神经网络的优化除了之前提到的一些硬件优化手段(AI硬件加速拾遗)之外,还有很多图层方面的优化手段。大家好啊,我是董董灿。
而且图层方面的优化,有时效果更佳。往往一个有效的优化,甚至可以“消除”掉一个算子的存在。
这里的“消除”用的引号,是因为这个算子并未被真正消除,从整个神经网络的计算流上看,这个算法仍然存在。
只不过,它的计算过程被其他计算过程掩盖住了,像是被“消除”了。
这里介绍一种算子融合并且使用图层流水进行网络优化的方法。
先看Resnet50 中一个网络片段。关于该网络的算法原理,可以参考以前的文章长文解析Resnet50的算法原理。
下图展示的是 Resnet50 中第一个 block 结束时的图结构。

该结构中,存在卷积算子和加法算子,我们可以利用融合手段,将红框标出的两个算子融合成一个算子。
将卷积和加法融合成一个算子后,再通过指令调度,实现卷积和加法指令的 ping-pong 流水,便可以利用卷积的计算掩盖掉加法的计算。
关于ping-pong流水的概念,可以参考 AI加速(五)| 一个例子看懂流水——从指令到算法 来进行理解。
这里说一点,为什么卷积计算可以掩盖掉加法计算呢?
因为在相同的输入输出规模的情况下,由于卷积的计算是乘累加,而加法的计算是单纯地加法,因此,在绝大部分的硬件上,一般都是卷积的计算耗时要大于加法。
那怎么掩盖呢?
正常的一个卷积后面如果跟一个加法的话,它的计算流从上到下是这样的:
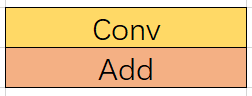
先计算卷积Conv,再计算加法Add。假设卷积的计算时间是 A, 加法的计算时间是 B,那么总共的耗时就是 A+B。
这很简单,大家都会算。
那如果将两个算子融合到一起,同时将一张输入图片(Feature Map)切成一半,分两次来运算。每次运算使用 ping-pong memory 来实现计算流水。
那两次计算的计算流从上到下是这个样子。

左侧 Conv 和 Add 计算前半张图,使用ping memory来计算,右侧 Conv 和 Add 计算后半张图,使用pong memory来计算。
这里说明一下:Conv 和 Conv 是不能并行的,因为一般一个硬件上,只有一个Conv 的硬件计算单元,当然,有多个的又是另外的话题了,这里暂时不考虑。
这个时候,可以看到第二行中,第一个 Add 和第二个 Conv 处在一个时间片内,同时由于使用的是不同的memory,两者可以完全并行。
两者并行完成计算,此时,Conv 就掩盖掉了左侧 Add 的时间。
而整个计算流消耗的时间便是:A/2 + A/2(掩盖掉了Add 的 B/2) + B/2 = A + B/2。
可以看到,此时整体的计算耗时已经比不进行流水时,减少了一半的加法。
那如果将图进一步切分,切成4份来进行运算呢?
那此时的计算流从上到下是这个样子:

由于第2、3、4行的 conv 分别掩盖掉了其左侧的Add 计算,因此,整个计算流所消耗的时间变成了 A + B/4。
可以看到,将图切的越小,流水起来之后,掩盖掉的加法的时间越多,剩余的加法的时间越少。
如果切的再多,加法的耗时甚至可以忽略掉了。

这种方法很简单,也很容易实现,但从硬件上来说,需要硬件满足以下条件:
-
卷积计算单元和加法计算单元在硬件上是独立的。
-
硬件有成熟的同步机制来完成卷积计算和加法计算的同步
为什么需要同步机制呢?因为每一个横向的时间片段中,Add 和 Conv 没有任何数据依赖,但是纵向的看,Add 的计算总是依赖于上面的 Conv 的输出。
因此,需要在每一个横向时间片段起始时,完成上一个时间片段中 Conv 计算和 Add 计算的同步。
只要硬件上满足了以上条件,软件上的切图、排流水、融合操作其实很简单。
很多深度学习编译器,如TVM提供了图融合和自动 tiling 策略,可以做到切图,并且调度指令完成流水排布。
即使编译器限于某些开发难度限制,无法自动完成融合和tiling,也可以手动写一个融合大算子出来,手动排指令流水,也不是很难的事。
总之,这种方法作为一个行之有效的融合方法,可以用在很多的神经网络性能优化中。
而且效果很出众。
深度学习加速优化,关注我,一起学习交流。