面向对象
一切皆对象,和java一样,各编程语言一样的思想
规范
类名首字母大写,和java一样
创建的规范
python3创建类的时候,可以不带括号,也可以带,也可以显示继承object,如果带个()空括号,其实也是隐士的继承了object。这三种方式是相等的。
类的组成
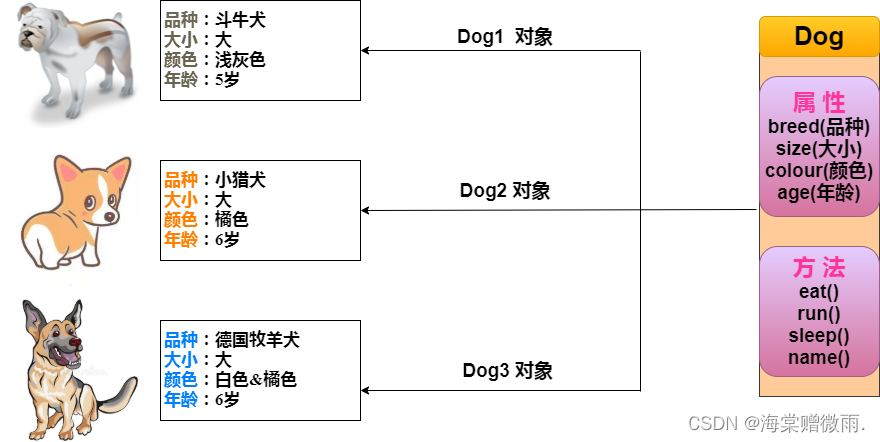
类属性:类中方法外,被该类所有对象共享
类方法:@classmethod修饰,使用类名直接访问的方法
静态方法@staticmethod,使用类名直接调用
类属性、类方法、静态方法都是用类名直接调用
实例方法
# 创建的语法
class Studnet:
native_pace = '吉林' # 类属性
# 初始化方法 这个self赋值时候不用写,赋值name和age即可,self默认带
def __init__(self,name,age): # 将局部变量的值赋值给实体属性,self.name称为实例属性
self.name = name
self.age = age
# 实例方法
# self 为这个方法名,name,age的为实例属性
def eat(self): # 这个self这里必写,self单词可以变,但程序员习惯self
print('学生在吃饭')
# 在类外定义的称为函数,类之内称为方法
# 类方法
@classmethod
def cm(cls):
print('类方法')
# 静态方法中不能写self,注意
@staticmethod
def sm():
print('静态方法')
# 类之外定义的称为函数,在类之内定义的称为方法
def drink():
print('喝水')对象的创建
和java一样
对象的创建又称为类的实例化
语法:
实例名=类名()
如stu = Student()
实例对象会有个类指针指向类对象
类名.方法名(类的对象),实际上就是方法定义处的self
Stu1 = Student('张三',20)Student.eat(stu1)动态绑定属性和方法
Python是动态语言,在创建对象之后,可以动态地绑定属性和方法
stu1 = Studnet('张三',20)
stu2 = Studnet('李四',30)
print(id(stu1)) # 和stu2不同
print(id(stu2))
print('--------为stu2动态绑定性别属性-----------')
stu2.gender = '女' # 这点和java不一样,java没有成员变量(属性-字段),是不能指定的
# Student中没有 gender属性 能动态绑定性别 ,只属于stu2自己
print(stu2.gender) # 女
def show():
print('定义在类之外的,称函数')
stu1.show = show()
stu1.show # 定义在类之外的,称函数
stu2.show # 报错 没有胃stu2动态绑定show方法,在对象上之后函数就称为方法了面向对象的三大特征
封装:提高程序的安全性
将数据(属性)和行为(方法)包装到类中。在方法内部对属性进行操作,在类对象的外部调用方法。这样,无需关心方法内部的具体实现细节,从而隔离了复杂度
在Python中没有专门的修饰符用于属性的私有,如果该属性不希望在类对象外部被访问,前面使用两个"-"
继承:提高代码的复用性
如果一个类没有继承任何类,默认继承object
Python支持多继承(java不支持多继承)
定义子类时,必须在其构造函数中调用父类的构造函数
多态:提高程序的可扩展性和维护性
封装
classStudent:def__init__(self,name,age):self.name = nameself.__age = agedefshow(self): print(self.name,self.__age)stu = Student('张三',20)# 在类外部使用name、ageprint(stu.name) # 张三# print(stu.__age) # 报错print(dir(stu)) # dir()可以查看类的所有属性和方法 ,里面找到一个_Student__ageprint(stu._Student__age) # 这样也能访问,但是不建议这种访问方式classStudent2:def__init__(self,age):self.set_age(age)defget_age(self):returnself.__age # 不希望在外面使用,所以加上两个__defset_age(self,age):if0<=age<=120:self.__age = ageelse:self.__age = 18stu1 = Student2(150)stu2 = Student2(30)print(stu1.get_age()) # 18print(stu2.get_age()) # 30继承
