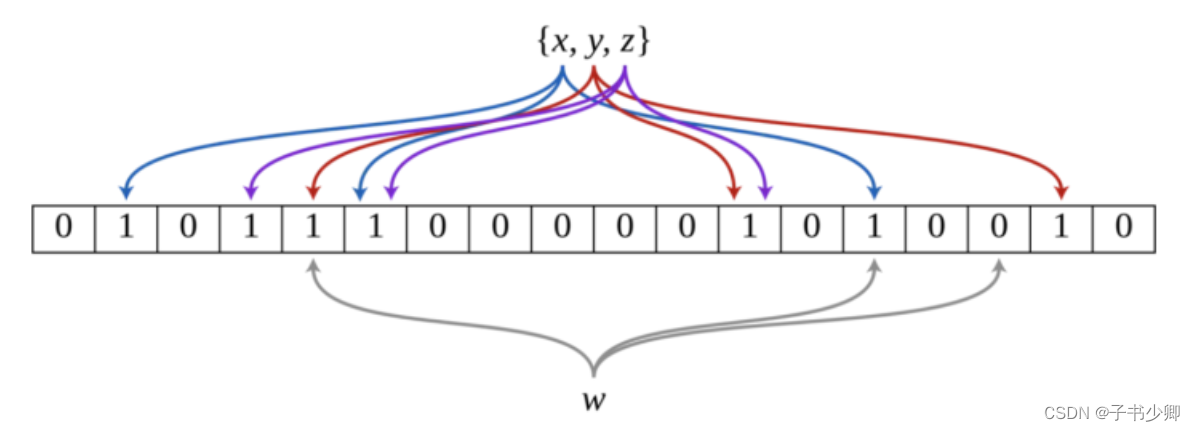
基于BERT-PGN模型的中文新闻文本自动摘要生成(2020.07.08)
基于BERT-PGN模型的中文新闻文本自动摘要生成(2020.07.08)
- 摘要:
- 0 引言
- 相关研究
- 2 BERT-PGN模型
- 2. 1 基于预训练模型及多维语义特征的词向量获取阶段
- 2. 1. 1 BERT预训练语言模型
- 2. 1. 2 多维语义特征
- 2. 2 基于指针生成网络模型的句子生成阶段
- 3 实验与分析
- 3. 1 实验数据
- 3. 2 评价指标
- 3.3 对比实验
- 3. 4 实验环境及参数设置
- 3. 5 实验结果与分析
- 3. 5. 1 总体摘要结果对比实验
- 3. 5. 2 多维语义特征对比实验
- 3. 5. 3 coverage机制实验分析
- 4 结语
摘要:
- 针对文本自动摘要任务中生成式摘要模型对句子的上下文理解不够充分、生成内容重复的问题,基于BERT 和指针生成网络(PGN),提出了一种面向中文新闻文本的生成式摘要模型——BERT-指针生成网络(BERTPGN)。首先,利用 BERT 预训练语言模型结合多维语义特征获取词向量,从而得到更细粒度的文本上下文表示;然后,通过 PGN模型,从词表或原文中抽取单词组成摘要;最后,结coverage机制来减少重复内容的生成并获取最终的摘要结果。在2017年CCF国际自然语言处理与中文计算会议(NLPCC2017)单文档中文新闻摘要评测数据集上的实验结果表明,与PGN、伴随注意力机制的长短时记忆神经网络(LSTM-attention)等模型相比,结合多维语义特征的BERT-PGN模型对摘要原文的理解更加充分,生成的摘要内容更加丰富,全面且有效地减少重复、冗余内容的生成,Rouge-2和Rouge-4指标分别提升了1. 5%和1. 2%。
0 引言
- 随着近些年互联网产业的飞速发展,大量的新闻网站、新闻手机软件出现在日常生活中,越来越多的用户通过新闻网站、手机软件快速获取最新资讯。根据中国互联网络信息中心(China Internet Network Information Center,CNNIC)第 42 次发展统计报告,到2018年6月,中国的移动电话用户规模达到7. 88 亿,网民接入互联网的比例也在增加,通过手机达到98. 3%。网友人数增多、新闻媒体网络平台使用率不断提升,网友们使用今日头条等新闻媒体的频率也不断提升。为了适应当下快节奏的生活,网友需要阅读最少的新闻字数,获取新闻文章的关键内容。网友们可以通过文本自动摘要技术,概括出新闻的主要内容,节省阅读时间,提升信息使用效率。因此,本文提出的面向新闻的文本自动摘要模型具有重要意义。
