本篇参考bilibili如何在本地微调DeepSeek-R1-8b模型_哔哩哔哩_bilibili
上篇:(小白0基础) 租用AutoDL服务器进行deepseek-8b模型微调全流程(Xshell,XFTP) —— 准备篇
初始变量
max_seq_length = 2048
dtype = None
load_in_4bit = True
- 单批次最大处理模型大小
- dype 参数的数据精度,包括各种矩阵中的数据的精例如 float32(高精度)、float16(半精度),选择None则是自动选择精度
- 4bit量化,可以将模型部署在消费级的显卡上,而不损失大量的精度
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/DeepSeek-R1-Distill-Llama-8B",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
token = hf_token,
)
- 解包操作,对于该方法复制给两个变量
question = "A 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?"
## 模型输入
FastLanguageModel.for_inference(model) # Unsloth has 2x faster inference!
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])
- input_ids这里是将字符转换为token
- max_new_tokens 生成的最大长度
- use_cache 缓存开启,也就是保存之前的键值对(这里还不太懂)
- attention_mask 指的是 Padding Mask 指的是忽略输入文本长度,针对样本不同的token填充例如[PAD],在矩阵中赋值为0
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth", # True or "unsloth" for very long context
random_state=3407,
use_rslora=False,
loftq_config=None,
)
-
Lora的基本概念,通过分解detw的值ΔW=A⋅B
-
r 分解矩阵的秩的大小:d×r+r×k
-
lora_alpha, LoRA缩放因子(ΔW = α * A*B)通常为r的倍数
-
lora_dropout 丢弃率,防止过拟合
-
bias 偏置项,减少训练量 wx+b的b
-
andom_state,用来确保实验可以复现(保存初始化元素)
