🎇C++学习历程:入门
- 博客主页:一起去看日落吗
- 持续分享博主的C++学习历程
博主的能力有限,出现错误希望大家不吝赐教- 分享给大家一句我很喜欢的话: 也许你现在做的事情,暂时看不到成果,但不要忘记,树🌿成长之前也要扎根,也要在漫长的时光🌞中沉淀养分。静下来想一想,哪有这么多的天赋异禀,那些让你羡慕的优秀的人也都曾默默地翻山越岭🐾。

🍁 🍃 🍂 🌿
目录
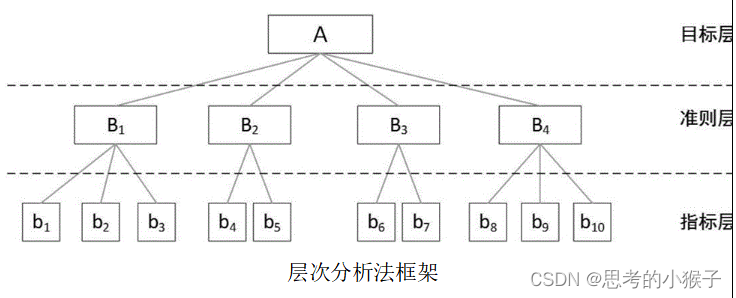
- 🍁1. pagecache
- 🍂1.1 pagecache整体设计
- 🍂1.2 pagecache中获取Span
- 🍁2. 申请内存过程联调
🍁1. pagecache
🍂1.1 pagecache整体设计
- page cache与central cache结构的相同之处
page cache与central cache一样,它们都是哈希桶的结构,并且page cache的每个哈希桶中里挂的也是一个个的span,这些span也是按照双链表的结构链接起来的。
- page cache与central cache结构的不同之处
首先,central cache的映射规则与thread cache保持一致,而page cache的映射规则与它们都不相同。page cache的哈希桶映射规则采用的是直接定址法,比如1号桶挂的都是1页的span,2号桶挂的都是2页的span,以此类推。
其次,central cache每个桶中的span被切成了一个个对应大小的对象,以供thread cache申请。而page cache当中的span是没有被进一步切小的,因为page cache服务的是central cache,当central cache没有span时,向page cache申请的是某一固定页数的span,而如何切分申请到的这个span就应该由central cache自己来决定。
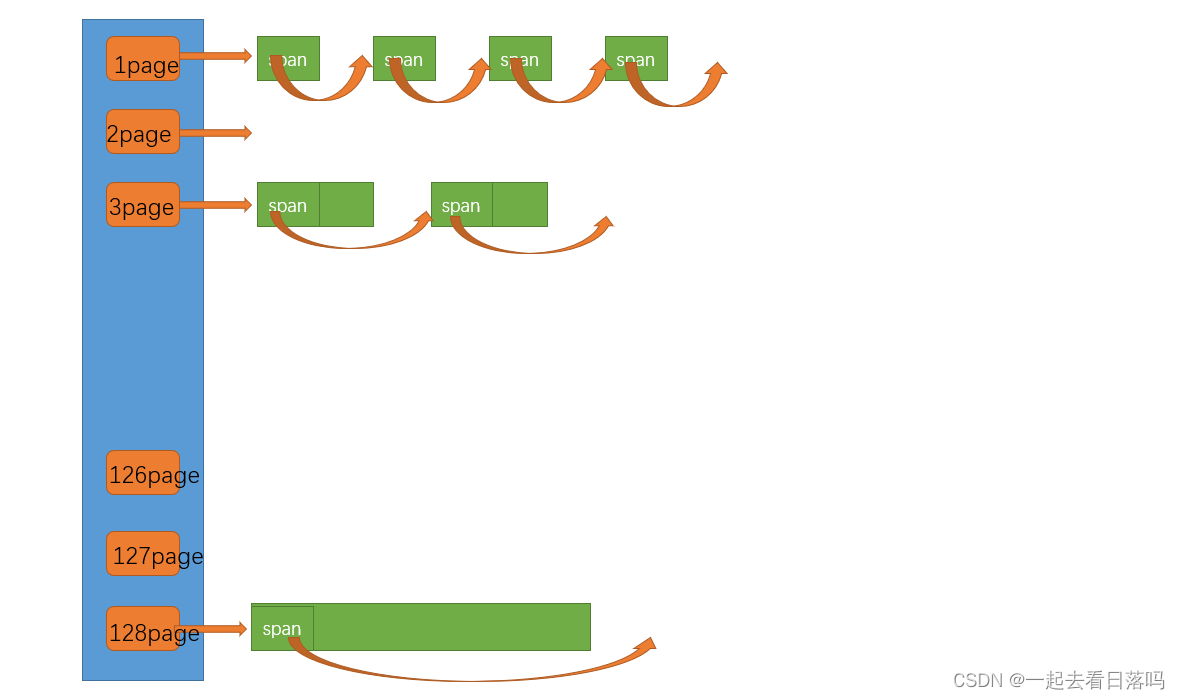
至于page cache当中究竟有多少个桶,这就要看你最大想挂几页的span了,这里我们就最大挂128页的span,为了让桶号与页号对应起来,我们可以将第0号桶空出来不用,因此我们需要将哈希桶的个数设置为129。
//page cache中哈希桶的个数
static const size_t NPAGES = 129;
为什么这里最大挂128页的span呢?因为线程申请单个对象最大是256KB,而128页可以被切成4个256KB的对象,因此是足够的。当然,如果你想在page cache中挂更大的span也是可以的,根据具体的需求进行设置就行了。
- 在page cache获取一个n页的span的过程
如果central cache要获取一个n页的span,那我们就可以在page cache的第n号桶中取出一个span返回给central cache即可,但如果第n号桶中没有span了,这时我们并不是直接转而向堆申请一个n页的span,而是要继续在后面的桶当中寻找span。
直接向堆申请以页为单位的内存时,我们应该尽量申请大块一点的内存块,因为此时申请到的内存是连续的,当线程需要内存时我们可以将其切小后分配给线程,而当线程将内存释放后我们又可以将其合并成大块的连续内存。如果我们向堆申请内存时是小块小块的申请的,那么我们申请到的内存就不一定是连续的了。
因此,当第n号桶中没有span时,我们可以继续找第n+1号桶,因为我们可以将n+1页的span切分成一个n页的span和一个1页的span,这时我们就可以将n页的span返回,而将切分后1页的span挂到1号桶中。但如果后面的桶当中都没有span,这时我们就只能向堆申请一个128页的内存块,并将其用一个span结构管理起来,然后将128页的span切分成n页的span和128-n页的span,其中n页的span返回给central cache,而128-n页的span就挂到第128-n号桶中。
也就是说,我们每次向堆申请的都是128页大小的内存块,central cache要的这些span实际都是由128页的span切分出来的。
- page cache的实现方式