- 国内外学者针对文本自动摘要已经做了大量的研究。文本自动摘要是 20世纪 50年代出现的一种用计算机完成的文本摘要技术,帮助人们从信息海洋中解放,提高信息的使用效率[2]。自2001年美国国家标准技术研究所举办文档理解会议以来,文本自动摘要研究得到了越来越多的关注[3]。
- 本文受文献[4]启发,针对网友阅读理解新闻时需要花费大 量 时 间 的 问 题 ,基 于BERT(Bidirectional Encoder Representations from Transformers)和 指 针 生 成 网 络(Pointer Generator Network,PGN),提出了一种面向中文新闻文本的自动摘要模型——BERT-指针生成网络(Bidirectional Encoder Representations from Transformers-Pointer Generator Network,BERT-PGN),能够有效节省时间,提高信息使用效率。该模型首先利用 BERT 预训练语言模型获取新闻文本的词向量,结合多维语义特征对新闻中的词所在的句子进行打分,其结果作为输入序列输入到指针生成网络中进行训练,得到新闻摘要的结果。本文主要贡献如下。
- 1)本文提出了一种面向新闻文本进行自动摘要的模型——BERT-PGN,分为两个阶段实现:基于预训练模型及多维语义特征的词向量获取阶段以及基于指针生成网络模型的句子生成阶段。
- 2)实验结果表明,该模型在2017年CCF国际自然语言处理与中文计算会议(the 2017 CCF International Conference on Natural Language Processing and Chinese Computing,NLPCC2017)单文档中文新闻摘要评测数据集上取得了很好的效果,Rouge-2和Rouge-4指标分别提升1. 5%和1. 2%。
相关研究
-自动文本摘要有两种主流方式,即抽取式摘要和生成式摘要[5]。在对文本进行语义挖掘的研究中,许多经典的分类、聚类算法被先后提出[6]。最早的摘要工作主要是利用基于词频和句子位置的基于统计的技术[7]。1958 年,Luhn[8]提出了第一个自动文本摘要系统。近十几年来,随着机器学习(Machine Learning,ML)以及自然语言处理(Natural Language Processing,NLP)的快速发展,许多准确高效的文本摘要算法被提出[9]。互联网作为商业媒介快速发展,导致用户吸收了太多信息。为了解决这种信息过载,文本自动摘要起到了关键作用。文本自动摘要可以在屏蔽大量干扰文本的同时,让用户更加快捷地获取关键信息,适应当下快节奏的生活[10]
。
