以视为一个稀疏,多维的映射关系,每个行都包含相同的列族,尽管行不需要在每个列族里存储数据。比如下图,是一个存储网页的HBASE表,行键是一个反向URL,有列族contents和anchor,前两行列族contents的内容为空,后三行列族anchor为空。HBASE表是一个稀疏的映射关系,即存在很多空的单元格。

在概念视图层面,HBASE中每个表是由许多行组成的,但是在物理存储层面,它采用了基于列的存储方式,而不是像传统关系数据库那样采用基于行的存储方式,比如上图的HBASE表会按照contents和anchor两个列族分别存放,属于同一个列族的数据保存在一起,同时,和每个列族一起存放的还包括行键和时间戳。
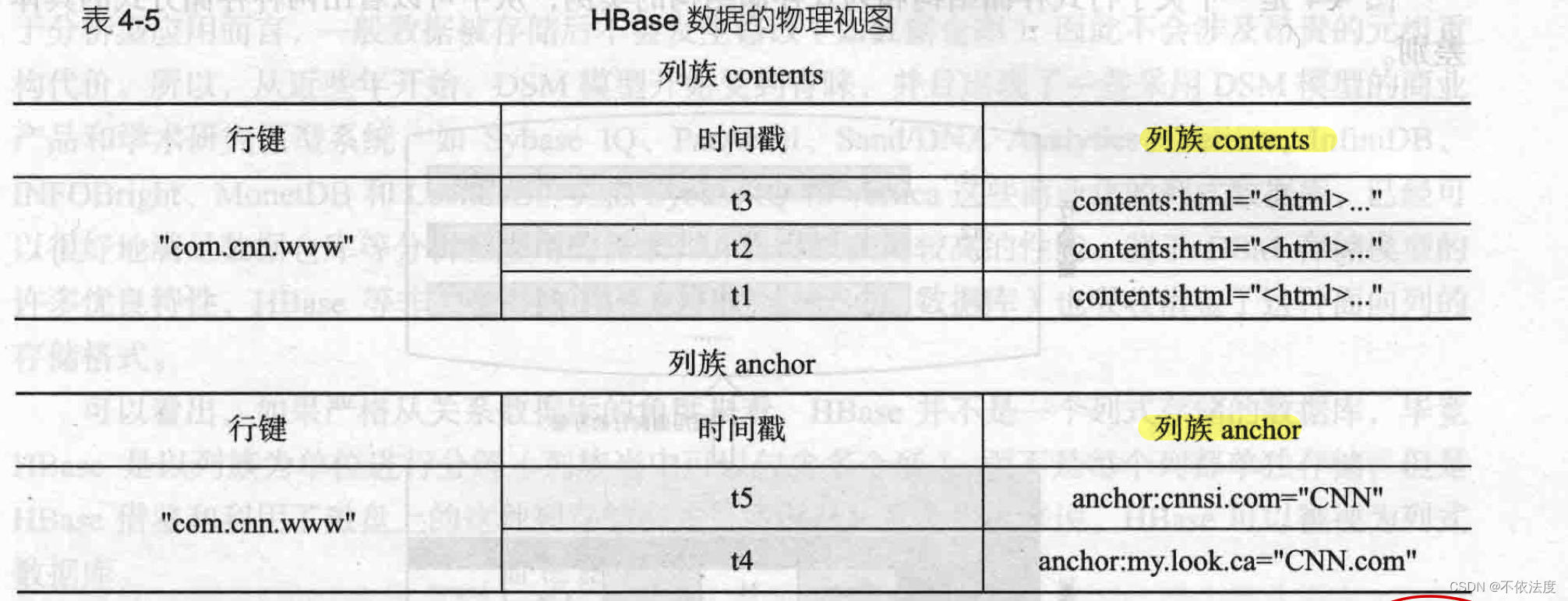
在表 4-4 的概念视图中,我们可以看到,有些列是空的,即这些列上面不存在值。在物理视图中,这些空的列不会被存储成 null,而是根本就不会被存储,当请求这些空白的单元格的时候会返回 null 值。
4.5 (修改)HBASE的系统结构与客户端、Zookeeper服务器、Master服务器、Region服务器功能P74-75
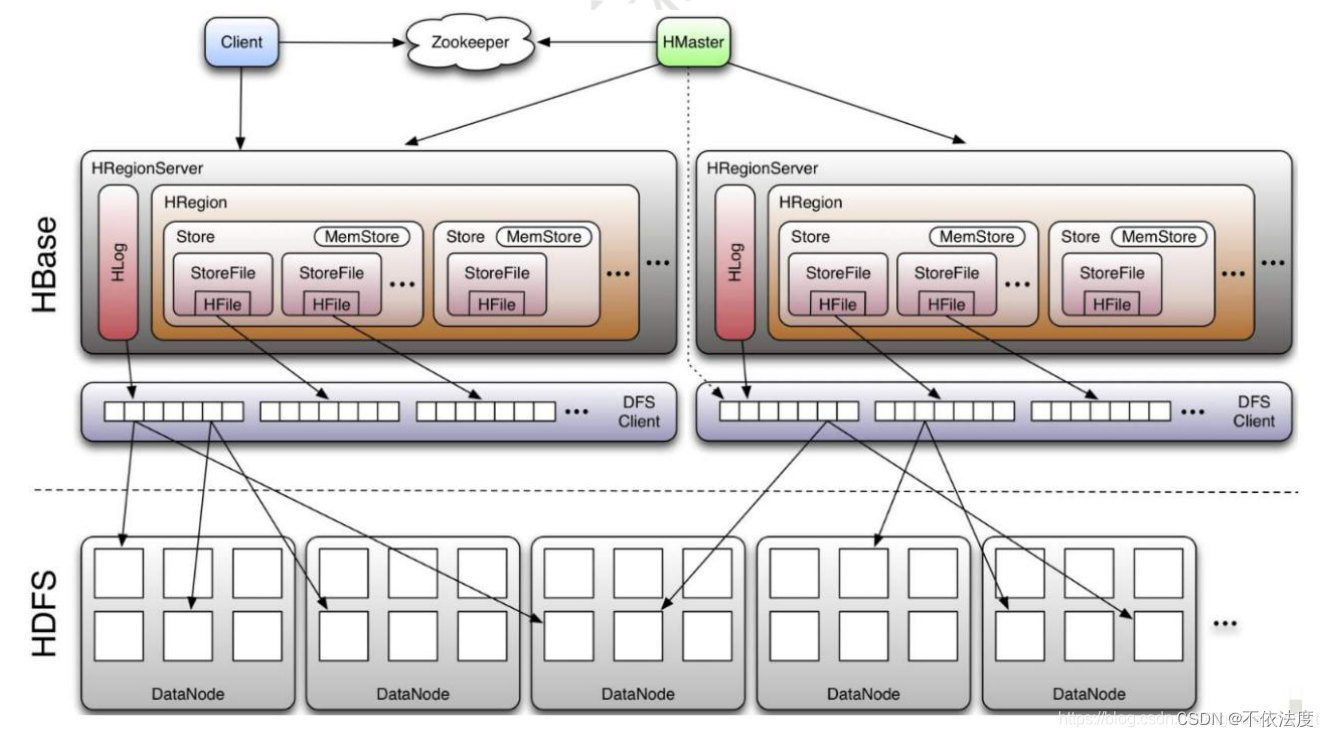
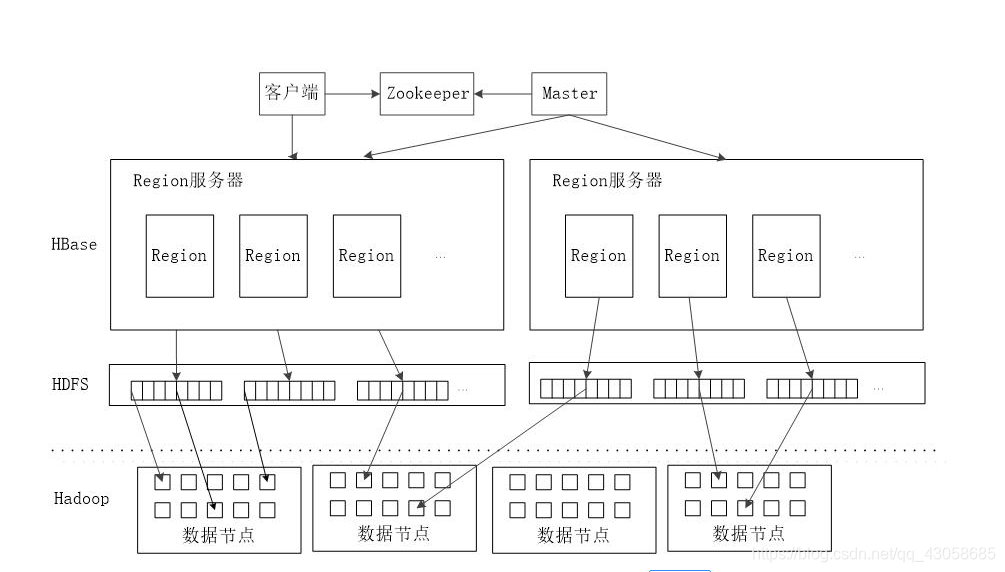
-
HBASE一般采用HDFS作为底层数据存储。
-
客户端
客户端包含访问HBase的接口,同时缓存中维护着已经访问过的Region信息,用来加快后续数据访问过程。 -
Region服务器/Region Server