当每个线程的thread cache没有内存时都会向central cache申请,此时多个线程的thread cache如果访问的不是central cache的同一个桶,那么这些线程是可以同时进行访问的。这时central cache的多个桶就可能同时向page cache申请内存的,所以page cache也是存在线程安全问题的,因此在访问page cache时也必须要加锁。
但是在page cache这里我们不能使用桶锁,因为当central cache向page cache申请内存时,page cache可能会将其他桶当中大页的span切小后再给central cache。此外,当central cache将某个span归还给page cache时,page cache也会尝试将该span与其他桶当中的span进行合并。
也就是说,在访问page cache时,我们可能需要访问page cache中的多个桶,如果page cache用桶锁就会出现大量频繁的加锁和解锁,导致程序的效率低下。因此我们在访问page cache时使用没有使用桶锁,而是用一个大锁将整个page cache给锁住。
而thread cache在访问central cache时,只需要访问central cache中对应的哈希桶就行了,因为central cache的每个哈希桶中的span都被切分成了对应大小,thread cache只需要根据自己所需对象的大小访问central cache中对应的哈希桶即可,不会访问其他哈希桶,因此central cache可以用桶锁。
此外,page cache在整个进程中也是只能存在一个的,因此我们也需要将其设置为单例模式
//单例模式
class PageCache
{
public:
//提供一个全局访问点
static PageCache* GetInstance()
{
return &_sInst;
}
private:
SpanList _spanLists[NPAGES];
std::mutex _pageMtx; //大锁
private:
PageCache() //构造函数私有
{}
PageCache(const PageCache&) = delete; //防拷贝
static PageCache _sInst;
};
当程序运行起来后我们就立马创建该对象即可。
PageCache PageCache::_sInst;
🍂1.2 pagecache中获取Span
- 获取一个非空的span
thread cache向central cache申请对象时,central cache需要先从对应的哈希桶中获取到一个非空的span,然后从这个非空的span中取出若干对象返回给thread cache。那central cache到底是如何从对应的哈希桶中,获取到一个非空的span的呢?
首先当然是先遍历central cache对应哈希桶当中的双链表,如果该双链表中有非空的span,那么直接将该span进行返回即可。为了方便遍历这个双链表,我们可以模拟迭代器的方式,给SpanList类提供Begin和End成员函数,分别用于获取双链表中的第一个span和最后一个span的下一个位置,也就是头结点。
//带头双向循环链表
class SpanList
{
public:
Span* Begin()
{
return _head->_next;
}
Span* End()
{
return _head;
}
private:
Span* _head;
public:
std::mutex _mtx; //桶锁
};
但如果遍历双链表后发现双链表中没有span,或该双链表中的span都为空,那么此时central cache就需要向page cache申请内存块了。
那具体是向page cache申请多大的内存块呢?我们可以根据具体所需对象的大小来决定,就像之前我们根据对象的大小计算出,thread cache一次向central cache申请对象的个数上限,现在我们是根据对象的大小计算出,central cache一次应该向page cache申请几页的内存块。