- 抽取式摘要方法是将一篇文章分成小单元,然后将其中的一些作为这篇文章的摘要进行提取。Liu等[11]提出了一个抽取式文本摘要的对抗过程,使用生成对抗网络(Generative Adversarial Network,GAN)模型获得了具有竞争力的Rouge分数,该方法可以生成更多抽象、可读和多样化的文本摘要;AlSabahi 等[12使用分层结构的自注意力机制模型(Hierarchical Structured Self-Attentive Model,HSSAM),反映文档的层次结构,进而获得更好的特征表示,解决因占用内存过大模型无法充分建模等问题 ;Slamet 等[13]提出了一种向量空间模型(Vector Space Model,VSM),利用VSM进行单词相似性测试,对文本自动摘要的结果进行测评,比较文本摘要实现的效果;Alguliyev 等[14]发现,与传统文本自动摘要方法相比,基于聚类、优化和进化算法的文本自动摘要研究最近表现出了良好的效果。但抽取式摘要并未考虑文本的篇章结构信息,缺少对文本中关键字、词的理解,生成的摘要可读性、连续性较差。
- 生成式摘要方法是一种利用更先进自然语言处理算法的摘要方法,对文章中的句子进行转述、替换等生成文章摘要,而不使用其中任何现有的句子或短语。随着近些年深度学习的快速发展,越来越多的深度学习方法被利用到文本摘要中。
- Cho等[15]和Sutskever等[16]最早提出了由编码器和解码器构成的 seq2seq(sequence-to-sequence)模型;Tan 等[17]提出了基于图的注意力机制神经模型,在文本自动摘要的任务中取得了很好的效果;Siddiqui等[18]在谷歌大脑团队提出的序列到序列模型的基础上进行改进,使用局部注意力机制代替全局注意力机制,在解决生成重复的问题上取得了很好的效果;Celikyilmaz 等[19]针对生成长文档的摘要,提出了一种基于编码器-解码器体系结构的深层通信代理算法;Khan 等[20]提出了一种基于语义角色标记的框架,使用深度学习的方法从语义角色理解的角度实现多文档摘要任务;江跃华等[21]提出了一种基于 seq2seq 结构和注意力机制并融合了词汇特征的生成式摘要算法,能在摘要生成过程中利用词汇特征识别更多重点词汇内容,进一步提高摘要生成质量。
- 现阶段大多数的文本自动摘要方法主要是利用机器学习或深度学习模型自动提取特征,利用模型进行摘要句子的选取及压缩。但自动提取的特征和摘要文本会存在不充分、不贴近的情况,不能很好地刻画摘要文本。本文提出的 BERT-PGN 模型基于 BERT 预训练语言模型及多维语义特征,针对中文新闻文本,从更多维度进行特征抽取,深度刻画摘要文本,能够得到更贴近主题的摘要内容。
2 BERT-PGN模型
- 本文提出的 BERT-PGN 模型主要分成两个阶段实现,即 基于预训练模型及多维语义的词向量获取阶段以及基于指针生成网络模型的句子生成阶段,如图 1 所示。该模型第一阶 段利用预训练语言模型 BERT 获取新闻文章的词向量,同时 利用多维语义特征对新闻中的句子进行打分,将二者进行简 单拼接生成输入序列;第二阶段将得到的输入序列输入到指针生成网络模型中,使用coverage机制减少生成重复文字,同 时保留生成新文字的能力,得到新闻摘要。
