嗨~你好呀!
我是一名初二学生,热爱计算机,码龄两年。最近开始学习汇编,希望通过 Blog 的形式记录下自己的学习过程,也和更多人分享。
上篇系列文章链接:【汇编】二、预备知识(一只 Assember 的成长史)
这篇文章主要讲解寄存器。
话不多说~我们开始吧!
⭐ 注:本系列文章基于 8086 CPU,16 位汇编,参考书《汇编语言》。
本系列旨在为 32 位汇编的学习以及汇编的实际使用打下基础。
目录
三 0. 本文中用到的汇编指令及其功能
三 1. 寄存器是什么
三 2. 寄存器的分类
1. 通用寄存器
2. 控制寄存器
3. 段寄存器
三 3. 通用寄存器及数据在通用寄存器中的存储
三 4. 物理地址、物理地址计算方法及段的概念
1. 物理地址
2. 物理地址计算方法
3. 段的概念
三 5. CS/IP 寄存器及 CPU 读取执行指令的工作过程
1. cs 和 ip 寄存器
2. CPU 读取、执行指令的工作过程
3. 修改 cs 和 ip 寄存器
三 0. 本文中用到的汇编指令及其功能
| 汇编指令 | 指令功能 | 高级语言语法描述 |
| mov X, Y | 将 Y 中的数据送至 X 中 | X = Y |
| add X, Y | 将 X,Y 相加,并将结果存储在 X 中 | X += Y 或 X = X+Y |
| jmp X:Y | 将 cs 的值设置为 X,将 ip 的值设置为 Y(后面会详细讲到) | cs = X; ip = Y |
| jmp 某一合法寄存器名 | 将 ip 的值设置为该合法寄存器中存储的值(后面会详细讲到) | ip = 该寄存器中存储的值 |
注:mov 和 add 的使用有一些限制,但涉及到更多知识,容易打乱思路和学习主线,所以会在遇到这些限制的时候再进行说明~
三 1. 寄存器是什么
上一篇说过,计算机有多种存储器,寄存器也是其中一种。
我们都知道,CPU 的运算速度远高于内存的读写速度,所以如果每次需要数据都要从内存中读取,会严重拖慢 CPU 的运行速度。正因如此,CPU 内嵌入了读写速度更快的 cache(高速缓存)和寄存器,用于存储最常用的数据(比如 for 循环中的 i)。cache 和寄存器也相当于 CPU 和内存之间的一座桥梁。
寄存器的体积最小、读写速度最快、价格最贵。
三 2. 寄存器的分类
不同的 CPU,寄存器的个数和结构都是不相同的,但总有那么几个寄存器出现在任何种类的 CPU 中。8086 CPU 共有 14 个寄存器(寄存器名不区分大小写):ax, bx, cx, dx, si, di, sp, dp, bp, ip, cs, ss, ds, es, psw。
不过这 14 个没必要一口气学完,此处仅列出分类,下文中会讲到几个,后续文章中会讲到其它的~如果现在就想详细了解,可以去:爱了爱了,这篇寄存器讲的有点意思
1. 通用寄存器
· 数据寄存器:ax, bx, cx, dx
· 地址指针寄存器:sp, bp