我们可以先根据对象的大小计算出,thread cache一次向central cache申请对象的个数上限,然后将这个上限值乘以单个对象的大小,就算出了具体需要多少字节,最后再将这个算出来的字节数转换为页数,如果转换后不够一页,那么我们就申请一页,否则转换出来是几页就申请几页。也就是说,central cache向page cache申请内存时,要求申请到的内存尽量能够满足thread cache向central cache申请时的上限。
//管理对齐和映射等关系
class SizeClass
{
public:
//central cache一次向page cache获取多少页
static size_t NumMovePage(size_t size)
{
size_t num = NumMoveSize(size); //计算出thread cache一次向central cache申请对象的个数上限
size_t nPage = num*size; //num个size大小的对象所需的字节数
nPage >>= PAGE_SHIFT; //将字节数转换为页数
if (nPage == 0) //至少给一页
nPage = 1;
return nPage;
}
};
代码中的PAGE_SHIFT代表页大小转换偏移,我们这里以页的大小为8K为例,PAGE_SHIFT的值就是13。
//页大小转换偏移,即一页定义为2^13,也就是8KB
static const size_t PAGE_SHIFT = 13;
需要注意的是,当central cache申请到若干页的span后,还需要将这个span切成一个个对应大小的对象挂到该span的自由链表当中。
如何找到一个span所管理的内存块呢?首先需要计算出该span的起始地址,我们可以用这个span的起始页号乘以一页的大小即可得到这个span的起始地址,然后用这个span的页数乘以一页的大小就可以得到这个span所管理的内存块的大小,用起始地址加上内存块的大小即可得到这块内存块的结束位置。
明确了这块内存的起始和结束位置后,我们就可以进行切分了。根据所需对象的大小,每次从大块内存切出一块固定大小的内存块尾插到span的自由链表中即可。
为什么是尾插呢?因为我们如果是将切好的对象尾插到自由链表,这些对象看起来是按照链式结构链接起来的,而实际它们在物理上是连续的,这时当我们把这些连续内存分配给某个线程使用时,可以提高该线程的CPU缓存利用率。
//获取一个非空的span
Span* CentralCache::GetOneSpan(SpanList& spanList, size_t size)
{
//1、先在spanList中寻找非空的span
Span* it = spanList.Begin();
while (it != spanList.End())
{
if (it->_freeList != nullptr)
{
return it;
}
else
{
it = it->_next;
}
}
//2、spanList中没有非空的span,只能向page cache申请
Span* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(size));
//计算span的大块内存的起始地址和大块内存的大小(字节数)
char* start = (char*)(span->_pageId << PAGE_SHIFT);
size_t bytes = span->_n << PAGE_SHIFT;
//把大块内存切成size大小的对象链接起来
char* end = start + bytes;
//先切一块下来去做尾,方便尾插
span->_freeList = start;
start += size;
void* tail = span->_freeList;
//尾插
while (start < end)
{
NextObj(tail) = start;
tail = NextObj(tail);
start += size;
}
NextObj(tail) = nullptr; //尾的指向置空
//将切好的span头插到spanList
spanList.PushFront(span);