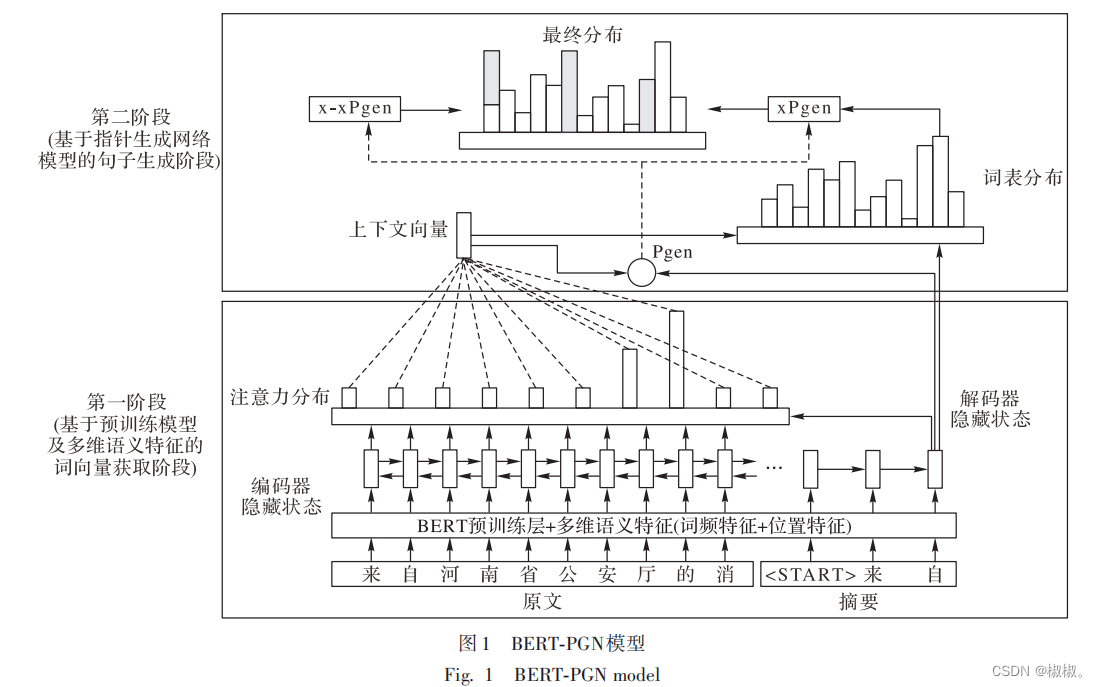
2. 1 基于预训练模型及多维语义特征的词向量获取阶段
2. 1. 1 BERT预训练语言模型
- 语言模型是自然语言处理领域一个比较重要的概念,利 用语言模型对客观事实进行描述后,能够得到可以利用计算机处理的语言表示。语言模型用来计算任意语言序列a1,a2, …,an出现的概率p(a1,a2,…,an ),即:
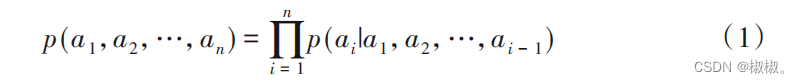
- 通过传统的神经网络语言模型获取的词向量是单一固定 的,存在无法表示字的多义性等问题。预训练语言模型很好地解决了这一问题,能够结合字的上下文内容来表示字。 BERT 采用双向 Transformer 作为编码器进行特征抽取,能够获取到更多的上下文信息,极大程度地提升了语言模型抽取 特征的能力。Transformer编码单元包含自注意力机制和前馈神经网络两部分。自注意力机制的输入部分是由来自同一个 字的三个不同向量构成的,分别Query向量(Q),Key向量(K)和Value向量(V)。通过Query向量和Key向量相乘来表示输 入部分字向量之间的相似度,记做[QK]T ,并通过dk进行缩放, 保证得到的结果大小适中。最后经过 softmax 进行归一化操 作,得到概率分布,进而得到句子中所有词向量的权重求和表示。这样得到的词向量结合了上下文信息,表示更准确,计算 方法如下:
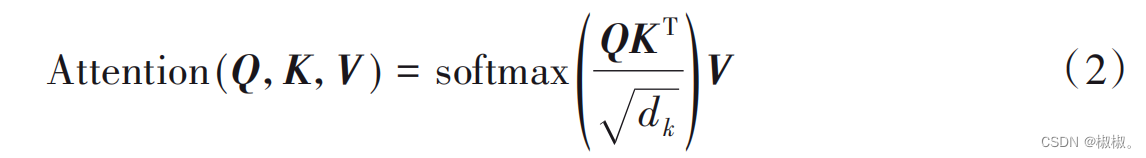
- BERT 预训练模型使用了“MultiHead”模式,即使用了多 个注意力机制获取句子的上下文语义信息,称为多头注意力机制。BERT预训练语言模型能够使词向量获取更多的上下 文信息,更好地表示原文内容。
2. 1. 2 多维语义特征
- 针对中文新闻重点内容集中在新闻开头、关键词出现频率高等特点,本文引入了传统特征以及主题特征对中文新闻文本中的句子进行细粒度的描述,提升对文本中句子的上下 文语义表述性能。
- 1)传统特征。
- 本文所选择的传统特征主要为句子层次的两种特征:句子中的词频以及在文章中的位置。词频特征是反映新闻文章中最重要信息的一种统计特征,也是最简单、最直接的一种统计特征。新闻文章中出现词的词频可以利用式(3)进行计算:

- 其中,wordj 代表文章中第j个词出现的次数。 在本文中,选择文章中的句子作为最终的打分基本单位。 句子是词的集合,如果句子包含的词语中,有在新闻文章中频 繁出现的高频词,则认为这个句子在文章中更加重要。新闻文章中第i个句子的词频特征打分公式如下:

