前言:重温经典,整理了一些几年前做轻量级网络的论文,其中的深度可分离卷积和通道shuffle的思想至今也在沿用
(这几天都没看论文然而实验还是没跑出来,不卷会议了,开始摆烂…)
论文地址:
MobileNets【here】
Xception【here】
ShuffleNet【here】
深度可分离卷积(MobileNets/Xception)
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
MobileNets放在之前将,是我觉得MobileNets将深度可分离卷积的原理阐释得更清楚一些,Xception更多的是从inception系列的发展来展开的
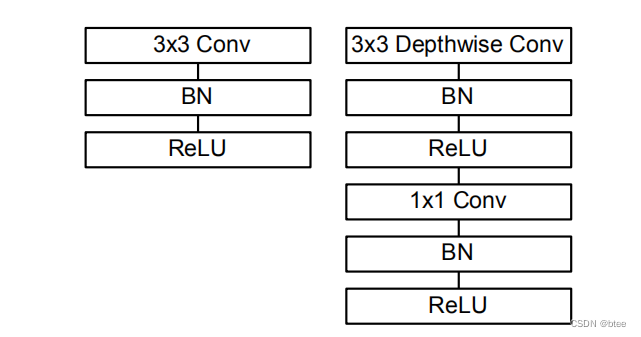
首先深度可分离卷积的图示
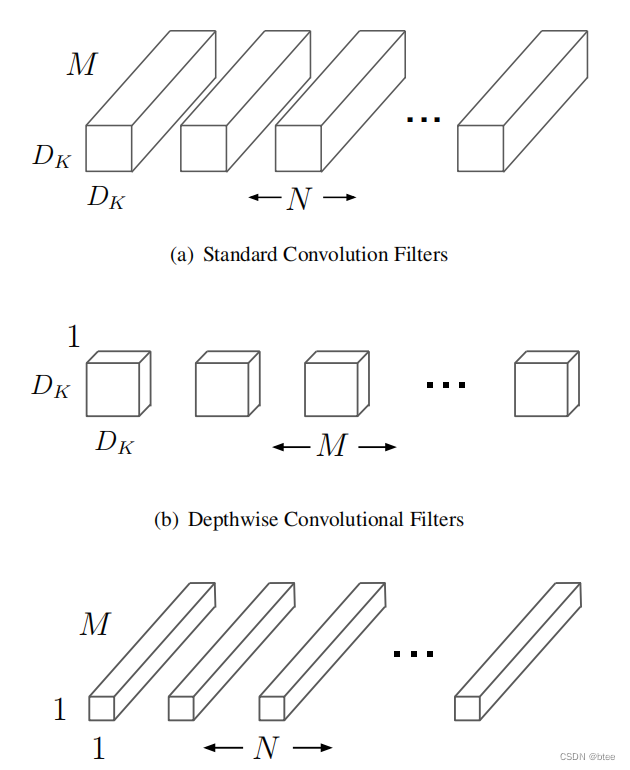
这个图很生动形象的解释了什么是深度可分离卷积,即把一个有着空间大小(3*3)和特征维度(c_in)的卷积核,拆成一个单位空间上的特征维度的卷积pointwise convolution 和每个单位特征层上的有着空间大小的卷积depthwise convolution
一个深度可分离卷积包括下图右边的部分
深度可分离卷积与普通卷积的计算量和参数量对比
普通卷积的卷积核大小
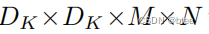
在一个Df * Df的图上的卷积计算量
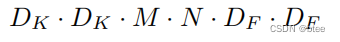
深度可分离卷积卷积核大小
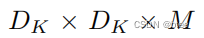
计算量
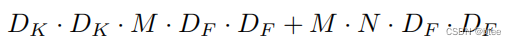
计算量的比较
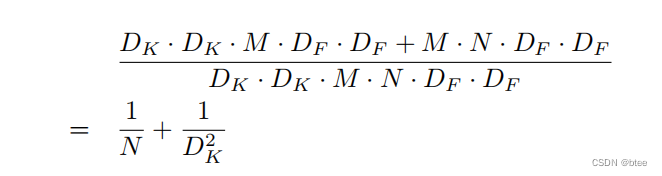