Region Server 为 Region 的管理者,其实现类为 HRegionServer,负责维护分配给自己的Region,并响应用户的读写请求。主要作用如下:- 维护master分配给他的region,处理对这些region的IO请求。
- 负责切分正在运行过程中变的过大的region。
-
Master
一个HBase集群存在多个HMaster节点,每时每刻只有一个hmaster在运行。主要作用如下:
- 只维护表和region的元数据,而不参与数据的输入/输出过程,hmaster失效仅仅会导致所有的元数据无法被修改,但表的数据读/写还是可以正常进行的。
- 对于 RegionServer的操作:分配 regions到RegionServer,监控每个 RegionServer的状态,负载均衡和故障转移。
- client访问hbase上的数据并不需要master参与(寻址访问zookeeper和region server,数据读写访问region server),master仅仅维护table和region的元数据信息(table的元数据信息保存在zookeeper上),负载很低。
注意:master上存放的元数据是region的存储位置信息,但是在用户读写数据时,都是先写到region server的WAL日志中(应该就是HLog吧,没去查),之后由region server负责将其刷新到region中。所以,用户并不直接接触region,无需知道region的位置,所以并不需要从master处获得region的元数据,而只需要从zookeeper中获取region server的位置元数据,之后便直接和region server通信。
-
Zookeeper
- Zookeeper实时监控每个Region Server的状态并通知给Master。