· 变址寄存器:si, di
2. 控制寄存器
· 指令指针寄存器:ip
· 标志寄存器:psw
3. 段寄存器
(结尾的 s 全称为 segment,即 “段”)
· 代码段:cs(c = code)
· 数据段:ds(d = data)
· 栈段:ss(s = stack)
· 附加段:es(e = extra)
三 3. 通用寄存器及数据在通用寄存器中的存储
8086 CPU 的所有寄存器都是 16 位的,可以存放两个字节(一个字)。如下图:
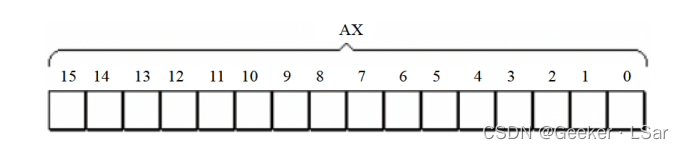
But,8086 的上一代 CPU 中的寄存器都是 8 位的,为了保证兼容,8086 CPU 中的 ax, bx, cx, dx 寄存器都可以分为两个 8 位寄存器来使用(但其他的不可以)。
ax 分为 ah 和 al(h = high,l = low,下同);
bx 分为 bh 和 bl;
cx 分为 ch 和 cl;
dx 分为 dh 和 dl;
通过其英文我们不难猜出,ah 中存储的是 ax 中的高 8 位数据,而 al 中存储的是 ax 中的低 8 位数据。下图是一个例子(“20H” 中的 H 表示该数据是十六进制)。
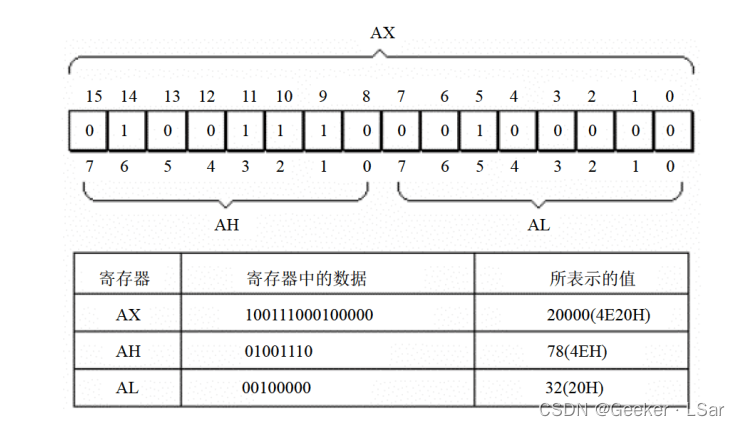
上图其实也表明了数据在 16 位寄存器中的存储。如果数据是一个字节,它将被存储在寄存器的某个 8 位中(高或低不确定)。如果数据是一个字,它的高位字节存储在寄存器的高 8 位中,低位字节存储在寄存器的低 8 位中。
如果在 ax 中存放的数据超过了 16 位(如 mov ax, FFFFFF0H),会导致高位丢失。
如果单独使用 al 或 ah,存放的数据超过 8 位时会导致高位丢失(不要误认为,单独使用 al 时,如果超过 8 位,会将进位存储在 ah 中)。
注意不要混淆寄存器和内存单元,一个字可以使用一个寄存器存储,但会占用两个内存单元(一个内存单元 8 位)。
在进行数据传送或运算时,两个操作对象的位数应当是一致的,比如不能这样写:mov ax,bl(前者是 16 位寄存器,后者是 8 位寄存器)。
三 4. 物理地址、物理地址计算方法及段的概念
1. 物理地址
上篇文章中说过,各个存储器的物理存储空间被合在一起看成一个逻辑存储空间,也就是内存地址空间,这个空间由很多内存单元构成。
而 CPU 想要寻址,就必须保证内存单元的地址的唯一性。内存单元在内存地址空间中唯一的地址就是它的物理地址(相当于身份证号)。
这就涉及到了一个问题——CPU 怎么给出物理地址?
2. 物理地址计算方法
首先需要面对一个非常囧的情况:8086 CPU 有 20 根地址总线,但只有 16 根数据总线......
通过上篇文章的计算公式不难得出,它的寻址能力是 1MB(或者说最大可以有 1MB 内存)。但是它一次只能发送 64KB 的数据(相当于 16 位的地址),表现出的寻址能力只有 64KB...