- 其中:TFi表示第i个句子中包含的词的词频之和,seni代表第i 个句子中包含的所有词。 位置特征同样是反映新闻文章中重要信息的一种统计特征。一篇新闻文章是由多个句子组成的,句子所在的位置不 同,其代表的重要性也不同,例如文章中的第一个句子大多是新闻文章中最重要的一句话。新闻文章中第 i个句子的位置 特征打分公式如下:

- 其中:Posi代表第 i个句子的位置得分,pi代表第 i个句子在新 闻文章中的位置,n代表文章中的句子总个数。
- 2)主题特征。
- 本文选取的主题特征也可表述为标题特征。新闻文章中 的标题具有很高的参考价值,很大程度上可以代表文章中的主题。因此,如果文章中的句子与新闻文章的标题有较高的 相似度,那么这个句子更容易被选择为文章摘要中的句子。本文使用余弦相似度计算新闻文章中第 i个句子的主题特征 得分,打分公式如下:
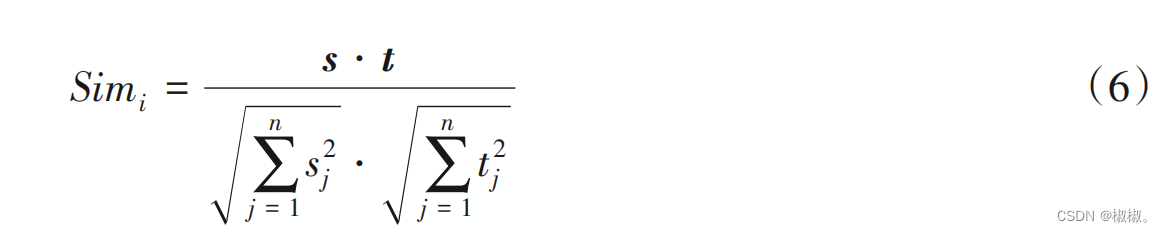
- 其中:Simi表示第 i个句子与新闻文章标题的相似度,s和 t分 别代表标题和新闻文章中句子的向量化表示。
2. 2 基于指针生成网络模型的句子生成阶段
- 指针生成网络模型结合了指针网络(Pointer Network, PN)和基于注意力机制的序列到序列模型,允许通过指针直接指向生成的单词,也可以从固定的词汇表中生成单词。文 本中的文字 wi依次传入 BERT-多维语义特征编码器、双向长短时记忆神经网络(Bidirectional Long Short-Term Memory,BiLSTM)编码器,生成隐层状态序列 hi 。在 t 时刻,长短时记忆 (Long Short-Term Memory,LSTM)神经网络解码器接收上一 时刻生成的词向量,得到解码状态序列st 。
- 注意力分布at 用来确定t时刻输出序列字符时,输入序列 中需要关注的字符。计算公式如下:
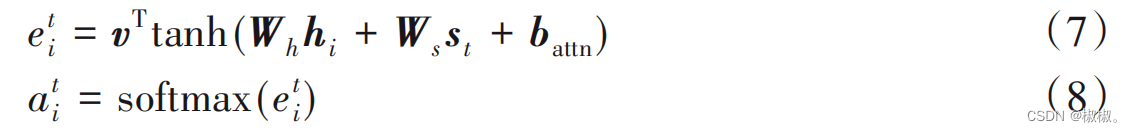
- 其中,v、Wh、Ws 、battn是通过训练得到的参数。利用注意力分布 对编码器隐层状态加权平均,生成上下文向量ht* 。

- 将上下文向量 ht * 与解码状态序列 st串联,通过两个线性 映射,生成当前预测在词典上的分布Pvocab,计算公式如下:
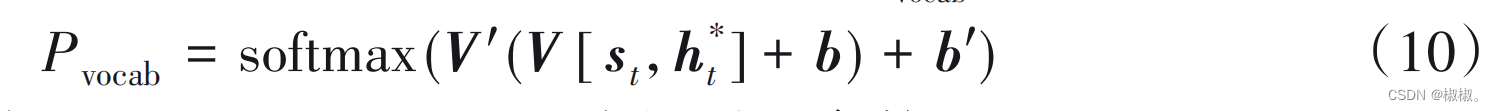
- 其中,V’、V、b、b’是通过训练得到的参数。
- 模型利用生成概率Pgen来确定复制单词还是生成单词,计 算公式如下:
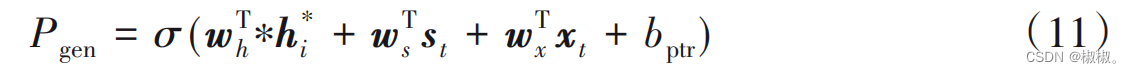
- 其中,wh、ws 、wx、bptr是通过训练得到的参数,σ是sigmoid函数, xt是解码输入序列。将at
作为模型输出,得到生成单词w的概率分布:
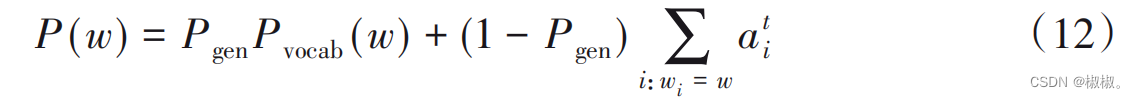