- 保证任意时刻总有一个Master在运行,避免Master的’单点失效问题‘。
- HBase 通过 Zookeeper 来做 Master 的高可用、RegionServer 的监控、元数据的入口以及集群配置的维护等工作。(辅助Master,减轻Master的负载)
推荐看看这个:https://blog.csdn.net/mm_bit/article/details/51304233
总结一下
- Master记载的是Region和table的元数据。
- ZooKeeper记载的是Region Server的元数据,读写数据只需要Region Server的元数据。
- hmaster启动时候会将hbase系统表.ROOT.加载到 zookeeper,根据三层结构zookeeper可以获取所有region server的元数据。
4.6 (补充)RegionServer,Region
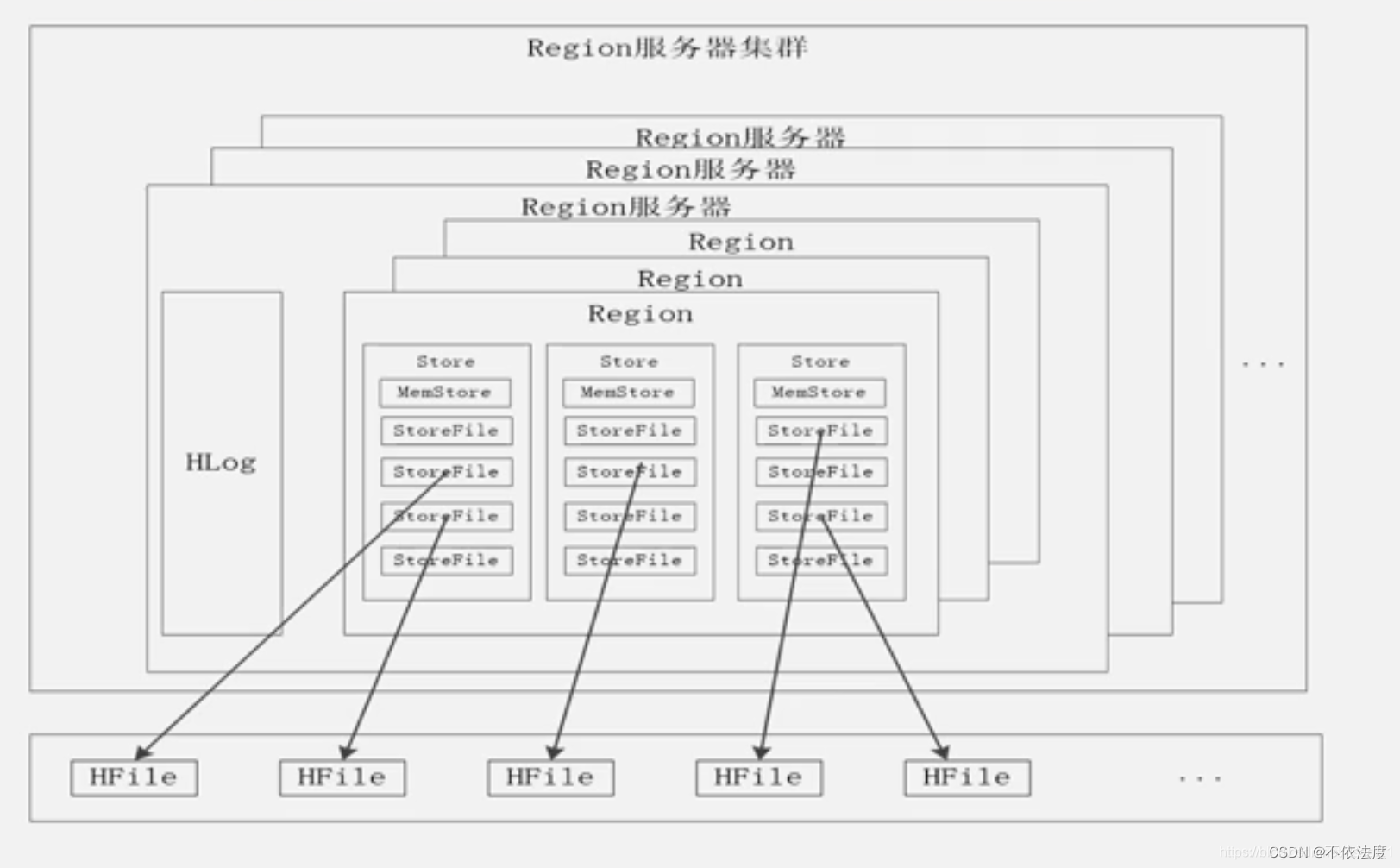
-
一个Region Server包括多个Region,这些Region共用一个公共的HLog;
-
每个Region按照列族进行存储,一个Store就是代表一个列族;
-
写数据
- 写数据首先被写入MemStore和HLog,操作写入HLog后MemStore才会刷写入磁盘。
- 一个Store中的数据不是直接写到底层中去,而是先写到MemStore(缓存)中,缓存满了后再flush到StoreFile磁盘文件中;StoreFile是HBase中的表示形式,底层是借助于HDFS中称为HFile的文件存储。
-
读数据
- 读取数据时, 先访问MemStore缓存,缓存中没找到才去磁盘中的StoreFile寻找。
-
缓存的刷新
