说明:本节的程序使用的是x86_64指令集的。
汇编语言是可以编译成机器指令的,机器指令是可以直接在CPU上面执行的。我们编写的汇编程序既可以直接在操作系统的帮助下执行,也可以绕过操作系统,直接在硬件上执行。
如果你打算编写的汇编程序在操作系统帮助下执行,那么你的汇编可以调用很多操作系统暴露的系统调用,或者别的语言的函数库,比如C语言的标准库中的函数。但是如果你打算编写绕过操作系统执行的汇编,会比较累,比如往显示器上显示一串字符串这件事情,如果你打算让操作系统帮你执行,你可以在汇编程序中直接调用系统调用(这一节我们打算这么做),来控制硬件(操作系统能帮助我们控制硬件),如果你打算自己去控制硬件,就比较麻烦点(下一节我们打算这么做)。
Hello World汇编文件编写
hello.asm文件的内容(等一会再详细剖析代码):
;hello.asm 交给nasm汇编器汇编的程序,通过英文分号开头表示注释
section .data
msg db "Hello, wolrd",0,0xA ;db表示define byte,即字节类型,逗号后边的0表示字符串结尾
;字符串中的每个字符占用一个字节,0xA是十六进制数,对应的换行符的ASCII码
;这样后边输出字符串的时候,就可以还行了
section .bss
section .text
global main
main:
mov rax,1 ;为了后续使用syscall,先将系统调用号1(含义是write)存到寄存器rax中
mov rdi,1 ;rdi寄存器通常表示目的地,1表示标准输出
mov rsi,msg ;rsi寄存器通常表示来源地,需要显示的是字符串,存放在rsi中
mov rdx,14 ;字符串的长度和末尾的0及换行符的长度。注意,汇编中的数字,如果不加0x前缀或者h后缀,表示的是十进制
syscall ;发起x86_64的系统调用,显示字符串
mov rax,60 ;程序的返回结果放在rax寄存器中,60表示退出,如果为负数表示发生了错误
mov rdi,0 ;0表示成功退出码
syscall ;退出
hello.asm同一个目录下的makefile文件内容:
#hello.asm的makefile makefile的注释用#开头
hello: hello.o
# no-pie选项是为了关闭pie,从而生成可调试的可执行文件
# pie是position independent executable的意思,表示与地址无关的
# 如果编译器在生成可执行程序的过程中使用了pie,那么当可执行程序被加载到内存中时,其加载地址存在不可预知性
gcc -o hello hello.o -no-pie
hello.o: hello.asm
# nasm -f 后边表示的是输出的格式
# elf64表示的是64位可执行和可链接的格式
nasm -f elf64 hello.asm
编译、执行
pilaf@pilaf-thinkpad:~/assembly_x64/hello_asm$ pwd
/home/pilaf/assembly_x64/hello_asm
pilaf@pilaf-thinkpad:~/assembly_x64/hello_asm$ ls
hello.asm makefile
pilaf@pilaf-thinkpad:~/assembly_x64/hello_asm$ make
nasm -f elf64 hello.asm
gcc -o hello hello.o -no-pie
pilaf@pilaf-thinkpad:~/assembly_x64/hello_asm$ ls
hello hello.asm hello.o makefile
pilaf@pilaf-thinkpad:~/assembly_x64/hello_asm$ ./hello
Hello, wolrd
pilaf@pilaf-thinkpad:~/assembly_x64/hello_asm$
make命令后生成了一个可执行的hello文件,然后执行它,在shell中输出了Hello, world。
反编译可执行文件
