文章目录
- 1、对索引字段进行了运算或者使用了函数
- 2、查询的数据类型与字段类型不一致
- 3、违反了索引的最左匹配原则
- 4、全表扫描更快
- 5、where语句中索引列使用了负向查询,可能会导致索引失效
- 6、索引字段可以为null,使用is null或is not null时,可能会导致索引失效
- 参考:
1、对索引字段进行了运算或者使用了函数
- 索引列上使用内置函数,一定会导致索引失效
索引失效:
mysql> select count(*) from tradelog where month(t_modified)=7;
t_modified索引生效:
mysql> select count(*) from tradelog where t_modified='2018-7-1’
下面是这个 t_modified 索引的示意图。方框上面的数字就是 month() 函数对应的值。
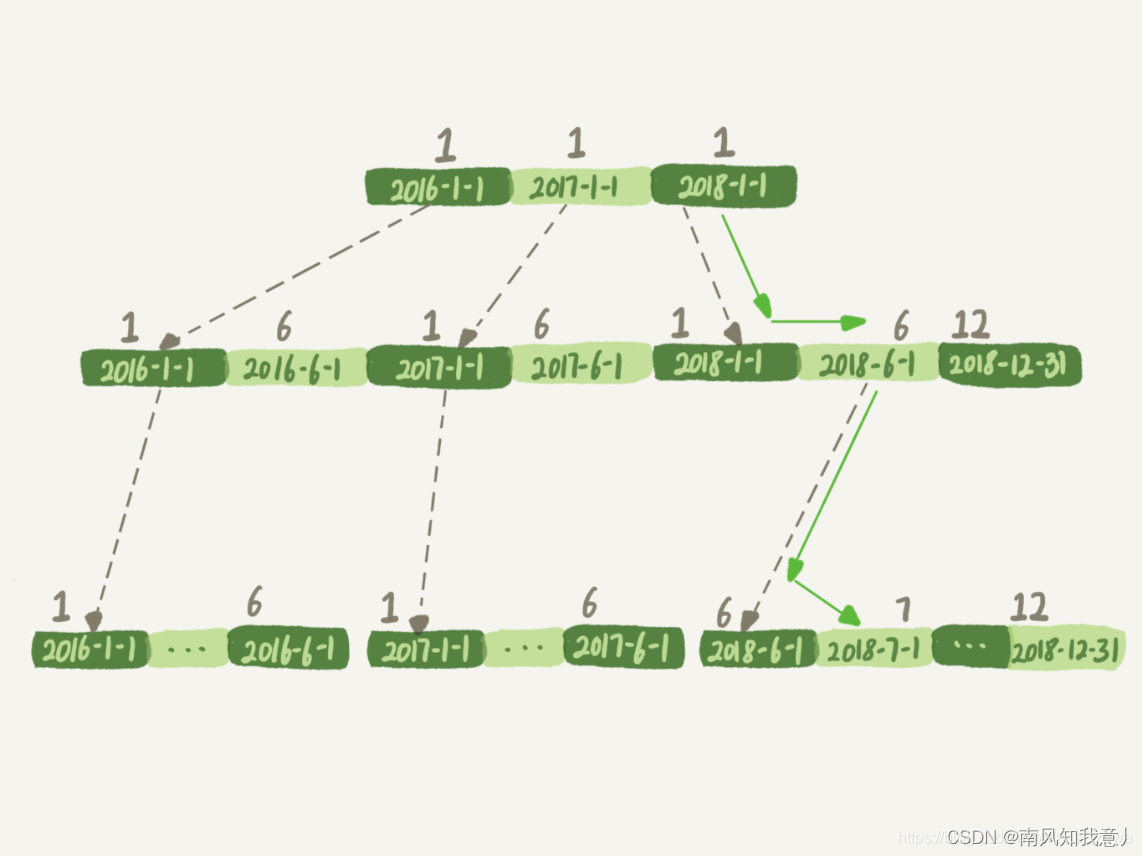
如果你的 SQL 语句条件用的是 where t_modified='2018-7-1’的话,引擎就会按照上面绿色箭头的路线,快速定位到 t_modified='2018-7-1’需要的结果。
实际上,B+ 树提供的这个快速定位能力,来源于同一层兄弟节点的有序性。
但是,如果计算 month() 函数的话,你会看到传入 7 的时候,在树的第一层就不知道该怎么办了。
也就是说,对索引字段做函数操作,可能会破坏索引值的有序性,因此优化器就决定放弃走树搜索功能。
- col + 1 = 100不会走索引,col = 99会走索引
mysql> select name from tradelog where id + 1=100
改为
mysql> select name from tradelog where id =99
2、查询的数据类型与字段类型不一致
- 例如字段id是varchar的,但是匹配的值时number类型的,数据库会进行隐式转换,也会导致不走索引
此时索引失效
select xx from xx where id = 1 等价于
select xx from xx where CAST(id AS signed int) = 1
- 但是字段task_id是int,匹配类型是Varchar类型,索引则不会失效
EXPLAIN SELECT * FROM all_info WHERE task_id='835';

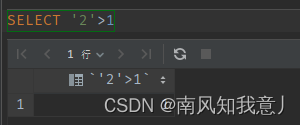
- 判断类型转换
- select “2” > 1 的结果:
如果规则是“将字符串转成数字”,那么就是做数字比较,结果应该是 1;
如果规则是“将数字转成字符串”,那么就是做字符串比较,结果应该是 0
3、违反了索引的最左匹配原则
- like查询以%开头时,会导致索引失效
EXPLAIN SELECT * FROM sha1_virus_name WHERE virus_name_id LIKE '%EB801BEEEE%'; --all
