一、Meta 全新大语言模型 LLaMA 正通过种子公开发放
2 月 24 日,Meta 公司发布了新的大模型系列 —— LLaMA(Large Language Model Meta AI)。Meta 宣称,LLaMA 规模仅为竞争对手 ChatGPT 的“十分之一”,但性能却优于 OpenAI 的 GPT-3 模型。
并且,提到了“通过使用torrent更高效地分发,节省带宽”,github截图:
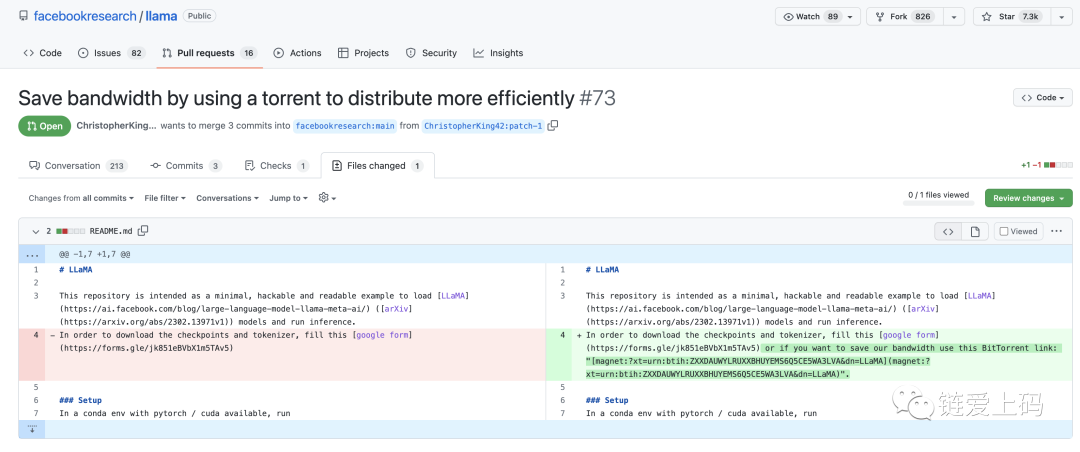
GitHub 链接:https://github.com/facebookresearch/llama/pull/73/files
对此,下面发表了不同的意见:
二、超越 ChatGPT,LLaMA 强在哪里?
文中指出,这个LLaMA名字的由来?反正Large Language Model Meta Artificial Intelligence缩写为LLMMAI,有点太接近LMAO了。我们可以将 LLMMAI 制作成该主题的各种变体,甚至有相当数量的咒骂。Large Language AI Model 会缩写为 LLAIM,这很有趣——“是的,我们正在使用来自 Facebook 的 LLAIM 基础模型”——显然是威尔士盖尔语,但你可以看到为什么 Meta Platforms 没有使用这些名称它的基础模型。“Large Language As Meta Ascertains”会让 LLAMA 成为现实,但它并不十分成功。这是一个想法:嘿元平台,你实际上可以使用人工智能想出一个更好的名字来打 LLAMA 缩写——不允许小写的“A”,那是作弊——或者更好的是,应用一些好的 ol' 人类智慧,想出一个允许双关式缩写的东西,但仍然很好感觉。
还指出,LLaMA 模型是根据世界上二十种最流行的拉丁语和西里尔字母表语言的文本进行训练的。论文LLaMA:Open and Efficient Foundation Language Models描述了该模型以及它与 GPT、Gopher、Chinchilla 和 PaLM 的比较。后一种模型利用了广泛的公共数据,但也有非公开可用或未记录的文本数据。LLaMA 专门针对公开可用的数据集进行培训,因此与开源兼容——尽管它本身尚未开源。