return span;
}
需要注意的是,当我们把span切好后,需要将这个切好的span挂到central cache的对应哈希桶中。因此SpanList类还需要提供一个接口,用于将一个span插入到该双链表中。这里我们选择的是头插,这样当central cache下一次从该双链表中获取非空span时,一来就能找到。
由于SpanList类之前实现了Insert和Begin函数,这里实现双链表头插就非常简单,直接在双链表的Begin位置进行Insert即可。
- 获取一个k页的span
当我们调用上述的GetOneSpan从central cache的某个哈希桶获取一个非空的span时,如果遍历哈希桶中的双链表后发现双链表中没有span,或该双链表中的span都为空,那么此时central cache就需要向page cache申请若干页的span了,下面我们就来说说如何从page cache获取一个k页的span。
因为page cache是直接按照页数进行映射的,因此我们要从page cache获取一个k页的span,就应该直接先去找page cache的第k号桶,如果第k号桶中有span,那我们直接头删一个span返回给central cache就行了。所以我们这里需要再给SpanList类添加对应的Empty和PopFront函数。
``cpp
//带头双向循环链表
class SpanList
{
public:
void PushFront(Span* span)
{
Insert(Begin(), span);
}
bool Empty()
{
return _head == _head->_next;
}
Span* PopFront()
{
Span* front = _head->_next;
Erase(front);
return front;
}
private:
Span* _head;
public:
std::mutex _mtx; //桶锁
};
如果page cache的第k号桶中没有span,我们就应该继续找后面的桶,只要后面任意一个桶中有一个n页span,我们就可以将其切分成一个k页的span和一个n-k页的span,然后将切出来k页的span返回给central cache,再将n-k页的span挂到page cache的第n-k号桶即可。
但如果后面的桶中也都没有span,此时我们就需要向堆申请一个128页的span了,在向堆申请内存时,直接调用我们封装的SystemAlloc函数即可。
需要注意的是,向堆申请内存后得到的是这块内存的起始地址,此时我们需要将该地址转换为页号。由于我们向堆申请内存时都是按页进行申请的,因此我们直接将该地址除以一页的大小即可得到对应的页号。
//获取一个k页的span
Span* PageCache::NewSpan(size_t k)
{
assert(k > 0 && k < NPAGES);
//先检查第k个桶里面有没有span
if (!_spanLists[k].Empty())
{
return _spanLists[k].PopFront();
}
//检查一下后面的桶里面有没有span,如果有可以将其进行切分
for (size_t i = k + 1; i < NPAGES; i++)
{
if (!_spanLists[i].Empty())
{
Span* nSpan = _spanLists[i].PopFront();
Span* kSpan = new Span;
//在nSpan的头部切k页下来
kSpan->_pageId = nSpan->_pageId;
kSpan->_n = k;
nSpan->_pageId += k;
nSpan->_n -= k;
//将剩下的挂到对应映射的位置
_spanLists[nSpan->_n].PushFront(nSpan);
return kSpan;
}
}
//走到这里说明后面没有大页的span了,这时就向堆申请一个128页的span
Span* bigSpan = new Span;
void* ptr = SystemAlloc(NPAGES - 1);
