Oracle中为了方便管理、查询数据当数据量大于500w或者2G时最好用分区表,常见的一种是使用时间作为分区。
分区表添加新的分区有 2 种情况:
(1) 原分区里边界是 maxvalue 或者 default。 这种情况下,我们需要把边界分区 drop 掉,加上新分区后,再添加上新的分区。 或者采用 split,对边界分区进行拆分。
(2) 没有边界分区的。 这种情况下,直接添加分区就可以了。
创建分区表:
CREATE TABLE WJZ.wjz_t1
( ID NUMBER,
STR1 VARCHAR2(20),
STR2 VARCHAR2(20),
STR3 VARCHAR2(20),
tdate date,
constraint pk_id_t1 primary key(id)
)
PARTITION BY RANGE (TDATE)
(PARTITION P202212 VALUES LESS THAN (TO_DATE('2023-01-01','YYYY-MM-DD')),
PARTITION POTHER VALUES LESS THAN (MAXVALUE) )然后插入数据
insert into WJZ_T1 values(1,'str1','str2','abc',to_date('2022-11-10 00:00:01','yyyy-mm-dd hh24:mi:ss'));
insert into WJZ_T1 values(2,'str1','str2','abc',to_date('2022-12-10 00:00:01','yyyy-mm-dd hh24:mi:ss'));
insert into WJZ_T1 values(3,'str1','str2','abc',to_date('2023-1-10 00:00:01','yyyy-mm-dd hh24:mi:ss'));
insert into WJZ_T1 values(4,'str1','str2','abc',to_date('2023-1-12 00:00:01','yyyy-mm-dd hh24:mi:ss'));
insert into WJZ_T1 values(5,'str1','str2','abc',to_date('2023-2-10 00:00:01','yyyy-mm-dd hh24:mi:ss'));
insert into WJZ_T1 values(6,'str1','str2','abc',to_date('2023-2-14 00:00:01','yyyy-mm-dd hh24:mi:ss'));
insert into WJZ_T1 values(7,'str1','str2','abc',to_date('2023-3-10 00:00:01','yyyy-mm-dd hh24:mi:ss'));其中增加POHTER分区是为了防止不符合分区条件是数据插入报错,但是如果直接新增分区会报错ORA-14074: 分区界限必须调整为高于最后一个分区界限,根本原因是存在最后maxvalue分区
ALTER TABLE wjz_t1 ADD PARTITION P202301 VALUES LESS THAN(TO_DATE('2023-02-01','YYYY-MM-DD'));
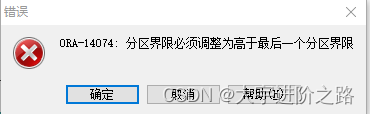
解决方法是拆分分区,在split partition时,根据split point原来的partition分裂成两个partition。
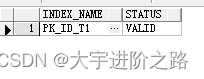
同时,观察在拆分分区前查看索引情况:
select a.index_name,a.status from user_indexes a where table_name in ('WJZ_T1') ;
拆分分区SQL:
ALTER TABLE wjz_t1 SPLIT PARTITION POTHER AT (TO_DATE('2023-02-01','YYYY-MM-DD')) INTO (PARTITION P202301, PARTITION POTHER);
ALTER TABLE wjz_t1 SPLIT PARTITION POTHER AT (TO_DATE('2023-04-01','YYYY-MM-DD')) INTO (PARTITION P202303, PARTITION POTHER);新增表分区成功,如下

查看表索引也是正常的:
但是如果要新增P202302表分区的话,以下会报错:
ALTER TABLE wjz_t1 SPLIT PARTITION POTHER AT (TO_DATE('2023-03-01','YYYY-MM-DD')) INTO (PARTITION P202302, PARTITION POTHER);所以分区拆分的时候,必须从小的开始,否则会提示如下报错
ORA-14080:无法按指定的上限来分割分区
正确的是
ALTER TABLE wjz_t1 SPLIT PARTITION P202303 AT (TO_DATE('2023-03-01','YYYY-MM-DD')) INTO (PARTITION P202302, PARTITION P202303);
此时查看表索引有问题:
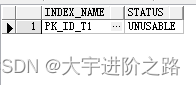
需要重建索引:
ALTER INDEX PK_ID_T1 REBUILD ONLINE;或者在拆分分区的时候使用以下也会重建索引:
ALTER TABLE wjz_t1 SPLIT PARTITION P202303 AT (TO_DATE('2023-03-01','YYYY-MM-DD')) INTO (PARTITION P202302, PARTITION P202303) UPDATE INDEXES ;所以如果清理表时,如果时间分区忘了增加,可以拆分默认表分区来新增表分区,然后再通过删除分区方式来清理数据:
alter table WJZ_T1 drop partition P202302;
但需要注意的是观察分区表的索引情况。
如果表分区split的时候将tablespace更换了,那么也需要rebuild index .
参考文章:
oracle11.2中add&split partition 对全局及本地index的影响 - 知乎
oracle分区表split,分区表split操作及maxvalue处理_科技体验者的博客-CSDN博客
Oracle Partition 分区详细总结_wounler的博客-CSDN博客


![[league/glide]两行代码实现一套强大的图片处理HTTP服务](https://img-blog.csdnimg.cn/img_convert/274ee749364c64a712894fd10ec5ad7d.png)