互联网应用通常面向海量用户,其后台系统必须支撑高并发请求。在后端开发面试中,高并发技术也是一个常见的考察点。
那么,高并发系统通常是怎么设计的呢?需要采用哪些技术呢?本文就简单聊一聊高并发背后的各种技术栈。
必须明确高并发本身是目的,而不是某一项技术;只要能够提高连接数或系统处理吞吐的技术都算。因此,这是一个涉及面非常广的话题,本文无法事无巨细地展开。
我会重点罗列实现高并发的常见技术栈,并简单介绍每种技术的工作原理和应用场景,帮大家快速建立整体的知识脉络。
虽然每种技术的讲解篇幅有限,但我会列出更详细的学习资料,方便查阅学习。
大家可以以此知识地图为指引,制定学习计划,查漏补缺。
并发与并行
应用程序
- 多进程
- 多线程
- 非阻塞轮询
- IO多路复用
- 内核参数调优
负载均衡
- Nginx
- HAProxy
- LVS
- F5
- DNS
数据库
- 数据库调优
- 主从同步
- 读写分离
- 数据分片
- MongoDB分布式架构
队列异步化
推荐书单
并发与并行
通常大家对并发的理解就是同时处理多个任务,虽说没有错,但不够具体。因此,开始之前,我们有必要更准确地理解:什么是 并发 ( concurrentcy )?并发跟 并行( parallel )有何不同?
以文件下载场景为例,假设你需要下载 10 个文件,服务器响应时间是 1 秒,那么串行下载需要耗时 10 秒。文件下载这种 IO密集型应用 ,绝大部分时间都消耗在等待上。如果我们同时建立 10 个连接发出请求,再逐个等待服务器响应,那么最终可能只需消耗 1 秒左右。
这就是一个典型的并发场景,最显著的特征是 同时发起 多个任务。
再来看另一个场景,假设你有一台单核的电脑,正在压缩一个很大的文件。压缩程序需要消耗很长时间,期间你要处理邮件,编辑文档。操作系统提供分时机制,压缩程序时间片用完就调度其他程序到 CPU 上执行。
这也是一个并发的场景,用户同时发起多个任务进程,它们轮流使用 CPU 。这样用户不用等待压缩程序执行完毕就能同时收发邮件,操作体验好很多。
如果你同时压缩两个大文件,假设每个都要消耗 2 分钟,最终还是要至少消耗 4 分钟。因为 CPU 是单核的,就算两个压缩程序都在运行,但同一时间只有一个能在 CPU 上执行。因此,像这种 计算密集型应用 ,并发并不能缩短执行时间。
这时您可能会想到多核 CPU ——没错!多核 CPU 每个核心可以近似看成一个完整的 CPU ,能够独立执行程序。这样一来,两个压缩程序可以分布在不同核心上,同时执行,整体耗时将减半!
这个场景就是所谓的 并行( parallel ),一种比并发更进一步的形态,最显著的特征是 同时执行 。
- 并发( concurrency ),同时发起,但不一定同时执行;
- 并行( parallel ),同时执行;
应用程序
互联网应用系统想要支持高并发,势必要具备同时处理大量 TCP 连接的能力。应用进程通过操作系统提供的套接字进行 TCP 通信,如果采用经典同步阻塞模式,一个程序同一时间只能处理一个套接字连接,何谈高并发?
在同步阻塞 IO 编程模型中,套接字默认是阻塞的。程序读写套接字时,recv 和 send 等系统调用会一直等待直到对方数据到达,或者本方数据发出。在阻塞等待期间,程序无法执行其他任务。
那么,如何实现在同一个程序中同时处理多个 TCP 连接呢?
多进程
在远古时代,我们通常利用多进程技术来处理并发 TCP 连接:
- 主进程负责监听端口,收到新连接后 fork 子进程进行处理;
- 新连接套接字被子进程继承,子进程为新连接提供服务,处理完毕后便退出;
这个方案在同步阻塞 IO 模式下采用多进程实现并发处理能力,胜在开发简单,但缺点也很明显:
- 每个连接占用一个进程,资源开销将严重制约程序的最大并发数;
- 多个进程轮流竞争 CPU 执行权,上下文切换开销大;
相关视频推荐
高并发场景下,三种锁方案:互斥锁,自旋锁,原子操作的优缺点
6种epoll的设计方法(单线程epoll、多线程epoll、多进程epoll)
8个nginx面试题,助你了解nginx的底层设计
免费学习地址:c/c++ linux服务器开发/后台架构师
需要C/C++ Linux服务器架构师学习资料加qun812855908获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享

多线程
由于进程的资源开销相对较大,操作系统提供了一种更轻量的进程——线程。一个进程可以创建多个执行线程,它们共享进程内存等资源,因此开销相对较小。编程模式上跟前面提到的经典多进程方案类似:
- 主线程负责监听端口,收到新连接后创建一个子线程进行处理;
- 子线程启动后为新连接提供服务,服务完毕后则退出;
相比多进程,多线程方案有不少优点:
- 所有线程共用进程中的内存资源,内存开销相对较少;
- 线程切换成本比进程小,因为内存是共享的,页表不用切换,TLB 缓存也不用刷;
现代操作系统进程采用虚拟地址来访问内存,由 CPU 负责将虚拟地址转换成物理地址。虚拟地址和物理地址的映射关系由 页表( page table )维护。CPU 根据页表做地址转换,并采用 TLB 缓存提升转换速度。 当 CPU 发生进程切换,需要先加载新进程的页表,并刷新 TLB 缓存。这是一个开销相对较大的操作,会制约系统的最终性能。因此,应用工作进程通常不能超过 CPU 核数,有些场景甚至会将主要进程跟 CPU 核心一一绑定,以避免进程切换开销。
那么,线程是不是就没有开销了呢?当然不是啦!