- 系统会周期性地把MemStore缓存里的内容刷写到磁盘的StoreFile文件中,清空缓存,并在Hlog里面写入一个标记;每次刷新都生成一个新的StoreFile文件。
- 每个Region Server都有一个自己的HLog文件,每次启动都检查该文件,确认最近一次执行缓存刷新操作之后是否发生新的写入操作;如果发现更新,则先写入MemStore,再刷写到StoreFile,最后删除旧的Hlog文件,开始为用户提供服务。
第五章
5.2 (纠错)关系型数据库不满足Web2.0应用的三大原因 P96
- 无法满足海量数据的管理需求。
- 无法满足数据高并发的需求。
- 无法满足高可拓展性和高可用性的需求。
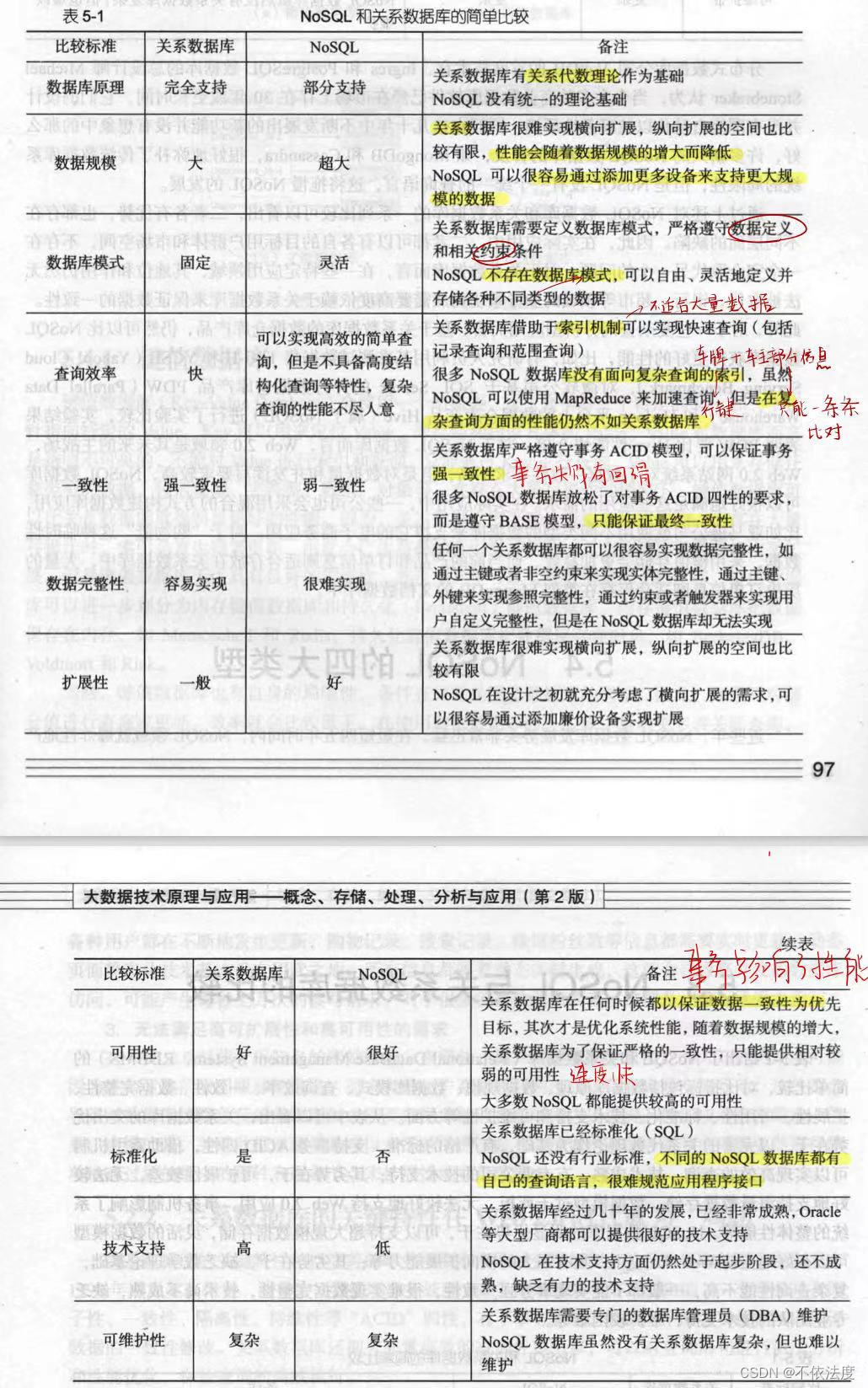
5.3(新增)NoSQL数据库与关系型数据库比较(优势与劣势)P97
- 关系数据库
- 突出优势在于,以完善的关系代数理论作为基础,有严格的标准,支持事务 ACID 四性,借助索引机制可以实现高效的查询,技术成熟,有专业公司的技术支持。
- 其劣势在于,可扩展性较差,无法较好地支持海量数据存储,数据模型过于死板,无法较好地支持 Web 2.0 应用,事务机制影响了系统的整体性能等。
- NOSOL 数据库
- 明显优势在于,可以支持超大规模数据存储,灵活的数据模型可以很好地支持 Web 2.0应用,具有强大的横向扩展能力等。
- 其劣势在于,缺乏数学理论基础,复杂查询性能不高,一般都不能实现事务强一致性,很难实现数据完整性,技术尚不成熟,缺乏专业团队的技术支持,维护较困难等。
记关键词,现编吧:数据库原理,数据规模,数据库模式,查询效率,一致性,数据完整性,扩展性,可用性,标准化,技术支持,可维护性。