LLaMA 在某种意义上是对Training Compute-Optimal Large Language Models论文的直接反应,该论文于 2022 年 3 月发表,描述了 Chinchilla 模型及其竞争对手。并且在模型大小、计算预算、令牌数量、训练时间、推理延迟和性能方面进行了对比。
LLaMA 模型已使用 67 亿、130 亿、320 亿和 652 亿个参数进行训练,其中两个较小的参数使用 1 万亿个代币,两个较大的参数使用 1.4 万亿个代币。Meta Platforms 在 2,048 个 Nvidia“Ampere”A100 GPU 加速器和 80 GB HBM2e 内存上使用这 1.4 万亿个令牌测试了最大的 LLaMA-65.2B 模型,并且花费了 21 天(以每个 GPU 每秒 380 个令牌的速度)训练模型。这不是特别快。然而,Meta AI 研究人员表示,LLaMA-13B 模型“在大多数基准测试中都优于 GPT-3,尽管它的体积小了 1`09 倍。” 难点在于:“我们相信该模型将有助于使 LLM 的访问和研究民主化,因为它可以在单个 GPU 上运行。
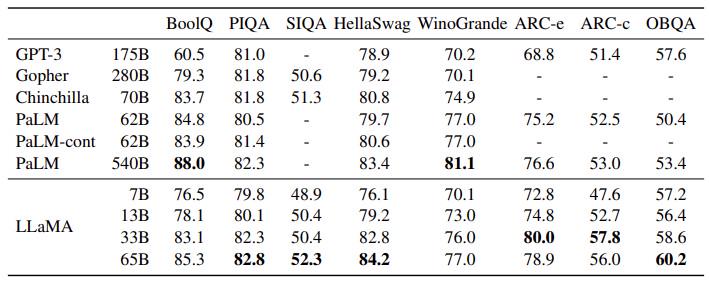
还有许多性能测试的对比,下面图展示了各种模型在“常识推理”任务上的零样本表现:
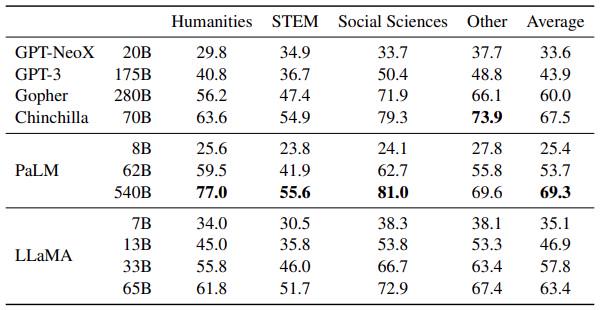
Meta Platforms 显示了 LLaMA 在人文、科学、技术和数学、社会科学以及其他领域的多项选择测试中的测试结果。看看这张表:
下面更有趣的是,因为它显示了 LLaMA 在不同参数计数下如何在各种常识推理和问答基准上与 Chinchilla 模型相比较:
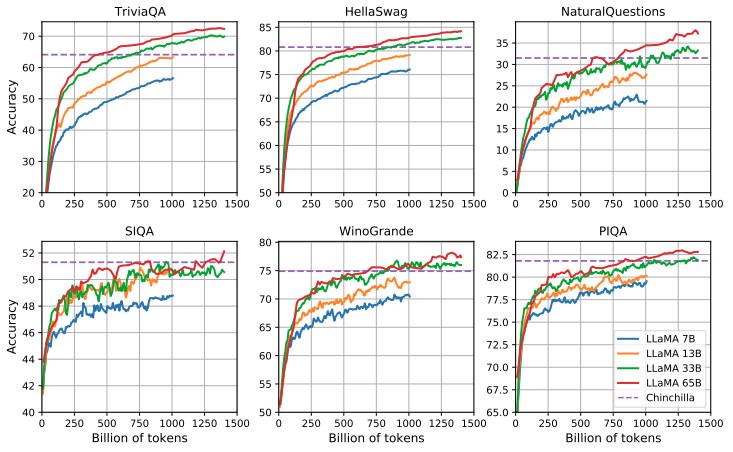
如您所见,LLaMA-33B 和 LLaMA-65B 可以与 Chinchilla-70B 抗衡,当代币数量达到 1 万亿甚至更多时超过它。
参考链接:
https://www.nextplatform.com/2023/02/28/move-over-chatgpt-meta-platforms-llama-makes-some-drama/




![[Linux入门篇]一篇博客解决C/C++/Linux System Call文件操作接口的使用](https://img-blog.csdnimg.cn/img_convert/bad446c4802dc09d0660be5bb815c0a6.png)