- 线程有独立的执行栈,线程数一多也要消耗很多内存;
- 线程切换要保存旧进程 CPU 寄存器(执行状态),然后加载新线程的寄存器,由此导致的 CPU 缓存和指令流水线失效,也会带来不少损耗;
关于多进程和多线程编程技术,本文就简单介绍这些。想要进一步理解进程和线程的工作原理、区别和联系,可以复习一下操作系统:
推荐书籍:《现代操作系统 原书第4版 操作系统教材 从入门到精通》
想要学习 CPU 的运行原理,更深入理解页表和 TLB 缓存的作用,可以复习计算机组成原理:
推荐书籍:《计算机组成与设计:硬件/软件接口(原书第5版 RISC-V版)》
想要学习多进程和多线程编程方法,掌握相关系统调用和代码开发技巧,可以看看 APUE :
推荐书箱:《UNIX环境高级编程 第3版》
非阻塞轮询
既然一个连接开一个进程或线程来处理开销太大,那有办法在一个执行流中同时处理多个连接吗?
同步阻塞模式下最棘手的问题是,套接字读写操作是阻塞的,会卡住进程或线程执行流。为此,操作系统支持将套接字设置成非阻塞模式:就算数据仍未就绪,读写操作也不会一直等待;而是直接返回错误,程序可以接着执行。
- 阻塞模式:读写操作会等待,直到数据就绪(函数调用迟迟不返回);
- 非阻塞模式:读写操作不会等待(函数调用立马返回);
由于应用程序不知道每个连接的数据何时就绪,因此只能进行轮询。举个例子,假设服务器进程通过 accept 系统调用接收到 3 个新连接,它并不知道这三个连接何时发请求上来。它只能采用轮询策略,定期尝试读取每个新套接字,看哪个有发数据过来。
非阻塞轮询方案也不完美,主要硬伤还是性能问题:
- 轮询时无差别读取,空闲连接也要读一遍,开销较大;
- 连接数据发上来后,要下一次轮询才能读到,及时性差;
- 为提升及时性,势必要提高轮询频率,但这样开销更大;
IO多路复用
为克服非阻塞轮询方案的种种缺点,操作系统又提供了 IO多路复用 ( IO multiplexing )技术。
IO 多路复用顾名思义,就是通过一次系统调用同时监视多个 IO 对象(套接字):应用进程执行系统调用告诉操作系统监视哪些文件描述符,当它们有可读、可写或错误事件时,系统调用返回告知应用程序。
IO 多路复用技术发展至今,已历经若干代,以 Linux 为例:
- 第一代:select ,解决有无问题;
- 第二代:poll ,优化文件描述符传递,突破数量限制;
- 第三代:epoll ,全面解决性能问题;
select
应用进程执行 select 系统调用,将要监视的文件描述符(套接字)列表传给内核:
int select(int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout);文件描述符列表分为 3 组,分别是:
- readfds ,监视可读事件,套接字上有数据到底时触发;
- writefds ,监视可写事件,数据送达对端套接字发送缓冲区释放时触发;
- exceptfds ,监视异常事件,内核网络协议栈检测到异常时触发;
内核接到系统调用后,逐一遍历每个文件描述符;当有文件描述符就绪时,select 系统调用便返回。就绪的套接字同样通过这几个参数,传回应用程序(通过指针修改数据)。
如果当前所有文件描述符均为就绪,select 系统调用会阻塞等待,直到:
- 有文件描述符就绪;
- 进程通过 timeout 指定的超时时间到达;
应用进程只需执行一次 select 系统调用,即可监视多个套接字,效率比应用进程自己轮询显著提高。不过,您可能也猜到了,select 也有它的局限性:
- 文件描述符列表 fd_set 大小有限制,通常只支持 1024 个文件描述符;
- 该限制由一个宏定义指定,虽然可以调节,但需要重新编译内核
- 每次调用需要将关注的全部文件描述符拷贝到内核,开销很大;
- 内核需要遍历每个文件描述符,本质上还是轮询;
select 在内核中轮询比进程在用户空间自己轮询高效,因为系统调用的开销降低了:本来每检查一个套接字就需要执行一次系统调用,现在总共只需要执行一次。 进程执行系统调用是有开销的,因为需要进行用户态和内核态切换( CPU 执行栈和寄存器)。只不过跟进、线程切换相比,系统调用上下文切换开销要小很多。 进程切换 > 线程切换 > 用户态内核态切换
更多关于 select IO多路复用的编程技巧,可以参考 APUE 或 Unix网络编程 :
推荐书箱:《UNIX网络编程 卷1 套接字联网API 第3版》
更多关于内核态、用户态、系统调用、上下文切换的细节,请查阅操作系统和 Linux 内核相关资料:
推荐书箱:《Linux内核设计与实现 原书第3版》
poll
poll 主要解决 select 文件描述符列表大小限制问题,它采用 pollfd 结构,列表大小可灵活调节:
int poll(struct pollfd *fds, nfds_t nfds, int timeout)- fds ,即待监控文件描述符列表,它是一个 pollfd 结构体数组,数组大小是动态的;
- nfds ,fds 数组长度;
虽然 poll 解决了文件描述符大小限制问题,但其他实现跟 select 差不多:
- 文件描述符集合仍需在用户态和内核态间复制;
- 检测仍需要轮询遍历每个文件描述符;
总体而言,随着监控套接字集合的增加,poll 性能会线性下降,因此也不适用于大并发场景。
epoll
为解决 select 和 poll 的性能问题,Linux 内核后来实现了 epoll 机制,有针对性地进行了优化:
- 文件描述符只需注册一次,不用每次都传进内核;