## 5.4 (补充)四大类型NOSQL数据库名称与特点P99-101 * 键值数据库 * 优点:扩展性好,灵活性好 ,**大量写操作性能高**。 * 缺点:**无法存储结构化信息,条件查询效率比较低**(准确就是不行,因为数据没有管理)。 * 列族数据库(参考hbase) * 优点:查找速度快,可扩展性强,容易进行分布式扩展,复杂性低。 * 缺点:**功能较少**,大都**不支持强事务一致性**。 * 文档数据库 * 优点:性能好,灵活性高,复杂度低,数据结构灵活,容易迁移,安全。 * 缺点:**缺乏统一的查询语句,查询性能不行,没有事务** * 图数据库 * 优点:灵活性高,**支持复杂的图算法**,可用于构建**复杂的关系图谱**。 * 缺点:**复杂性高,只能支持一定的数据规模**。 
第七章
7.1 (新增)MapReduce与Hadoop的关系 P134
大规模数据集的处理包括分布式存储和分布式计算两个核心环节。Hadoop 使用分布式文件系统HDFS实现分布式数据存储,用 Hadoop MapReduce实现分布式计算。MapReduce的输入输出都需要借助于分布式文件系统进行存储,这些文件被分布存储到集群中的多个节点。
7.4 (新增)什么是“计算向数据靠拢”?为什么采用这一思想?
MapReduce设计的一个理念就是”计算向数据靠拢“:不移动数据,每台计算机之间的数据不交互,而是把计算程序发送给数据。
原因:移动数据需要大量的网络传输开销,尤其在大规模的数据环境下这种开销犹为惊人。移动计算要比移动数据更加经济。
第九章
(补充)9.1 Hadoop的缺陷与Spark的优点,优点的实现方式P174
Hadoop的缺陷:

Spark的优点及其实现方式
