- 使用列表
- 标量列表函数
- size() 函数返回列表中的元素的数量
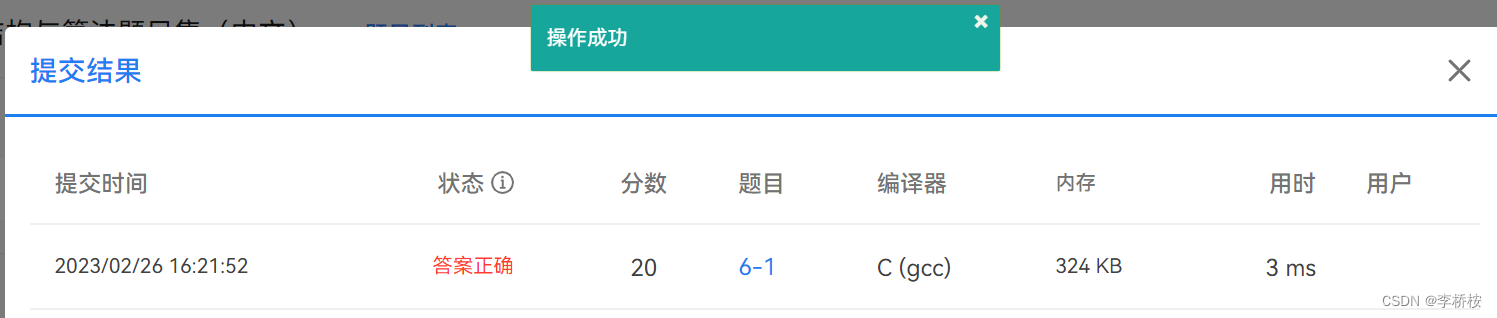
- MATCH (p:Person)-[:ACTED_IN]->(m:Movie) WITH p, collect (m.title) AS MovieTitles WITH p, MovieTitles, size(MovieTitles) AS NumMovies WHERE NumMovies >= 20 RETURN p.name AS Actor, NumMovies, MovieTitles ORDER BY NumMovies
- 列表的第一个 head() 函数和最后一个元素 last() 函数
- MATCH (m:Movie) WHERE date(m.released).year = 2000 WITH m ORDER BY date(m.released) WITH collect(m) AS Movies WITH head(Movies) as First, last(Movies) as Last RETURN First.title AS FirstTitle, First.released AS FirstDate,Last.title AS LastTitle
- reduce() 函数,可以让您计算一个值,您可以在其中指定初始值,并使用列表中每个元素的初始值应用公式或计算。
- MATCH (m:Movie) WHERE date(m.released).year = 2000 WITH collect(m.revenue) AS Revenues WITH Revenues, reduce(t=0, r IN Revenues | t + r) AS TotalRevenue RETURN TotalRevenue, size(Revenues) AS TotalMovies
- MATCH (:User)-[r:RATED]->(m:Movie) WHERE m.title = 'Toy Story' WITH collect(r.rating) AS Ratings WITH Ratings, reduce(Rating = 0, x IN Ratings | Rating + x) AS TotalRatings RETURN round(TotalRatings/size(Ratings),1)
- range() 函数创建数字列表
- RETURN range(0,100,5)
- 返回初值为0,终值为100,相差5的数字。
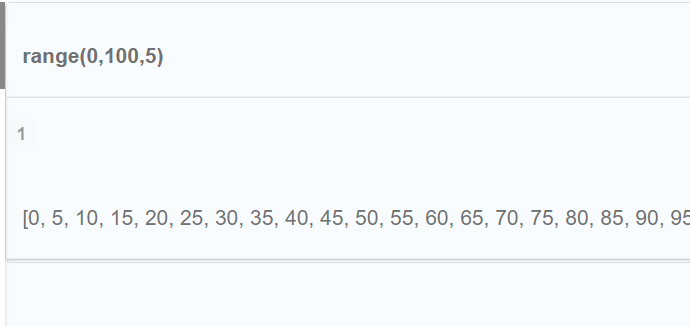
- 返回初值为0,终值为100,相差5的数字。
- RETURN range(0,100,5)
- reverse() 反转列表的元素
- MATCH (a:Actor)--(m:Movie) WHERE m.year < 1910 WITH a, count (m) AS NumMovies WITH NumMovies, [a.name, NumMovies] AS Stats ORDER BY NumMovies WITH collect(Stats) as AllStats RETURN AllStats, reverse(AllStats)
- tail() 返回列表的剩余元素 与 head() 互斥
- MATCH (m:Movie) WHERE date(m.released).year = 2000 WITH m ORDER BY date(m.released) WITH collect(m) AS Movies RETURN head(Movies).title AS FirstTitle, head(Movies).released AS FirstDate, size(tail(Movies)) AS SizeOfTail,tail(Movies)[-1].title AS LastTitle, tail(Movies)[-1].released AS LastDate
- split() 函数来分隔指定分隔符的字符串中的值,split()从字符串创建列表
- split( 属性 , 分隔符)
- nodes() 函数来提取给定路径中的节点列表,获取可变长度路径中的节点
- MATCH path = (p:Person {name: 'Elvis Presley'})-[*4]-(a:Actor) WITH nodes(path) AS n UNWIND n AS x WITH x WHERE x:MovieR ETURN DISTINCT x.title
- size() 函数返回列表中的元素的数量
- 标量列表函数