怎么办?如果只能发送 16 位的地址,那么内存大小只会有 64KB,且还白白浪费了 4 根地址总线。
但大佬就是大佬,一个 16 位不够,可以用两个啊!(虽然我很好奇为什么当时不加上 4 根数据总线,那不就万事大吉了)
so,解决办法出炉了——用两个 16 位地址合成一个 20 位地址。一个称为段地址,一个称为偏移地址(后面会讲到)。
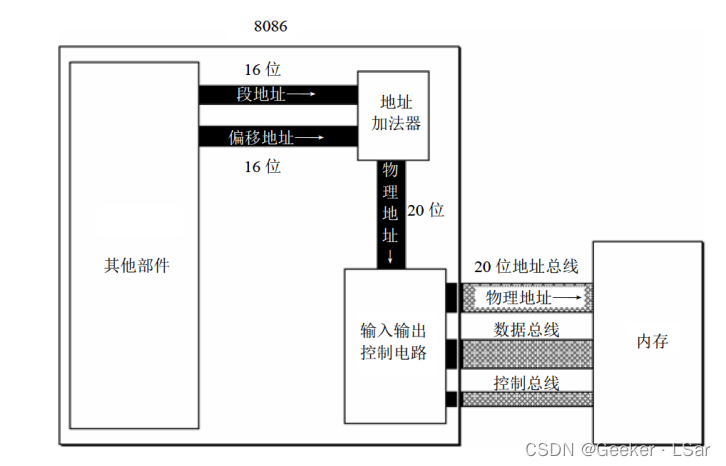
如上图,概括一下 8086 CPU 读写内存的过程:
CPU 把段地址和偏移地址告诉地址加法器,地址加法器按照公式用这两个 16 位地址生成一个 20 位物理地址,再通过地址总线送到存储器。
这个公式就是:物理地址 = 段地址 * 16 + 偏移地址( * 16 相当于左移 4 位)
补充一些数学知识:
· 一个 X 进制的数据左移 1 位,相当于乘以 X。
· 一个二进制数左移 4 位,相当于在原数的末尾加 4 个 0。
· 一个十六进制数左移 4 位,相当于在原数的末尾加 1 个 0。
补充的第二条也解释了为什么两个 16 位地址经过公式计算后可以生成一个 20 位地址。因为原来的段地址是 16 位,段地址 * 16 后末尾多了 4 个 0,变成了 20 位,再加上 16 位的偏移地址,还是 20 位。
下图是一个例子,其中段地址和偏移地址都用十六进制表示(其实它们在被送上地址总线的时候都是二进制,但是十六进制相对易读,也比较短)。
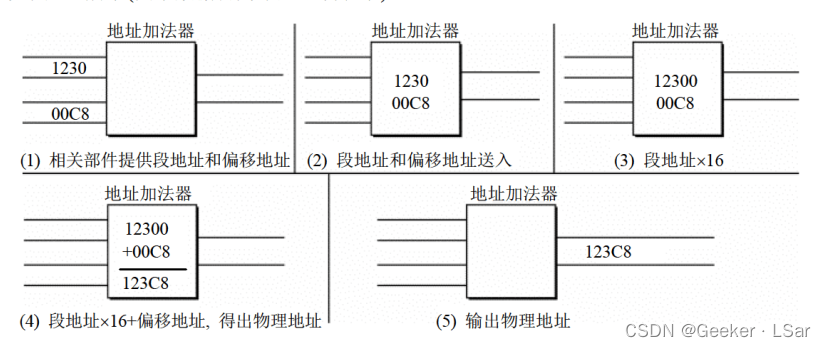
这个公式的本质含义是:CPU 在访问内存时,用一个基础地址和一个相对于基础地址的偏移地址相加,给出内存单元的物理地址。其中,“基础地址” 就是段地址 * 16。
根据这个公式,同一个物理地址可以用不同的段地址和偏移地址来表示,比如:
| 段地址 | 偏移地址 | 物理地址 |
| 0001 | 0000 | 0001 * 16 + 0000 = 00010+0000 = 00010 |
| 0000 | 0010 | 0000 * 16 + 0010 = 00000+0010 = 00010 |
其实 32 位 CPU 也延续了用段地址和偏移地址来表示一个内存单元的传统,只不过操作系统从实模式变成了保护模式,添加了 GDT、段描述符、段选择子等等一系列复杂的东西,后续文章会讲到哒~
3. 段的概念
你可能已经注意到了,“段地址” 这个名称似乎在暗示,内存地址空间是被分段的...?