- Spark的计算模式也属于MapReduce,但不限于Map和Reduce操作,还提供了多种数据集操作类型,编程模型比MapReduce更灵活。
- Spark提供了内存计算,中间结果直接存放到内存中,带来了更高的迭代运算效率。
- Spark基于DAG的任务调度执行机制,要优于MapReduce的迭代执行机制。
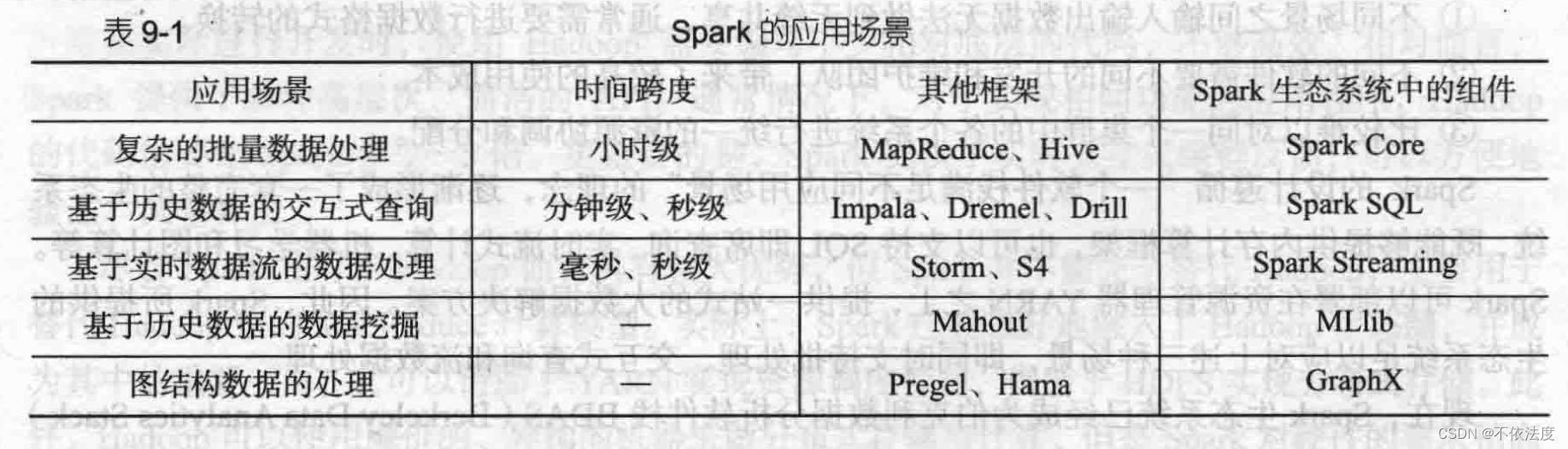
9.2 Spark生态系统的组件与其功能 P176
-
Spark Core
Spark Core包含了Spark基本功能,如内存计算、任务调度、部署模式、故障恢复、存储管理等,主要面对批数据处理场景。Spark建立在统一的抽象RDD之上,使其可以以基本一致的方式应对不同的大数据处理场景。
-
Spark SQL
Spark SQL允许开发人员直接处理RDD,同时也可查询Hive、HBase等外部数据源。Spark SQL的一个重要特点是其能够统一处理关系表和RDD,使得开发人员不需要自己编写Spark应用程序,开发人员可以轻松使用你SQL命令进行查询,并进行更复杂的数据分析。
-
Spark Streaming
Spark Streaming支持高吞吐量、可容错处理的实时流数据处理,其核心思路是将流数据分解成一系列短小的批处理作业,每个短小的批处理作业都可以使用Spark Core进行快速处理。Spark Streaming支持多种数据输入源,如Kafka、Flume和TCP套接字等。
-
MLlib(机器学习)
MLlib提供了常用机器学习算法的实现,包括聚类、分类、回归、协同过滤等,降低了机器学习的门槛,开发人员只需要具备一定的理论知识就能进行机器学习工作。
-
GraphX(图计算)