- 为了解决生成词语重复的问题,本文引入了 coverage 机 制。通过 coverage 机制对指针生成网络模型进行改进,能够有效减少生成摘要中的重复。引入 coverage 向量 ct 跟踪已经 生成的单词,并对已经生成的单词施加一定的惩罚,尽量减少生成重复。coverage向量ct 计算方式如下:

- 通俗来说,ct 表示目前为止单词从注意力机制中获得的 覆盖程度。使用coverage向量ct 影响注意力分布,重新得到注 意力分布at,计算公式如下:
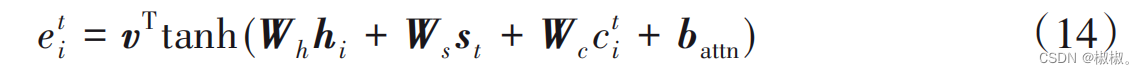
- 其中Wc是通过训练得到的参数。
3 实验与分析
3. 1 实验数据
- 本文的实验部分使用的数据是由 2017 年 CCF 国际自然 语 言 处 理 与 中 文 计 算 会 议(NLPCC2017)提 供 ,来自 于 NLPCC2017中文单文档新闻摘要评测数据集,包含训练集新 闻文本 49 500 篇,测试集新闻文本 500 篇。该任务中要求生成的摘要长度不超过60个字符。
3. 2 评价指标
- Rouge是文本自动摘要领域摘要评价技术的通用指标之 一,通过统计模型生成的摘要与人工摘要之间重叠的基本单元,评判模型生成摘要的质量。本文参考NLPCC2017中文单文档新闻摘要评测任务,使用 Rouge-2、Rouge-4 和 Rouge-SU4作为评价指标,对摘要结果进行评价。
3.3 对比实验
-
本文实验部分选取 8 种基本模型:NLPCC2017 单文档新 闻 摘 要 评 测 任 务 结 果 较 好 团
队(ccnuSYS、LEAD、 NLP@WUST、NLP_ONE)提 出 的 模 型[22] 、PGN(without coverage mechanism)[23] 、PGN[23] 、主题关键词信息融合模型[24] 以及 BERT-PGN(without semantic features)。对人工提取的主 题特征、传统特征进行特征的有效性验证,验证本文提出方法 的有效性。 -
1)ccnuSYS[22] :使用基于注意力机制的 LSTM 编码器-解 码器结构模型生成摘要。
-
2)LEAD[22] :从原文选取前60个字作为文本摘要。
-
3)NLP@WUST[22] :使用特征工程的方法进行句子抽取, 并利用句子压缩算法对抽取的句子进行压缩。
-
4)NLP_ONE[22]:NLPCC2017单文档新闻摘要评测任务第 一名的算法,包含输入、输出序列的注意力机制。
-
5)PGN(without coverage mechanism)[23] :ACL2017 中提出 的一种生成模型,使用指针网络和基于注意力机制的序列到序列模型生成摘要,不使用coverage机制。
-
6)PGN(coverage mechanism)[23] :改进的指针生成网络模型,利用coverage机制解决生成重复词和未登录词的问题。