两个超参数
第一个超参数是网络的宽度(这里作者不调深度而是调宽度是因为实验证明差不多参数量和计算量的情况下,更窄的网络比更浅的网络性能会好一点)
第二个超参数是输入图像的分辨率,通过减小输入图像的分辨率可以减小网络的运算量
Xception: Deep Learning with Depthwise Separable Convolutions
首先inception系列的思想是用pointwise卷积把特征映射到不同区域,再分别对它进行分不同卷积操作,最后融合特征
比如经典inception v3
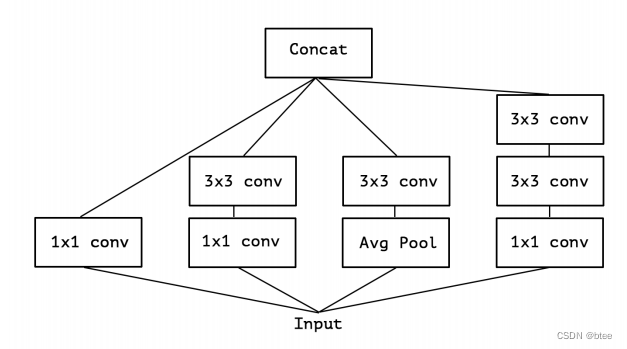
简化后其实可以看做(把AVGpooling 那一支去掉)
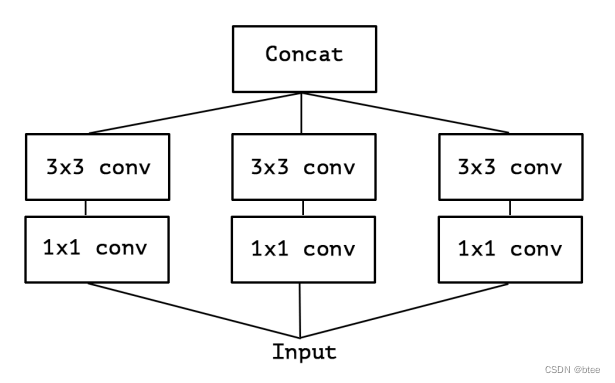
而这个简化后的版本,有可以看做用一个很大的pointwise卷积,将特征维扩展到原来的3倍,划分到不同区域,再在不同区域用3 * 3conv,这和简化版本inception是等价的
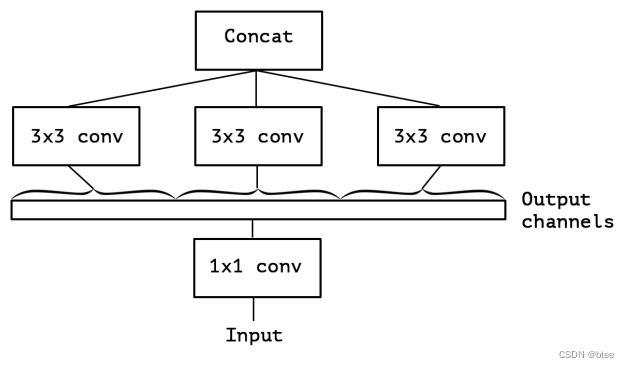
最后,可以把这个简化版本Inception极端化,即每一个特征通道就是一个区域。因此就有了Xception的Idea
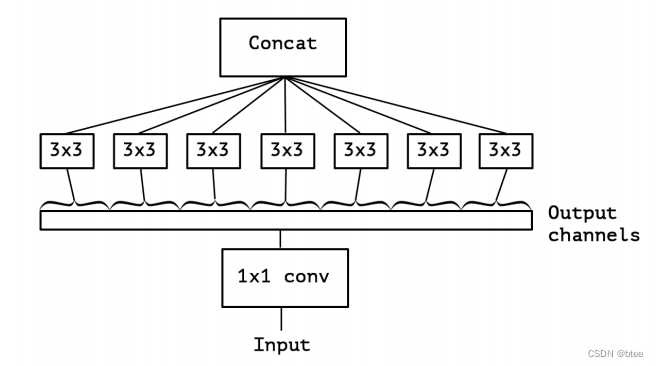
这里作者指出,极端化后的inception和深度可分离卷积的区别有两点,第一点是深度可分离卷积是先进行depthwise卷积再进行pointwise卷积,但是极端的inception则反过来(作者认为这个区别不大)
第二点则是,深度可分离卷积每层后加Relu激活函数,但是极端版本不需要relu,作者也做实验分析了,加激活函数的效果
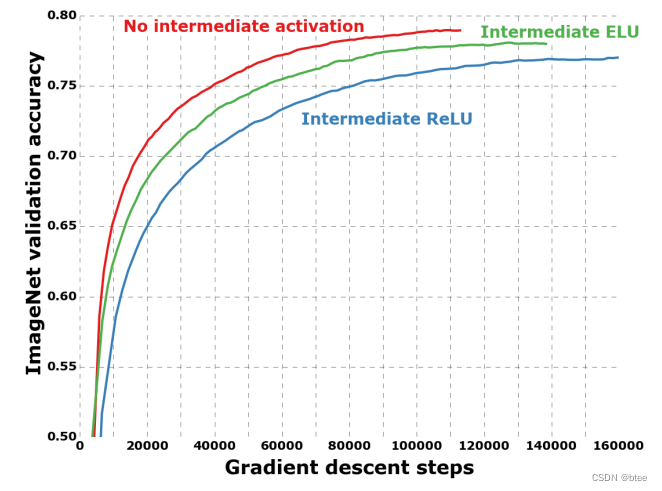