- 执行 epoll_ctl 系统调用,注册/修改/取消要监视的文件描述符;
- 内核用红黑树维护注册的文件描述符,提高查找效率(避免遍历);
- 采用回调函数机制订阅 IO 事件,避免轮询;
- epoll_ctl 添加新文件描述符的同时,内核会注册 IO 事件回调函数;
- 当相关 IO 事件发生,回调函数就会执行,内核就知道哪些文件描述符就绪了;
- 只返回就绪文件描述符到用户空间;
- 回调函数执行时,内核会将对应的活跃描述符加入就绪链表;
- epoll_wait 等待文件描述符就绪,然后只需取出就绪链表并返回,不用遍历;
- 应用进程只处理就绪文件描述符,无需遍历每个文件描述符进行判断;
采用 epoll 机制,应用进程通常这样操作:
- 执行 epoll_create 系统调用,创建 epoll 专用文件描述符(保存相关上下文);
- 参数 size 告诉内核监听规模,这不是一个限制,只是一个建议值,内核据此分配资源初始化相关数据结构;
- epoll 创建红黑树用于保存待监听文件描述符;
- epoll 创建就绪链表用于保存就绪的文件描述符;
- 执行 epoll_ctl 系统调用,注册、修改、移除待监听文件描述符;
- EPOLL_CTL_ADD 注册新的文件描述符,内核将该文件描述符保存到红黑树,然后注册 IO 事件回调函数;
- 当 IO 事件发生,回调函数被执行,对应文件描述符将被放入就绪链表;
- EPOLL_CTL_MOD 修改已注册的文件描述符,根据要订阅的事件,调整回调函数注册;
- EPOLL_CTL_DEL 移除文件描述符注册,删除回调函数注册;
- 执行 epoll_wait 系统调用,等待文件描述符就绪;
- 内核直接从链表中取出就绪文件描述符并返回;
- 应用程序直接处理就绪文件描述符,无需逐个遍历;
- 如果就行链表为空,epoll_wait 可以阻塞直到其中有一个就绪;
另外,epoll 还支持不同的触发模式:
- 水平触发,以读事件为例,只要文件描述符可读,就会一直返回;
- 边缘触发,以读事件为例,仅当文件描述符从不可读变成可读时,才会返回;
边缘触发模式通常效率更高——因为 epoll 只在文件描述符变为可读时通知一次,不会重复通知。但边缘触发模式代码编写起来要复杂一些,应用进程必须自己持续读取,以免遗漏。
更多关于 epoll 的工作原理和编程技巧,可以参考《Unix网络编程》:
推荐书箱:《UNIX网络编程 卷1 套接字联网API 第3版》
操作系统调优
采用 IO 多路复用之后,进程连接数可能还是上不去,这时需要检查 Linux 系统参数。有两个非常重要的参数制约一个进程能够打开的文件数上限,包括套接字。第一个是内核参数 /proc/sys/fs/file-max :
$ cat /proc/sys/fs/file-max
100000这个参数控制 Linux 系统最多允许同时打开多少个文件,是系统级别的硬限制。如果这个参数设置过小,进程连接数肯定上不去。通常 Linux 内核会根据系统硬件资源(内存)状况自动计算该限制,如无特殊需要不必调整。
如果该参数当前设置太小,可以手工调大:
$ echo 1000000 > /proc/sys/fs/file-max还有另一个限制是 ulimit ,更具体讲是其中的 nofile ,它控制一个进程能够打开的最大文件数。nofile 参数分两个值来设置,其中:
- hard ,设置硬限制,进程能自己调节,但只能调小;
- soft ,设置软限制,进程能自己调节,既能调大也能调小,但不能超过 hard ;
最终进程能打开的最大文件数受 soft 值直接控制,受 hard 值间接控制。之所以将参数分成两个值,我猜是内核想想让进程自主控制最大文件数,又不想其超过既定范围,分成两个值更灵活一些。
很多 Linux 系统 ulimit.nofile 默认设置为 1024 ,这意味着进程最多能同时处理的连接数只有一千出头!如果需要调大,可以执行 ulimit 命令或编辑 /etc/security/limits.conf 文件,本文不再赘述。
关于 Linux 资源限制( resource limit 或 rlimit )更多细节,可以查阅 Linux 经典书籍:
推荐书箱:《鸟哥的Linux私房菜 基础学习篇 第3版》
采用 IO 多路复用技术,并调好关键内核参数,单个应用进程能够实现相当可观的并发。由于现代 CPU 通常有很多核心,因此我们还可以采用多进程技术,进一步提高并发能力。
这里的多进程跟之前的已有本质区别,每个进程都能同时支持很多并发连接,而不仅仅是一个。如果还想继续优化,将单机性能发挥到极致,就只能深挖处理器架构和 Unix 内核相关知识了。
处理器方面要了解 SMP 和 MUMA 架构、流水线以及缓存原理,才能有针对性地进行优化。举个例子,处理同样的大矩阵,按行还是按列遍历性能可能会相差一个数量级,因为不好的访问方式会让 CPU 缓存失效。
这方面我推荐看《深入理解计算机系统》,里面有很多例子:
推荐书箱:《深入理解计算机系统 原书第3版》
Linux 内核方面则可以看看《Linux内核设计与实现》,补全关于进程调度、内存管理等知识。
负载均衡
采用 IO 多路复用技术配合多进程,我们可以将多核机器的性能发挥到极致。然而性能再好的机器,它能够支撑的并发负载也是有限的,毕竟 CPU 核心就那么多个。这时又该如何优化呢?
我们可以将应用从 单机架构 升级到 分布式架构 ,以实现 水平扩展 。水平扩展的思路简单粗暴,一台机器不够,那就两台;两台不够就三台,还不够还可以继续加!
那么,如何实现能够水平扩展的分布式架构呢?