nonono!内存地址空间是一个逻辑空间,并没有分段,段的划分来自于 CPU(上面那个表格也可以解释这一点,如果内存被分段的话,就会有两个内存单元对应同一个物理地址了)。
分段的方式可以让开发者更好地管理内存,比如我们可以把一部分内存划为代码段,专门用于存放代码;另一部分内存划分为数据段,专门用于存放数据;等等。在后续的文章中会陆续出现的~
比如,我们可以用不同的方式划分 10000H~100FFH 这段内存(不过一个段的起始地址一定是 16 的倍数,相当于段地址 * 16 + 0)。

如果你想在一个学校中找到 “初二 5 班 29 号同学”,你可以先找到初二5班,再在这个较小的范围中寻找 29 号同学,这可以减小你的工作量。
同理,分段可以让你不必记住这个内存单元的物理地址,而只需要先设置好段地址(后续文章会讲到),再通过偏移地址在这个段中定位需要的内存单元就可以了~
不过,偏移地址的长度是 16 位,所以一个段的长度最大为 64KB。
三 5. CS/IP 寄存器及 CPU 读取执行指令的工作过程
1. cs 和 ip 寄存器
cs 和 ip 是 CPU 中两个最关键的寄存器,它们指示了 CPU 当前要读取的指令的地址。其中 cs 为代码段寄存器(存储段地址),ip 为指令指针寄存器(存储偏移地址)。
若设 cs 中内容为 X,ip 中内容为 Y,对于 8086 CPU,它将从内存 X * 16 + Y 单元开始,读取一条指令并执行。换言之,它将 cs:ip 指向的内存单元中的内容当作指令执行。
2. CPU 读取、执行指令的工作过程
我们已经知道 CPU 会将 cs:ip 指向的内容当作指令执行,那么,一条指令究竟是怎么执行的呢?CPU 在这个过程中是如何工作的?
我们通过一个例子来看这个问题。
如下图,cs 的值为 2000H,ip 的值为 0000H,内存 20000H~20009H 单元存放着可执行的机器码,旁边给出了每几条对应的汇编指令。地址加法器负责计算物理地址;输入输出控制电路负责输入/输出数据;指令缓冲器负责缓冲(暂存)指令;指令执行器(或称为执行控制器)负责执行指令。