classPerson(object): #object默认不写也行def__init__(self,name,age):self.name = nameself.age = agedefinfo(self): print('姓名:{0},年龄{1}'.format(self.name,self.age))# 定义子类classStudent(Person):def__init__(self,name,age,score):super().__init__(name,age)self.score = scoredefinfo(self):super.info()# 还想用父类的info()可以super. print(self.score)# 重写# 测试stu = Student('Haha',20,'1001')stu.info() # 从父类中继承的方法 ,重写后就是Student的方法了object类
object类是所有类的父类,因此所有类都有object类的属性和方法
内置函数dir()可以查看指定对象的所有属性
Object有一个_ str_ ()方法,用于返回一个对于“对象的描述”,对于内置函数str()进程用于print()方法,帮我们查看对象的信息,所以我们经常会对__str _()进行重写,而不是输出内存地址
重写str
classStudent:def__init__(self,name,age):self.name=nameself.age=agedef__str__(self):return'我的名字是{0},今年{1}岁'.format(self.name,self.age)stu=Student('Haha',20)print(stu) # 我的名字是Haha,今年{20}岁 默认调用_str_()这样的方法多态
指的是一类事物有多种形态,一个抽象类有多个子类(因而多态的概念依赖于继承),不同的子类对象调用相同的方法,产生不同的执行结果,多态可以增加代码的灵活度
Python中虽然没有数据类型,但是具备多态特征
classAnimal:def eat(self): print('eating...')classDog(Animal): def eat(self): print('dog gnawing...')def fun(obj): obj.eat()fun(Animal()) # eating...fun(Dog()) # # dong gnawingJava是静态,强类型语言,Python是动态语言
静态语言和动态语言关于多态的区别
静态语言实现多态的三个必要特征
继承
方法重写
父类引用执行子类对象
动态语言的多态的多态崇尚“鸭子类型”,当看到一只鸟走起来像鸭子、游泳像鸭子,收起来也像鸭子,那么这鸟就可以被称为鸭子;
在鸭子类型中,不用对象是什么类型,到底是不是鸭子,只关心对象的行为
特殊方法和特殊属性
特殊属性
_ dict __ :获得类对象或实例对象所绑定的所有属性和方法
__ len __():通过重写它,让内置函数len()的参数可以是自定义类型
特殊方法
_add _():通过重写它,让内置函数len()的参数可以是自定义类型
_new _():用于创建对象
_init() _:对创建的对象进行初始化
classA:def__init__(self,name,age): self.name = name self.age = agex = A('Jack',18)print(x.__dict__) #{'name': 'Jack', 'age': 18}print(x.__class__) # <class '__main__.A'> 所属的类classB(A):passprint(B.__base__) # <class '__main__.A'> # 类的基类,如果多继承,谁在前输出谁print(B.__bases__) # (<class '__main__.A'>,) 输出其父类类型的元素print(B.__mro__) # 继承层次结果 B继承A继承object (<class '__main__.B'>, <class '__main__.A'>, <class 'object'>)print(A.__subclasses__())#子类列表 [<class '__main__.B'>]a = 20b = 100c = a + bd = a.__add__(b) #等同于+print(c)print(d)classStudent:def__init__(self,name): self.name = namedef__add__(self, other):# 必须在这里写,stu1.__add_(stu2)这样也报错return self.name + other.namedef__len__(self):# 必须写在这里才能计算长度return len(self.name)stu1 = Student('张三')stu2 = Student('李四')s = stu1 + stu2 # 写了__add__方法才能加,否则报错print(s) # 张三李四lst = [1,2,3,4,5]print(len(lst)) # 5print(lst.__len__()) # 5print(stu1.__len__()) # 2