我们可以将应用部署到若干台机器上,请求可以送到任意一台机器上处理。这样一来,一个 N 节点组成的应用,其处理能力理论上可以达到单机模式的 N 倍。
换句话讲,系统的处理能力,跟系统的节点数成线性关系。这是一种非常有弹性的系统架构,特别适用于应用负载会随时间变化的场景。当系统负载上升时,只需为系统扩容新机器;当负载下降时,则反过来缩容一些。
还有一个问题,怎么将请求分发到不同的机器上执行,并且尽量均匀呢?总不能让客户端自己来决定请求哪个节点吧?这就需要引入 负载均衡 ( load balancing )技术。
负载均衡顾名思义就是负责将请求负载,均匀地分发到背后的工作节点。按负载均衡工作的网络层次,可以进一步分为两种:
- 四层负载均衡,工作在传输层;
- 七层负载均衡,工作在应用层;
业界的负载均衡技术很多,常用的有
- Nginx
- HAProxy
- LVS
- DNS
- etc
Nginx
Nginx 是一款非常强大的 Web 服务器,常用于 路由转发 和 负载均衡 场景。
假设有一个电商站点,后台应用原来部署在一台机器上。现在由于用户量快速上涨,急需扩容。我们可以再找一台机器,部署上后台应用,然后前面再部署一个 Nginx 来分发流量:

如上图,Nginx 充当 反向代理( reversed proxy )的角色,客户端直接将请求发给 Nginx ,由 Nginx 负责转发到其后面的两台 Web 应用服务器。这一切对客户端来说是完全透明的,它们只跟 Nginx 打交道,因此反向代理常被称为透明代理。
Nginx 反向代理配置起来也很简单,我们来看一个例子:
server {
# 监听端口
listen 80;
# 代理对外域名
server_name proxy-site.com;
location / {
# 转向服务器
proxy_pass http://dest-site.com;
proxy_redirect default;
}
}
# 服务器集群及权重(可选)
upstream dest-site.com {
server 10.0.0.1:80 weight=1;
server 10.0.0.2:80 weight=2;
}这个例子定义了一个 upstream ,包含两台应用服务器,假设 IP 分别是 10.0.0.1 和 10.0.0.2 ;server 节则定义 proxy_pass 将所有流量转到这个 upstream 。注意到,upstream server 还能设置权重,给性能好点的服务器分发更多流量。
简单业务场景,请求通常可以落在任一台服务器处理,因此 Nginx 只需随机转发。但在某些复杂的业务场景可能就不行,比如有的需要实现会话保持。
举个例子:如果应用服务器将登陆会话保存在本地,那么 Nginx 必须保证登录后的请求都落在原来那台。否则若登录时落在 A 节点上处理,之后又落在 B 节点就会有问题,因为 B 并没有保存该请求的会话信息。
那么,Nginx 如何配置会话保持呢?常用的配置手段有两种:
- ip hash ,根据客户端 IP 哈希决定转发到哪个节点;
- 客户端 IP 如果发生变化,转发节点很可能也会变化,进而导致会话失效;
- 根据 IP 哈希,理论上可以将请求均匀地分布在不同节点;
- 但来自同一局域网的客户端,由于出口 IP 相同,会被转发到同一节点,可能导致负载失衡;
- sticky_cookie_insert ,启用会话亲缘关系,Nginx 设置 cookie 并据此决定转发;
- 基于 cookie 而非客户端 IP 来判断,可以避免同一局域网或前端代理导致的负载均衡;
哈希映射 是一种简单高效的数据映射方法,做法很简单:
- 对映射节点进行编号,N 个节点可以编号成 0 ,1 ,…… , N-1 ;
- 对数据(如 IP 地址)求哈希值,并对 N 取模( hash % N ),得到一个 0 到 N-1 的数值,就是映射到的节点编号;
Nginx 还支持配置健康检查,对 upstream 后端服务进行监控,发现故障就将其剔除:
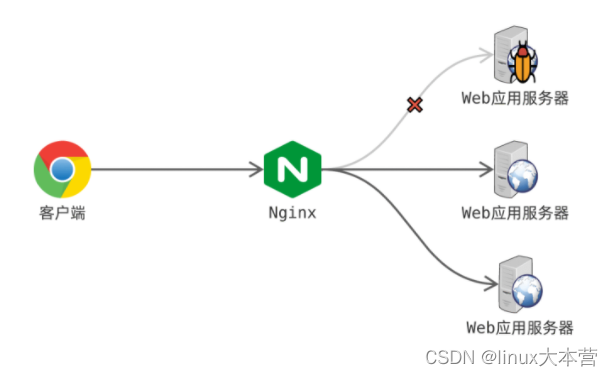
如上图,Nginx 背后配了 3 台 Web 应用服务器,其中第一台服务器发生故障;Nginx 通过健康检查发现了故障,并将其从 upstream 中摘除;新进来的请求将分发到正常的服务上,因此客户端对此完全无感。这种集群架构允许集群部分节点故障,系统功能完全不受影响,因此同时实现了 高可用( high availability )。
因此,利用负载均衡技术,我们可以实现高并发,也可以实现高可用,或者兼而有之。
HAProxy
