1、错误率与精度
错误率与精度是分类任务中最常用的两种性能度量,错误率是指分类错误的样本占样本总数的比例,精度则是分类正确的样本数占样本总数的比例。
错误率:
精度:
2、准确率/召回率/FScore
True Positive(真正例, TP):将正类预测为正类数.
True Negative(真负例, TN):将负类预测为负类数.
False Positive(假正例, FP):将负类预测为正类数 → 误报 (Type I error).
False Negative(假负例, FN):将正类预测为负类数 → 漏报 (Type II error).
查准率:
查全率/召回率:
准确率:
F-Score:
F=2PR/(P+R)
F是准确率和召回率的结合,更加符合实际应用需求
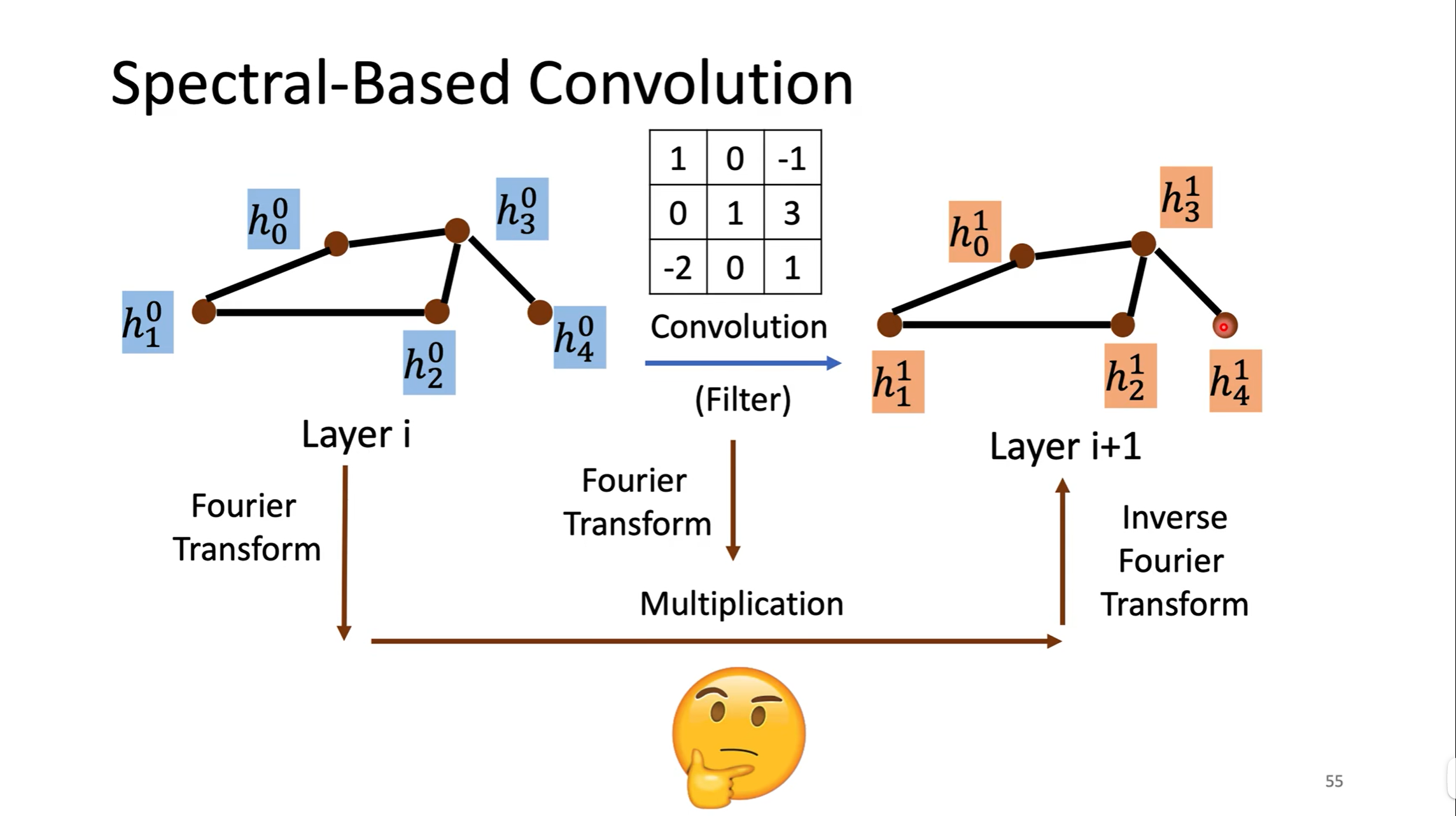
3、ROC曲线/AUC
当样本不平衡时,ACC难以评估样本的准确性,因而通过AUC进行评估;AUC 通过对 ROC 曲线下各部分的面积求和而得
4、Precision@K
precision@k=topk中相关文档数/k
5、AP 和 MAP
AP(Average Precision) = Average Precision@K
MAP (Mean average precision) :不同请求/query AP的平均值

6、MRR(Mean reciprocal rank)
Mean reciprocal rank(MRR) 是另一种对排序列表进行评价的指标,MRR 定义为
表示第i个查询第一个相关结果在列表中的位置。
7、DCG@K (Discounted cumulative gain)
Discounted cumulative gain 简写为 DCG,是搜索引擎常用的评价指标。DCG 的出发点可以理解为:在搜索引擎的结果中,相关结果比弱相关和不相关的结果更为重要,因而要更注重对相关结果的排序结果。
DCG@K的一个变形为
Normalized DCG
可以看到 IDCG 是一个理想情况,即按照真实标签排序的情况。 目前在我所在的搜索场景在离线评测时还是会考虑 NDCG 的情况,而具体的 K 值选择则要根据业务场景自行调整。
参考文献
排序学习(LTR)杂谈 (上) - 知乎
1、排序学习(LTR)杂谈 (上) - 知乎
2、Learning to Rank: pointwise 、 pairwise 、 listwise - 知乎
3、排序评估指标——NDCG和MAP_comli_cn的博客-CSDN博客(ndcg详例)
4、排序评价指标 - 知乎