new执行是优先于init的。new后的对象会给__ init __中的self
类的浅拷贝与深拷贝
变量的赋值操作
只是形成两个变量,实际上还是指向同一个对象
浅拷贝
Python拷贝如果没特殊说明的话,一般都是浅拷贝,拷贝时,对象包含的子对象的内容不拷贝,因此,源对象与拷贝对象会引用同一个子对象
深拷贝
使用copy模块的deepcopy函数,递归拷贝对象中包含的子对象,源对象和拷贝对象所有的子对象也不相同
源对象和拷贝对象的所有子对象也要重新拷贝一份
浅拷贝

classCPU:passclassDisk:passclassComputer:def__init__(self,cpu,disk): self.cpu = cpu self.disk = diskcpu1 = CPU()cpu2 = cpu1 # 这个是赋值操作print(cpu1,cpu2) # 内存地址一样# <__main__.CPU object at 0x000001A54423FF40> <__main__.CPU object at 0x000001A54423FF40>print('----------------------')disk = Disk() # 创建一个硬盘computer = Computer(cpu1,disk) # 创建一个计算机类的对象# 浅拷贝import copycomputer2 = copy.copy(computer)print(disk)# # <__main__.Disk object at 0x000001E1026AF3D0>print(computer,computer.cpu,computer.disk)# computer2和computer内存地址不同,子对象的内存地址是相同的-Disk和CPU# <__main__.Computer object at 0x000001A543EF4850> <__main__.CPU object at 0x000001A54423FF40> <__main__.Disk object at 0x000001A54423F3D0>print(computer2,computer2.cpu,computer2.disk)# <__main__.Computer object at 0x000001A5442928F0> <__main__.CPU object at 0x000001A54423FF40> <__main__.Disk object at 0x000001A54423F3D0>print('---------------------------')# 深拷贝computer3 = copy.deepcopy(computer)print(computer,computer.cpu,computer.disk)print(computer3,computer.cpu,computer3.disk)# 打印的内存地址各不同,computer、cpu、disk都拷贝了一份,内存地址变化了# <__main__.Computer object at 0x00000265D67B3E80> <__main__.CPU object at 0x00000265D67B3FD0> <__main__.Disk object at 0x00000265D67B3EB0># <__main__.C深拷贝

对于多肽
动态语言:动态语言关注对象的行为
静态语言:继承、方法重写、父类引用指向子类对象
模块
英文为Modules
一个模块可以包含N多个函数
在Pyhton中一个扩展名.py的文件就是一个模块
使用模块的好处
方便其它程序和脚本的导入并使用
避免函数名和变量名冲突
提高代码的可维护性
提高代码的可重用性
自定义模块
创建模块
新建一个.py文件,名称尽量不要与Python的自带的标准名称相同
导入模块
import 模块 [as 别名]
from 模块名称 import 函数/变量/类
import math # 导入数学模块 每一个模块都有id、type以及它的值组成print(id(math))print(type(math))print(math)print(math.pi) # 3.141592653589793#2051647076960#<class 'module'>#<module 'math' (built-in)>print(dir(math))from math import piprint(pi) # 这是能直接输出的print(pow(2,3)) # 如果不导入math,只导入from math import pi 是不能使用的以主程序形式运行
在每个模块的定义中都包括一个记录模块名称的变量_ name _,程序可以检查该变量,以确定它们在哪个模块中执行,如果一个模块不是被导入到其它程序中执行,那么它可能在解释器的顶级模块中执行。顶级模块的 _ name _变量的值为 _main _