-
use_rslora lora变体
-
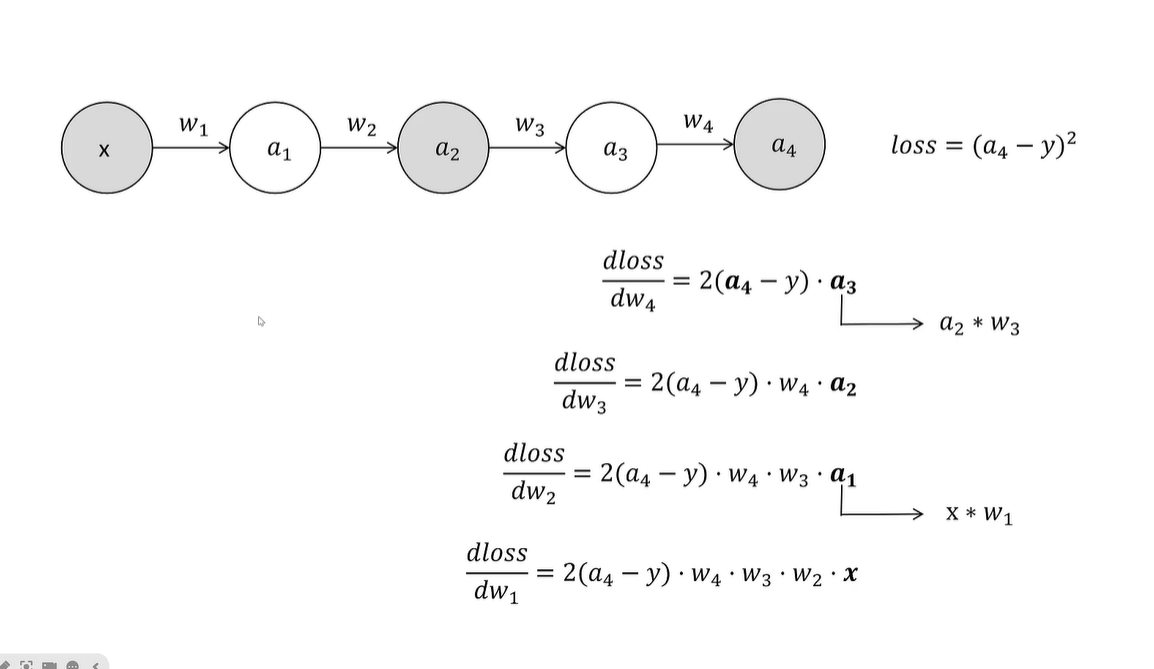
use_gradient_checkpointing 梯度检查点
Forward: [Layer1-5 → 检查点 → Layer6-10 → 检查点 → …] 仅存储检查点激活
Backward:-
从最后一个检查点重计算 Layer6-10
-
计算 Grad10-6
-
从中间检查点重计算 Layer1-5
-
计算 Grad5-1
具体来说,就是删除其中一些向量a,我们在反向传播的时候要用到的a通过再次前向传输进行计算输出
用空间换时间
-
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=max_seq_length,
dataset_num_proc=2,
args=TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
# Use num_train_epochs = 1, warmup_ratio for full training runs!
warmup_steps=5,
max_steps=60,
learning_rate=2e-4,
fp16=not is_bfloat16_supported(),
bf16=is_bfloat16_supported(),
logging_steps=10,
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="outputs",
