1.3 入门案例:WordCount
入门案例与SparkStreaming的入门案例基本一致:实时从TCP Socket读取数据(采用nc)实时进行词频统计WordCount,并将结果输出到控制台Console。
文档:http://spark.apache.org/docs/2.4.5/structured-streaming-programming-guide.html#quick-example
功能演示
运行词频统计WordCount程序,从TCP Socket消费数据,官方演示说明截图如下:
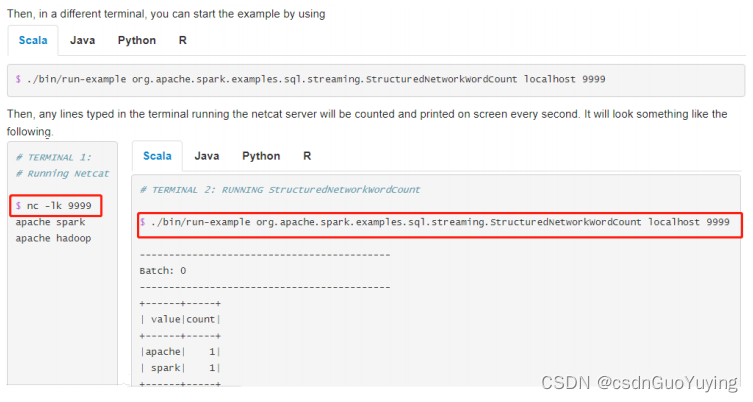
演示运行案例步骤:
第一步、打开终端Terminal,运行NetCat,命令为:nc -lk 9999
第二步、打开另一个终端Terminal,执行如下命令
# 官方入门案例运行:词频统计
/export/server/spark/bin/run-example \
--master local[2] \
--conf spark.sql.shuffle.partitions=2 \
org.apache.spark.examples.sql.streaming.StructuredNetworkWordCount \
node1.itcast.cn 9999
# 测试数据
spark hadoop spark hadoop spark hive
spark spark spark
spark hadoop hive
发送数据以后,最终统计输出结果如下:

Socket 数据源
从Socket中读取UTF8文本数据。一般用于测试,使用nc -lk 端口号向Socket监听的端口发送数据,用于测试使用,有两个参数:
参数一:host,主机名称,必须指定参数
参数二:port,端口号,必须指定参数
范例如下所示:

Console 接收器
将结果数据打印到控制台或者标准输出,通常用于测试或Bedug使用,三种输出模式OutputMode(Append、Update、Complete)都支持,两个参数可设置:
参数一:numRows,打印多少条数据,默认为20条;
参数二:truncate,如果某列值字符串太长是否截取,默认为true,截取字符串;
范例如下所示:

编程实现
可以认为Structured Streaming = SparkStreaming + SparkSQL,对流式数据处理使用SparkSQL数据结构,应用入口为SparkSession,对比SparkSQL与SparkStreaming编程:
- Spark Streaming:将流式数据按照时间间隔(BatchInterval)划分为很多Batch,每批次数据封装在RDD中,底层RDD数据,构建StreamingContext实时消费数据;
- Structured Streaming属于SparkSQL模块中一部分,对流式数据处理,构建SparkSession对象,指定读取Stream数据和保存Streamn数据,具体语法格式:
- 加载数据Load:读取静态数据【spark.read】、读取流式数据【spark.readStream】
- 保存数据Save:保存静态数据【ds/df.write】、保存流式数据【ds/df.writeStrem】
词频统计案例:从TCP Socket实消费流式数据,进行词频统计,将结果打印在控制台Console。
第一点、程序入口SparkSession,加载流式数据:spark.readStream
第二点、数据封装Dataset/DataFrame中,分析数据时,建议使用DSL编程,调用API,很少使用SQL方式
第三点、启动流式应用,设置Output结果相关信息、start方法启动应用
完整案例代码如下:
import org.apache.spark.sql.streaming.{OutputMode, StreamingQuery}
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* 使用Structured Streaming从TCP Socket实时读取数据,进行词频统计,将结果打印到控制台。
*/
object StructuredWordCount {
def main(args: Array[String]): Unit = {
// TODO: 构建SparkSession实例对象
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")
.config("spark.sql.shuffle.partitions", "2") // 设置Shuffle分区数目
.getOrCreate()
// 导入隐式转换和函数库
import spark.implicits._
import org.apache.spark.sql.functions._
// TODO: 1. 从TCP Socket 读取数据
val inputStreamDF: DataFrame = spark.readStream
.format("socket")
.option("host", "node1.itcast.cn").option("port", 9999)
.load()
/*
root
|-- value: string (nullable = true)
*/
//inputStreamDF.printSchema()
// TODO: 2. 业务分析:词频统计WordCount
val resultStreamDF: DataFrame = inputStreamDF
.as[String] // 将DataFrame转换为Dataset进行操作
// 过滤数据
.filter(line => null != line && line.trim.length > 0)
// 分割单词
.flatMap(line => line.trim.split("\\s+"))
.groupBy($"value").count() // 按照单词分组,聚合
/*
root
|-- value: string (nullable = true)
|-- count: long (nullable = false)
*/
//resultStreamDF.printSchema()
// TODO: 3. 设置Streaming应用输出及启动
val query: StreamingQuery = resultStreamDF.writeStream
// TODO: 设置输出模式:Complete表示将ResultTable中所有结果数据输出
// .outputMode(OutputMode.Complete())
// TODO: 设置输出模式:Update表示将ResultTable中有更新结果数据输出
.outputMode(OutputMode.Update())
.format("console")
.option("numRows", "10").option("truncate", "false")
// 流式应用,需要启动start
.start()
// 流式查询等待流式应用终止
query.awaitTermination()
// 等待所有任务运行完成才停止运行
query.stop()
}
}
其中可以设置不同输出模式(OutputMode),当设置为Complete时,结果表ResultTable中所有数据都输出;当设置为Update时,仅仅输出结果表ResultTable中更新的数据。