-
7)主题关键词融合模型[24] :一种结合主题关键词信息的多注意力机制模型。
-
8)BERT-PGN(without semantic features):本文提出的一种基于BERT和指针生成网络的模型,利用coverage机制减少 生成重复内容。
-
9)BERT-PGN(semantic features):在 BERT-PGN(without semantic features)模型上进行优化得到的模型,结合多维语义特征获取细粒度的文本上下文表示。
3. 4 实验环境及参数设置
- 本文实验使用单个GTX-1080Ti(GPU)进行训练。本实验 获取文本词向量使用 BERT-base 预训练模型。BERT-base 模型 共 12 层 ,隐 层 768 维 。 设 置 最 大 序 列 长 度 为 128,
train_batch_size为16,learning_rate为 5E-5。 指针生成网络模型设置 batch_size 为 8,隐层
256维,设置 字典大小为 50k。训练过程共进行 700k 次迭代,训练总时长 约为7 d5 h(合计173 h)。
3. 5 实验结果与分析
3. 5. 1 总体摘要结果对比实验
- 本文重新运行了部分baseline模型,将获取的结果与本文 提出的模型结果做对比,实验结果如表1。
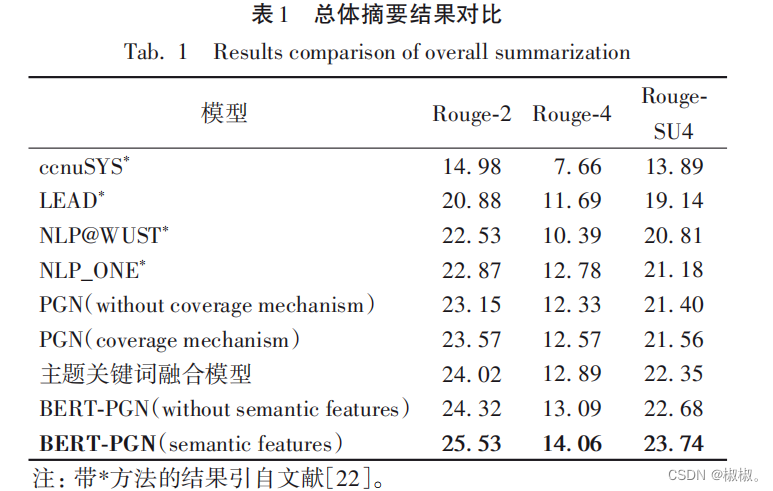
- 从表 1 可以看出,本文提出的模型性能相较于 PGN、 NLP_ONE 等模型有了显著的提升,在 Rouge-2、Rouge-4 以及Rouge-SU4的评价指标中有着明显的优势,Rouge指标提升了 1. 2~1. 5个百分点。 由 BERT-PGN(semantic features)模型与 PGN、BERT-PGN (without semantic features)模型进行对比,可以看出使用BERT 预训练模型并结合有效的多维人工特征,能够显著提升模型效果。使用BERT预训练模型并结合人工抽取的特征得到的句子上下文表示,对文本中句子的语义理解更加深刻、准确,在文本自动摘要任务中能够有效提升性能。
- 根据表 2 不同模型生成摘要的内容可以发现,本文提出的 BERT-PGN 模型相较于其他模型,在中文新闻文本的自动摘要任务中生成的摘要内容更丰富、更全面、更贴近标准摘要,说明该模型对全文的理解更加充分,能够结合文中句子的上下文充分理解句子、词语的含义,对文中的句子、词语进行更细致的刻画。

3. 5. 2 多维语义特征对比实验
- 多维特征选取的部分,本文针对新闻文本“主要内容集中 在开头部分”的特点,选取传统特征、主题特征中的词频特征、位置特征以及标题特征,分别表示为TF、Pos以及Main。 由表 3 可以看出,同一模型结合人工提取的词频特征和位置特征效果最好,Rouge-2 指标最多提升了 1. 2 个百分点, Rouge-4指标最多提升了1. 0个百分点。