),
)
-
SFTTrainer是trl库中专门用于对语言模型进行监督式微调(Supervised Fine-Tuning)的训练器,通常用于指令微调(Instruction Tuning)。 -
dataset_num_proc=2
作用: 指定在预处理数据集(例如,进行分词)时使用的 CPU 进程数量。
-
per_device_train_batch_size=2 Batch Size 是指在单次模型权重更新前,模型处理的样本数量。
-
gradient_accumulation_steps=4 小批次反向传播
-
warmup_steps 在训练开始的前
warmup_steps步(这里是 5 步),学习率会从一个很小的值(通常是 0)逐渐线性增加到设定的learning_rate。这有助于在训练初期稳定模型,避免因初始梯度过大导致训练发散。- max_steps=60 训练将在执行了 60 次权重更新后停止,无论处理了多少数据或完成了多少轮(Epoch)。如果同时设置了
num_train_epochs,max_steps会覆盖它。这里设置为 60,表明这是一个非常短的训练过程,可能用于快速验证代码或流程是否正常。注释提示完整训练应使用num_train_epochs。
- max_steps=60 训练将在执行了 60 次权重更新后停止,无论处理了多少数据或完成了多少轮(Epoch)。如果同时设置了
-
num_train_epochs = 1 删除
max_steps=60,设置num_train_epochs = 1作为 -