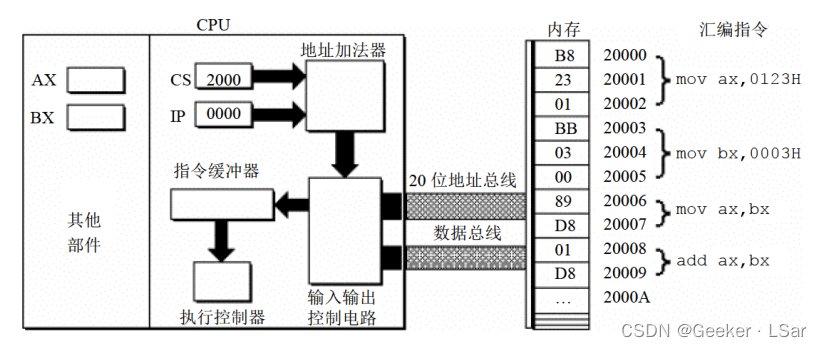
第一步:如下图,cs, ip 中的内容送入地址加法器,地址加法器通过 “物理地址 = 段地址 * 16 + 偏移地址” 计算出内存单元的物理地址。
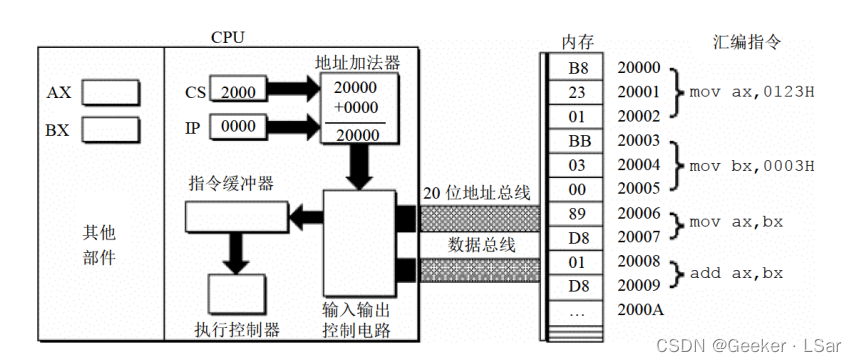
第二步:如下图,地址加法器将物理地址送入输入输出控制电路。
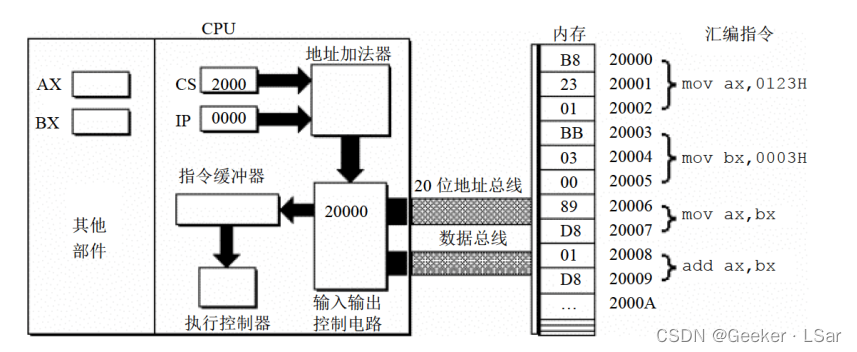
第三步:如下图,输入输出控制电路将物理地址 20000H 送上地址总线,经地址总线送入内存。
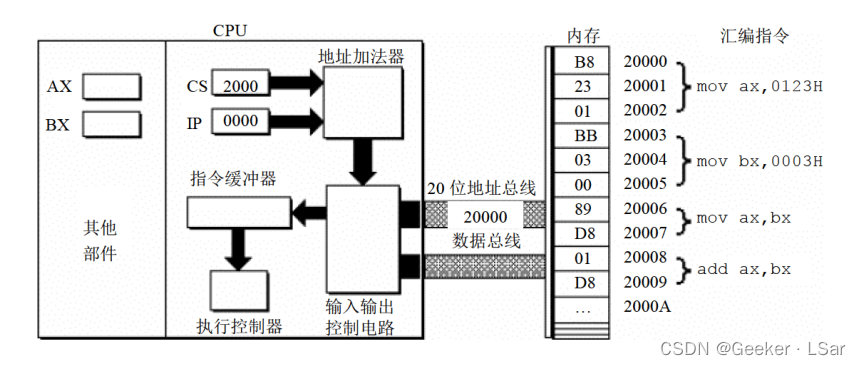
第四步:如下图,从内存 20000H 单元开始存放的机器指令(B8 23 01)通过数据总线被送入 CPU。
(你可能会好奇,诶 CPU 怎么知道它要三个内存单元的数据?它怎么知道 20000H 到 20003H 就是完整的一条汇编指令?)
(这是因为 CPU 有指令解释器,它知道 mov 后面跟着几个字节~)
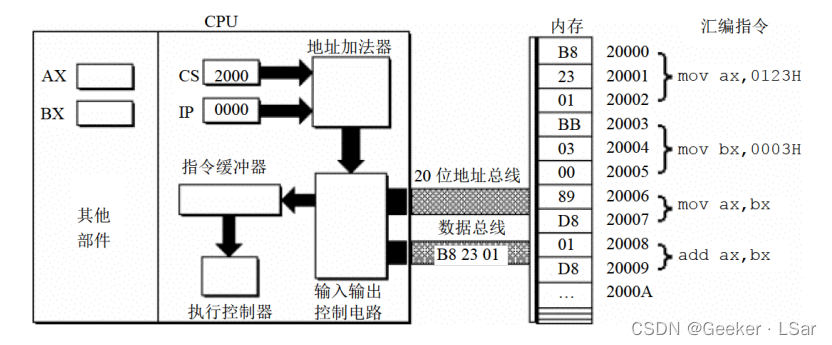
第五步:如下图,输入输出控制电路将机器指令(B8 23 01)送入指令缓冲器。
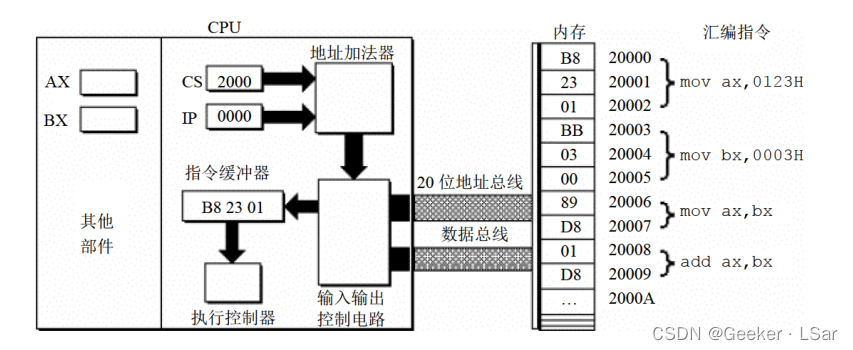
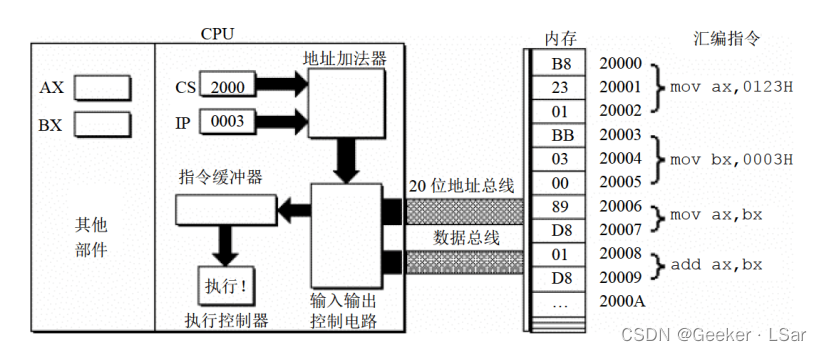
第六步:如下图,读取一条指令后,ip 寄存器中的值将自动增加,以便 CPU 可以读取下一条指令。因为当前读入的指令长度为 3 个字节,所以 ip 中的值自动加 3。此时 cs:ip 指向内存单元 2000:0003。

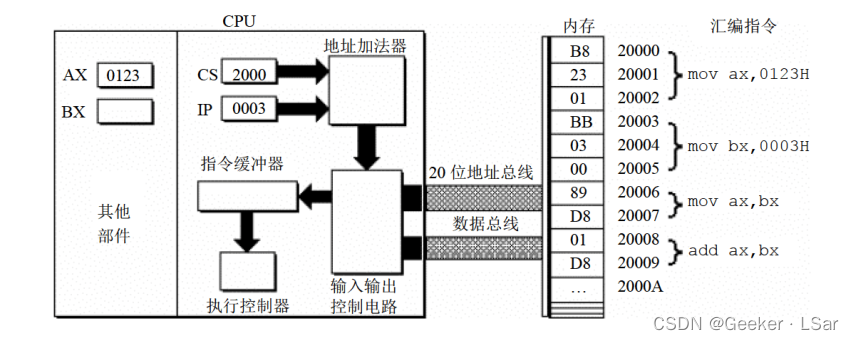