Nginx 通常应用于七层(应用层),它可以配置复杂策略,根据 HTTP 请求内容(如 cookie )来转发请求。如果采用其他应用层协议,或者不关心应用层协议,只需按端口转发,则可以采用 HAProxy 。
HAProxy 本质上是一个端口转发器:它监听自己的服务端口,然后把客户端的连接转发到背后的服务器上:
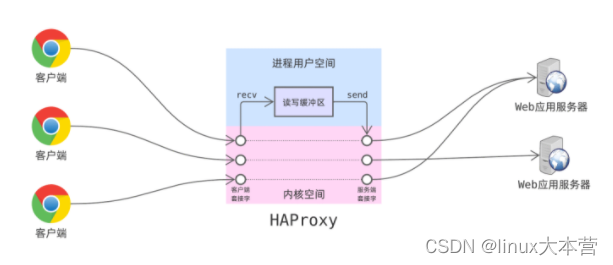
- 一个客户端连上了后,HAProxy 会拿到一个连接套接字;
- HAProxy 根据转发策略,代表该客户端与背后的服务器建立连接,得到另一个套接字;
- 此后 HAProxy 负责在这两个套接字间来回拷贝数据;
由于 HAProxy 只是一个四层转发转发器,它配置起来比 Nginx 要简单一些。当然了,功能也更为单一,但在简单的业务场景下,也是够用的。
LVS
根据套接字编程接口,HAProxy 转发数据时需要先将数据从一个套接字读到( recv )用户空间,再通过对应的套接字发送( send )出去。很显然,这会导致了大量的数据拷贝:读取时从内核空间拷贝到用户空间,发送时从用户空间又重新拷贝回内核空间。
为避免不必要的数据拷贝,内核提供了 sendfile 系统调用进行优化。sendfile 系统调用将数据从一个文件描述符读取出来,并写到另一个,期间无需在用户态和内核态间拷贝数据。
虽然 sendfile 避免了数据拷贝,但系统调用还是避免不了。如果端口转发可以绕过进程,直接在内核中做,那性能肯定还会大幅提升。为此,章文嵩博士在内核中实现了 LVS( Linux Virtual Server )。
LVS 是一个基于四层,工作于内核且性能十分强悍的反向代理服务器,支持很多模式:
- DR 模式;
- NAT 模式;
- FULLNAT 模式;
对比 HAProxy ,LVS 的工作原理要复杂很多。因篇幅关系,本文就不再深入介绍了。后续有机会,我再写篇文章详细讲解一下。现在,我们只这样理解 LVS :
- 工作于内核;
- 实现四层转发;
- 无数据拷贝,性能强悍;
- 支持回程流量不经过代理接入节点直接回给客户端,能有效缓解接入节点的带宽瓶颈;
F5
LVS 性能比 HAProxy 要好很多,但毕竟只是软件负载均衡技术,性能仍达不到极致。如果想要得到更好的性能,可以采用一些硬件解决方案,比如 F5 。
硬件负载均衡技术,本质上跟前面介绍的软件解决方案是一样的。只不过硬件不存在操作系统中断、上下文切换等软件处理开销,因此性能会好很多。当然了,硬件解决方案通常也比较贵,因为需要买专用设备。
DNS
根据 DNS 协议,一个域名可以解析到多个不同的 IP 上。因此,DNS 也可以用来做负载均衡,水平扩展系统的处理能力。
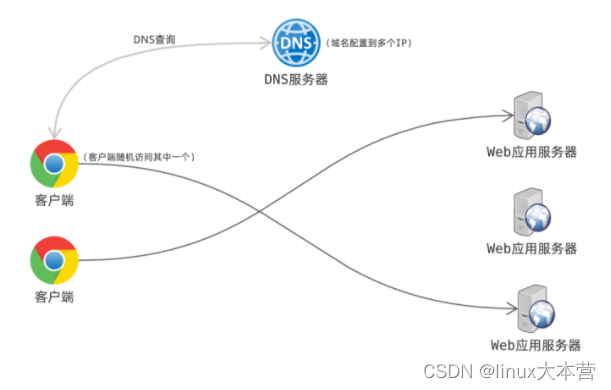
举个例子,假设我的站点 fasionchan.com 的访问量很大,我可以多部署多几台服务器,然后把 IP 都配置到 DNS 。用户访问站点需要先解析域名,由于得到的 IP 有多个,它会随机挑一个来访问。正因 IP 选择是随机的,每台服务器的负载大致是均匀的。
数据库
互联网后台通常是由应用程序和数据库组成的大型系统,如果数据库性能跟不上,就算应用程序优化得再好也是白搭。那这部分我们就一起来研究一下,如何对数据库进行优化。
数据库调优
数据库调优这个话题还是很大,涉及面非常广。小到字段类型,大到索引设计,SQL 语句写法都会影响查询性能。
举个例子,有一个长度很大的字段需要建索引,最好另存一个 MD5 字段,把索引建在 MD5 字段上。因为 MD5 值的长度是固定的,而且长度相对较短,不管是索引空间还是查询效率都会显著提高。
由于本文只是指引性介绍,姑且以这个例子抛砖引玉,有兴趣的读者可以深入学习《高性能MySQL》之类的权威著作:
主从同步高可用
前面提到,应用程序可以部署多个节点,配合负载均衡技术实现高可用。那么,数据库也可以这样实现高可用吗?
我们来考察一个简单的场景,假设我们有一个类似微信朋友圈的应用:
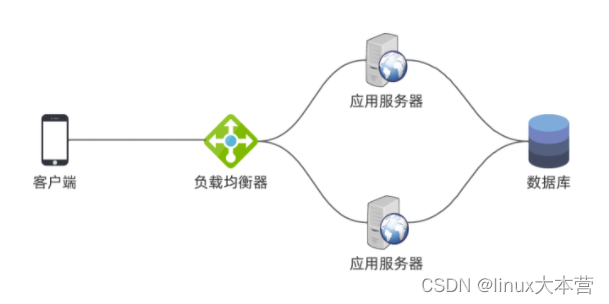
我们部署了多台应用服务器,提供后端 API 接口,它们都连同一个数据库。客户端的请求上来后,先经过一个负载均衡器,由它转发给应用服务器。应用服务器则根据业务逻辑,对数据库进行读写。
这个架构应用服务器是高可用的,因为不管哪个节点挂了,负载均衡器都可以将流量送到健康节点。想要容忍更多服务器故障,我们只需部署更多节点。只要不是所有服务器都挂点,我们的服务就不受影响。
但是,我们的数据库只有一台!但由于数据库是典型的有状态服务,不能无差别地部署多实例。试想用户发朋友圈写 A 库,读朋友圈读 B 库不就发现自己的数据不见了吗?