fp16=not is_bfloat16_supported(), 数据精度问题
bf16=is_bfloat16_supported(), -
logging_steps=10 设置记录训练指标(如损失、学习率等)的频率
-
optim=“adamw_8bit” adam优化器
-
-
weight_decay=0.01 权重衰减是一种正则化技术,通过在损失函数中添加一个与权重平方和成正比的惩罚项,来防止模型权重变得过大,有助于减少过拟合。区别(L2)
-
lr_scheduler_type=“linear” 学习率调度器负责在训练过程中动态调整学习率,这里是线性增加
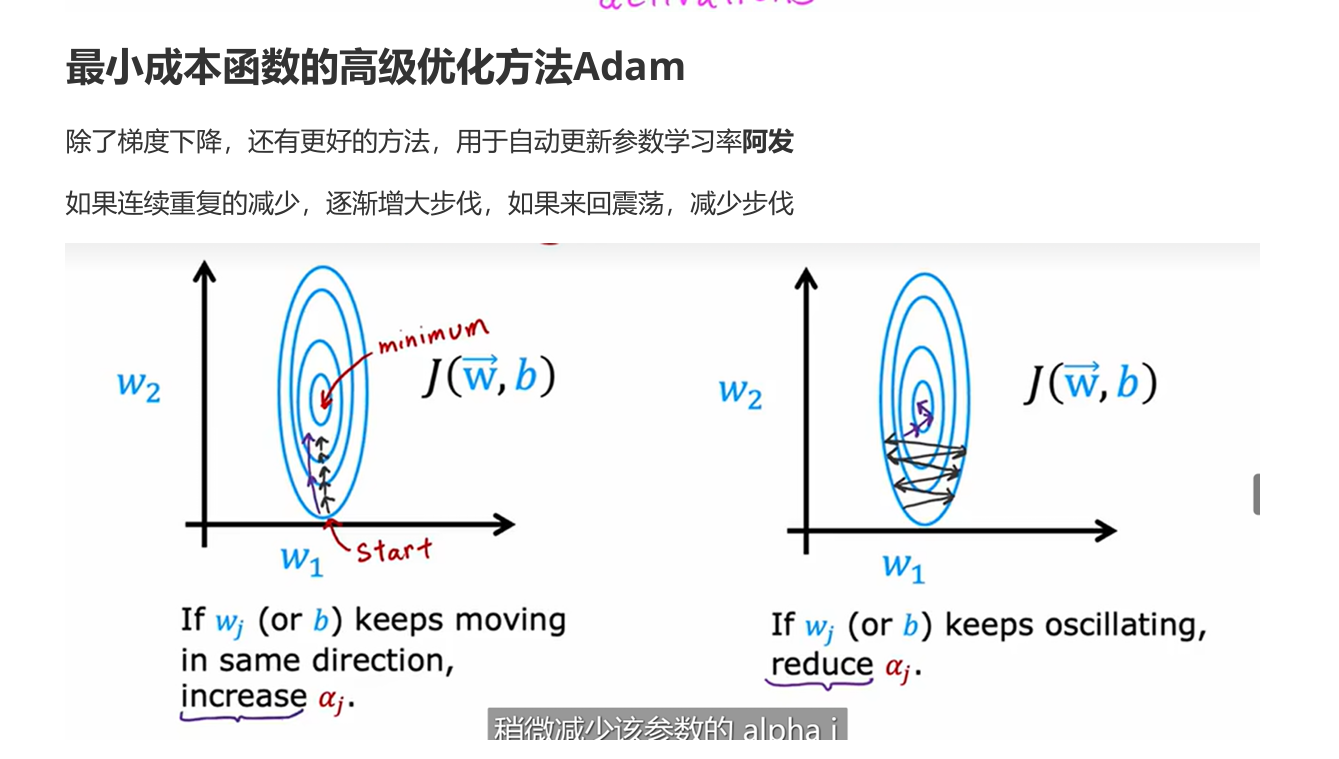
这里的学习处理的一些参数设置关系
训练开始 (Step 0 -> Step 5):
- Warmup 控制:
warmup_steps=5生效。 - Scheduler (Linear) 配合: 学习率从 0 开始线性增加。
- Optimizer (AdamW_8bit) 执行: 在每一步使用这个逐渐增大的学习率和计算出的梯度来更新模型权重。
预热结束 (Step 5):
- 学习率达到峰值
learning_rate=2e-4。
训练继续 (Step 6 -> Step 60):
- Scheduler (Linear) 控制:
lr_scheduler_type="linear"生效。学习率从2e-4开始线性下降,目标是在第 60 步时降到 0。 - Optimizer (AdamW_8bit) 执行: 在每一步使用这个逐渐减小的学习率和计算出的梯度来更新模型权重。