GraphX是Spark中用于图计算的API,可认为是Pregel在Spark上的重写优化,GraphX性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂地图算法。
9.3 (补充)RDD与DAG的基本概念 P180
理解RDD的话看这个:
- RDD,弹性分布式数据集, 是分布式内存的一个抽象概念,RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,只能通过在其他RDD执行确定的转换操作(如map、join和group by)而创建,然而这些限制使得实现容错的开销很低。对开发者而言,RDD可以看作是Spark的一个对象,它本身运行于内存中,如读文件是一个RDD,对文件计算是一个RDD,结果集也是一个RDD ,不同的分片、 数据之间的依赖 、key-value类型的map数据都可以看做RDD。

9.4 (新增)RDD转换操作与行动操作的区别 P180
- “行动”:用于执行计算并指定输出的形式。
- “转换”:指定RDD之间的相互依赖关系。
两类操作的主要区别是,转换操作(如map,filter、groupBy、join 等)接受RDD并返回RDD,而行动操作(如count、collect等)接受RDD但是返回非RDD(即输出一个值或结果)。
9.4 (补充)RDD哪些操作属于转换操作,哪些操作属于行动操作(常用API表)
- 转换操作(如map,filter、groupBy、join 等)
- 行动操作(如count、collect 等)

(新增)9.5 RDD惰性调用与DAG的构建