对比Inception中的中间激活层起的作用,作者给出的解释是,对于浅层卷积,比如只有一个通道的depthwise卷积,加了激活可能会损害性能
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile
在原有的深度可分离卷积的基础上还有优化空间,即对于特征维过于宽的情况,pointwise卷积显得并没有那么高效
因此可以继续对pointwise卷积进行分组,
分组后的参数量和计算量的变化(引用来自博文)

但是对通道分组后,组与组之间就不相关了
因此进行一次channelshuffle
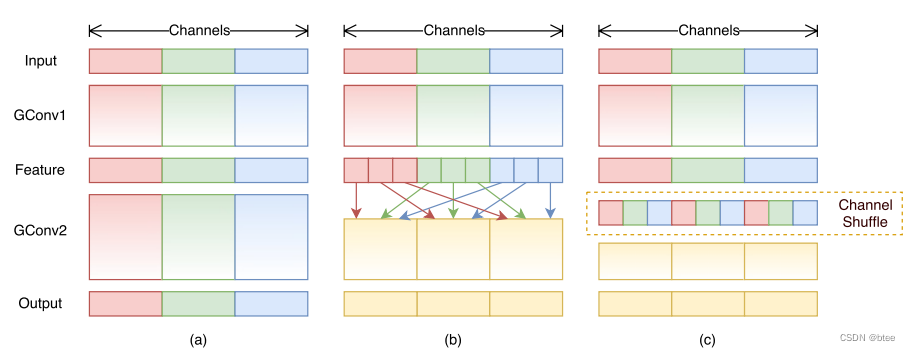
所以,shufflenet 的设计改变可以由下图所示,Pointwise分组卷积+channelshffle+3 * 3 depthwise conv +Pointwise分组卷积
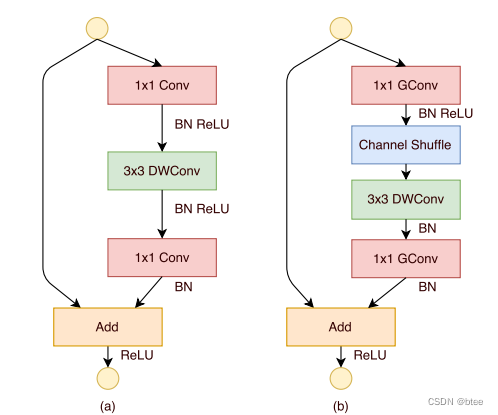
最后作者做实验证明了shuffleNet设计后有性能提升
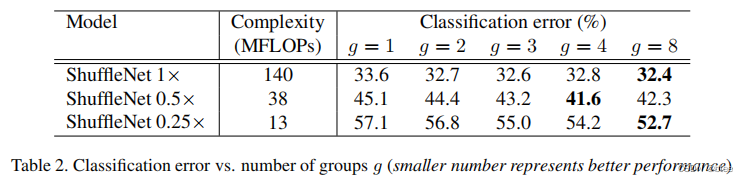
注意,这里并不是对同样的网络,加group和不加group的性能比较,而是对于加了group和channel shuffle后再加宽网络,保持差不多的网络参数量进行的比较
总结
深度可分离卷积证实了,空间和通道分开卷积一定程度上平衡好了性能和效率,对于3D时空任务而言,能不能实现空间和时间维的分开卷积呢?待我查查相关资料再回来看这个问题







![[Linux入门篇]一篇博客解决C/C++/Linux System Call文件操作接口的使用](https://img-blog.csdnimg.cn/img_convert/bad446c4802dc09d0660be5bb815c0a6.png)