第七步:如下图,指令执行器执行指令 B8 23 01。
此时,ax 寄存器中的内容为 123H。
总结一下 CPU 读取和执行指令的过程吧~:
1. 从 cs:ip 指向的内存单元读取指令,读取的指令进入指令缓冲器;
2. ip = ip + 所读取的指令的长度,从而转向下一条指令;
3. 执行指令,转到步骤 1,重复这个过程。
3. 修改 cs 和 ip 寄存器
本文最开始提到,mov 和 add 指令的使用是有限制的,其中的一些限制在这里表现了出来。
如何改变一个寄存器的值?我猜你第一个想到的是使用 mov 指令,把一个值送入寄存器。
buuuuuut...cs 和 ip 偏偏就很有个性,它俩不接受通过 mov 修改它们的值...(其实 “有个性” 的寄存器不止它俩,后续文章中会提到~)
能够改变 cs 和 ip 的值的指令被称为转移指令,其中最简单的一个是 jmp 指令。
若想同时修改 cs 和 ip 的值,可用形如 “jmp 段地址:偏移地址” 来实现。jmp 用指令中给出的段地址修改 cs,用指令中给出的偏移地址修改 ip。如:jmp 218h:520h,执行后 cs = 218H,ip = 520H,CPU 将从 026A0H(218H * 16 + 520H)处读取指令。
若仅想修改 ip 的值,可用形如 “jmp 某一台合法寄存器” 来实现。jmp 用指令中给出的合法寄存器中的值修改 ip。如:mov ax, 1320h; jmp ax(注意!汇编代码后面没有分号,此处使用分号仅仅为了便于区分两条指令~),执行后 ip = 1320H。
如果你希望定义一个代码段,可以使用 cs:ip 指向代码段中第一条指令所在的内存地址空间(的起始位置)。
还有一些别的转移指令,后续文章中会讲到~
以上就是本文的全部内容啦~感谢你看到这里~
作者只是一名初学者,有任何错误或解释不当之处欢迎指出呀~一起加油!
那,我们下一篇再见咯~
2023-03-04
By Geeker · LStar
❤️