- RDD惰性调用:在RDD的执行过程中,真正计算发生在RDD的“行动”操作。对于“行动”之前的所有“转换”操作,Spark只是记录“转换”操作应用的一些基础数据集以及RDD生成的轨迹,即互相之间的依赖关系,而不会触发真正的计算。
- DAG的构建:当进行“行动”操作的时候,Spark才会根据RDD的依赖关系生产DAG,并从起点开始真正的计算。
补充一下:(了解就行)
采用惰性调用,通过DAG连接起来的一系列RDD操作就可以实现管道化,避免了多次转换操作之间数据同步的等待,而且不必担心有过多的中间数据,因为这些具有血缘关系(DAG)的操作都管道化了,一个操作得到的结果不需要保存为中间数据,而是直接管道式地流入到下一个操作进行处理。同时,这种通过血缘关系把一系列操作进行管道化连接的设计方式,也使得管道中每次操作的计算变得相对简单,保证了每个操作在处理逻辑上的单一性。
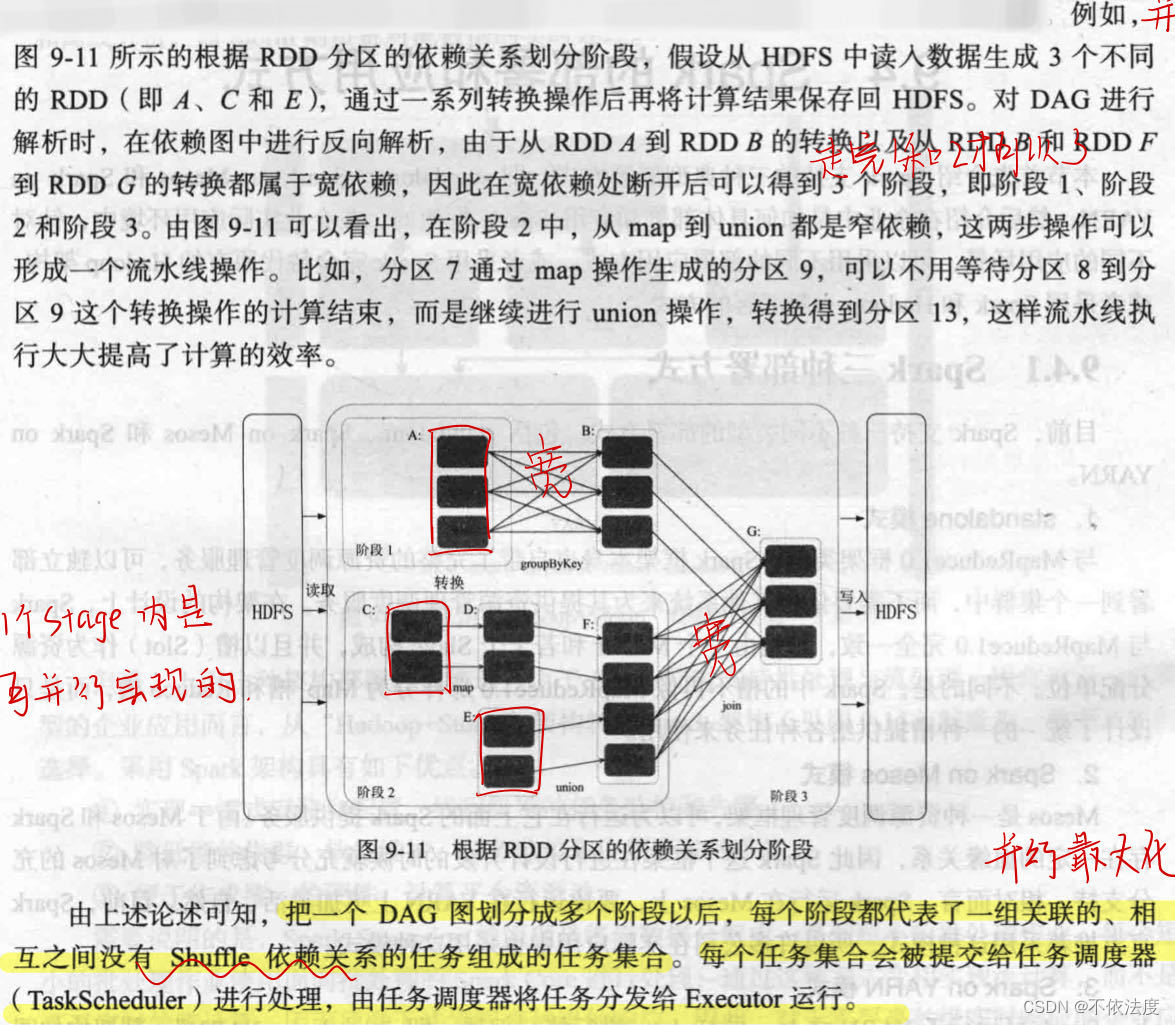
(新增)9.6 Spark宽依赖与窄依赖的定义,DAG阶段的划分
9.6.1 Spark宽依赖与窄依赖的定义
这里的宽窄可以记作父RDD的一个分区对应子RDD分区的范围大小,对应一个子RDD分区就是窄,对应多个就是宽。

9.6.2 DAG阶段的划分
在DAG中进行反向解析,遇到宽依赖就断开,遇到窄依赖就把当前的RDD加入到当前阶段中,将窄依赖尽量划分在同一阶段中。
第十章
流数据就是动态数据。
(补充)10.5.3 Spark和Spark Streaming的差别

详细内容请查看原博客
点赞关注o不ok






![[league/glide]两行代码实现一套强大的图片处理HTTP服务](https://img-blog.csdnimg.cn/img_convert/274ee749364c64a712894fd10ec5ad7d.png)