# 开发时间:2023/2/11defadd(a,b):return a+bif __name__ == '__main__': print(add(10,20)) # 只有当运行这个calc2的时候才会执行这个主程序语句,可防止其它程序调用此类运行这个Python中的包
Python中的包
包是一个分层次的目录结构,它将一组功能相近的模块组织在一起(包中包含N多个模块)
作用
代码规范
避免模块名称冲突
包与目录的区别
创建之后默认包含__ init __ .py文件的目录称为包
目录里通常不包含_init _ .py文件
包的导入
import 包名.模块名(import只能导入包名、模块名)
用from 能导入包、模块、函数名、变量名 pageage1.module_A import ma
比如
创建python软件包
在下面新建pageage1,下面创建2模块-module_A.py/moduleB.py
在外面创建demo.py
import pageage1.module_A as ma# 现在就可以使用pageage1.module_A的内容了(别名叫ma)Python中常用的内置模块
模块名 | 描述 |
sys | 与Python解释器及其环境操作相关的标准库 |
time | 提供与时间相关的各种函数的标准库 |
os | 提供了访问操作系统服务功能的标准库 |
calendar | 提供与日期现相关的各种函数的标准库 |
urllib | 用于读取来自网上(服务器)的数据标准库 |
json | 用于使用序列号和反序列化对象 |
re | 用于在字符串中执行正则表达式匹配和替换 |
math | 提供标准算术运算函数的标准库 |
decimal | 用于进行准确控制精度、有效位数和四舍五入的十进制运算 |
logging | 提供灵活的记录事件、错误、警告和调试信息等日志信息的功能 |
简单的代码实现
import sysimport timeimport urllib.requestimport math# getsizeof是获取占用字节数print(sys.getsizeof(20)) # 28print(sys.getsizeof(21)) # 28print(sys.getsizeof(True)) # 28print(sys.getsizeof(False)) # 24print(time.time()) # 对应秒数 1676127718.0125294print(time.localtime(time.time())) # 将秒转成本地时间time.struct_time(tm_year=2023, tm_mon=2, tm_mday=11, tm_hour=23, tm_min=1, tm_sec=58, tm_wday=5, tm_yday=42, tm_isdst=0)print(urllib.request.urlopen('http://ww.baidu.com').read())print(math.pi)第三方模块
Python如此强大,离不开第三方模块
第三方模块的安装
pip install 模块名(在线安装方式-cmd安装-也是使用最多的方式)
第三方模块的使用
import 模块名(安装导入之后我们就可以使用)
在cmd窗口,我们可以输入python进入python交互模式
此时import使用已经安装的模块如果能使用证明安装成功
编码格式
编码格式介绍
文件的读写原理
文件读写操作
文件对象常用的方法
with语句(上下文管理器)
目录操作
常见的字符编码格式
Python的解释器使用的是Jnicode(内存)
py文件在磁盘上使用UTF-8存储(外存)

py默认是UTF-8,它是变长编码,1-4个字节表示1个字符,英文1个字节,汉字3个字节
文件读写原理
读写俗称IO操作-先进先出,如管道一般
文件到内存称为读,内存到文件称为写
读写之后需要关闭资源
文件读写操作
内置函数open()创建文件对象
语法规则:file = open(filename,[,mode,encoding])
file 是被创建的文件对象,open是创建文件对象的函数,
filename:是要创建或打开的文件名称,
mode:打开模式为只读模式
encoding:默认文本文件中字符的编写格式为gbk(所以我们在编译器中常见一打开乱码,并提示reload gbk)
file = open('a.txt','r') # 读,中括号是可选,写不写都行print(file.readlines()) # readlines读取的是一个列表file.close()常用的文件打开模式
常用的文件打开模式
文件的类型
按文件中数据的组织形式,文件分为以下两大类
文本文件:存储的是普通“字符"文本,默认为unicode:字符集,可以使用记本事程序打开
二进制文件:把数据内容用“字节”进行存储,无法用记事本打开,必须使用专用的软件打开,举例:mp3音频文件,jpg图片.doc文档等
打开模式 | 描述 |