bigSpan->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;
bigSpan->_n = NPAGES - 1;
_spanLists[bigSpan->_n].PushFront(bigSpan);
//尽量避免代码重复,递归调用自己
return NewSpan(k);
}
这里说明一下,当我们向堆申请到128页的span后,需要将其切分成k页的span和128-k页的span,但是为了尽量避免出现重复的代码,我们最好不要再编写对应的切分代码。我们可以先将申请到的128页的span挂到page cache对应的哈希桶中,然后再递归调用该函数就行了,此时在往后找span时就一定会在第128号桶中找到该span,然后进行切分。
这里其实有一个问题:当central cache向page cache申请内存时,central cache对应的哈希桶是处于加锁的状态的,那在访问page cache之前我们应不应该把central cache对应的桶锁解掉呢?
这里建议在访问page cache前,先把central cache对应的桶锁解掉。虽然此时central cache的这个桶当中是没有内存供其他thread cache申请的,但thread cache除了申请内存还会释放内存,如果在访问page cache前将central cache对应的桶锁解掉,那么此时当其他thread cache想要归还内存到central cache的这个桶时就不会被阻塞。
因此在调用NewSpan函数之前,我们需要先将central cache对应的桶锁解掉,然后再将page cache的大锁加上,当申请到k页的span后,我们需要将page cache的大锁解掉,但此时我们不需要立刻获取到central cache中对应的桶锁。因为central cache拿到k页的span后还会对其进行切分操作,因此我们可以在span切好后需要将其挂到central cache对应的桶上时,再获取对应的桶锁。
这里为了让代码清晰一点,只写出了加锁和解锁的逻辑,我们只需要将这些逻辑添加到之前实现的GetOneSpan函数的对应位置即可。
spanList._mtx.unlock(); //解桶锁
PageCache::GetInstance()->_pageMtx.lock(); //加大锁
//从page cache申请k页的span
PageCache::GetInstance()->_pageMtx.unlock(); //解大锁
//进行span的切分...
spanList._mtx.lock(); //加桶锁
//将span挂到central cache对应的哈希桶
🍁2. 申请内存过程联调
- ConcurrentAlloc函数
在将thread cache、central cache以及page cache的申请流程写通了之后,我们就可以向外提供一个ConcurrentAlloc函数,用于申请内存块。每个线程第一次调用该函数时会通过TLS获取到自己专属的thread cache对象,然后每个线程就可以通过自己对应的thread cache申请对象了。
static void* ConcurrentAlloc(size_t size)
{
//通过TLS,每个线程无锁的获取自己专属的ThreadCache对象
if (pTLSThreadCache == nullptr)
{
pTLSThreadCache = new ThreadCache;
}
return pTLSThreadCache->Allocate(size);
}
里说一下编译时会出现的问题,在C++的algorithm头文件中有一个min函数,这是一个函数模板,而在Windows.h头文件中也有一个min,这是一个宏。由于调用函数模板时需要进行参数类型的推演,因此当我们调用min函数时,编译器会优先匹配Windows.h当中以宏的形式实现的min,此时当我们以std::min的形式调用min函数时就会产生报错,这就是没有用命名空间进行封装的坏处,这时我们只能选择将std::去掉,让编译器调用Windows.h当中的min。