训练结束 (Step 60):
- 学习率理论上降到 0,训练停止。
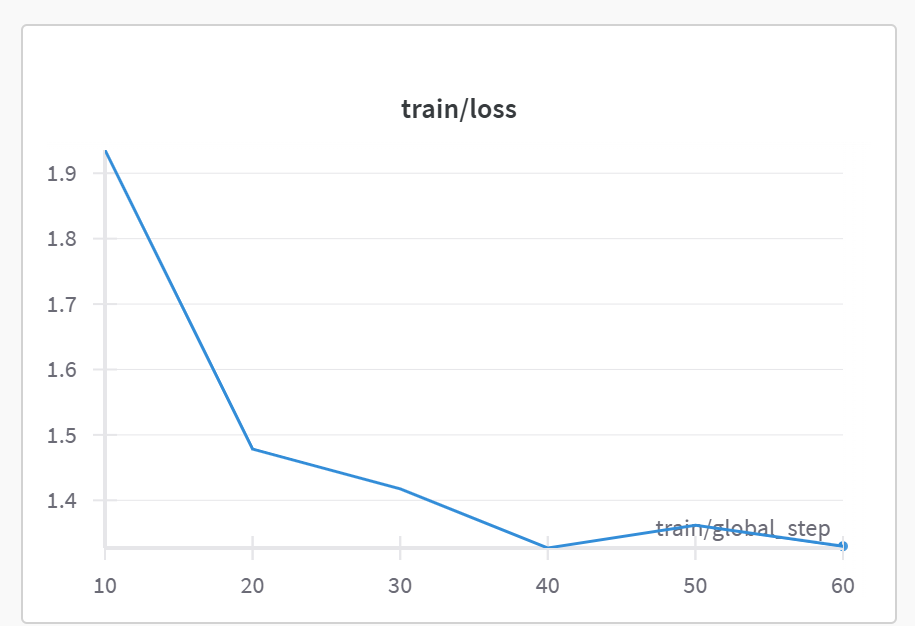
wandb图标观察
train/loss(训练损失)
-
X 轴:
train/global_step- 训练进行的全局步数(优化器更新次数),从 10 到 60。 -
Y 轴: Loss (损失值) - 模型在训练数据上计算出的损失函数值。这个值越低通常表示模型拟合训练数据越好。
-
曲线解读: 图表显示损失值从训练开始(第 10 步之后)的较高值(约 1.9)迅速下降,然后在后续步骤中(20 到 60 步)下降速度减缓,最终达到约 1.35 左右。
-
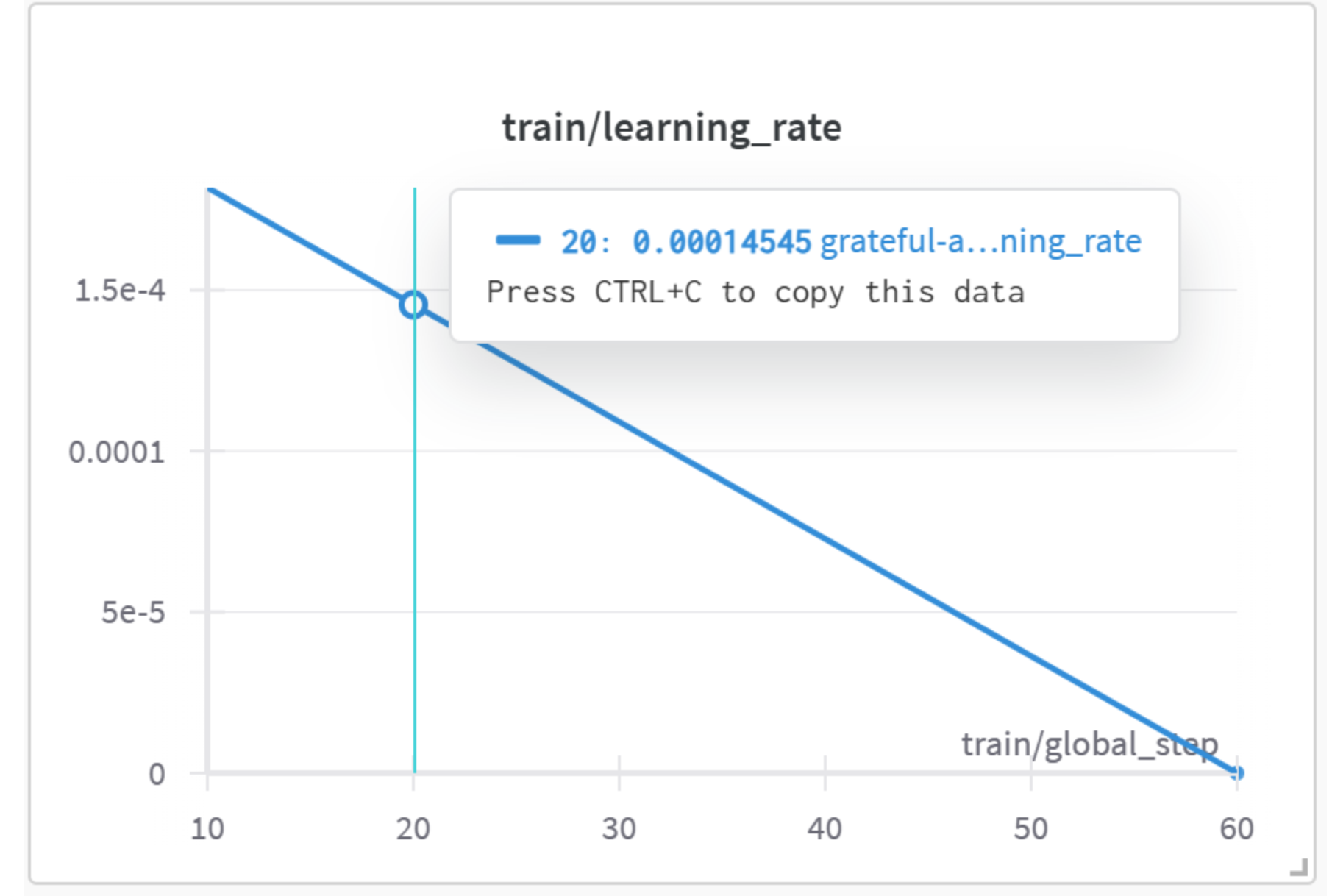
train/learning_rate(训练学习率)
- X 轴:
train/global_step- 全局步数 (10 到 60)。 - Y 轴: Learning Rate (学习率) - 优化器在每一步实际使用的学习率。
- 曲线解读: 学习率从第 10 步时的一个较高值(接近你设置的峰值
2e-4,这里显示约 1.6e-4 可能是因为记录点和实际峰值点略有偏差或 warmup 刚结束)开始,随着步数增加线性下降,在第 60 步接近 0。 - 意义: 这个图完美地验证了你的学习率调度设置:
warmup_steps=5(前 5 步预热,图中未完全显示,因为 x 轴从 10 开始) 和lr_scheduler_type="linear"以及max_steps=60。学习率在预热后达到峰值,然后线性衰减至训练结束。