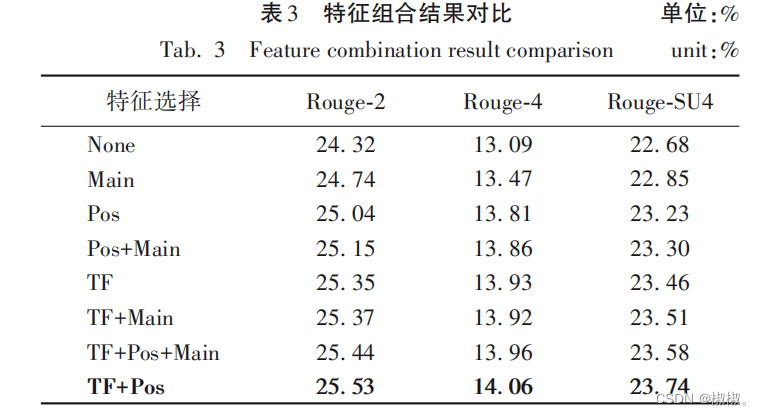
- 本文选取的主题特征 Main 能够在一定程度上提升模型 的 Rouge 指标。从 Pos 和 Pos+Main、TF 和 TF+Main的特征组 合结果对比可以得知,主题特征结合词频特征时提升明显,结 合位置特征时基本没有提升。句子在新闻中的位置靠前时,与标题的相似度也更高,说明两种人工特征在衡量句子在新 闻中的重要性时起到了相似的作用。
- 通过对比 TF+Main 和TF+Pos两种特征组合的结果可以得知,词频信息结合位置信 息相较于结合主题信息效果更好,能够充分表达句子在新闻文章中的重要性。因此,本文选择使用词频特征以及位置特 征的特征组合作为多维特征。 新闻文章中多次出现的关键词,是反映新闻文章中最重要信息的一种统计特征,进行词频统计的意义在于找出文章 表达的重点;此外,句子出现的位置也是反映句子重要程度的关键,出现的位置越靠前,说明该句子在文章中起到的作用越 大。因此,词频、位置特征是自动摘要模型提升的关键。
3. 5. 3 coverage机制实验分析
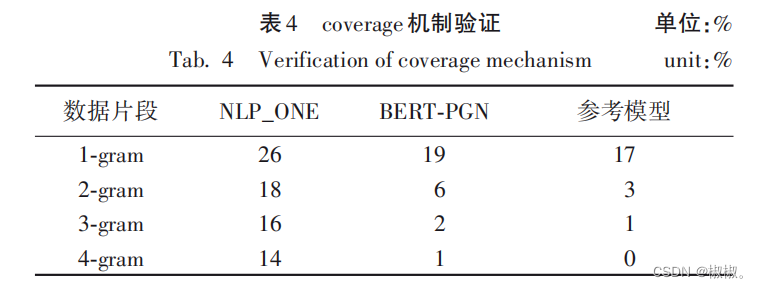
- 本文使用的模型使用了 coverage 机制,试图解决生成重 复内容的问题。通过计算生成摘要中 1-gram、2-gram、3-gram以及 4-gram 所占比例,定量分析引入 coverage 机制解决生成 内容重复问题的效果。 由表 4 可以看出,本文提出的BERT-PGN 模型相较于 NLP_ONE能够有效减少生成内容的重复,在解决重复的方面 效果明显,在 3-gram、4-gram的摘要结果定量分析中,接近标 准摘要的效果。
- 由表 4 可以看出,本文提出的 BERT-PGN 模型相较于 NLP_ONE能够有效减少生成内容的重复,在解决重复的方面 效果明显,在3-gram、4-gram 的摘要结果定量分析中,接近标 准摘要的效果。
4 结语
- 本文提出了一种面向中文新闻文本的 BERT-PGN 模型, 结合 BERT 预处理模型及多维语义特征获取词向量,利用指 针生成网络模型结合coverage机制减少生成重复内容。经实 验表明,BERT-PGN模型在中文新闻摘要任务中,生成的摘要结果更接近标准摘要,包含更多原文的关键信息,能有效解决 生成内容重复的问题。 下一步将尝试挖掘更多要素,例如:面向新闻文本的有效人工特征等,提升摘要结果;简化模型,缩短模型训练时间;提 升生成摘要内容的完整性、流畅性;构建新闻领域的外部数据,帮助模型结合句子上下文充分理解句子含义。
只是自己在工作中或者业务看到了这篇论文,顺便记录一下自己的学习。如果需要原论文可以评论邮箱,直接发邮箱。