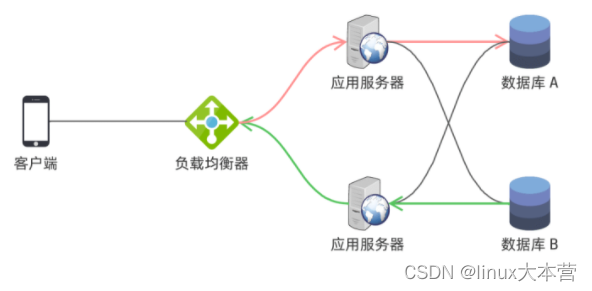
因此,数据库部署多实例后还需要同步数据,确保每个实例数据是一致的。由于多点写入会给数据同步带来挑战,数据冲突可能难以解决,因此通常采用主从同步模式:
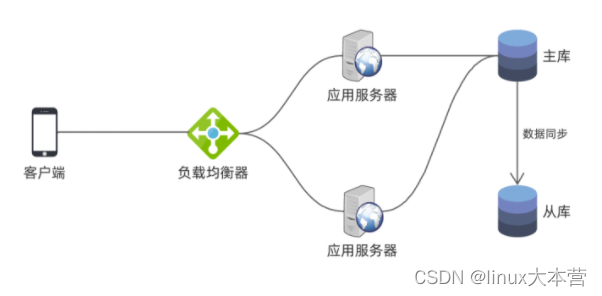
如上图,应用连接主库读写数据,从库连接主库同步数据。平时应用不会连接从库,因此从库只起到备份数据的作用。当主库故障无法恢复时,管理员可以将应用切到从库,从库转为主库,继续提供服务:
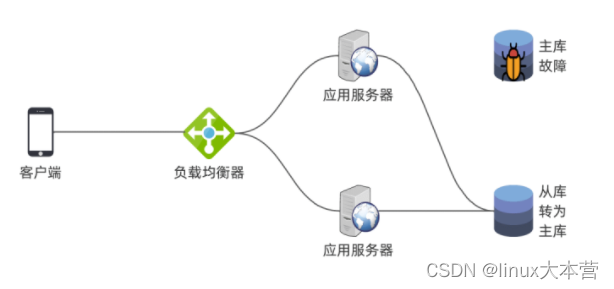
- 由于数据同步存在时延,因此从库跟主库可能不一致;
- 主从切换需要人工判断是否安全,以及切换后是否需要进行数据维护,以保证数据一致性;
- 当主库恢复后,可以转为从库,连接新主库同步数据;
采用主从同步架构后,就算主数据库故障短时间无法恢复,管理员也可以将应用切到从库从而恢复服务,可用性在一定程度上得到有效保障。
读写分离
假设我们要实现一个类型朋友圈的功能,后端提供一个 API 模块。用户发朋友圈时,前端调用 API 写数据库;用户刷朋友圈时则调 API 读数据库。这是一个应用的最小化模型,很简单对吧?
假设现在应用的用户量很大, 很多人都在刷朋友圈,数据库查询压力很大,怎么办呢?
最简单的做法是部署主从同步架构来做读写分离:
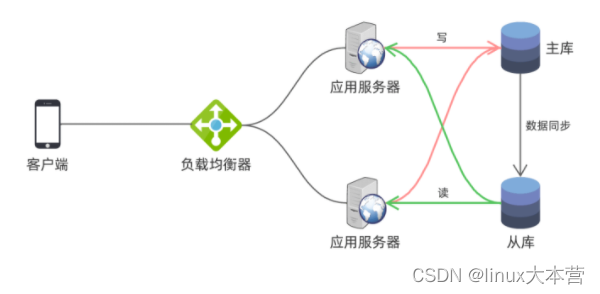
如上图,数据库部署主从同步结构,应用写操作连到主库上,读操作连接到从库上。这样读压力就从主库分散到从库上,从而获得更大的吞吐量。如果读压力很大,我们还可以多部署几个从库,进一步分散读压力。
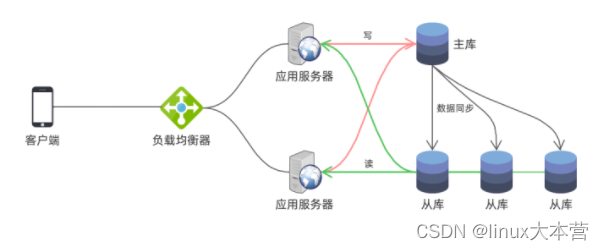
因此,主从同步结构特别适用于读压力很大的业务场景。
数据同步延迟
用户发朋友圈,数据写入主库后,还要经过一小段时间之后才能同步到从库。假设你发了朋友圈,数据还没同步到从库,这时你刷新自己的首页,岂不是发现自己发的朋友圈丢了!
因此,采用读写分离架构的应用,必须关注数据同步延迟,并加以处理。拿这个例子来说,应用服务只要保证当前用户的朋友圈总是到主库读,就不会有问题。
单调读
假设好友发了一条朋友圈,写入主库,但只有从库①已经同步,从库②和③尚未完成同步,这时你刷朋友圈会发生什么现象?
由于刷朋友圈是一个读操作,应用服务器会连接从库读取数据。如果连的是从库①,这时可以读到好友的朋友圈。假设这时你刷新了页面,应用服务器连接从库②读取数据, 这时你会发现好友发的朋友圈消失了!你再刷新,如果又连回从库①,这时朋友圈又出现了,再刷一下可能又消失了……
由于从库的同步速度不是完全一致的,而且步调也难以控制,因此应用肯定会读到不一致的数据。那么,我们应该怎么解决这个问题呢?