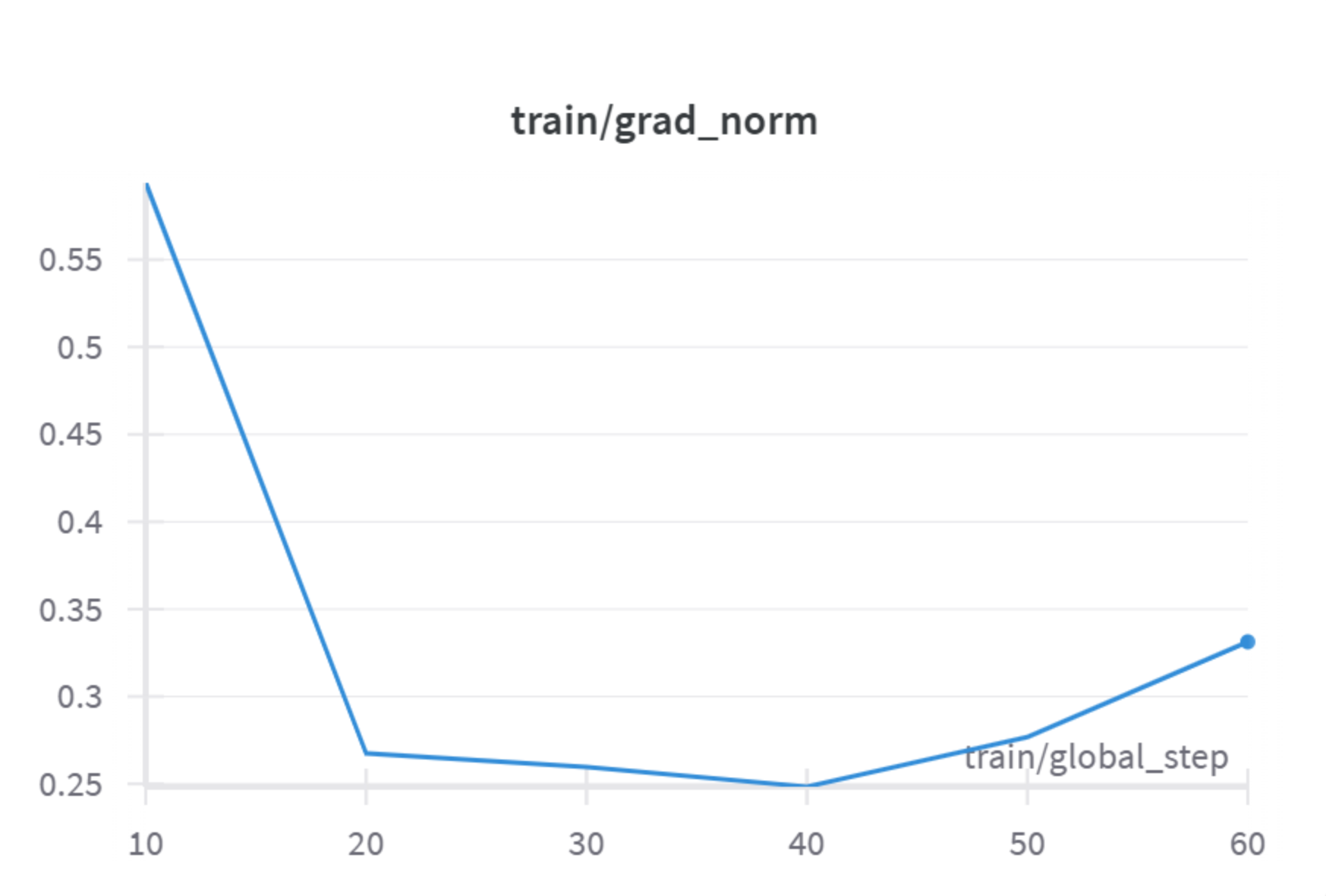
train/grad_norm(训练梯度范数)- X 轴:
train/global_step- 全局步数 (10 到 60)。 - Y 轴: Grad Norm (梯度范数) - 模型所有参数梯度组成的向量的长度(范数)。它衡量了梯度的大小。
- 曲线解读: 梯度范数在训练早期(第 10 步)相对较高(约 0.58),然后迅速下降到 0.3 左右(第 20 步),之后趋于稳定,最后略有回升到 0.35 左右。
- 意义: 梯度范数可以帮助诊断训练稳定性。初始值较高表明模型离最优解较远,需要较大调整。迅速下降表明模型快速进入损失较低的区域。后续稳定或轻微波动是正常的。需要警惕的是梯度范数爆炸(变得非常大)或消失(变得非常接近 0),这两种情况都可能阻碍训练。你图中的值看起来在合理范围内。
- X 轴:
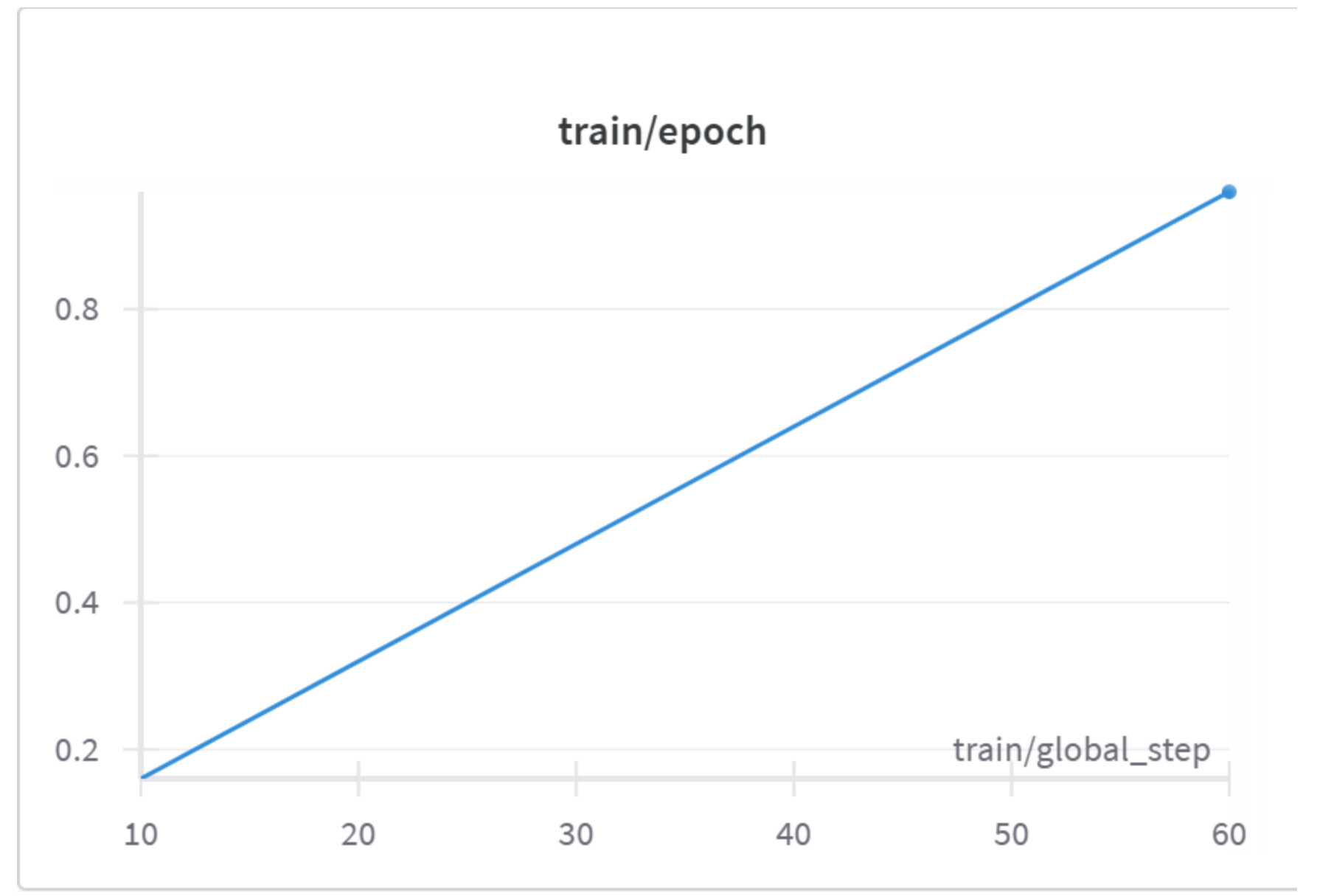
train/epoch(训练轮数)- X 轴:
train/global_step- 全局步数 (10 到 60)。 - Y 轴: Epoch - 当前训练进度相当于遍历了整个训练数据集的多少比例。
- 曲线解读: Epoch 值随着全局步数的增加而线性增加,从第 10 步的约 0.15 增加到第 60 步的约 0.9。
- X 轴:
完整代码
pip install unsloth # 安装unsloth库
pip install bitsandbytes unsloth_zoo # 安装工具库
import torch # 加载torch库
from unsloth import FastLanguageModel
# ############## 加载模型和分词器#####################
# 超参数设置
max_seq_length = 2048 #模型的上下文长度,可以任意选择,内部提供了RoPE Scaling 技术支持
dtype = None # 通常设置为None,使用Tesla T4, V100等GPU时可用Float16,使用Ampere+时用Bfloat16
load_in_4bit = True # 以4位量化进行微调
# 基于unsloth加载deepseek的蒸馏模型
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/DeepSeek-R1-Distill-Llama-8B",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
token = hf_token,
)
# ################# 提示模板 #######################
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>{}"""
# ##################### 微调前推理示例 #######################
question = "一个患有急性阑尾炎的病人已经发病5天,腹痛稍有减轻但仍然发热,在体检时发现右下腹有压痛的包块,此时应如何处理?"
