论文标题:Improving Language Understanding by Generative Pre-Training
论文链接:https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf
论文来源:OpenAI
一、概述
从无标注文本中高效学习的能力对于缓解对监督学习的依赖是很关键的。很多自然语言处理任务依赖于大量的标注数据,对于这些任务来说,能够从无标注数据中学习的无监督方法就成了重要的替代方法。然而,从未标注的文本中利用单词级以上的信息具有挑战性,主要有两个原因:
①目前尚不清楚哪种类型的优化目标在学习对迁移有用的文本表示时最有效;
②对于将这些学习到的表征转移到目标任务的最有效方法,目前还没有达成共识。
在本文中探索了一种用于语言理解的半监督方法,也就是GPT,其采用无监督预训练与有监督微调相结合的方式。本文的目标是学习一种普遍的表征,它可以不需要任何适应就能转移到广泛的任务中,而且不要求这些目标任务与未标注语料库处于同一域中。首先,我们在未标注数据上使用语言建模目标函数。随后,我们使用相应的监督目标函数将这些参数调整到目标任务。
GPT采用Transformer作为模型架构。Transformer在捕获长程依赖方面能力优越,相较于循环网络是更合适的选择。在进行下游任务迁移时,GPT采用特定于任务的输入适配方法,将结构化文本输入处理为单个连续的token序列。这些适配使我们能够在对预训练模型的架构进行最小更改的情况下有效地进行微调。
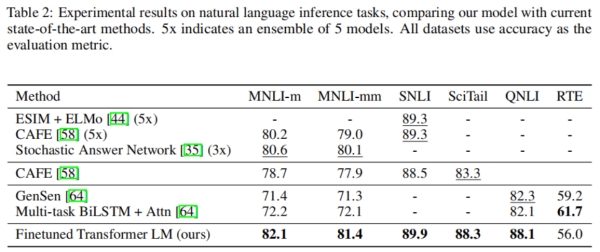
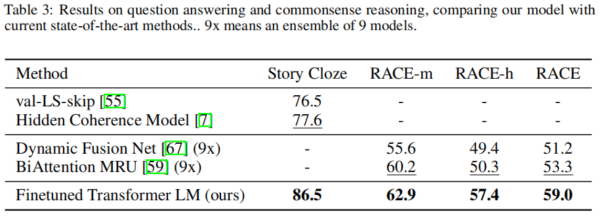
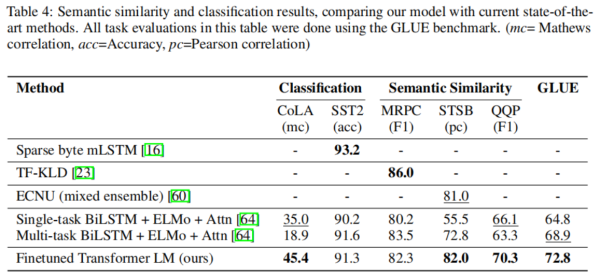
GPT在进行实验的12个数据集中的9个上取得了新的SOTA结果。举例来说在常识推理任务(Stories Cloze Test)上取得了8.9%的提升,在问答任务(RACE)上取得了5.7%的提升,在文本蕴含任务(MultiNLI)取得了1.5%的提升,另外在GLUE多任务benchmark数据集上取得了5.5%的提升。
二、方法
GPT的训练过程主要包括两个阶段。第一个阶段是利用一个大的文本语料库来学习一个高容量的语言模型,接着第二个阶段进行微调,也就是利用标注数据将模型适配到一个下游任务。
无监督预训练
给定一个无监督语料库,其token集合用来表示,我们使用一个标准语言建模目标函数来最大化以下似然:
❝ ❞
这里的是上下文窗口的大小。条件概率使用参数为的神经网络来建模,这些参数使用随机梯度下降来训练。在本文的实验中,使用一个多层Transformer decoder(其实是Transformer decoder中的masked多头自注意力层加上前馈层,没有使用中间那一层)来作为语言模型,这是Transformer的变种。这个模型在输入文本token上应用多头自注意力机制,然后使用前馈层来产生一个目标token的输出分布。以下是GPT预测当前token的过程:
❝ ❞
这里的相当于当前预测token的上下文指示向量,用于从word embedding矩阵(是词典大小,是word embedding的维度)中取出当前预测token的上下文embedding向量。在这里表示使用的Transformer 层的数量,是位置矩阵,是层的输出。
有监督微调
在处理下游任务时需要将模型参数适配到相应的任务。我们假设一个有标注数据集,其中每个实例包含一个输入token的序列以及一个标签。输入token序列将通过GPT以获取其最后一层的最后一个token的输出,然后将其通过一个参数为的线性输出层来预测:
❝ ❞
这相当于最大化以下似然:
❝ ❞
另外本文发现在微调时将预训练的目标函数作为辅助目标是有帮助的,这可以:
①提高有监督模型的泛化性能;
②加速收敛。
因此在微调时可以优化以下目标函数(作为权重超参数):
❝ ❞
总而言之,在微调时需要的额外参数只有,以及分隔符token的embedding(后面会提到)。
特定于任务的输入转换
对于某些任务,如文本分类,我们可以直接如上所述微调我们的模型。然而某些其他任务,如问答或文本蕴含,具有结构化的输入,如有序的句子对,或文档、问题和答案的三元组。由于我们的预训练模型是在连续的文本序列上训练的,所以我们需要进行一些修改才能将其应用于这些任务。GPT的策略是将这些任务的结构化输入转换为GPT可以处理的有序序列,这样可以避免对模型进行广泛的更改。下图展示了针对各种任务的适配。所有的输入变换都需要添加随机初始化的开始和结束token<s>和<e>。
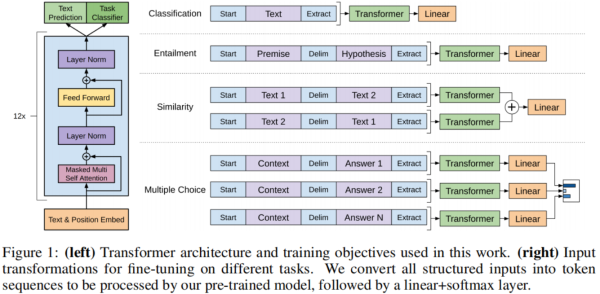
文本蕴含
对文本蕴含数据集中实例的处理就是将前提和假设中间用分隔符$隔开。
文本相似性
对于相似性任务,两个对比的句子没有固有的顺序,为了反映这一点我们将两个句子按不同的顺序排列,中间都用分隔符$隔开。然后单独处理两个顺序的拼接获得两个,最后将这两个element-wise地加起来再输入到线性输出层。
问答及常识推理
对于这一类的任务,每个实例都包含一个文档、问题以及一个可能的答案集合。我们将文档与问题直接拼接起来,然后与每个答案拼接(需要添加分隔符$)。所有这些拼接的token序列被GPT单独处理然后用一个softmax来预测可能的答案。
三、实验
数据集
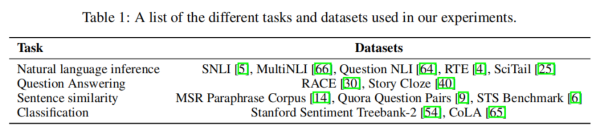
无标注数据集使用BooksCorpus书籍数据集。下游任务数据集如下表所示:
实验
各类下游任务的实验结果如下图所示:
分析
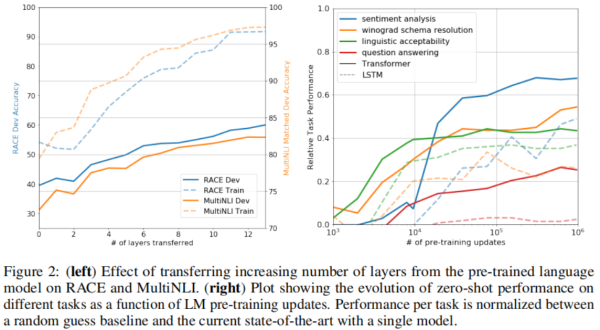
探究了模型层数的影响与zero-shot设置的模型性能:
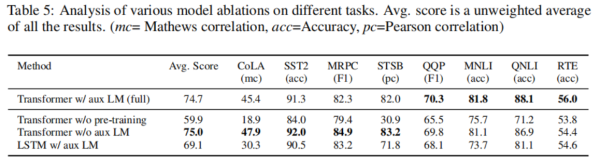
消融实验
GPT的消融实验:

![【项目设计】高并发内存池 (四)[pagecache实现]](https://img-blog.csdnimg.cn/ca656d66a1484fd89961465b5276ba34.png)