其实很简单,应用服务器可以根据用户算哈希值,来决定连哪个从库,以此保证同个用户会固定读一个从库。这样一来,只要朋友圈记录从主库同步到当前从库,被用户读到之后就不会再消失。
从库数据的同步进度,决定了其数据快照的时间点。一旦读取到新的数据快照,就不会重新读到旧快照,这就是所谓的 单调读 。
关于读写分离架构就先简单介绍这些,更多细节大家可以阅读《数据密集型应用系统设计》深入学习:
数据缓存
数据库读压力太大,还可以通过引入缓存来解决。举个例子,网络论坛应用首页展示热门帖子,这需要查询数据库。而且这不是一个简单查询,开销可能较大。如果每个用户刷新首页都要查一遍数据库,压力可想而知。
热门帖子通常在短时间内不会变化,因此我们可以将查询结构缓存起来:
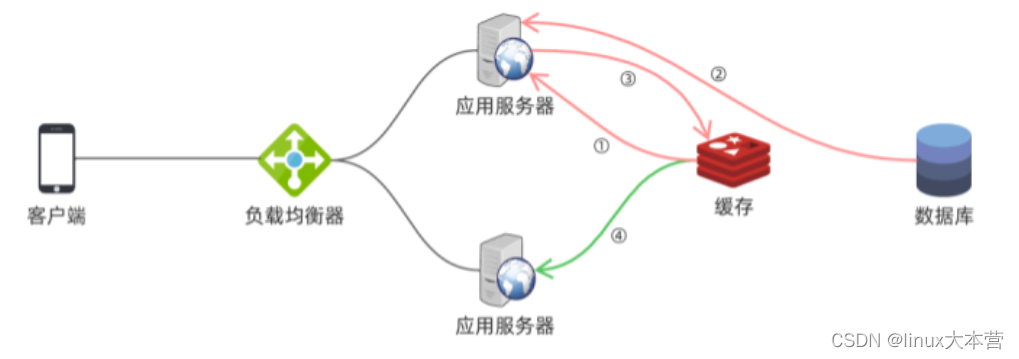
- 应用服务器先查缓存——①;
- 如果缓存数据不存在或者已经过期,查询数据库——②;
- 将数据库查询结构写到缓存,同时可以设置有效期——③;
- 只要缓存数据尚未失效,应用程序可以直接从缓存中读取——④;
有了缓存挡在前面,应用服务器仅当缓存失效时才会查询数据库,因此数据库压力大幅降低。如果应用服务器采用多节点部署,查库写缓存操作(如图②和③)可能需要用分布式锁加以保护。
至于缓存模块的实现,可以采用目前很流行的中间件,比如:
- Redis
- Memcached
数据分片
在海量业务面前,以上这些套路还是远远不够的。假设你有一个国民级应用,你光用户表就得有十几亿条数据!那问题来了,什么样的数据库才能支持单表十几亿规模的在线查询呢?
常用数据库对此可能都无能为力,以 MySQL 为例,单表数据规模达到千万级以上后,性能就会有明显下降。那问题是否就完全无解了呢?
计算机科学中有一个非常有名的分治思想,几乎放之四海而皆准。我们可以对大表进行划分,分成若干小表,然后存放到不同的数据库上。

这样一来,每个数据库中的数据量下降了,压力也就下降了。不过我们还有一个问题尚未解决,数据应该如何划分呢?如果是随机划分,查询时如何确定查哪个库呢?难不成每个库都查一遍?
数据划分
一般而言,可以采用以下两种策略来划分数据:
- 哈希划分,对数据键(唯一用户名)求哈希值,决定保存在哪个库;
- 范围划分,对数据区间进行分段后保存,比如身份证号为 44 开头的保存在某个库;
哈希划分
回到前面的例子,我们可以先对用户名求哈希值,再根据哈希值决定数据保存到哪个子库。这种划分方式通常可以保证数据基本上是均匀的,因为哈希映射是随机的。
查询时,应用需要根据查询条件决定查询哪个数据库。举个例子,如果查询 tom 的用户信息,计算 tom 的哈希值并进行映射即可知道应该查询数据库②。
不过有些查询无法确定子数据库,只能每一个都查一遍,再合并结果。例如查询 tom 的好友,查询条件没有包含哈希用的字段,也就无法做哈希映射;而 tom 的好友可能保存在任一个子库中,因此只能全部查一遍。
一致性哈希
顺便提一下,如果只是采用普通哈希方法,增减子库时会导致大量的数据迁移。因为 N 一变,哈希值取模出来的序号也跟着变,那映射关系也就全变了。映射关系一变意味着我们需要将数据从旧库,迁移到新映射的库上去。
这种问题可以采用 一致性哈希 ( consistent hashing )算法加以解决,它通过引入一层虚拟节点,来减少映射关系的变动。
范围划分
范围划分,顾名思义就是将字段值的范围划分为若干区间,再分别保存到不同的子库。举个例子,有个应用用户 ID 的范围在 1~1000000 之间,用户表需要分 5 个子库存储,可以这样分:
- 1~200000 ,存在子库①;
- 200001~400000 ,存在子库②;
- 400001~600000 ,存在子库③;
- 600001~800000 ,存在子库④;
- 800001~1000000 ,存在子库⑤;
分段太大通常不太灵活,例如数据分别可能不均匀。因此,我们可能需要缩小分段范围,比如以 100 为一个段,1 百万的 ID 范围可以划分为 1 万个区间,再映射到子库上去,而映射关系作为元数据保存。
如果发现某个子库负载较高,可以将上面的某些区间数据迁移到其他节点上,数据库维护起来就灵活多了。
MongoDB案例
MongoDB 是一个典型的分布式数据库,我们就以它为学习案例,深入考察 数据复制 和 数据分片 相关架构设计。
- 数据复制( replication ),通常为了实现高可用,同时也实现压力分散;