FastLanguageModel.for_inference(model)
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])
# ###################### 更新提示模板 #######################
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
{}
</think>
{}"""
# ####################### 处理函数 #########################
EOS_TOKEN = tokenizer.eos_token # 末尾必须加上 EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["Question"]
cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for input, cot, output in zip(inputs, cots, outputs):
text = train_prompt_style.format(input, cot, output) + EOS_TOKEN
texts.append(text)
return {
"text": texts,
}
# ################### 加载数据集 ##########################
from datasets import load_dataset
dataset = load_dataset("FreedomIntelligence/medical-o1-reasoning-SFT", 'zh', split = "train[0:500]", trust_remote_code=True)
print(dataset.column_names)
dataset = dataset.map(formatting_prompts_func, batched = True)
print(dataset["text"][0])
# ################## 微调参数设置 #####################
model = FastLanguageModel.get_peft_model(
model,
r=16, # 选择任何数字 > 0 !建议 8、16、32、64、128微调过程的等级。
#数字越大,占用的内存越多,速度越慢,但可以提高更困难任务的准确性。太大也会过拟合
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
], # 选择所有模块进行微调
lora_alpha=16, # 微调的缩放因子,建议将其等于等级 r,或将其加倍。
lora_dropout=0, # 将其保留为 0 以加快训练速度!可以减少过度拟合,但不会那么多。
bias="none", # 将其保留为 0 以加快训练速度并减少过度拟合!
use_gradient_checkpointing="unsloth", # True or "unsloth" for very long context
random_state=3407, # 随机种子数
use_rslora=False, # 支持等级稳定的 LoRA,高级功能可自动设置 lora_alpha = 16
loftq_config=None, # 高级功能可将 LoRA 矩阵初始化为权重的前 r 个奇异向量。
#可以在一定程度上提高准确性,但一开始会使内存使用量激增。
)
# ################# 训练参数设置 #######################
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=max_seq_length,
dataset_num_proc=2,
args=TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
# Use num_train_epochs = 1, warmup_ratio for full training runs!
warmup_steps=5,
max_steps=60,
learning_rate=2e-4,
fp16=not is_bfloat16_supported(),
bf16=is_bfloat16_supported(),
logging_steps=10,
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="outputs",
),
)
# ################### 模型训练 #################
trainer_stats = trainer.train()
# ################### 模型保存 ##################
new_model_local = "DeepSeek-R1-Medical-COT"
model.save_pretrained(new_model_local) # 本地模型保存
tokenizer.save_pretrained(new_model_local) # 分词器保存
# 将模型和分词器以合并的方式保存到指定的本地目录
model.save_pretrained_merged(new_model_local, tokenizer, save_method = "merged_16bit",)
# model.push_to_hub("your_name/lora_model", token = "...") # Online saving
# tokenizer.push_to_hub("your_name/lora_model", token = "...") # Online saving






![[连载]Transformer架构详解](https://i-blog.csdnimg.cn/direct/5c0929e48f7f41a498455d295488e37a.png)