r(read only) | 以只读模式打开文件,文件的指针将会放在文件的开头 |
w(write only) | 以只写模式打开文件,如果文件不存在则创建,如果文件存在,则覆盖原有内容,文件指针在文件的开头 |
a | 以追加模式打开文件,如果文件不存在则创建,文件指针在文件开头,如果文件存在,则在文件末尾追加内容,文件指针在原文件末尾 |
b | 以二进制方式打开文件,不能单独使用,需要与共它模式一起使用,rb,或者wb |
+ | 以读写方式打开文件,不能单独使用,需要与其它模式一起使用,a+ |
文件对象的常用方法
方法名 | 说明 |
read([size]) | 从文件中读取size个字节或字符的内容返回。若省略[size],则读取到文件末尾,即一次读取文件所有内容 |
readline() | 从文本文件中读取一行内容 |
readlines() | 文本文件中的每一行都作为单独的字符串对象,并将这些对象返回到列表中返回 |
write(str) | 将字符串str内容写入文件 |
writelines(s_list) | 将字符串列表s_lst写入文本文件,不添加换行符 |
seek(offset[,whence]) | 把文件指针移动到新的位置,offset表示相对于hencel的位置:offset:为正往结束方向移动,为负往开始方向移动whence(从何处)不同的值代表不同含义:0:从文件头开始计算(默认值)1:从当前位置开始计算2:从文件尾开始计算 |
tell() | 返回文件指针的当前位置,第一个字母是0,也就是从0开始 |
flush() | 把缓冲区的内容写入文件,但不关闭文件 |
close() | 把缓冲区的内容写入文件,同时关闭文件,释放文件对象相关资源-close()之后就不能写内容了,flush之后能close |
file = open('a.txt','r')file = seek(2) # a.txt有中国两字。一个字占取2字节(gbk),从国开始读(如果在pyCharm中写的txt,可能就是utf-8了,不是2字节)print(file.read()) # 国# tellprint(file.tell()) # 会把当前所有内容打印出,指向最后一个位置。如seek(2)跳过了2,如果打印hello的话只会出现llowith语句
with语句可以自动管理上下文资源,不论什么原因跳出with块,都能确保文件正确的关闭,以此来达到释放资源的目的
写文件时建议使用with语句形式

上下文为表达式,结果为上下文管理器
实现了__ enter__ () 方法和 __ exit()__方法 称为这个类遵守上下文管理协议,这个类的实例对象称为上下文管理器
# open('logo.png','rb') with之后as之前为上下文表达式,结果为上下文管理器-->同时创建一个运行时上下文-->自动调用_enter_()方法,并将返回值赋值给src_filewith open('logo.png','rb') as src_file:# as src_file:可选项上下文管理器对象的引用[可选项]src_file.read() # with语句体# 离开运行时上下文,自动调用上下文管理器的特殊方法_exit_()withopen('a.txt','r') asfile: print(file.read()) # 不用再手动close关闭了,因为离开with语句时会自动释放资源# 开发时间:2023/2/12# MyContentMgr实现了特殊方法__enter__(),__exit__()称为该类对象遵守了上下文管理器协议,该类对象的实例对象,称为上下文管理器classMyContentMgr(object):def__enter__(self): print('enter方法被调用执行了')return selfdef__exit__(self, exc_type, exc_val, exc_tb): print('exit方法被调用执行了')# print('show方法被调用执行了',1/0) 即使产生异常也会调用exit方法,称为自动关闭资源defshow(self):# 实例Method print('show方法被调用执行了')# MyContentMgr这个类遵守上下文管理协议,它的对象就称为上下文管理器,把这个对象赋给file去存储# 相当于file = MyContentMgr(),这时候就可以通过file调用它的方法# with里面的所有缩进都称为with语句体with MyContentMgr() as file:# 这个with语句体执行之后就会自动跳出上下文管理器,调用exit方法 file.show() # exit方法被调用执行了目录操作
os模块是Python内置的与操作系统功能和文件系统相关的模块
该模块中的语句的执行结果通常与操作系统有关,在不同的操作系统上运行,得到的结果可能不一样。
os模块与os.path模块用于对目录或文件进行操作
既然是和os有关的,那么可以调用os有关的文件
不需要安装,它是自带的模块
os模块操作目录相关函数