下面我们通过gdb看一下hello可执行程序反汇编的结果:
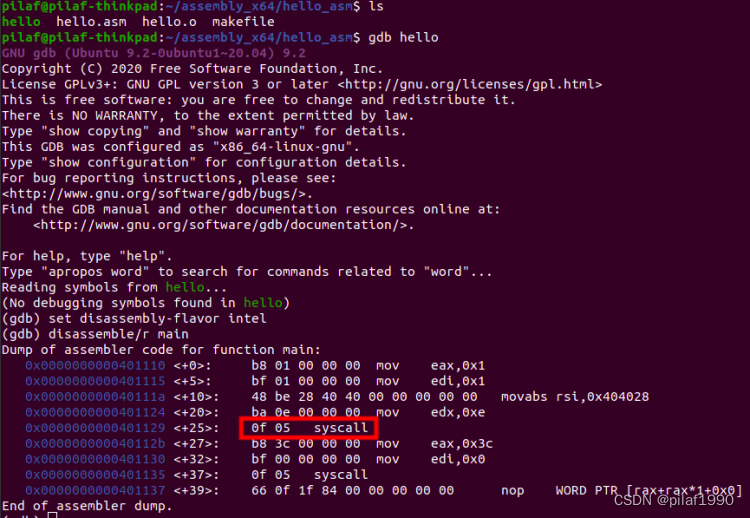
dissassemble/r main,可以显示出main函数(global main定义)的十六进制指令及其汇编指令关系,最左边的蓝色的一列是二进制可执行程序的内存地址(逻辑地址)。可以看到syscall指令的机器码是0f05。
上边很有意思的是这几行:
0x0000000000401110 <+0>: b8 01 00 00 00 mov eax,0x1
0x0000000000401115 <+5>: bf 01 00 00 00 mov edi,0x1
0x000000000040111a <+10>: 48 be 28 40 40 00 00 00 00 00 movabs rsi,0x404028
0x0000000000401124 <+20>: ba 0e 00 00 00 mov edx,0xe
0x0000000000401129 <+25>: 0f 05 syscall
0x000000000040112b <+27>: b8 3c 00 00 00 mov eax,0x3c
0x0000000000401130 <+32>: bf 00 00 00 00 mov edi,0x0
内存地址后边跟着的尖括号中的"+数字"表示相对第一个指令的内存地址的偏移字节数。
第二条指令mov edi,0x1相对于第一条指令mov eax,0x1偏移了5个字节,正好就是b8 01 00 00 00这5个字节所占的内存长度。而mov edi,0x1也占用了5个字节的内存,所以它后便的内存中的指令movabs rsi,0x404028相对于它又增加了5个字节(10-5=5)。
还有我们发现有mov eax的地方,机器码都是b8开头,有mov edi的地方,机器码都是bf开头,后便跟着4个字节,就是mov指令有操作数。这也就是说了mov eax,mov edi在指令中一共才占用1个字节,这1个字节就表示了mov和寄存器两个信息了。
我们还可以发现,b8、bf后边跟着的4个字节(32位整数的十六进制表示),和mov指令右操作数好像不一样啊,其实这是因为Intel CPU采用的是小端字节序,对应的还有大端字节序。所谓的大端还是小端,指的是将一个多字节的数存放到内存的时候,这个数字的权重大的字节(比如,十进制的102这个数字的1的权重比2大)放在内存低地址还是权重小的字节放在内存低地址。如果权重低的字节放在内存低地址,就是小端字节序,如果权重大的字节放在内存低地址就是大端字节序。
我们的0x01是0x00000001这个四字节数的简写,但是却把01这个字节放在内存低地址,所以它是小端字节序。
等等,不知道你有没有发现一个问题,我们hello.asm中用的不是rax么?怎么反编译完了变成了eax了?好多r开头的寄存器怎么都变成e开头的了?这是因为r开头的寄存器是64位的,e开头的是32位的,汇编器发现mov右操作数没有必要用64位寄存器存储,就优化了。不知你是否还记得,8086的几个通用寄存器,ax、bx、cx、dx(它们又可以拆分为两个8位寄存器,如ah、al,h表示high,l表示low),80386开始有eax、ebx、ecx、edx,e表示extend扩展的意思,它们都是32位的寄存器了,到了64位,有了rax、rbx、rcx、rdx这些寄存器。类似的还有ip、eip、rip表示存放下一个指令内存地址的寄存器。
系统调用方式之syscall
好了,让我们再来看看syscall这个汇编指令。
书上说,进行系统调用的可以通过下面三种方式:
- INT(中断Interrupt,旧的方式,不太推荐用了)
- syscall指令(syscall是汇编指令,我们hello.asm中用到了)
- 程序库API(如C语言的标准库中的printf就对write系统调用进行了封装)
作为菜鸟的我,看到《x64汇编语言:从新手到AVX专家》中给出的这段汇编,有很多地方不明白的,比如mov rax,1和mov rdi,1中的1有什么联系?为什么要往rax中mov,不往别的寄存器mov?
