接上文:RBucket对象桶 -> Redisson系列-1(让redis操作更优雅)_子书少卿的博客-CSDN博客
本质上布隆过滤器是一种数据结构,是一种比较巧妙的概率性数据结构,特点是可以高效的插入和查询,可以用来判断:“某个值一定不存在或可能存在”。
优点:相比于传统的list、set、map等数据结构,更高效、占用空间更小(不需要存储数据本身,只需要存储数据对应hash比特位);
缺点:返回的结果是概率性的,而不是确切的;不支持删除元素
HashMap 的问题
讲述布隆过滤器的原理之前,我们先思考一下,通常你判断某个元素是否存在用的是什么? 应该蛮多人回答 HashMap 吧,确实可以将值映射到 HashMap 的 Key,然后可以在 0(1)的时间复杂度内返回结果,效率奇高。但是 HashMap 的实现也有缺点,例如存储容量占比高,考虑到负载因子的存在,通常空间是不能被用满的,而一旦你的值很多例如上亿的时候,那 HashMap 占据的内存大小就变得很可观了。
还比如说你的数据集存储在远程服务器上,本地服务接受输入,而数据集非常大不可能一次性读进内存构建 HashMap 的时候,也会存在问题。
布隆过滤器数据结构
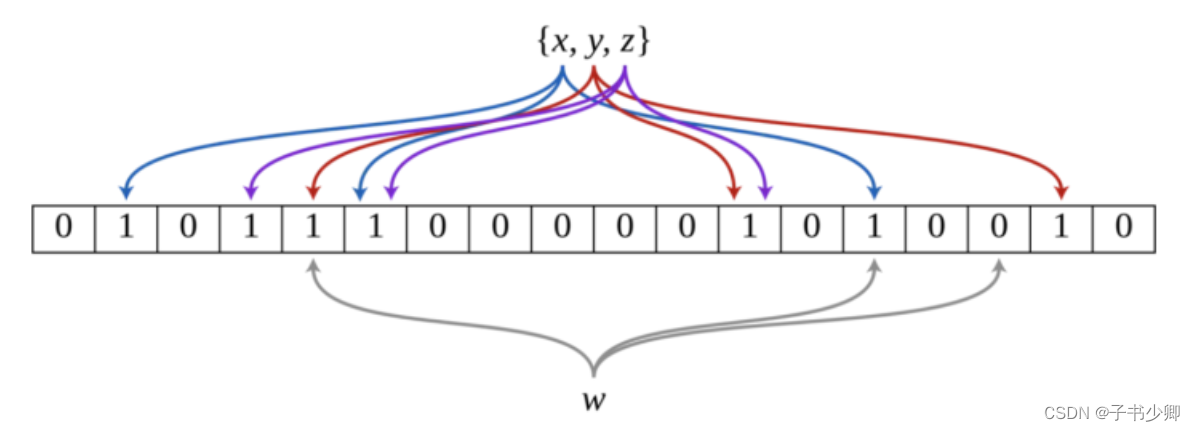
布隆过滤器是一个 bit 向量或者说 bit 数组
详解布隆过滤器的原理、使用场景和注意事项
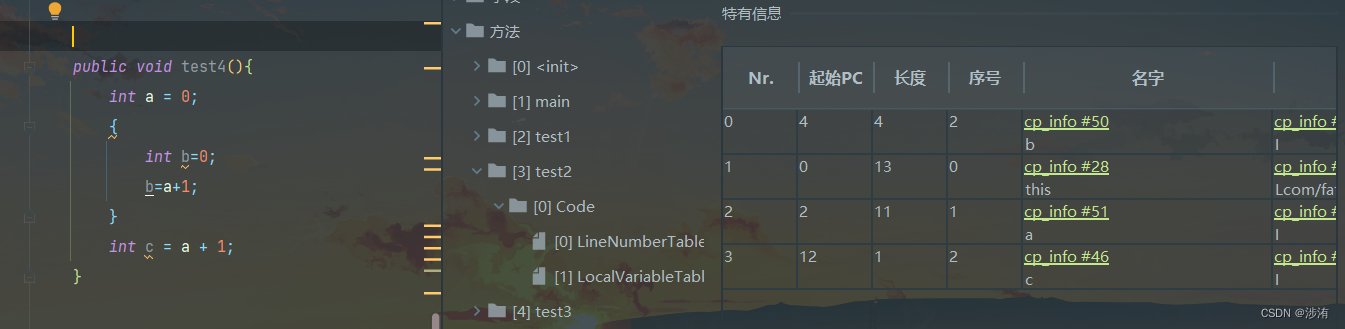
如果我们要映射一个值到布隆过滤器中,我们需要使用多个不同的哈希函数生成多个哈希值,并对每个生成的哈希值指向的 bit 位置 1,例如针对值和三个不同的哈希函数分别生成了哈"baidu"希值 14、7,则上图转变为:
测试代码:
@Service
public class BloomService {
private static final String BLOOM_KEY = "bloom:key:";
@Resource
private RedissonClient redisson;
/**
* 测试布隆过滤器
* @param id
* @return
*/
public Integer test(Integer id){
RBloomFilter<Integer> bloomFilter = redisson.getBloomFilter(BLOOM_KEY);
// 初始化布隆过滤器,第一个参数:预计存放的数据量(实际存放过程中如果不够,会自动扩充,最好初始化够);第二个参:误差
bloomFilter.tryInit(1000000L,0.01);
if(bloomFilter.contains(id)){
System.out.println(id+"存在");
}else {
System.out.println(id+"bu存在");
// 入布隆过滤器
bloomFilter.add(id);
}
return 1;
}
}问题:在大数据集合场景下,如果使用该场景,怎样保证返回数据的准确性呢,如果该数据类型不能保证数据的准确定,用在哪种实际的场景下比较合适呢?
由于可能出现哈希碰撞,不同元素计算的哈希值有可能一样,导致一个不存在的元素有可能对应的比特位为1,这就是所谓“假阳性”(false positive)。相对地,“假阴性”(false negative)在BF中是绝不会出现的。因此,Bloom Filter不适合那些“零错误”的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter通过极少的错误换取了存储空间的极大节省。
参考自:
https://edu.csdn.net/learn/27749/375603?spm=3001.4143
布隆过滤器Bloom Filter简介_多啦@不懂a梦的博客-CSDN博客