函数 | 说明 |
getcwd() | 返回当前的工作目录(文件目录) |
listdir(path) | 返回指定路径下的文件和目录信息 |
mkdir(path[,mode]) | 创建目录 |
makedirs(path1/path2...[,mode]) | 创建多级目录 |
rmdir(path) | 删除目录 |
removedirs(path1/path2......) | 删除多级目录 |
chidr(path) | 将path设置为当前工作目录 |
import os# 调用记事本# os.system('notepad.exe')# 直接调用可执行文件# os.startfile('C:\\Users\\79382\\AppData\\Local\\Google\\Chrome\\Application\\chrome.exe')os.path模块操作目录
import 导入os.path
函数 | 说明 |
abspath(path) | 用于获取文件或目录的绝对路径 |
exists(path) | 用于判断文件或目录是否存在,如果存在返回True,否则返回False |
join(path,name) | 将目录与目录或者文件名拼接起来 |
splitext() | 分离文件名和扩展名 |
basename(path) | 从一个目录中提取文件名 |
dirname(path) | 从一个路径中提取文件路径,不包括文件名 |
isdir(path) | 用于判断是否为路径 |
案例
import os.pathprint(os.path.abspath('demo13.py')) # F:\pythonProject1\venv\Scripts\demo13.pyprint(os.path.exists('demo13.py')) # Falseprint(os.path.join('E:\\Python','demo13.py')) # E:\Python\demo13.pyprint(os.path.split('E:\\vipython\\chap15\\demo13.py')) # ('E:\\vipython\\chap15', 'demo13.py')print(os.path.splitext('demo13.py')) # ('demo13', '.py')print(os.path.basename('E:\\vippython\\chap15\\demo13.py')) # demo13.pyprint(os.path.dirname('E:\\vippython\\chap15\\demo13.py')) # E:\vippython\chap15print(os.path.isdir('E:\\vippython\\chap15\\demo13.py')) # False 因为demo13.py是文件获取当前目录下的指定文件
import ospath = os.getcwd() # 获取当前目录下的所有文件lst = os.listdir(path)for filename in lst: # 获取所有以py结尾的文件if filename.endswith('.py'): print(filename)获取当前目录下的指定文件(包括子目录)
import ospath = os.getcwd()# os.walk()可以遍历指定目录下所有的文件lst_files = os.walk(path)print(lst_files) # 获取的是一个对象# 这个迭代器对象返回来的是一个元组for dirpath,dirname,filename in lst_files:''' print(dirpath) print(dirname) print(filename) print('------------') '''for dir in dirname: print(os.path.join(dirpath,dir))for file in filename: print(os.path.join(dirpath),file) print('------------------------------')
●为了应付期末考试,我又学习了一门语言
●1760字,让你拿捏['列表']
●这个字典能做什么
●强大的内置数据结构_元组(6,)
●太强了!带你轻松玩转Python集合
●学会捕捉_异常处理机制

![English Learning - L2 第1次小组纠音 [ɑː] [ɔː] [uː] 2023.2.25 周六](https://img-blog.csdnimg.cn/2dd7bac83ebb459f908f5b06c89fe968.png)







![[深入理解SSD系列综述 1.5] SSD固态硬盘参数图文解析_选购固态硬盘就像买衣服?](https://img-blog.csdnimg.cn/img_convert/0692bee0cbc042e8a32ce5869ca25185.png)