带着这些疑问,我man了一下syscall(Linux shell中执行了man syscall):
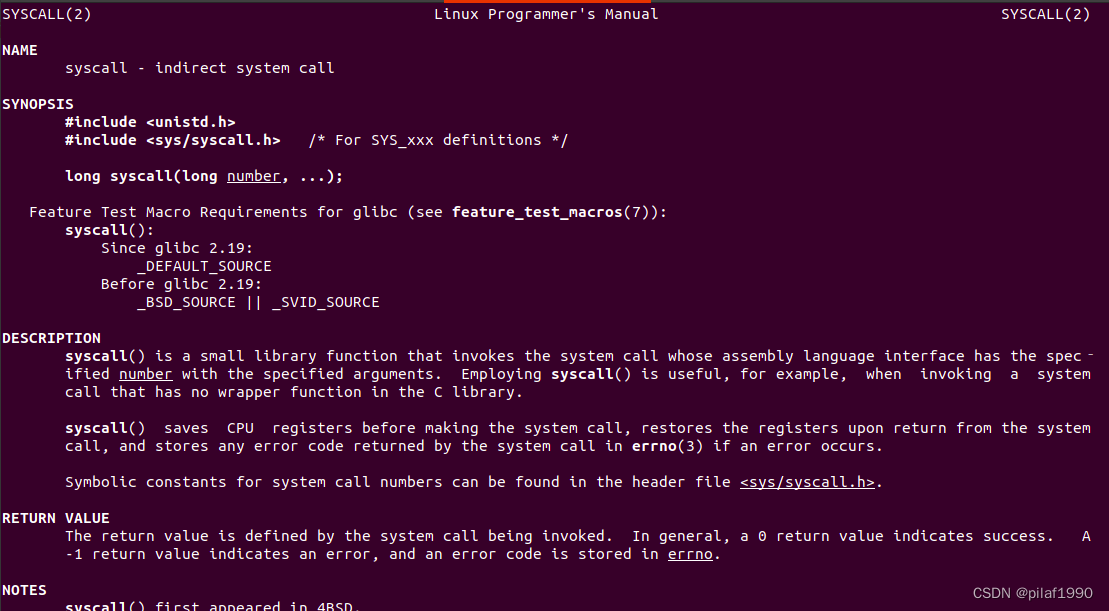
内容很长,我只截了一部分。从中我们可以看到,C头文件中也定义了一个syscall的函数(名字和汇编的syscall指令相同),它是一个小的库函数,它用于调用一些系统调用,这些系统调用(系统调用是操作系统对硬件操作的封装,对硬件操作少不了汇编指令,Linux操作系统的系统调用的实现都是C语言中嵌套着汇编)的汇编接口有特定的号码和参数。syscall函数可以调用其它的系统调用,只需要按照调用约定将系统调用号和参数传递给它即可。
也就是说,汇编提供了一个syscall指令用于调用操作系统的系统调用,只需要将操作系统的系统调用号和参数准备好就可以了。
我们可以通过汇编直接调用syscall指令,也可以用C语言提供的syscall函数(这个函数内部实现肯定是包了汇编指令syscall的)。
并且系统调用号的数字和符号表示关系在<sys/syscall.h>中有定义。
syscall汇编指令的用法
我继续阅读man syscall给出的信息,发现下面这些有用的信息。
表一:
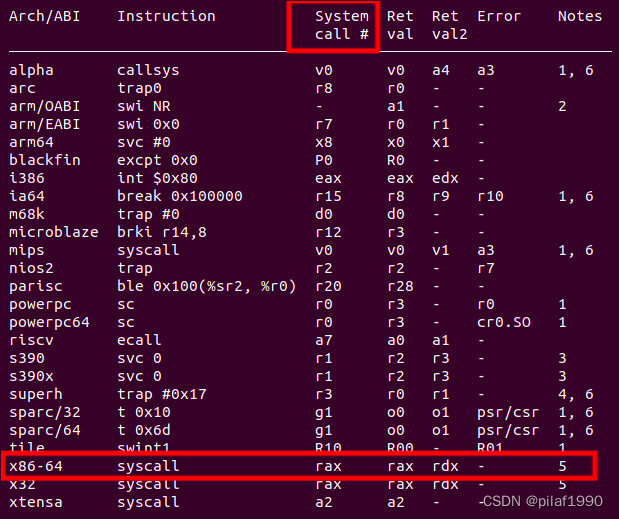
文档直接给出了x86-64的syscall指令的使用方法,也就是说调用syscall之前,需要将系统调用号(System call #,英文中经常用井号表示Number的缩写)放到rax寄存器,返回值1放到rax中,返回值2放到rdx中。