改为:
EXPLAIN SELECT * FROM sha1_virus_name WHERE virus_name_id LIKE 'EB801BEEEE%'; --range
- 索引中字段顺序为col1,col2,col3,查询的时候col1 = 1 and col3 =2 and col2 =2不会走索引,mysql8.x做了优化,即使顺序不对也会走索引
- 违背最左匹配原则
当创建一个联合索引的时候,如(k1,k2,k3),相当于创建了(k1)、(k1,k2)和(k1,k2,k3)三个索引,这就是最左匹配原则。
索引失效:
select * from t where k2=2;
select * from t where k3=3;
slect * from t where k2=2 and k3=3;
仅命中k1
slect * from t where k1=2 and k3=3;
4、全表扫描更快
例表总行数10000行,col > 100 行数是9w多行,这时候走索引会遍历9W多条数据,要回表9w多次,数据库优化器就会进行评估,评估后全表扫描比索引快,就会自动变成全包扫描不走索引
5、where语句中索引列使用了负向查询,可能会导致索引失效
负向查询包括:NOT、!=、<>、!<、!>、NOT IN、NOT LIKE等,
并不绝对会索引失效,这要看MySQL优化器的判断,全表扫描或者走索引哪个成本低了。
6、索引字段可以为null,使用is null或is not null时,可能会导致索引失效
其实单个索引字段,使用is null或is not null时,是可以命中索引的,字段要设为not null并提供默认值
- null的列使索引/索引统计/值比较都更加复杂,对MySQL来说更难优化。
- null 这种类型MySQL内部需要进行特殊处理,增加数据库处理记录的复杂性;同等条件下,表中有较多空字段的时候,数据库的处理性能会降低很多。
- null值需要更多的存储空,无论是表还是索引中每行中的null的列都需要额外的空间来标识。
- 对null 的处理时候,只能采用is null或is not null,而不能采用=、in、<、<>、!=、not in这些操作符号。
如:where name!=’shenjian’,如果存在name为null值的记录,查询结果就不会包含name为null值的记录。
参考:
https://juejin.cn/post/6844904022885793806
https://blog.csdn.net/MariaOzawa/article/details/107363136





![[Linux入门篇]一篇博客解决C/C++/Linux System Call文件操作接口的使用](https://img-blog.csdnimg.cn/img_convert/bad446c4802dc09d0660be5bb815c0a6.png)