- 数据分片( partitioning ),通常为了实现水平扩展;
MongoDB 支持主从同步,通常是一个主节点加两个从节点组成一个 复制集( replica set ),检查 RS :
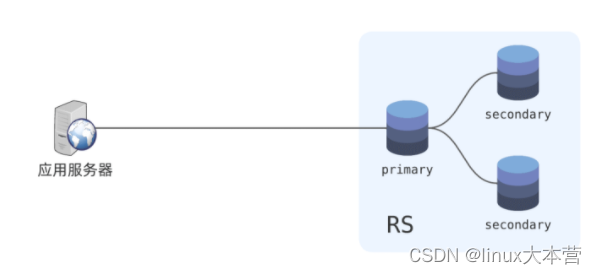
如上图是一个三节点组成的复制集,三个节点保持通信,并通过分布式共识算法选举主节点。主节点接收写请求,从节点从主节点同步复制数据。读请求可以视业务场景配置读取策略:
- 只读 primary ;
- 只读 secondary(读写分离);
- 两者都可读;
应用程序通常将 RS 每个节点的 IP 都配上,它可以连接任一节点,读取 RS 集群信息,然后再连接主节点。选举时要满足过半数原则,因此节点数通常为奇数,即 , 则为过半数。
由此一来,一个 RS 至少需要有 3 个节点:一主两从,数据为三副本。如果只要一主一从两副本模式,可以加一个仲裁节点。仲裁节点只参与选举,不存储数据。
RS 实现数据多副本,达到高可用和分散压力的目的。一方面,RS 允许有节点挂掉,只要故障节点不超过半数,数据库服务就不受影响;另一方面,通过读写分离,可以将读压力分散到 secondary 节点,从而降低 primary 的压力。
除了数据副本复制功能,MongoDB 还提供了数据分片功能:
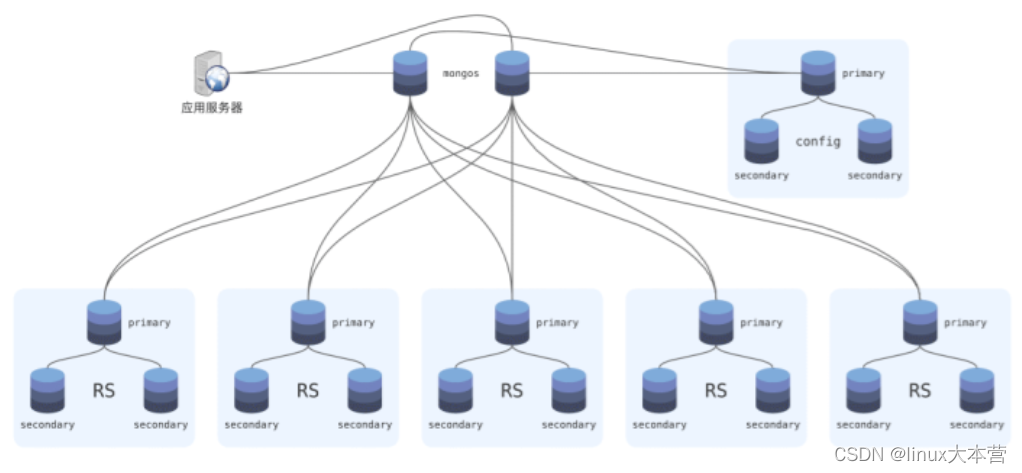
如上图,这是一个 MongoDB 分片集群:集群中有 5 个分片,每个分片的数据由一个 RS 负责存储,RS 做数据副本复制以实现高可用;MongoDB 支持通过哈希或者范围划分,将数据分到某一个 RS 上保存;数据划分策略、分片映射关系则由一个独立的 RS 保存,称为 config ;由于这类元数据不大,因此 config 通常都很小;mongos 则负责查询路由,它解析客户端请求,根据 config 中的元数据判断数据位于哪个 RS ;如果查询条件无法确定数据位置,它会向每个 RS 都发起查询,再合并结果;mongos 是无状态的,通常可以部署多个实例,来实现高可用;此外,MongoDB 还可以自动平衡数据,将数据从负载高的 RS 迁移到负载低的 RS (迁移好后更新 config 元数据)。
队列异步化
应用负载通常不是均匀的,比如电商大促时请求量可能是平时的好几倍,甚至几十倍。面对突发而来的极高并发,系统通常难以应对。何况按瞬时峰值负载来规划系统容量,放在平时会造成极大的浪费。
笔者曾负责一个主机监控系统的研发,最开始的架构大致如下:
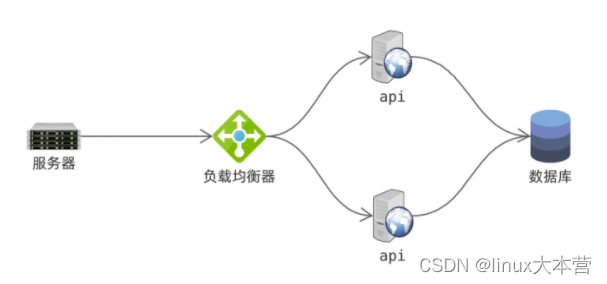
每台服务器主机上都部署 agent ,定期采集性能指标,并提交给后端处理。由于定时任务总是在整点执行,因此会出现主机总在采集时点同时请求 api 提交数据的情况。
所有主机几乎在同一时间请求 api 提交数据,但由于数据库写入吞吐是有限的,经常会有数据写入失败。如果 agent 没有失败重试机制,则意味着数据丢失。
然而瞬间请求过后,系统就又空闲下来了。如果可以将数据写入分摊到整个提交周期,系统的表现应该要好很多。就像拦河大坝,发生洪灾时先把水拦住,再慢慢放水,就不会造成严重损失。
因此,我们可以引入消息队列来做水库,对 api 进行异步化改造:
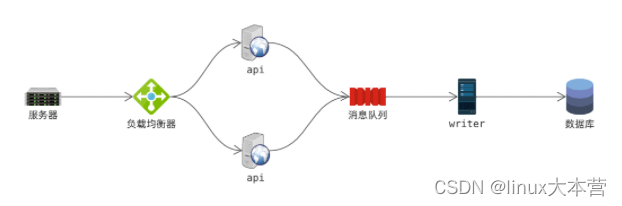
- api 收到数据提交后,先把数据写入 消息队列( message queue 简称 MQ );
- 消息队列通常是顺序写入磁盘,因此写性能要比数据库高很多;
- 后台服务 writer 负责从 MQ 消费数据,并写入数据库;
这样一来,当采集时刻瞬时数据提交并发上来后,api 可以从容地将全部数据写到 MQ 。这时数据可能仍堆积在 MQ ,尚未写入数据库。writer 模块会慢慢消费数据,完成写库任务。
只要在下次提交时间到达前可以顺利写完,系统就可平稳运行。由此可见,MQ 就像一个水库,对数据流起到 削峰平谷 的作用。
此外,MQ 的引入还有效降低了系统模块间的耦合。回到这个例子,如果 writer 或数据库发生故障或正在维护,对 api 完全没有影响。agent 还能继续提交数据,只是数据会堆积在 MQ 中。writer 和数据库恢复后,再慢慢追数据即可。
总结一下,引入消息队列可以发挥以下效果:
- 流量削峰平谷;
- 处理异步化;
- 模块解耦;
目前,比较流行的消息队列系统有 Kafka ,RabbitMQ 等等,有兴趣的同学可以自行了解一下。