还有下面的入参信息。
表二:
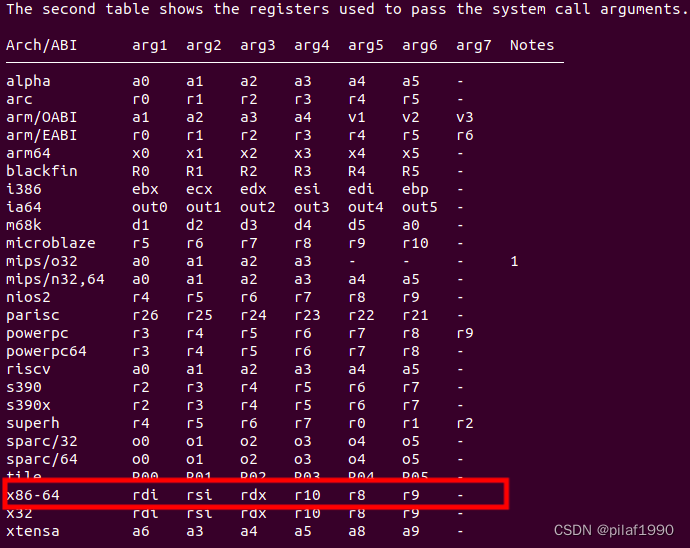
说明了x86-64的系统调用的参数1放在rdi寄存器中,参数2放在rsi寄存器中,参数3放在rdx寄存器中,参数4放在r10寄存器中,参数5放在r8寄存器中,参数6放在r9寄存器中。
回到我们的hello.asm,我们用了汇编的syscall指令调用了操作系统的系统调用,按照上面截图中说的x86-64使用syscall汇编指令的时候,会将操作系统的系统调用号放到rax寄存器中,我们的程序写的是mov rax,1,也就是说系统调用号是1,我们刚才看到说系统调用号和它的符号表示在<sys/syscall.h>头文件中的,我们在CLion(Jetbrains全家桶中的C语言集成开发环境IDE)中随便打开一个c文件,引入头文件:
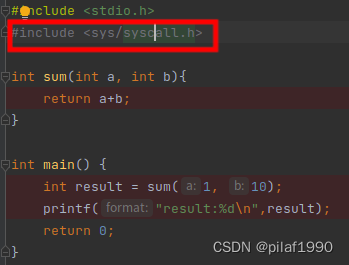
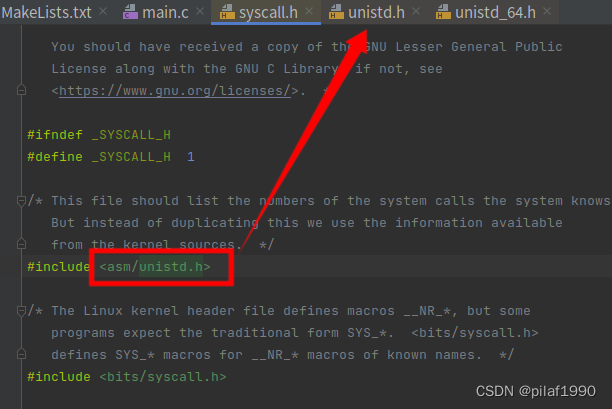
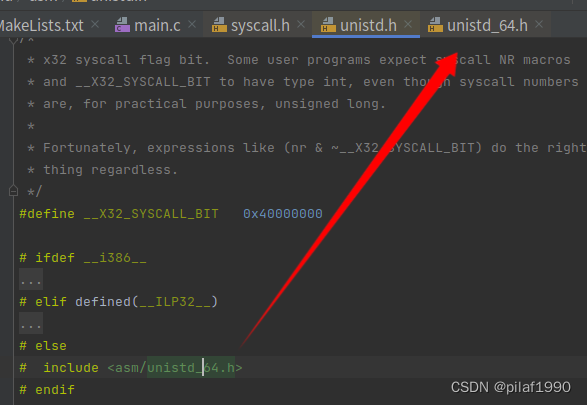
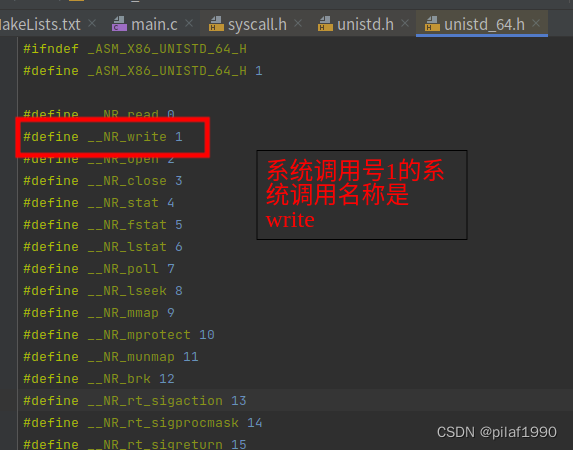
一路追踪下来,终于发现,操作系统调用号为1的系统调用名称是write!废话不多说,直接执行man 2 write看看:
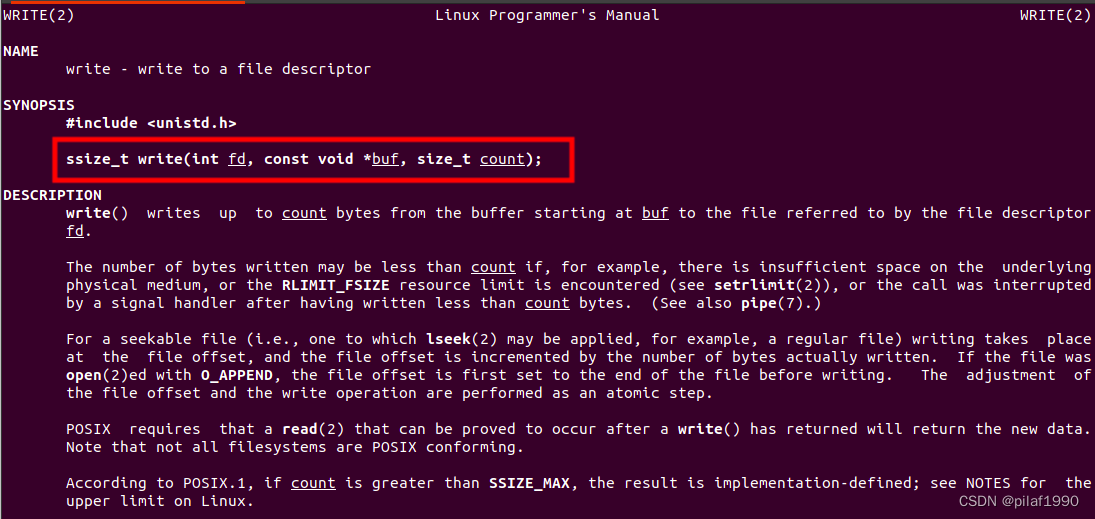
可以看到Linux操作系统的write系统调用的参数有三个,第一个是文件描述符(Linux中一切皆文件,0表示标准输入,1表示的标准输出文件描述符,2表示错误输出),第二个参数是一个指针,即输入内容起始内存地址,第三个参数表示输入的字节数。
上面表二中说了,Linux操作系统的系统调用的入参,第一个放到rdi寄存器,第二个放到rsi寄存器,第三个放到rdx寄存器等等。结合man 2 write得到的知识,传递给write系统调用的三个参数分别是1,msg的地址,14(Hello, world字符及其结尾0加上换行一共14字节)。
也就是说我们的hello.asm干了这么件事情:通过汇编的syscall指令,调用了Linux系统调用write,让write往标准输出上面输出14个字节,内容是"Hello, world"然后换行。
总结
作为菜鸟的我在运行书中的一段hello world程序的时候,书中很多地方没有写明为什么这样做,笔者通过一点点摸索,终于搞清楚其底层的运行逻辑,顿感欢喜,以此记录,希望能帮到和我一样菜的菜鸟。也希望大家不要浮躁,沉下心来,夯实基础,做一个有工匠精神的码农,也许某一天平时积累的点滴就派上了大用场。加油!
参考资料
1.《x64汇编语言:从新手到AVX专家》
2.《汇编程序设计与计算机体系结构 软件工程师教程》P211